

1. 서 론
2. 대상현장 및 침하 데이터베이스 구축
3. 방법론
3.1 계측기반 침하예측 기법
3.2 딥러닝 모델
3.3 딥러닝 기반 침하예측 모델 구축
4. 침하예측 결과
5. 결 론
1. 서 론
압밀침하는 지반 내부의 간극수가 외부 하중에 의해 배출되면서 흙의 체적이 감소하고 변형이 발생하는 현상이다. 일반적으로 연약지반은 입자 크기가 매우 작은 점토로 구성되어 있어 투수성이 매우 낮다. 이로 인해 오랜 기간에 걸쳐 서서히 압밀이 발생하고 다량의 간극수가 배출됨에 따라 최종적으로 큰 침하량이 발하게 된다. 따라서, 대심도 연약지반에 항만, 공항, 교량 등의 구조물이 건설되는 경우, 장기적인 압밀침하로 인해 구조물의 기울어짐과 균열과 같은 심각한 지반공학적 문제가 유발될 수 있다. 이와 같은 지반공학적 문제를 예방하기 위해서는, 잔류침하량을 최소화하고 구조물의 안정성을 높이는 방법 외에도 정확한 침하예측을 통한 관리가 중요하다.
설계 단계에서는 압밀침하를 예측하기 위해 여러 압밀이론(Terzaghi, 1943; Barron, 1948; Hansbo, 1960)과 유한요소 해석(Chen et al., 2023c) 기법이 활용되지만, 지반 정수의 변동성과 복잡한 현장 특성으로 인해 예측된 침하와 실제 발생한 침하가 다른 경우가 빈번하게 나타난다.
시공 단계에서는 침하예측 정확도를 높이기 실제 현장에서의 계측자료(지표침하판 데이터)를 활용한 계측기반 침하예측 기법들이 적용되고 있으며, 대표적인 방법으로 쌍곡선법(Sridharan et al., 1987; Tan et al., 1991), Asaoka법(Asaoka, 1978), Hoshino법(Hoshino, 1962), Log S법(Yoo and Kim, 2000), Monden법(Monden, 1963) 등이 있다. 국내에서는 편이성으로 인해 쌍곡선법과 Asaoka법의 적용 사례가 많지만, 이 기법들은 성토 완료 후 압밀도 60% 이상의 시점부터 정확한 침하예측이 가능하다는 한계가 있다(Tan and Chew, 1996). 기존의 계측기반 침하예측 기법들의 한계점을 보완하기 위해, 최근 Kwak et al.(2022)은 가중 비선형 회귀 분석 방식을 도입한 쌍곡선법을 제안하였다. 제안된 방법은 기존 계측기반 침하예측 기법에 비해 낮은 압밀도(40% 이상)에서 정확한 침하예측이 가능하다는 장점이 있지만, 여전히 회귀분석에 사용되는 초기 측정 데이터를 선택할 때의 공학적 판단이 예측 결과에 큰 영향을 미친다는 점은 문제로 지적되고 있다.
최근 인공지능의 급격한 발전에 따라, 딥러닝 모델들이 기존 침하예측 기법들의 한계를 극복하기 위한 대안으로 주목받고 있다. 특히, 압축지수와 압밀계수와 같은 압밀정수를 예측하는 연구가 다수 보고되었으며(Ge et al., 2024; Díaz and Spagnoli, 2024), 시계열 침하예측도 많은 발전을 이루고 있다.
Kanayama et al.(2014)은 인공신경망(Artificial neural network, ANN) 기반의 침하예측 모델을 제안하였다. ANN 기반 모델은 35% 이상의 압밀도를 넘어선 계측 데이터를 학습할 때, 높은 정확도를 보여 쌍곡선법과 비교하여 우수한 성능을 나타냈다. Chen et al.(2023a)은 장단기 메모리(Long short term memory, LSTM) 모델을 이용해 홍콩 국제공항(Hong Kong International Airport)의 장기침하를 예측하고, 수치해석 결과와 비교·분석을 수행하였다. Hong et al.(2024)은 LSTM 모델을 이용해 부산항 신항의 침하를 예측하고, 기존의 계측기반 침하예측 기법(쌍곡선법, Asaoka법)과의 비교를 통해 인공지능 기반 모델의 우수성을 확인하였다. 신경망을 통한 시계열 침하예측과 더불어 인코더를 활용한 침하예측도 수행되었으며, 최근 자연어처리를 위해 개발된 Transformer 모델을 활용한 침하예측 사례도 증가하고 있다(Lo et al., 2023; Li et al., 2024).
연약지반 현장에서는 시공과정 중 예상치 못한 침하가 발생할 때 초기 대책을 마련하고 잔류침하를 최소화하기 위해 이른 시점에서 정확한 침하예측이 중요하다. 머신러닝 및 딥러닝 모델들은 침하예측 시, 빠르고 정확한 예측이 가능하다는 측면에서 많은 이점을 제공하지만, 일반적으로 충분한 양의 데이터가 확보되지 않은 상황에서 제한된 데이터로는 정확한 예측이 어려운 것으로 알려져 있다(Miller et al., 2024). 하지만, 기존 연구들은 계측 일수와 같은 정량적인 학습 데이터양에 따른 예측 모델 성능을 명확히 제시하지 않고, 전체 계측 기간을 비율(%)로 구분하거나 압밀도를 기준으로 학습/예측을 구분하여 연구를 수행하였다. 이러한 접근 방식은 침하 계측 기간과 침하 경향에 따라 학습 데이터의 양이 달라지는 문제를 일으키며, 예측 모델의 신뢰성을 일관되게 평가하기 어렵게 만든다.
또한, 기존 연구는 대부분 소수의 침하 계측 자료를 사용했으며, 딥러닝 모델과 기존 계측기반 침하예측 기법 간의 비교·분석이 부족하고 딥러닝 기법 간의 광범위한 비교도 거의 이루어지지 않았다. 시계열 예측 문제를 해결하기 위한 최적 기법이 존재하지 않기 때문에, 예측 방법들의 정확도를 다수의 데이터를 통해 비교하고 평가하는 것이 중요하다(Zhang and Kline, 2007).
따라서, 본 연구에서는 최근 제안된 침하예측 모델들과 계측기반 침하예측 기법들의 정확도를 비교·분석하기 위해, 4개의 딥러닝 알고리즘(ANN, LSTM, GRU, Transformer)과 3개의 계측기반 침하예측 기법(쌍곡선법, Asaoka법, 가중 비선형 회귀 쌍곡선법)을 적용하여 침하예측을 수행하였다. 침하 데이터베이스는 부산항 신항 내 위치한 6개 현장 지표침하판 계측자료 98개를 활용하여 구축하였으며, 정량적인 평가를 위해 학습 및 회귀 일수(60일-150일)에 따라 총 392개 조건에서 침하예측을 실시하였고, 이를 통해 각 기법과 모델의 정확도를 면밀히 분석하였다.
2. 대상현장 및 침하 데이터베이스 구축
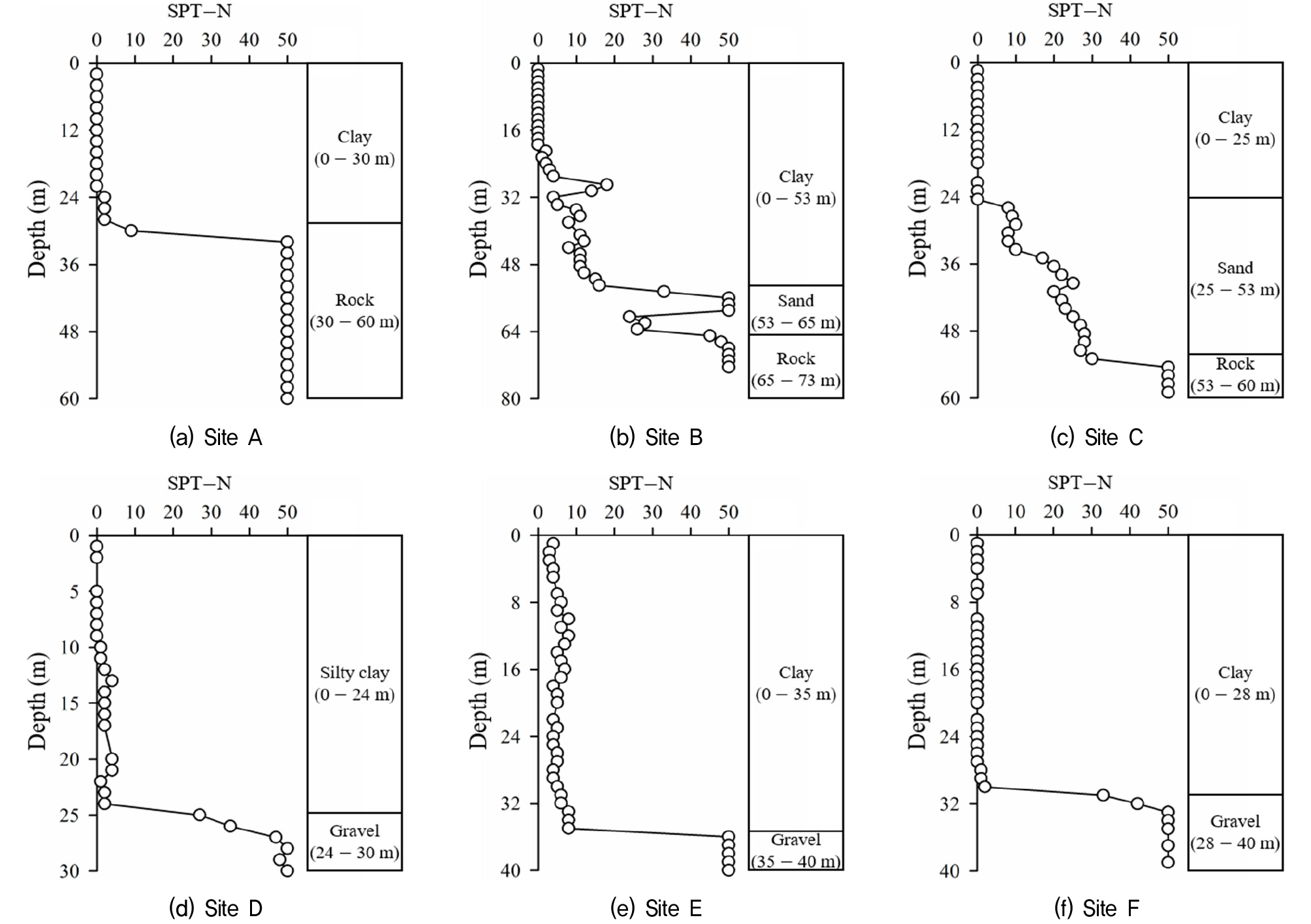
본 연구에서는 연약지반 침하예측 기법들을 비교·분석하기 위해, 부산항 신항에 위치한 6개 현장 계측자료를 수집하였다. Fig. 1은 각 현장의 대표 지층 구성과 심도별 SPT-N값을 보여준다. 대상 현장들에서는 약 25m에서 55m 깊이까지 점토층으로 구성되어 있으며, 그 아래에는 암반(A, B, C 현장) 또는 자갈층(D, E, F 현장)이 위치하였다. 상부 점토층에서는 연약지반 기준인 SPT-N값 4 이하(층 두께 10m 미만)와 6 이하(층 두께 10m 이상)가 나타났고(KDS 11 30 05), 심도가 깊어질수록 하부층의 저항과 강도가 증가하여 값이 급격히 상승하는 경향을 보였다.
대상 현장들은 지반개량을 위해 선행하중공법(Preloading)과 연직배수재(Prefabricated vertical drains, PVD)를 활용하였다. PVD는 스미어 효과(Smear effect)와 웰 저항(Well resistance)을 고려하여 설계 및 배치되었으며, 설치 후 각 현장에 다수의 지표침하판이 전략적으로 배치되었다. Fig. 2는 현장에서 사용된 지표침하판의 모식도를 보여준다. 각 지표침하판 지지대(Stiffer)와 침하봉(Settlement rod)이 부착되었고, 침하봉은 성토 작업과 토압에 의한 손상을 방지하기 위해 보호 케이슨(Proection cap)으로 추가로 보호되었다. 침하봉은 성토 높이보다 높게 설계되었으며 침하봉의 높이는 광파기를 통해 5-7일 간격으로 계측되었다. 성토 높이가 침하봉 높이를 초과하게 되면 침하봉을 연장하여 지속해서 원지반 침하를 계측하였다.
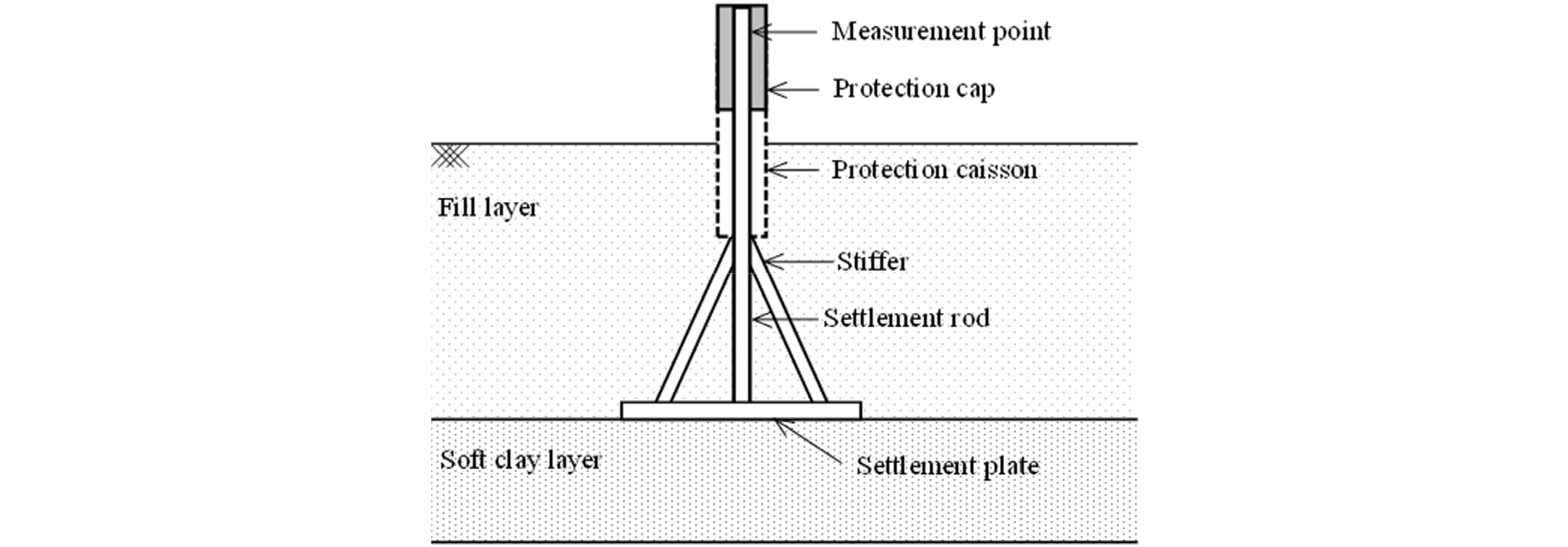
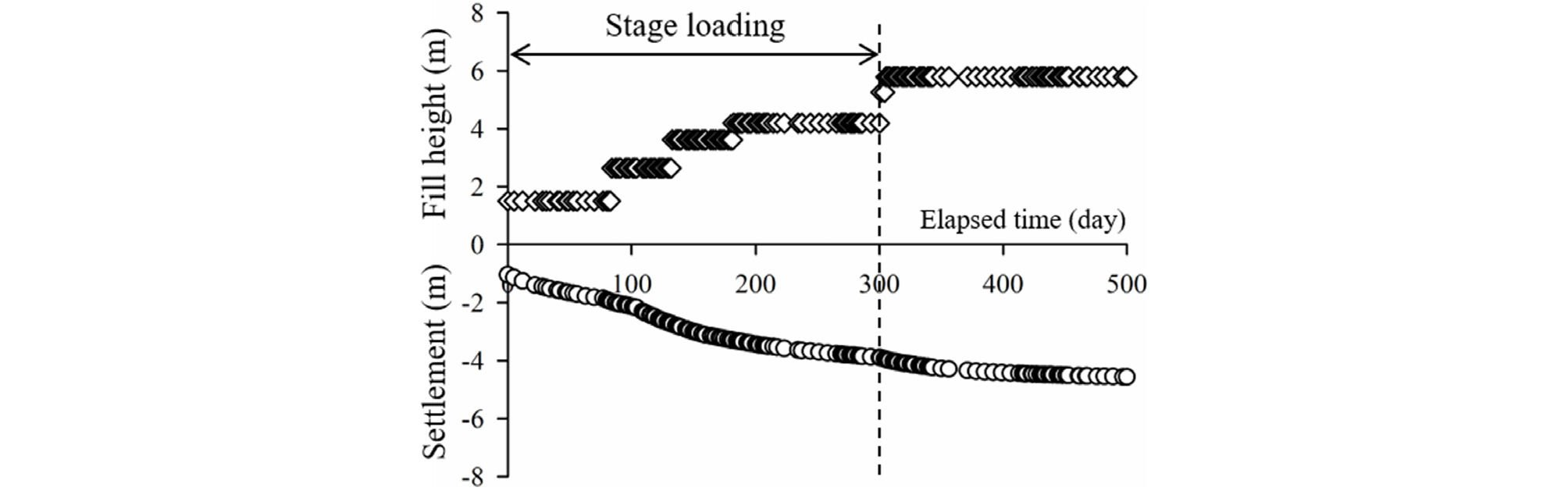
Fig. 3은 지표침하판 계측결과 예시를 나타낸다. 대상 현장에서는 사면 안정성을 확보하기 위해 설계하중에 도달할 때까지 단계적으로 성토를 진행하였으며, 계측은 설계하중에 도달한 이후에도 잔류침하량이 설계기준을 만족할 때까지 지속적으로 이루어졌다.
본 연구에서는 최종성토 완료 후 계측된 침하량을 이용해 데이터베이스(Database, DB)를 구축하였다. 다수의 지표침하판 계측결과 중, 다음 세 가지 기준을 만족하는 98개의 지표침하판을 선정하여 DB를 구축하고 모델개발 및 침하예측을 수행하였다.
(1) 최종성토 이후 200일 이상의 계측이 이루어진 지표침하판
(2) 평균 계측 간격이 5일 이하인 지표침하판
(3) 최대 계측 간격이 10일 이하인 지표침하판
Table 1은 위 조건을 충족하는 현장별 지표침하판의 수, 최종성토 이후의 평균 계측 기간, 그리고 평균 최종침하량을 나타낸다. 이 중 D 현장에서는 가장 많은 지표침하판이 선정(24개)되었고, F 현장은 평균적으로 가장 긴 계측 기간과 가장 큰 침하가 발생하였다.
3. 방법론
3.1 계측기반 침하예측 기법
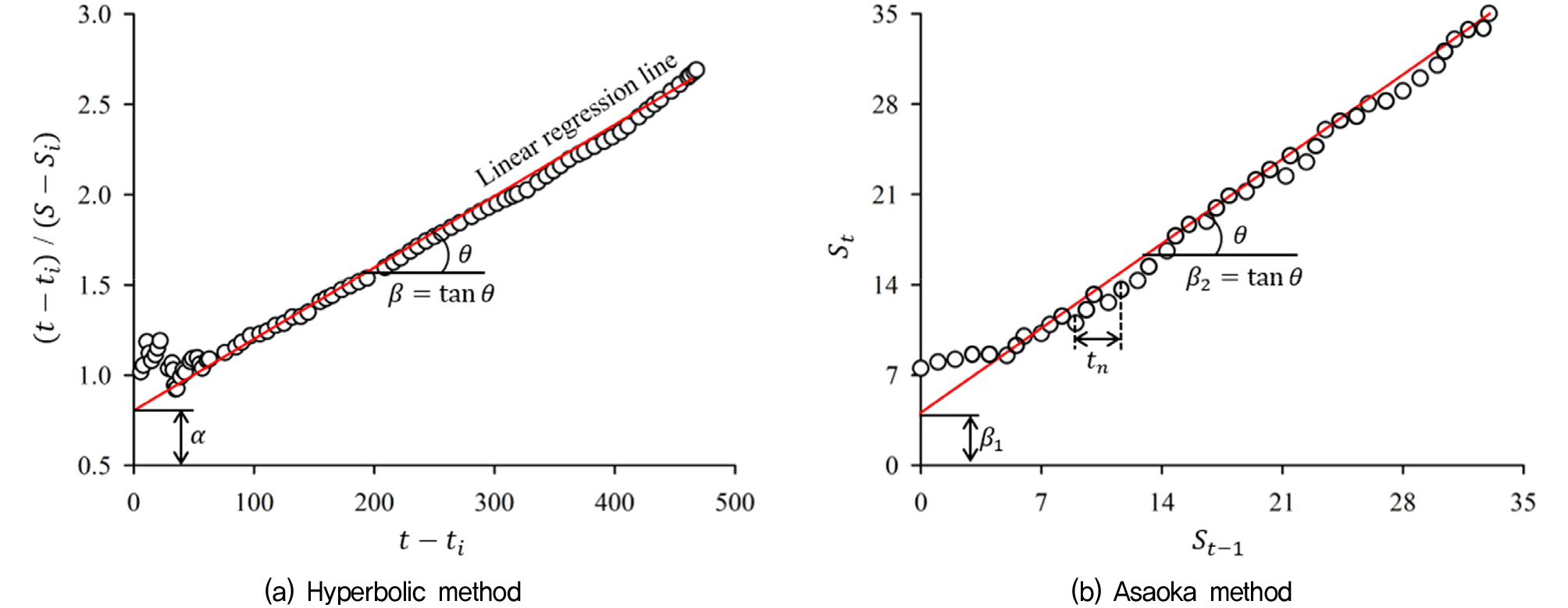
계측기반 침하예측 기법은 성토 완료 후 침하량을 계측하여 장래의 침하량을 예측하는 방법이다. 쌍곡선법은 침하 속도가 쌍곡선적으로 감소한다는 가정에 따른 것으로, 성토 완료 후 현장에서 계측된 침하량을 통해 도출된 침하-시간 관계를 이용하여 장래침하량을 추정한다(Tan, 1993). 쌍곡선법을 통한 침하예측은 식 (1)을 이용하며, Fig. 4(a)는 와 관계를 이용한 쌍곡선 회귀계수(, ) 결정 방법을 나타낸다.
여기서, (일)은 성토 완료 직후 시점, (m)은 (일)에서의 침하량, 와 는 쌍곡선 회귀계수를 나타내며 (일)와 (m)는 예측 시점과 예측 침하량이다.
Asaoka(1978)는 Mikasa(1963)에 의해 유도된 압밀 방정식을 이용하여 장래침하량 및 최종침하량을 산정하는 새로운 방법을 제시하였다. Asaoka법을 통한 침하예측은 식 (2)를 따르며, 본 기법을 이용해 침하를 예측하기 위해서는 일정 시간 간격()의 결정이 필요하다. Fig. 4(a)는 대 관계를 이용한 Asaoka 회귀계수(, ) 결정 방법을 나타낸다.
여기서, (일)은 성토 완료 직후 시점, (m)는 (일)에서의 침하량, (일)은 시간 간격, 와 는 Asaoka법 회귀계수를 나타내며 (일)와 (m)는 예측 시점과 예측 침하량이다.
Kwak et al.(2022)은 기존 쌍곡선법의 한계점을 보완하기 위해 가중 비선형 회귀 쌍곡선법(Weighted nonlinear, WN Hyperbolic)을 제시하였다. 본 기법에서는 초기 침하 계측 결과가 부정확하다는 점(과잉간극수압의 소산 등)과 최근 측정된 침하 계측 결과가 더 중요한 정보를 포함하고 있다는 가정하에 최소자승법(least square method)을 적용하여 최신 데이터에 더욱 높은 가중치를 부여할 수 있도록 하였다. 식 (3)과 식 (4)는 제시된 가중치 부여 비선형 회귀 분석방법과 가중치 함수식을 나타낸다.
여기서, 와 는 쌍곡선법 회귀계수, (일)는 최종성토 완료 이후부터의 날짜, (m)는 (일)에서의 침하량, 는 가중치 함수를 나타내며 (일)은 최종성토 완료 이후 마지막 계측날짜이다.
3.2 딥러닝 모델
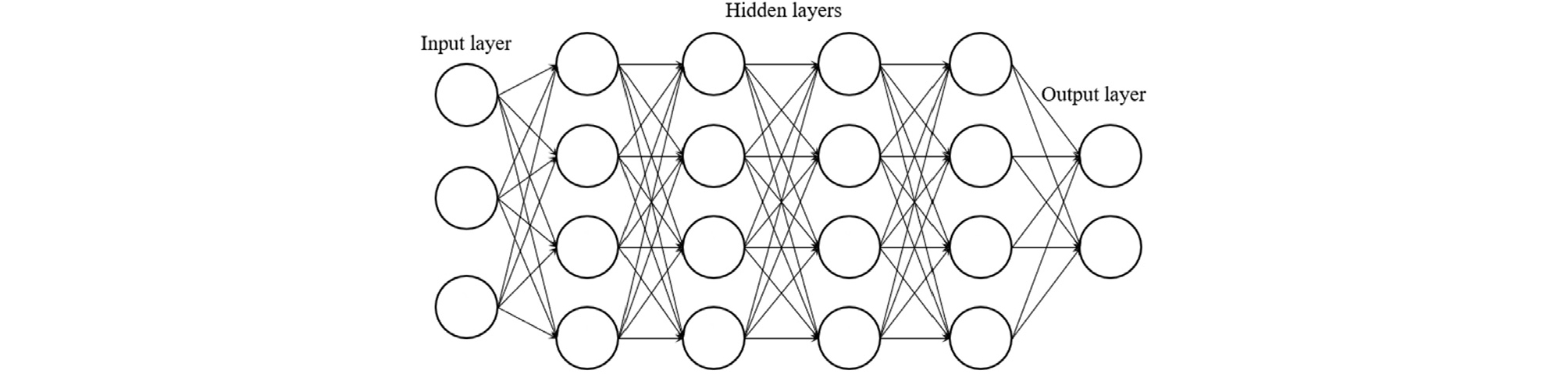
머신러닝은 컴퓨터가 데이터를 통해 학습하고, 명시적으로 프로그래밍하지 않고도 경험을 통해 개선되는 인공지능(AI)의 한 분야이다. 딥러닝은 머신러닝의 한 분야로, 기존 머신러닝 기법을 더욱 발전시킨 형태이다. Fig. 5는 대표적인 인공신경망(ANN)의 구조를 나타내며 네트워크는 입력층, 은닉층, 출력층으로 구성된다. 입력값은 초기 데이터를 받아들이고, 은닉층에서는 가중치와 활성 함수를 통해 데이터를 처리하면서 패턴을 학습한다. 최종 예측값은 출력층에서 산출되며, 이는 실제 결과와 비교하여 학습이 수행된다. ANN의 구조는 다양한 문제에 적응할 수 있는 유연성을 가지며, 특히 비선형 문제해결에 효과적이다.
ANN의 한 종류인 순환신경망(RNN)은 데이터를 순차적으로 다룰 수 있는 특성을 가지며, 시간이나 순서에 따른 데이터 패턴을 학습하는 데 적합하다. Figs. 6(a)와 (b)는 순환신경망(RNN)의 한 종류인 LSTM과 GRU 구조를 나타낸다. RNN은 순차 다루는 인공신경망으로, 언어 변환, 자연어처리, 음성 인식, 이미지 캡션 등 다양한 문제해결에 널리 사용된다(Rumelhart et al., 1986). LSTM은 RNN의 한계였던 기울기 소실(Vanishing gradients) 문제를 극복하기 위해 개발된 모델로, 중요한 정보만을 선택적으로 기억하며 긴 시퀀스(Sequence)에서도 우수한 성능을 발휘한다(Hochreiter, 1997). LSTM은 셀 상태(Cell state)를 통해 데이터를 효과적으로 전달하지만, 복잡한 구조로 인해 많은 파라미터를 가지게 되어 데이터가 충분하지 않을 경우 과적합의 위험이 있다.
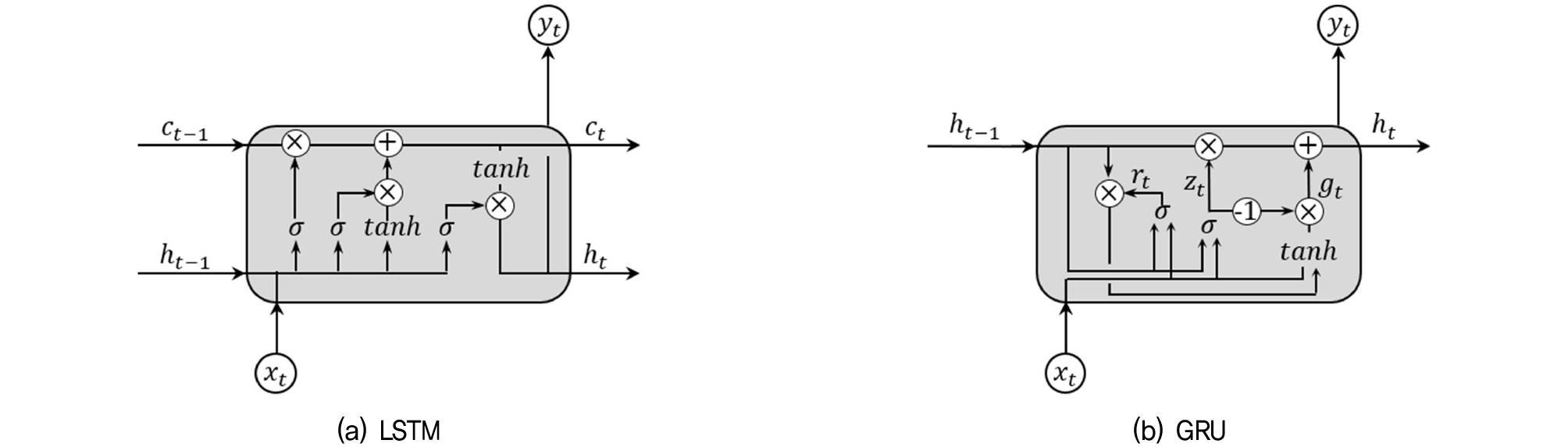
GRU는 이러한 LSTM의 복잡성을 줄이기 위해 개발된 모델로, 망각 게이트(Forget gate)와 입력 게이트(Input gate)를 하나의 갱신 게이트(Update gate)로 통합하여 단순화된 구조를 갖는다(Cho, 2014). GRU는 셀 상태와 셀 출력상태를 통합하여 연산 비용을 줄였으며, LSTM과 유사한 성능을 유지하면서도 더 적은 파라미터가 필요하다. 이러한 이유로 GRU는 연산 효율성을 높이면서도 높은 성능을 보여주는 모델로 평가받고 있다(Chen et al., 2023b).
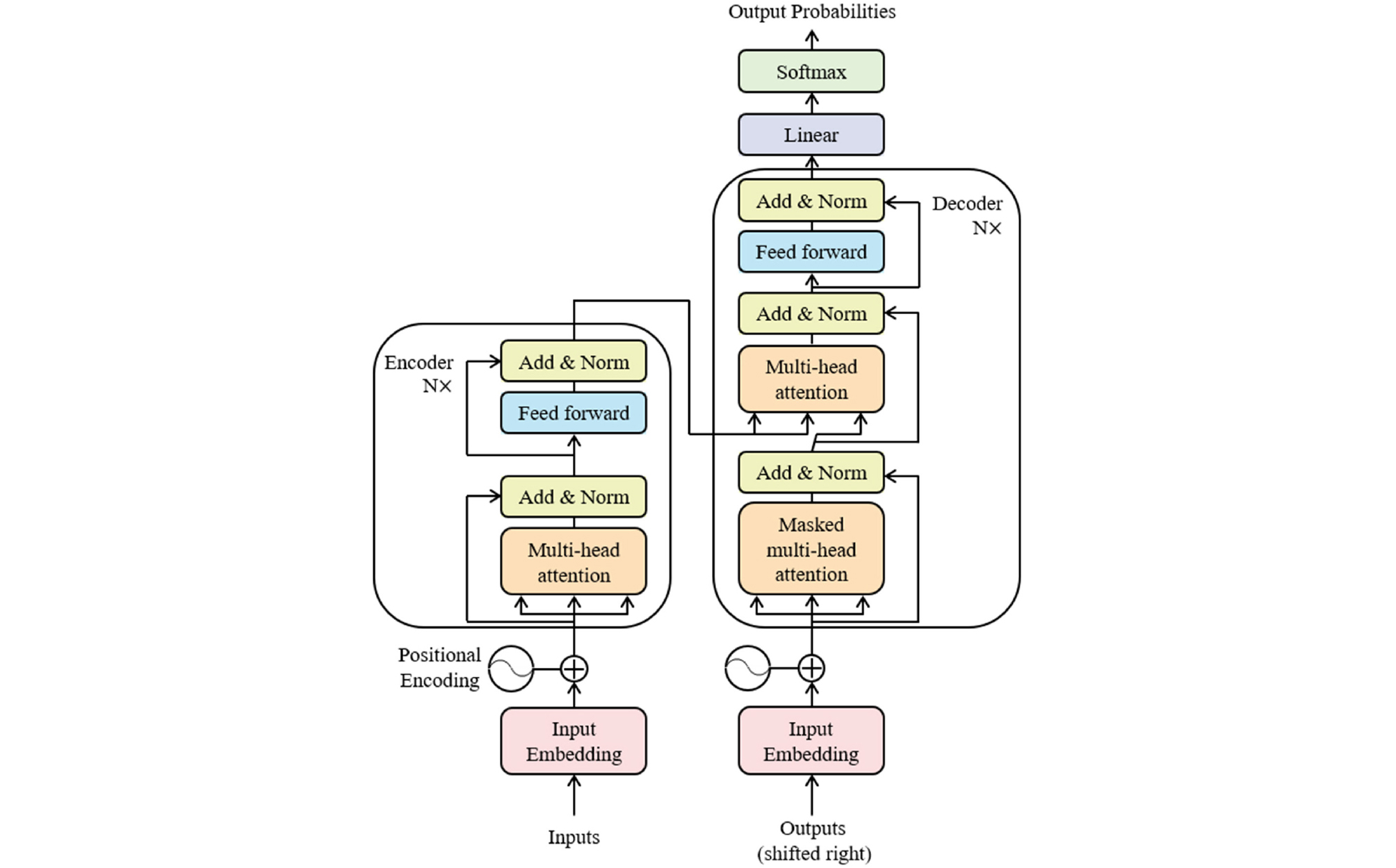
Transformer는 Vaswani(2017)이 제안한 모델로, 기존의 RNN 대신 인코더-디코더 구조를 활용해 자연어처리 분야에서 높은 성능을 보였다. 특히 병렬 처리 능력 덕분에 학습 속도와 효율성에서 큰 이점을 갖는다. Fig. 7은 Transformer의 구조를 보여주며, 입력값은 인코더(Encoder)로 전달되어 포지셔널 인코딩(Positional encoding)과 결합된다. 인코더는 행렬 연산을 통해 입력 간의 관계를 동시에 계산하여 어텐션 벡터를 생성하고, 이는 디코더(Decoder)로 전달되어 최종 출력값을 생성한다. 트랜스포머는 셀프 어텐션(Self-Attention) 메커니즘을 사용해 입력 간의 상관관계를 효과적으로 학습하며, 순차 계산에 의존하지 않아 긴 시퀀스에서도 효율적이다.
3.3 딥러닝 기반 침하예측 모델 구축
본 연구에서는 연약지반 침하예측을 위해 4개의 딥러닝 기반 모델(ANN, LSTM, GRU, Transformer)을 구축하였고 각 모델은 계측된 침하량을 이용해 장래침하량을 예측하도록 설계되었다. 딥러닝 모델들은 학습/검증/예측 데이터의 구분, 데이터 전처리, 그리고 하이퍼파라미터 최적화를 통해 구축되었다.
첫 번째 단계에서는 Table 2의 학습량 기준에 따라 각 지표침하판의 계측결과를 학습, 검증, 예측 데이터셋으로 구분하였다. 이를 통해 98개의 지표침하판에 대해 각각 4가지 조건을 적용하여, 총 392개(98 × 4)의 데이터셋이 생성되었다.
Table 2.
Test cases according to training and validation range
이후, 선형회귀 모델을 사용해 각 데이터셋을 1일 간격으로 재구성하고, 식 (5)를 통해 min-max 정규화를 적용하였다. 이로 인해 학습 및 검증 데이터는 0에서 1 사이의 값으로 변환되었고, 예측 데이터는 1 이상의 값으로 변환되었다.
여기서, 는 정규화 이전의 값, 과 는 학습과 검증 데이터 내 의 최소 최대값을 나타내며, 은 정규화된 값이다.
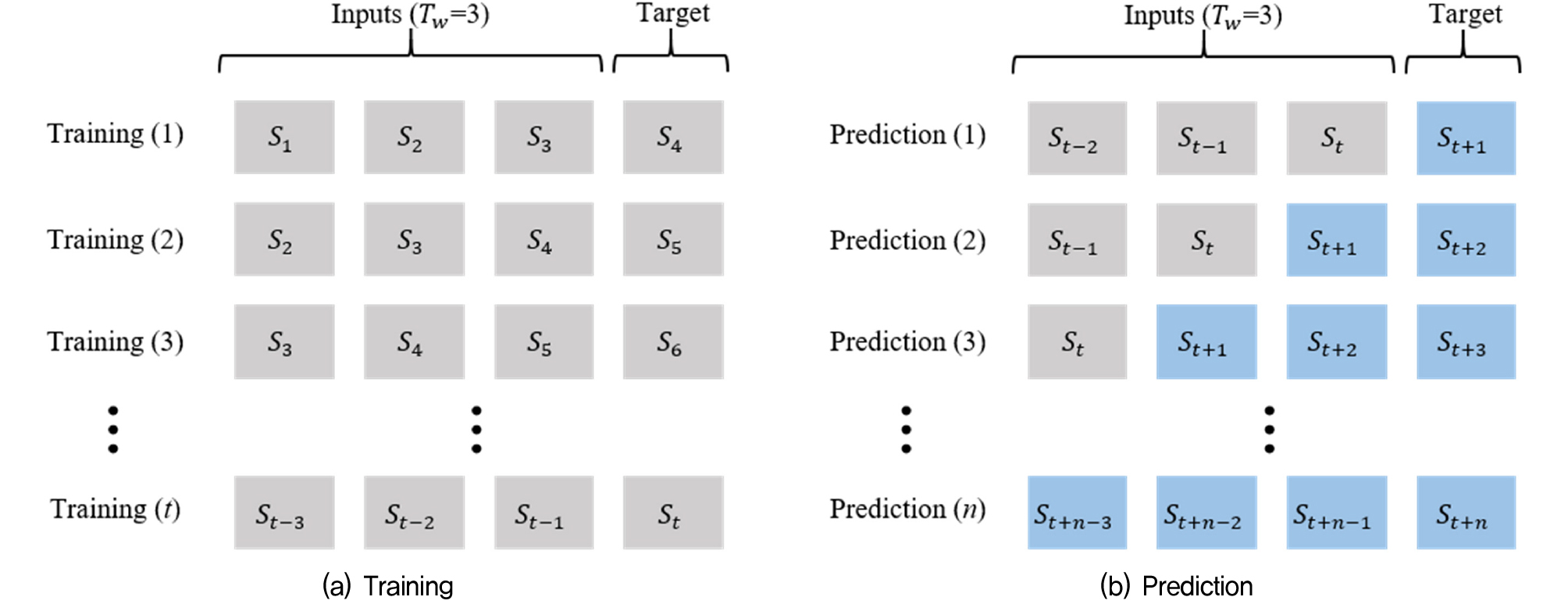
정규화 이후 전체 데이터는 Fig. 8과 같이 시계열 윈도우(Time window, )에 따라 재구성되었다. Fig. 8(a)는 =3으로 가정된 것이며, 이는 3개의 침하 계측 이력이 1개의 장래침하량을 학습하는데 사용된 것을 나타낸다. 학습 데이터의 마지막 세트는 Fig. 8(b)와 같이 장래침하량()을 예측하기 위한 입력값으로 사용된다. 첫 번째 예측 후 예측된 을 입력값으로 적용하여 데이터 세트를 재구성한 다음, 을 예측하기 위한 다음 입력값으로 사용된다. 상기 과정을 반복함으로써 딥러닝 기반 예측 모델들은 반복적으로 침하를 예측할 수 있으며 결론적으로 장기예측을 수행할 수 있다.
본 연구에서는 하이퍼파라미터를 선정하기 위해 격자 탐색 기법(Grid search)을 적용했다. 딥러닝 모델에서 하이퍼파라미터는 학습 알고리즘을 제어하며 모델 성능에 큰 영향을 미치고 모델이 학습하는 과정에서 갱신되지 않으므로 모델 정확도 평가에 앞서 최적화 과정을 거쳐야 한다. 이를 위해, Table 2에 제시된 학습 일수와 지표침하판 별로 구분된 계측 DB의 모델 조건(392개)을 학습하였다. 각 조건별 검증 오차(Validation loss)는 식 (6)을 사용해 평균 제곱근 오차(Root mean squared error, RMSE)로 산정하였으며, 전체 조건에 대한 평균 결과를 바탕으로 모델 성능을 평가하였다. 최종적으로, 평균 검증 오차가 가장 낮은 모델을 최적의 모델로 선정하였다.
여기서, 은 데이터 개수, 와 는 실측값과 예측값이다.
Table 3과 Table 4는 침하예측을 위한 ANN, LSTM, GRU, 그리고 Transformer의 최적 하이퍼파라미터 조합을 나타낸다. ANN 모델은 512-256-256의 은닉층 구조를 가지며, 학습률은 0.001, 활성 함수는 tanh, 그리고 는 2로 결정되었다. LSTM 모델은 256-256-128-32의 은닉층 구조를 사용하며, 학습률은 0.001, 활성 함수는 tanh, 는 2로 결정되었다. 모든 신경망 기반 모델은 Adam 옵티마이저를 사용하였다. Transformer 모델은 8개의 인코더 레이어, 64개의 임베팅 차원, 8개의 어텐션 헤드, 128개 MLP 네트워크로 구성되었으며, 학습률은 0.0001, 배치 크기는 4로 설정되었다. 옵티마이저는 다른 신경 모델들과 동일하게 Adam이 적용되었다. 모든 모델에 대해 epoch는 따로 설정하지 않고 early stopping 기법을 적용하여, 검증 손실이 20회 연속으로 개선되지 않을 경우 학습을 중단하도록 하였다. 이를 통해 과적합을 방지하고 최적의 성능을 얻을 수 있도록 하였다.
4. 침하예측 결과
본 연구에서는 부산항 신항 4개 현장에 설치된 98개의 지표침하판 계측결과와 7개의 침하예측 기법들을 이용하여 침하예측을 수행하고 정확도를 비교·분석하였다. 침하예측은 Table 2에 따라 수행되었으며 Case 1부터 4까지 학습 및 회귀 데이터양을 60일에서 150일까지 30일 간격으로 증가시키며 수행하였다. 계측기반 침하예측 기법들은 학습과 검증 데이터셋을 모두 활용해 침하예측을 하였다. 딥러닝 기반 침하예측 모델들은 침하예측 결과의 재현성을 확인하기 위해 조건별로 30회 반복 학습 및 예측을 수행하였다.
Fig. 9는 B 현장에서 계측된 지표침하판 데이터를 활용하여 기법별 데이터 사용량에 따른 침하예측 결과를 나타낸다. Fig. 9(a)는 0-60일간의 계측 이력을 활용(Case 1)한 침하예측 결과이며 LSTM 모델이 RMSE = 1.3cm 가장 정확한 예측을 수행하였고 이와 반대로 ANN 모델이 RMSE = 17.0cm로 장래침하량을 과소평가하였다. 0-90일간의 계측 이력을 활용한 Fig. 9(b)에서도 LSTM 모델의 정확도가 RMSE = 1.1cm 가장 높았으며 ANN 모델의 예측 정확도가 RMSE = 16.2cm로 가장 낮았다.
Fig. 9(c)는 0-120일간의 계측 이력을 활용한 침하예측 결과를 나타낸다. 본 조건에서도 LSTM 기법의 침하예측 정확도가 RMSE = 1cm로 가장 높은 것을 평가되었으나 가중 비선형 회귀 쌍곡선법과 쌍곡선법이 RMSE = 2cm로 유사한 정확도를 보였다. 반면, GRU 모델과 Transformer 모델은 침하를 과대 예측하였고 ANN 모델과 Asaoka법은 과소 예측하였다. Fig. 9(d)는 150일간의 계측 이력을 활용한 결과이며, 본 조건에서는 7개 예측기법 모두 3cm 이하의 오차가 발생하였다.
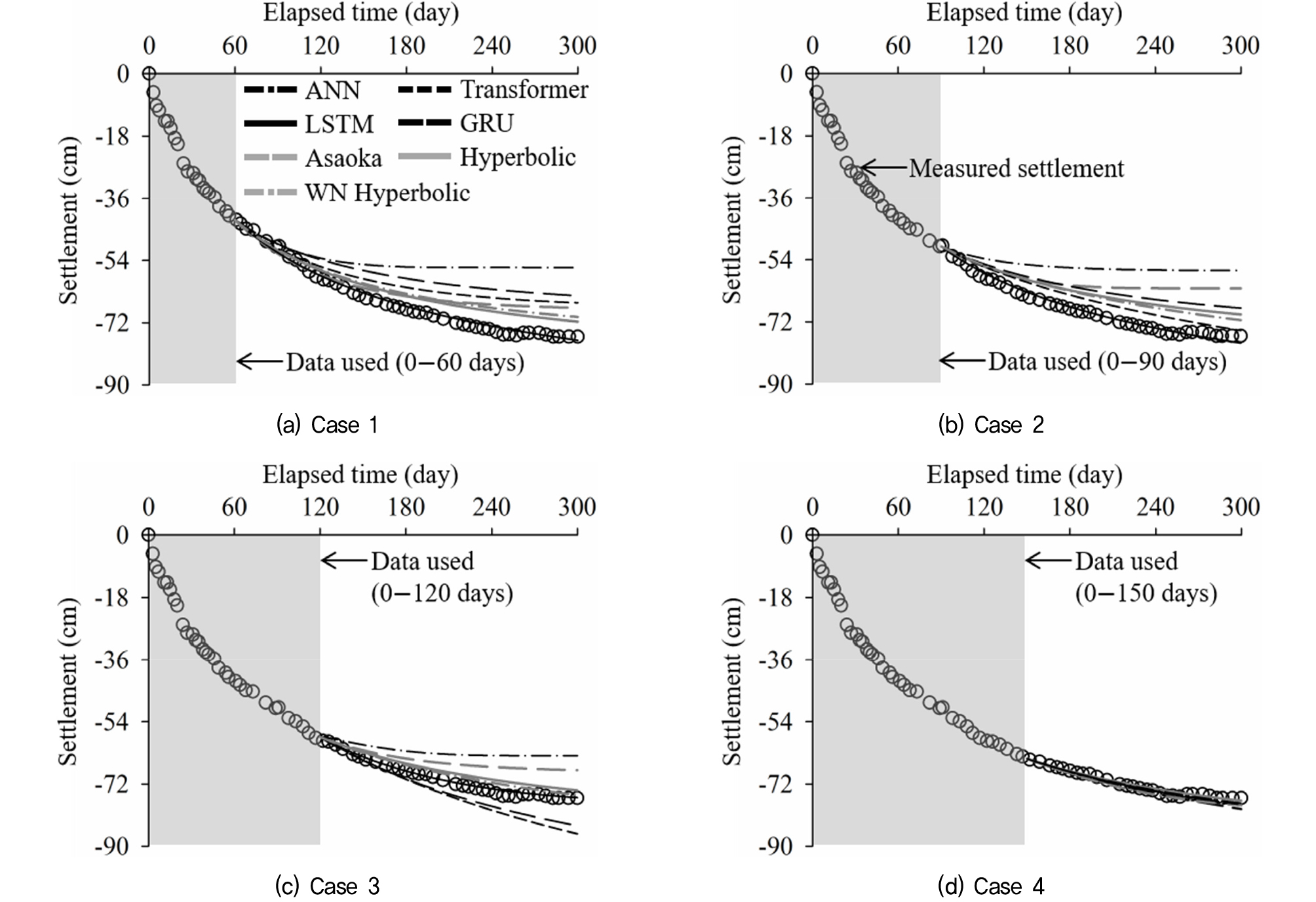
Fig. 10과 Table 5는 다양한 학습 및 회귀 일수에 따른 기법별 평균 RMSE 값을 나타낸다. 본 연구에서는 평균 제곱근 오차(RMSE)를 통해 예측 정확도를 평가하였다.
Table 5.
Prediction accuracy according to prediction methods
Fig. 10(a)에서 볼 수 있듯이, 0-60일간의 데이터를 사용할 경우, 가중 비선형 회귀 쌍곡선법의 오차가 17.1cm로 가장 작았으며, 딥러닝 모델들과 기존 침하예측 기법들이 그 뒤를 따랐다. 기존 침하예측 기법(쌍곡선법, Asaoka법)은 25cm 이상의 높은 오차를 보였고, 딥러닝 기반 모델들은 평균적으로 약 20cm의 오차를 나타냈다. 부산항 신항의 현장 조건에서 가중 비선형 회귀 쌍곡선법은 기존 침하예측 기법들보다 32% 더 정확했으며, 딥러닝 모델들에 비해서도 평균 15% 더 우수한 성능을 보였다.
Fig. 10(b)에서는 0-90일간의 데이터를 사용할 경우, 앞선 60일 학습 및 회귀 조건에 비해 모든 기법들의 정확도가 평균적으로 44% 향상되었고, 특히 GRU 모델의 정확도 향상이 52%로 가장 컸다. 이 조건에서 GRU 모델과 가중 비선형 회귀 쌍곡선법의 오차가 가장 작게 평가되었으며, 기존 침하예측 기법들보다 35%와 41% 더 정확한 결과를 나타냈다.
Fig. 10(c), 0-120일 학습/회귀 조건에서도 가중 비선형 회귀 쌍곡선법의 정확도가 가장 높은 것으로 평가되었으나 GRU 모델과의 차이가 0.2cm로 매우 작았다. 이 조건에서는 모든 예측 기법들이 평균적으로 10cm 미만의 오차를 기록하여 앞선 조건들에 비해 상대적으로 높은 정확도를 제공하였다.
0-150일의 데이터를 사용한 Fig. 10(d)의 조건에서는 가중 비선형 회귀 쌍곡선법과 딥러닝 기반 모델 모두 5cm 이하의 오차를 보였으며 쌍곡선법과 Asaoka법은 7.5cm 이하의 오차를 나타냈다. 분석 결과, 쌍곡선법과 Asaoka법은 0-150일간의 계측 데이터를 활용하더라도 가중 비선형 회귀 쌍곡선법과 딥러닝 모델들보다 예측 정확도가 낮은 것으로 확인되었으며, 최신 기법을 적용하면 기존 기법 대비 약 30일 이른 시점에서 보다 정확한 침하예측이 가능한 것으로 판단된다.
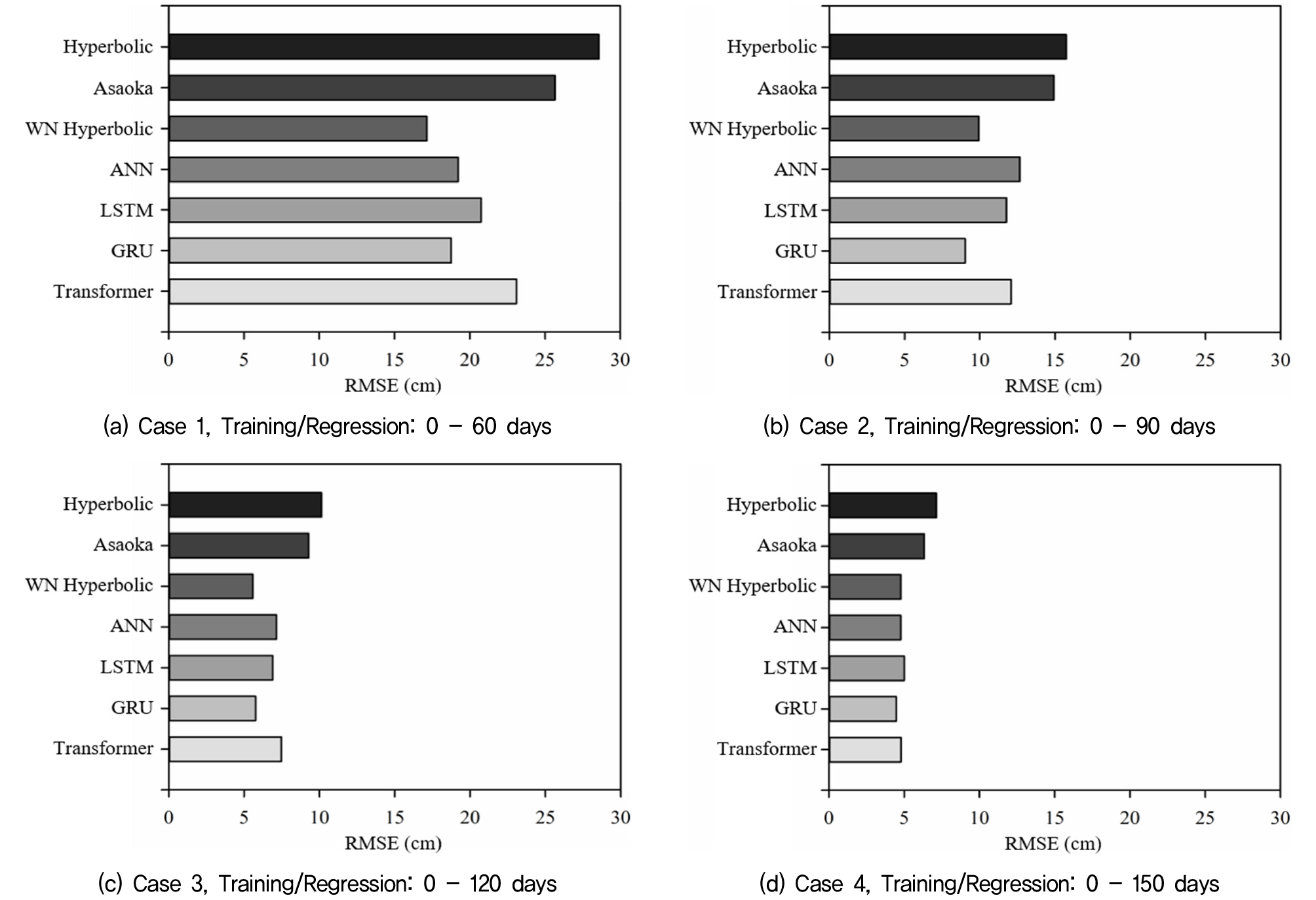
Fig. 11은 다양한 침하예측 기법들의 RMSE 분포를 각 학습 및 회귀 조건에 따라 보여준다. Fig. 11(a)에서 기존 침하예측 기법들은 넓은 RMSE 분포를 나타내어 예측 결과의 불확실성이 큰 반면, 딥러닝 기반 모델들은 좁은 RMSE 분포를 보여 높은 예측 정확도를 보인다. 가중 비선형 회귀 쌍곡선법은 평균적으로 가장 정확한 결과를 제공하지만, 딥러닝 모델들에 비해 다소 넓은 RMSE 분포를 가진다. Fig. 11(b)에서는 0-90일간의 데이터를 사용했을 때, 데이터 사용량이 증가함에 따라 모든 기법의 RMSE 분포가 좁아져 예측 정확도가 개선되었음을 알 수 있다. 기존 기법들도 RMSE 분포가 좁아졌지만, 여전히 딥러닝 모델과 가중 비선형 회귀 쌍곡선법에 비해 정확도가 낮게 평가되었다. Fig. 11(c)와 (d)에서는 데이터 사용량이 120일과 150일로 증가하면서 모든 기법에서 RMSE 분포가 더욱 좁아져 예측 정확도가 높아지는 양상을 보였다.
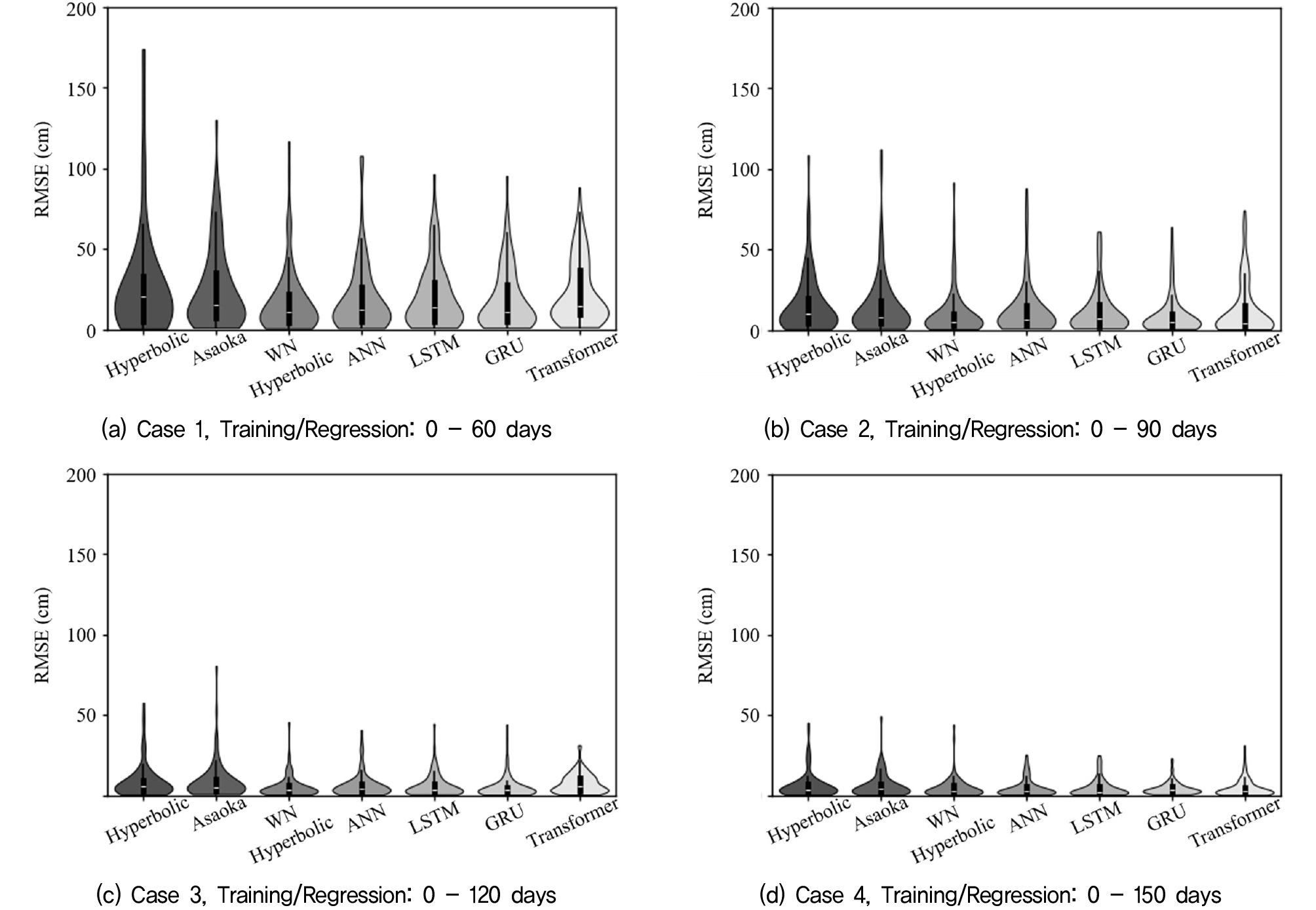
다양한 기법들을 종합적으로 분석한 결과, 전체 조건에서 가중 비선형 회귀 쌍곡선법과 딥러닝 기반 모델들이 전반적으로 우수한 예측 정확도를 보였다. 특히, 가중 비선형 회귀 쌍곡선법은 평균적으로 가장 낮은 RMSE 값을 기록하여 다양한 데이터 조건에서도 안정적인 성능을 나타냈다. 딥러닝 모델 중에서는 LSTM과 GRU가 뛰어난 예측 정확도를 보였으며, 학습 데이터가 증가할수록 기존 예측 기법들에 비해 정확도가 크게 향상되었다. 반면, 쌍곡선법과 Asaoka법은 예측 성능이 상대적으로 낮았으며, 특히 짧은 기간의 데이터를 활용하는 경우 불확실성이 큰 것으로 평가되었다. 이러한 결과는 최신 기법을 적용함으로써 기존 기법 대비 예측 정확도와 신뢰성을 크게 향상시킬 수 있음을 시사하며, 특히 가중 비선형 회귀 쌍곡선법과 LSTM, GRU와 같은 기법들이 실제 현장에서 다방면으로 가장 우수한 예측 성능을 제공할 수 있을 것으로 판단된다.
5. 결 론
본 연구에서는 다양한 계측기반 침하예측 기법들과 딥러닝 기반 침하예측 모델들의 정확도를 비교 분석하였다. 이를 위해 4개의 딥러닝 알고리즘(ANN, LSTM, GRU, Transformer)과 3개의 계측기반 침하예측 기법(쌍곡선법, Asaoka법, 가중 비선형 회귀 쌍곡선법)이 적용되었다. 부산항 신항 내 위치한 98개 지표침하판 계측자료를 활용해 학습 일수에 따라(60일, 90일, 120일, 150일) 총 392개 조건 아래 침하예측을 수행하고 정확도를 평가하였다. 이를 통해 다음과 같은 결론을 얻을 수 있었다.
(1) 가중 비선형 회귀 쌍곡선법과 GRU 모델은 모든 조건에서 전반적으로 가장 높은 예측 정확도를 나타내었고 특히, 짧은 학습/회귀 기간(60일, 90일)에서도 뛰어난 성능을 보였다. 계측 데이터 사용 기간이 증가할수록 모든 기법의 예측 정확도가 향상되었으며, 150일간의 데이터를 사용할 경우 모든 기법에서 3cm 이하의 오차를 달성하여 정확한 예측 결과를 제공하였다.
(2) 딥러닝 기반 모델들은 기존 침하예측 기법(쌍곡선법, Asaoka법)과 비교해 RMSE 분포가 좁아 예측 결과의 일관성과 정확도가 높았다. 특히, LSTM과 GRU 모델은 데이터 양이 증가함에 따라 예측 성능이 크게 개선되었고, 가중 비선형 회귀 분석 함께 높은 정확도를 기록하였다. 최신 기법을 적용할 경우, 기존 기법에 비해 약 30일 더 이른 시점에 정확한 침하예측이 가능할 것으로 분석되었다.
본 연구는 딥러닝을 활용하여 연약지반 침하예측의 정확도를 크게 향상시킬 수 있음을 입증하였다. 특히 GRU와 LSTM 모델은 짧은 데이터 계측 기간에도 기존 기법 대비 높은 예측 정확도를 보여, 실제 공사 현장에서 신속한 의사결정을 지원할 수 있는 가능성을 제시하였다. 이는 시간과 비용 절감은 물론, 연약지반에서 발생할 수 있는 구조물 손상 예방에 기여할 수 있다.
또한, 본 연구는 국내 연약지반 조건에서 다양한 침하예측 기법을 적용하여 비교·분석하였다는 점에서 의의가 있으나, 부산항 신항이라는 단일 지역의 데이터만 사용했다는 한계가 있다. 향후 연구에서는 다양한 지역과 지반 조건에서의 침하 계측 데이터를 수집하여 기법들을 검증하고, 딥러닝 모델의 최적화 및 하이퍼파라미터 튜닝을 통해 예측 성능을 더욱 개선할 필요가 있을 것으로 판단된다. 또한, 향후 연구에서는 본 기법을 다양한 지역 및 지반 환경에서 검증하고, 실시간 데이터를 활용한 온라인 학습 모델로 확장하여 현장 적용성을 더욱 높이는 방향으로 나아가야 할 것이다.
