

1. 서 론
2. DEM 해석 프로그램
2.1 LAMMPS
2.2 LAMMPS 버전 및 컴파일러
3. 하드웨어 및 운영환경
3.1 하드웨어 구성
3.2 운영체계, 플러그인 및 해석결과 시각화
4. 해석모델
5. 해석 최적화
5.1 병렬 확장성 평가: MPI 프로세서 수(rank) 변화에 따른 시뮬레이션 성능 분석
5.2 하드웨어 가속옵션의 평가
5.3 AMD CPU
5.4 동적부하균형(DLB, Dynamic Load Balancing)
5.5 평가결과
6. 결 론
1. 서 론
사질토 지반의 응력-변형율 거동특성은 개별토립자간의 상호작용에 의해 나타나는 현상이다. 이러한 개별 요소간의 상호작용에 관한 수치적인 풀이 방법은 Cundall과 Stack(Cundall and Stack, 1979)에 의해 1979년 최초 제안되어 개별요소법(Discrete Element Method, DEM)의 형태로 발전되어 왔다. DEM해석은 개별 입자 간의 접촉 여부를 판단 후, 접촉 시 탄성 거동 및 마찰에 의한 미끄러짐을 운동 방정식을 통해 계산하고, 시간에 따른 입자의 변위를 누적하여 개별입자의 거동을 풀이한다. 해석 대상 입자의 수가 증가할수록 입자간의 접촉 판단에 필요한 연산량이 기하급수적으로 증가하며, 시간적분 간격도 감소하게 되어 전체 연산 시간이 크게 늘어나는 특징이 있다. 특히, 강성이 크고 질량이 작은 흙입자일 수록 안정된 해를 도출하기 위한 시간적분 간격이 극단적으로 짧아지며, 해석공간 내 위치하는 입자의 수와 함께 증가하는 자유도의 수는 DEM해석의 연산량을 증가시키는 주요 원인이다. 이러한 제약사항으로 인하여 2000년대 초반까지 사질토 지반의 응력-변형률 거동에 대한 수치해석적인 접근 방법은 연속체역학 기반의 유한요소법(Finite Element Method, FEM) 또는 유한차분법(FInite Difference Method, FDM)을 활용하는 것이 일반적이였으며, 일부 DEM해석을 이용한 사질토 시료의 실내시험 시뮬레이션은 모델의 크기를 극단적으로 축소시키거나 사질토 입자의 형상을 단순화 하여 수행되었다(Kuhn et al., 2014).
그러나, 최근들어 컴퓨터 중앙처리장치(CPU)의 연산효율을 극대화 하기 위한 병렬 프로그래밍 기법이 실용화 되면서 DEM을 이용한 사질토 지반의 거동해석이 다시 주목받고 있다. DEM 해석의 병렬 처리를 위한 프로그래밍은 공유 메모리 기반의 OpenMP(OpenMP Architecture Review Board, n.d., 이하 OMP), 분산 메모리 기반의 OpenMPI 및 MPICH(Open MPI Project, n.d.; MPICH Project, n.d., 이하 MPI), 그리고 GPU를 활용한 범용 계산(GPGPU: General-Purpose computing on Graphics Processing Units, Owens et al., 2007)으로 발전하고 있다. 이들은 사용되는 하드웨어의 특성과 메모리 구조에 따라 구분된다. 위에서 설명된 병렬처리 기법은 고유한 장점과 한계를 지니고 있기 때문에, 현 시점에서 DEM 해석 기법의 최종적인 발전 방향을 단정짓는 것은 이르다고 할 수 있다. 이에 더하여 실제 사질토 입자의 형상을 어떻게 이상화할 것인지, 그리고 그에 따른 입자 간 접촉 판단 알고리즘을 어떻게 최적화할 것인지에 대한 연구도 활발히 진행되고 있다(O’Sullivan, 2017; Zhao et al., 2023).
따라서, 현실적인 DEM 해석을 위한 핵심과제는 해석시간의 단축이며, 이는 하드웨어 및 소프트웨어의 최적화 전략에 크게 의존한다. 예를 들어, 해석을 효율를 통해 10일이 소요되는 해석시간을 7일로 단축 가능하다면, 동일 해석모델을 이용한 매개변수해석을 10회 수행하는 경우 해석시간을 무려 30일 단축할 수 있는 효과를 기대할 수 있다. 따라서 실내 실험에 사용되는 시료의 크기로 사질토 입자의 거동을 DEM해석으로 시뮬레이션하기 위해서는 고성능 컴퓨팅(High Performance Computing, HPC) 기법을 적절히 활용함으로써 해석 효율을 극대화 하는 것이 필요하다. 2015년 Berger 등(Berger et al., 2015)은 DEM 해석 프로그램인 LIGGGHTS(DCS Computing GmbH., LIGGGHTS, n.d.)의 동적 부하 분산(Dynamic Load Balancing) 알고리즘 개발 과정을 발표하고, 128코어를 갖는 AMD Opteron 기반 클러스터를 활용하여 병렬 해석 기법별 OMP, MPI, 그리고 Hybrid(OMP+MPI) 구성에 따른 해석 시간 단축 효과를 분석하였다. 이 연구에 따르면, MPI 기반 병렬 확장의 성능이 일정 수준 이상 향상되지 않을 경우, 잔여 컴퓨팅 자원을 활용한 Hybrid 병렬 해석 기법을 통해 해석 시간을 추가로 단축할 수 있음을 확인하였다. 다만, DEM 해석의 병렬 효율은 해석 모델의 특성 및 사용되는 하드웨어 자원에 따라 최적 조건이 달라지므로, Berger 등의 연구 이후 약 10년간 급속히 발전해온 중앙처리장치(CPU) 아키텍처와 병렬 연산 라이브러리 개선을 반영한 재평가가 필요하다. 이에 본 연구에서는 DEM 해석의 병렬 처리 최적화를 위한 벤치마크 테스트를 수행하였으며, 하드웨어 구성 조건, 연산 가속 효과, 병렬 확장성(Scalability)을 중심으로 성능을 평가하였다(HPC Wiki, n.d.).
본 연구에서 사용된 DEM 해석 프로그램은 LAMMPS(Thompson et al., 2022)이며, 운영체제는 Ubuntu Server(Canonical Ltd., n.d.)를 기반으로 하였다. 해석용 워크스테이션은 HP사의 시스템으로, 두 개의 Intel Xeon Gold 6252 CPU(총 48코어, 96스레드)와 4개의 비균일 메모리 접근구조(Non Uniform Memory Acess, NUMA) 노드를 갖춘 구성이다(Wikipedia, NUMA, n.d.).
벤치마크 테스트에 사용된 해석 모델은 한 변의 길이가 2cm인 상부 개방형 정육면체 용기 내부에 직경 1mm의 비정형 사질토 입자를 자유 낙하시켜 시료를 조성하는 DEM모델이다.
2. DEM 해석 프로그램
현재 DEM해석을 기반으로 개발된 다양한 시뮬레이션 프로그램들이 병렬해석을 지원하고 있다. 대표적으로, OMP를 지원하는 PFC(Itasca consulting group, n.d.), YADE(Angelidakis et al., 2024), MPI를 지원하는 LIGGGHTS(Kloss et al., 2012), ESyS-Particle(Wang and Mora, 2009), 그리고 GPGPU를 지원하는 RockyDEM(ANSYS, inc., n.d), MUSEN(Dosta and Skorych, 2020), EDEM(Altair Engineering, Inc., n.d), MFIX(Syamlal et al., 1993) 등이 있다. OMP해석은 OMP라이브러리를 활용하며, MPI해석은 OpenMPI 또는 MPICH를 사용한다. GPGPU해석은 하드웨어 제조사에 따라 NVIDIA의 CUDA(NVIDIA, n.d.), AMD의 HIP(ROCm Project, n.d.), Intel의 oneAPI(Intel Corporation, n.d.), 또는 OpenCL(Khronos Group, n.d.)과 같은 다양한 병렬 컴퓨팅 플랫폼을 활용할 수 있다.
일반적으로, DEM해석에서 MPI 및 GPGPU 기반 병렬화가 OMP보다 더 높은 연산 효율성과 확장성을 제공하는 것으로 평가된다. 그러나 병렬화를 위하여 하드웨어의 노드 수를 무한정 증가시키는 것이 항상 성능의 향상을 보장하지는 않는다. 이는 Amdahl의 법칙(Amdahl, 1967)에 따라, 병렬화 비율의 한계와 함께 노드 간 정보 공유 시 발생하는 병목 현상(bottleneck), 오버헤드(overhead), 그리고 메모리 경합(race condition) 등의 문제가 병렬 해석의 효율을 저하시킬 수 있기 때문이다(Fig. 1). 2024년 Dosta 등(Dosta et al., 2024)은 9개의 오픈소스 DEM해석 프로그램에 대한 벤치마크 테스트를 발표하였다. 벤치마크 모델에 한하여 GPGPU기반 DEM해석 속도가 OMP, MPI 기반 해석에 비하여 10배 정도의 효율을 나타냄을 발표하였으나, 벤치마크에 사용된 CPU의 물리코어가 12개로 확장성이 제한적이며, DEM시뮬레이션 중 응력계산 등 CPU자원을 활용하는 절차가 생략되어 있기 때문으로 이들의 벤치마크 결과를 일반화 하기 어렵다 할 수 있다. 최근들어 HPC를 활용한 여러 분야에서 MPI병렬해석을 위한 최적의 노드 수를 결정 후, 여유 CPU자원을 활용한 하이브리드 병렬화 기법이 제안되고 있으며, 대표적으로 Hybrid MPI + OMP 및 MPI + GPGPU 방식이 사용되고 있다. 이를 반영하여 최근의 DEM해석 또한 다양한 병렬해석 기법을 활용한 연산효율 극대화를 목표로하여 해석시간 단축과 해석모델의 대형화를 동시에 달성하는 연구가 진행중이다.
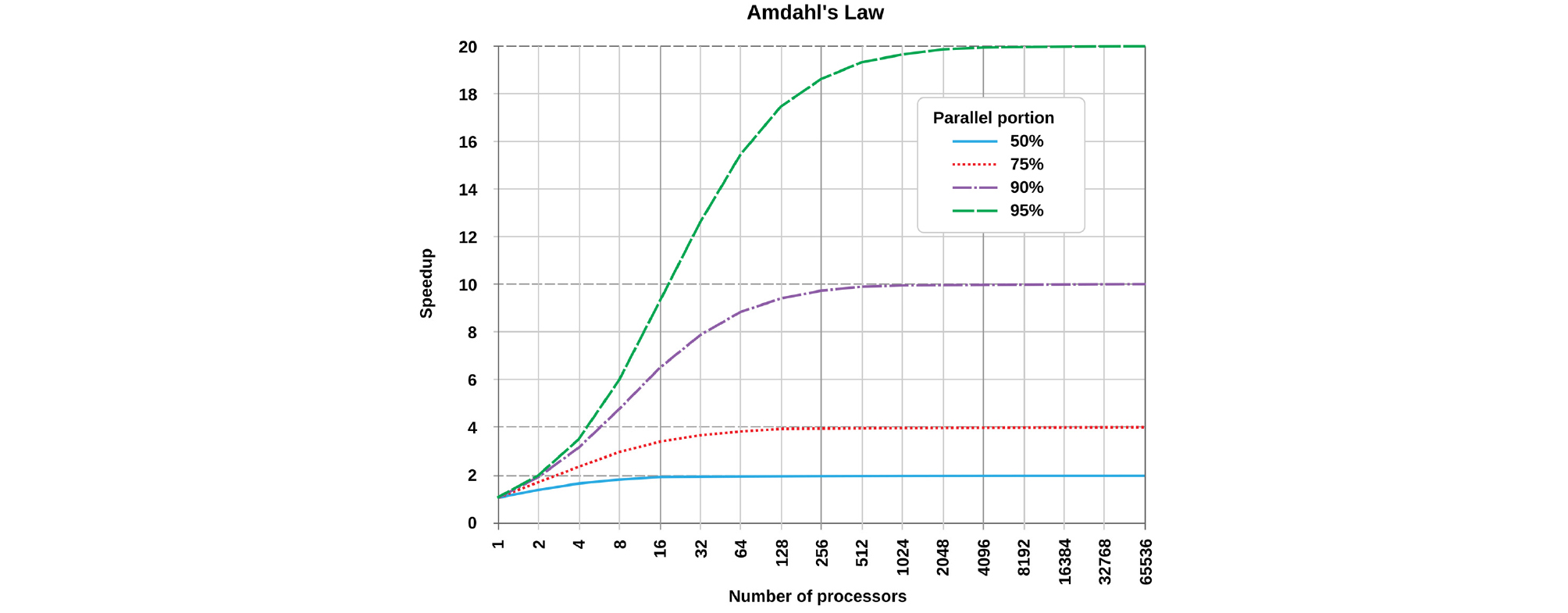
DEM해석의 최적화는 하드웨어 자원(CPU 코어, 메모리 구조, 노드간 고속통신 연결 등)의 활용 뿐만 아니라 컴파일러 최적화, 병렬처리 설정 등 프로그램 실행환경을 정교하게 조정하는 과정 또한 필수적이다. 이에 따라, 본 연구에서는 MPI, OMP, GPGPU병렬 해석을 모두 지원하는 LAMMPS 시뮬레이션 프로그램을 활용하여 하드웨어 확장을 구현하고, 연산 가속 옵션 및 컴파일러 최적화를 적용함으로써 해석효율화와 병렬 확장성에 대한 평가를 수행하였다.
2.1 LAMMPS
LAMMPS(Large-scale Atomic/Molecular Massively Parallel Simulator)는 분자동역학(MD, Molecular Dynamics)의 해석을 위해 개발된 오픈소스 시뮬레이션 소프트웨어로, 액체, 고체, 기체 상태의 입자 집합을 수치모델링하는 데 사용된다. 이 프로그램은 미국 Sandia National Laboratories에서 개발되었으며, 현재까지 활발히 유지·보수되며 기능이 확장·개선되고 있다. LAMMPS는 원자, 고분자, 생체계, 고체분말(금속, 세라믹, 산화물 등), 분체(granular), 거친 입자(coarse-grained)등을 대상으로, 입자간 상호퍼텐셜 함수(힘장: force field 등)와 경계 조건을 토대로 2차원 또는 3차원 공간에서의 거동을 시뮬레이션할 수 있다. 병렬연산을 위한 프로그램 구조가 우수하여 수십억 개의 입자를 포함하는 대규모 시뮬레이션도 처리할 수 있는 확장성을 갖추고 있으며, GROMACS(GROMACS, n.d.)와 함께 분자동역학 분야에서 널리 활용되고 있다. LAMMPS는 분자동역학에 중점을 두고 개발되었으나, 지반공학 및 DEM해석을 위한 granular와 molecule 패키지를 제공하여, 사질토 입자와 같은 비정형 입자 기반의 시뮬레이션에도 활용 가능하다. 그러나 사용환경(OS, Operating System), 컴파일 과정 및 입자모델링 방법이 사용자 친화적이지 않음으로 인하여 DEM해석에는 널리 사용되지 않고 있는 실정이다. 이러한 접근성을 보완하기 위해, 오스트리아의 DCS Computing은 LAMMPS를 기반으로 DEM해석을 위해 파생된 LIGGGHTS(DCS Computing GmbH., LIGGGHTS, n.d.), Aspherix(DCS Computing GmbH., Aspherix, n.d.)를 공개하였다. 그러나 이들 프로그램은 원본인 LAMMPS에 비해 병렬 확장성 측면에서 상대적인 한계를 가진다. LAMMPS는 C++로 개발되었으며 C++11 표준을 따르는 컴파일러를 요구한다. 모든 버전의 소스 코드는 공식 웹사이트 또는 GitHub 저장소를 통해 자유롭게 접근할 수 있다. 객체지향 기반 구조로 설계되어 있어, 사용자 정의 함수, 힘장(pair style), 경계 조건, 진단 기능 등을 손쉽게 추가하거나 수정할 수 있다. LAMMPS는 병렬 계산을 전제로 설계되어 있으며, 단일 노트북이나 데스크톱 환경에서도 실행이 가능하지만, MPI를 활용한 다중 코어 시스템 또는 클러스터 환경에서 실행할 때 가장 높은 성능을 발휘한다. 현재는 멀티코어 CPU 시스템, 클러스터, 슈퍼컴퓨터 등 다양한 하드웨어 환경에서 운용 가능하며, 병렬 처리를 위한 최신 기능들이 지속적으로 업데이트되고 있다. 대표적으로 OMP기반 멀티스레딩, 고급 벡터 명령어 세트인 AVX-512(Wikipedia, AVX-512, n.d.), GPU가속을 이용한 연산 최적화가 지원되며, 최근에는 Kokkos(Kokkos Project, n.d.)와 같이 LLVM(Wikipedia, LLVM, n.d.) 기반 멀티플랫폼 병렬화 라이브러리도 도입되고 있다. 다만, 현시점에서 DEM해석을 위한 Kokkos 가속기능은 지원되지 않는다. LAMMPS를 이용한 DEM해석은 뉴턴의 운동방정식을 기반으로, 시간적분시 Verlet 적분(Wikipedia, Verlet integration, n.d.)이 사용된다. 개별 입자는 원자(atom), 분자(molecule), 전자(electron), 원자 클러스터(cluster of atoms), 또는 거시적인 흙입자(macroscopic clump of material)와 같이 다양한 물리적 단위를 표현할 수 있으며, 입자 간 상호작용은 접촉에 의한 힘의 전달 외에도 화학적 또는 전기적 힘을 포함할 수 있다. 입자간 접촉력은 단거리(short-range) 상호작용으로 모델링되며, 전자기적 상호작용은 장거리(long-range) 상호작용으로 구현된다. 입자 간 상호작용(접촉) 여부는 이웃 리스트(neighbor list)를 통해 추적되며, 시뮬레이션 중 지속적으로 갱신된다. 시뮬레이션 모델은 MPI 기반의 분산 메모리 환경에서 해석 영역 분할(domain decomposition)을 통해 여러 개의 서브도메인(sub-domain)으로 나뉘고, 각 서브도메인은 고유한 프로세스 번호(rank)를 가진 하나의 프로세스에 할당된다. 이후 각 프로세스는 할당받은 서브도메인에 대해 독립적으로 연산을 수행하며, 이를 통해 전체 모델에 대한 병렬 처리가 이루어진다. 프로세스 간 정보 교환은 유령 원자(ghost atoms)를 통해 서브도메인 경계에서의 상호작용 계산이 가능하도록 한다. 여기에 OpenMP(OMP)나 GPU 가속과 같은 하드웨어 가속 기법이 병합될 경우, 시뮬레이션 모델의 유형에 따라 계산 효율을 더욱 향상시킬 수 있다.
2.2 LAMMPS 버전 및 컴파일러
본 논문 작성 시점을 기준으로 공식적으로 배포된 안정화 버전은 stable_29Aug2024_update1이나, 본 연구에서는 개발자 버전인 patch_4Feb2025-105-gaaa81b2576이 사용 되었다. 컴파일러는 Intel OneAPI 툴킷을 사용하였다. 해당 툴킷은 C, C++, Fortran 컴파일러와 함께 MPI, Threading Building Blocks(TBB), Math Kernel Library(MKL) 등을 포함한다. LAMMPS는 make와 CMake 빌드 시스템(Kitware, Inc., CMake, n.d.)을 모두 지원하며, 본 연구에서는 CMake를 이용하여 최적화된 빌드 환경을 구성하였다. 시뮬레이션 대상은 비정형 사질토 입자로, 이를 구현하기 위해 컴파일 옵션으로 granular, rigid, molecule 패키지가 사용되었다. 시뮬레이션 결과의 시각화는 VTK 라이브러리를 활용하여 출력파일을 생성하였다. 하드웨어 가속 효과 비교를 위해 Intel 및 OMP 패키지를 추가하여 컴파일하였으며, 컴파일 최적화는 최대 수준의 최적화 옵션인 -O3과 함께, 2017년 이후 Intel Skylake 아키텍처부터 지원되는 고급 벡터 확장 명령어 세트인 AVX-512(-xCORE-AVX512)가 활성화되도록 설정하였다. 본 논문에서 사용된 LAMMPS의 컴파일 옵션은 다음과 같다.
cmake ../cmake \
-DCMAKE_C_COMPILER=icx \
-DCMAKE_CXX_COMPILER=icpx \
-DCMAKE_Fortran_COMPILER=ifx \
-DCMAKE_C_FLAGS="-O3 -xCORE-AVX512 -fp-model fast -fno-exceptions -funroll-loops -fstrict-aliasing -qopt-report=5 -qopt-report-phase=vec,loop -flto" \
-DCMAKE_CXX_FLAGS="-O3 -xCORE-AVX512 -fp-model fast -fno-exceptions -funroll-loops -fstrict-aliasing -qopt-report=5 -qopt-report-phase=vec,loop -flto" \
-DCMAKE_Fortran_FLAGS="-O3 -xCORE-AVX512 -fp-model fast -funroll-loops -fstrict-aliasing -qopt-report=5 -qopt-report-phase=vec,loop -flto" \
-D PKG_INTEL=yes \
-D PKG_OPENMP=yes \
-D PKG_GRANULAR=yes \
-D PKG_RIGID=yes \
-D PKG_MOLECULE=yes \
-D PKG_PYTHON=yes \
-D PKG_VTK=yes \
-D PKG_EXTRA-FIX=yes \
-D INTEL_ARCH=cpu \
-D INTEL_LRT_MODE=threads \
-D BUILD_SHARED_LIBS=yes \
3. 하드웨어 및 운영환경
3.1 하드웨어 구성
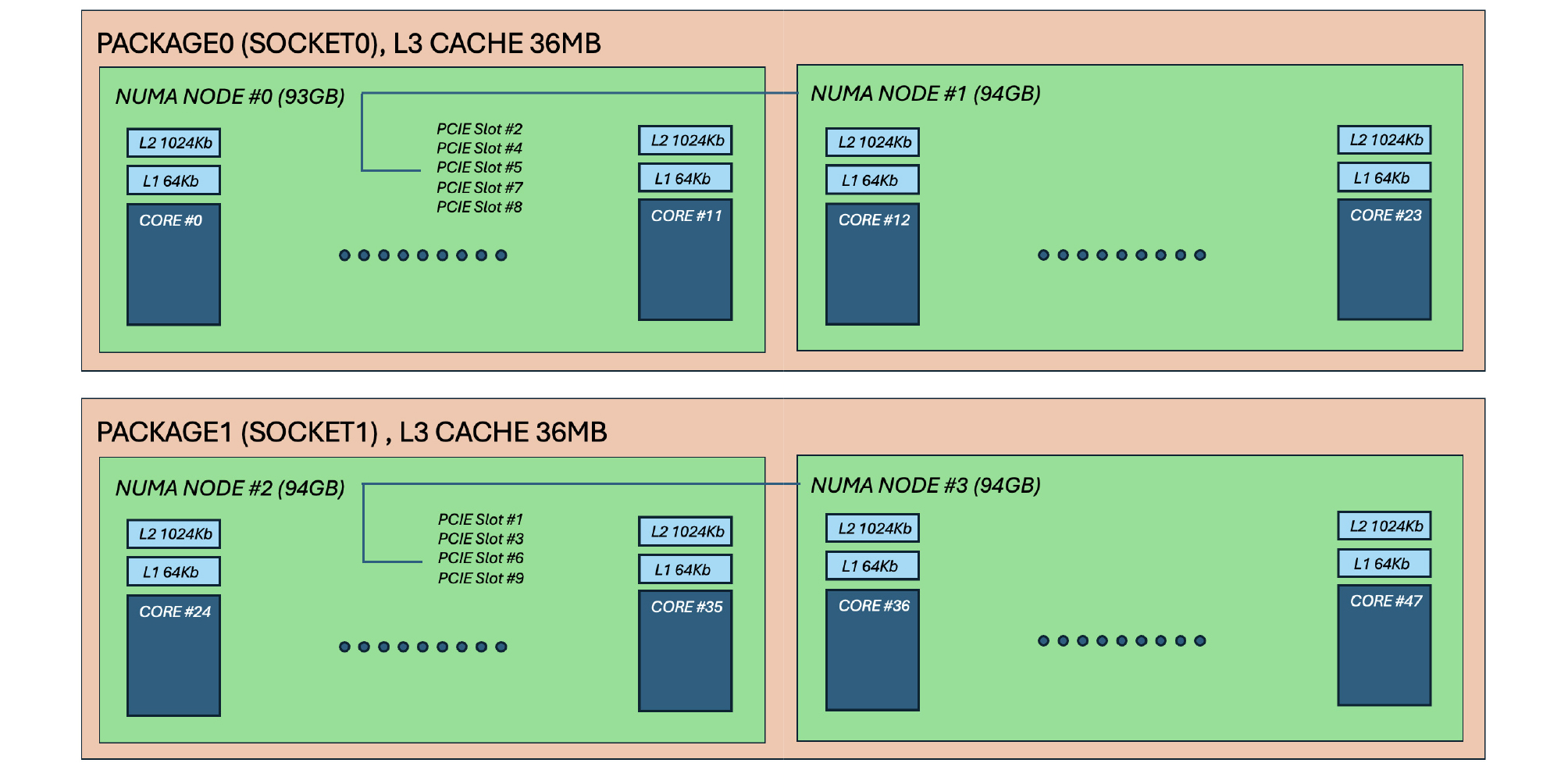
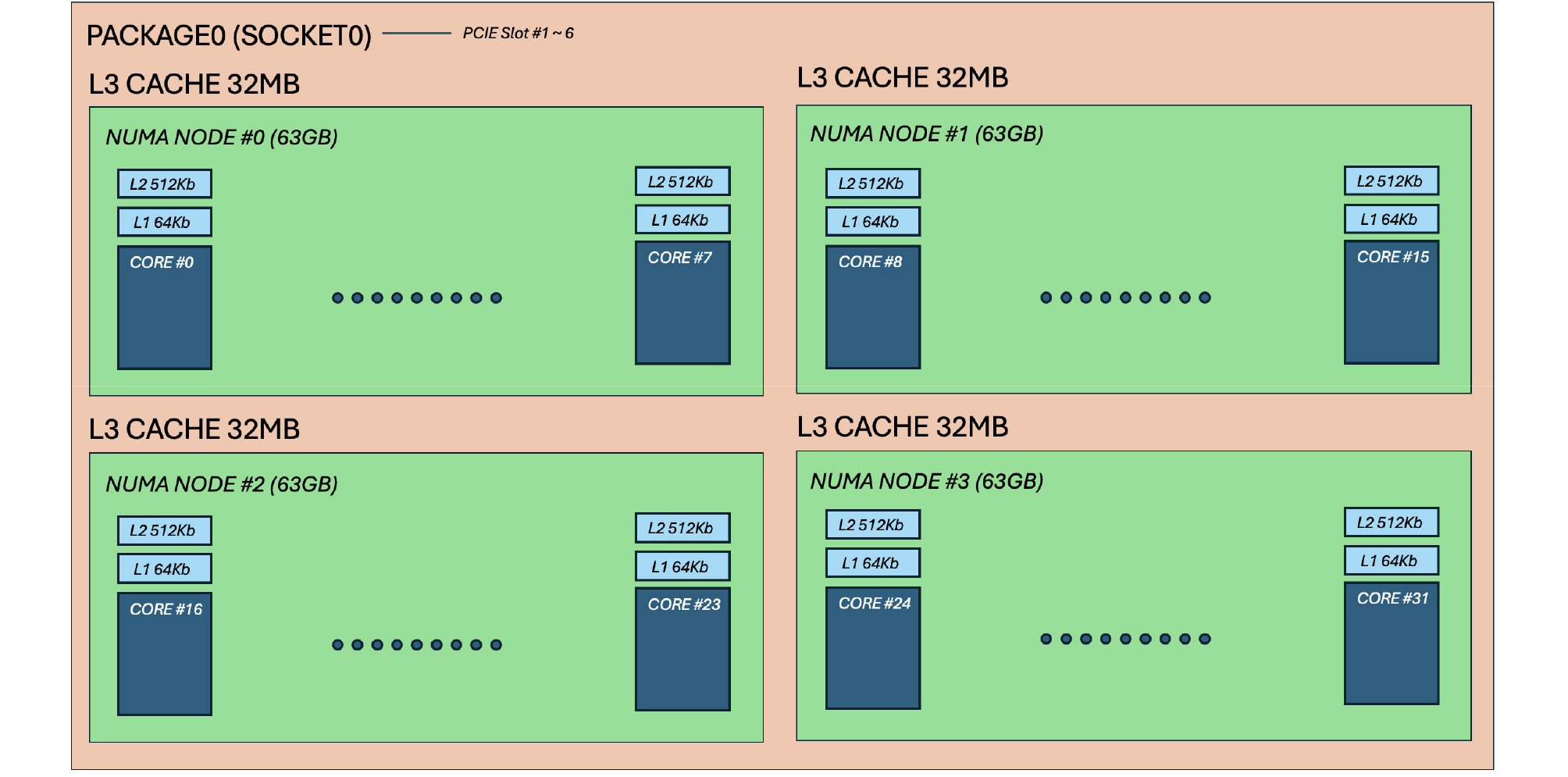
본 연구에 사용된 해석용 워크스테이션은 HP사의 Z8-G4 모델로, 2개의 소켓에 Intel® Xeon® Gold 6252 프로세서가 각각 탑재되어 총 48개의 물리 코어(physical cores)와 96개의 논리 코어(logical cores)를 제공한다. 또한, 시스템은 총 12개의 메모리 채널을 지원하여 대용량 데이터 처리에 적합한 구조를 갖추고 있다. 사용된 Intel® Xeon® Gold 6252 프로세서는 인텔의 14나노미터 공정을 기반으로 한 Cascade Lake 아키텍처를 적용하였으며, AVX-512 명령어 세트를 지원하고, 고성능 연산을 위한 유연한 확장성(scalability) 및 4개의 NUMA노드 구성이 가능한 것이 특징이다. 해당 CPU의 사양 및 전체 하드웨어 구성은 각각 Table 1과 Fig. 2에 정리하였다. Fig. 2는 시스템의 구성으로, CPU소켓당 2개의 NUMA노드로 구성이 되며, 소켓당 36Mb의 L3캐시 메모리를 공유하도록 구성되어 있어 하나의 실리콘 다이에 모든 코어가 집적된 CPU로 내부 코어간의 통신지연이 발생하지 크지 않은 장점이 있다. PCIe통신 슬롯은 개별 CPU소켓과 연결되어 클러스터 구성시 유리한 구성이다.
Table 1.
System architecture and processor specifications of the Intel® Xeon® Gold 6252 used in the benchmark tests
3.2 운영체계, 플러그인 및 해석결과 시각화
LAMMPS는 Linux, Windows, macOS 등 다양한 운영체제에서 실행이 가능하다. 본 연구에서는 이들 중에서 확장성이 우수하고 컴파일러 선택의 자유도가 높으며, 프로그램 실행 시 시스템 자원 사용을 세부적으로 관리하고 모니터링할 수 있는 Linux 운영체제를 채택하였다. 구체적으로는 Ubuntu Server 24.04.2 LTS를 사용하였으며, 이는 안정성과 최신 패키지 지원 측면에서 유리한 환경을 제공한다. LAMMPS는 시뮬레이션 결과의 후처리 및 시각화를 위해 다양한 출력 형식과 플러그인을 제공하고 있다. 본 연구에서는 KITWare사에서 개발한 Paraview(Kitware, ParaView, n.d.)와의 호환을 위해 VTK(Visualization Toolkit) 플러그인(Kitware, VTK, n.d.)을 사용하여 시각화 데이터를 생성하였다. VTK플러그인을 사용하여 LAMMPS에서 출력된 시뮬레이션 결과는 .vtk, .vtu, 또는 .xyz와 같은 다양한 포맷으로 저장될 수 있으며, 이 중 .vtk 포맷은 Paraview에서의 호환성과 활용성이 뛰어나 주로 사용된다. 본 연구에서는 VTK 플러그인을 통해 생성된 결과 파일을 Paraview에 로드하여 입자의 위치, 속도, 접촉력 등의 물리량을 시각화하였다.
4. 해석모델
본 연구에서 벤치마킹에 사용된 DEM해석모델은 사질토 입자의 낙사 시뮬레이션 모델이다. 낙사과정을 통한 흙 시료의 조성은 지반의 거동을 DEM으로 해석하기 위해 기본이면서도 난이도가 높은 과정으로, 특히 낙사 과정의 재현시 입자의 낙하 속도, 시뮬레이션 시간에 따른 접촉 상태의 변화, 이웃 리스트의 지속적인 갱신 등으로 인하여 시료가 조성된 이후의 거동시뮬레이션(K0압밀, 삼축압축, 전단시험 등)에 비하여 매우 높은 연산부하가 발생하게 된다. 이를 해결하기 위해 입경 확장(radius expansion), 보로노이 기반 입자 배치(Wang et al., 2018) 등 간소화된 시료 생성 기법이 제안되어 왔으나, 이러한 방법들은 실제 실험 조건을 충분히 반영하지 못하는 한계를 갖는다(O’Sullivan, 2017). 이에 본 연구에서는 고성능 컴퓨팅 자원을 활용하여 사질토 입자의 낙사 과정을 최적화 함으로써 보다 실제에 근접한 시료 조성을 구현하고자 하였다. 이 과정에서 하드웨어 구성과 컴파일러 최적화를 병행하여 해석 효율에 미치는 영향을 벤치마킹 하였다.
낙사과정의 시뮬레이션 최적화와 함께, 사질토 지반의 거동을 정밀하게 재현하기 위해서는 불규칙한 입자 형상의 구현이 필수적이다. 초기 DEM 해석에서는 입자를 단순 구형으로 이상화하였으나, 이는 입자의 상대밀도 표현의 한계, Rocking 현상, 입자 분쇄 등의 거동을 재현하는 데 제약이 있었다(Kuhn et al., 2014; Zhao et al., 2023). 이를 극복하기 위해 여러 개의 구형 입자를 결합하여 하나의 불규칙 입자를 구성하는 Multi-sphere(clump) 기법이 제안되었다. 이 기법은 다수의 구형입자를 사용할수록 입자의 형상을 정교하게 묘사할 수 있는 특징이 있으나, 이로 인해 입자 수가 기하급수적으로 증가하면서 연산 부담이 크게 증가하는 단점 또한 존재한다(Zhou et al., 2018; Zheng and Hryciw, 2016; 2017; Xu et al., 2021). 그러나, 불규칙 입자의 형상을 재현하기 위해 제안된 여러 다른 기법에 비해 검증이 용이하며, 알고리즘의 구현이 명시적이여서 앞도적으로 많이 사용되는 기법이라 할 수 있다(Zhao et al., 2023).
따라서, 본 연구에서는 LAMMPS가 제공하는 Rigid molecule 기능을 활용하여 Multi-sphere 기반의 비정형 사질토 입자를 구현하였다. 입자의 수의 증가로 인한 연산 부하는 Clump를 구성하는 입자간의 이웃 리스트 생성을 제외하여 해석시간을 효과적으로 단축하였다. 시뮬레이션 모델은 가로, 세로, 높이가 각각 2cm인 정육면체 박스를 해석영역으로 설정하였고, 사질토 입자는 중력에 의해 박스 내로 낙하하도록 구성하였다. 시료가 조성되는 박스는 LAMMPS의 granular wall(region)을 사용하였다. 이는 DEM 해석에서 입자의 경계 조건을 정의하기 위해 사용되는 고정 또는 이동 가능한 경계이며 입자와는 접촉모델을 이용하여 상호작용하게 된다. LAMMPS에서는 region 명령어를 이용하여 다양한 형상의 경계(벽)을 정의하며 정지된 상태 또는 fix move 명령어 등을 통해 시간에 따른 변위, 회전 등을 정의할 수 있다.
본 연구에서 사용된 낙사 해석 모델은 난수 함수(random function)를 이용하여 사질토 입자를 생성하므로, 반복 실행 시 항상 동일한 결과를 보장하지는 않는다. 이에 따라 반복 실행 간 결과 차이를 최소화하기 위해 입경이 1mm로 동일한 입자만을 사용하여 시료를 조성하였으며, 입자의 생성 위치 및 생성 시간을 가능한 한 축소하였다. 입자의 초기 생성 위치는 바닥면으로부터 4.0cm에서 4.8cm 사이로 설정되었으며, 한 번의 낙사 과정에서 약 500개의 입자가 생성되어 자유낙하 된다. 바닥에 입자가 적층되면 추가 낙사를 반복하며, 약 12회 반복을 통해 충분한 양의 시료를 조성할 수 있다. 시료 조성은 최상단 입자의 위치가 2.2cm에 도달하는 시점에서 종료되도록 하였다.
DEM 해석에서 반복 가능성(Repeatability 또는 Reproducibility)은 동일한 조건(입력 스크립트, 하드웨어, 컴파일러 등) 하에서 시뮬레이션을 반복 수행했을 때 결과가 일치하는 정도를 의미한다. 단일 프로세서를 사용하고 배정밀도(double-precision) 설정으로 수행되는 해석의 경우 반복 가능성이 높아 동일한 결과를 재현할 수 있다. 그러나 고성능 컴퓨팅(HPC) 환경에서 수행되는 병렬 해석의 경우, 동적 부하 분산(Dynamic Load Balancing), 하이브리드 병렬(Hybrid Parallelization), GPU 기반 연산 등으로 인해 연산 순서가 달라져 동일한 결과가 항상 보장되지 않는다. 본 연구의 해석 모델은 배정밀도를 기반으로 시뮬레이션을 수행함으로써, 반복 실행 시 최대한 높은 수준의 반복 가능성이 확보되도록 구성하였다.
이렇게 조성된 DEM시료는 총 6,000개의 Multi-sphere와 이를 구성하는 총 157,980개의 원형입자로 완성되었다. 원형입자 사이의 접촉거동은 탄성체인 두 입자간의 수직, 전단방향 힘을 전달하는 Hertz-Mindlin 모델(Hertz, 1881; Mindlin and Deresiewicz, 1953)을 적용하였다. LAMMPS에서는 Glanular 패키지를 적용시 식 (1)의 Hertz모델을 사용하여 접촉하는 두 개의 입자간에서 발생하는 힘을 계산하게 된다.
여기서, 는 접촉하는 두 입자간 전달되는 힘
는 두 입자간의 겹침 거리
, 는 각각 수직, 전단 접촉거동에 대한 스프링상수
, 는 각각 수직, 전단 접촉거동에 대한 점탄성 감쇠상수, (Tsuji et al., 1992)
는 접촉하는 2개의 입자의 유효질량으로 와 는 각각 접촉하는 입자의 질량
는 접촉하는 2개입자간의 접선방향 탄성변위
접촉하는 2개의 입자 중심을 잇는 단위 방향벡터
, 는 각각 접촉하는 2개의 입자간의 수직 및 전단방향 상대속도
접촉에 의한 에너지 감쇠는 Tsuji 등(Tsuji et al., 1992)이 제안한 점탄성 감쇠모델이 사용되었다. 따라서, 시뮬레이션을 위한 입력변수로 , 가 필요하며, , 는 실험결과로 부터 결정하거나, 두 입자간의 접촉조건에 따라 자동으로 결정될 수 있다. 와 의 정확한 실험값을 확보하지 못하는 경우 , 의 기본값이 사용된다. 식 (1)의 , 와 사질토의 포아송비, 탄성계수와의 관계는 Zhang과 Makse(Zhang and Makse, 2005)가 식 (2)와 같이 제시하였다. 본 논문에서는 실리카 모래입자의 탄성계수와 포아송비로부터 식 (2)를 이용하여 입력변수를 획득하였다. 시뮬레이션에 사용된 입력변수를 Table 2에 정리하였으며, 모래입자의 탄성계수와 포아송비는 Dutta와 Penumadu(Dutta and Penumadu, 2007)의 실험결과를 사용하였다. 시료박스와 입자 간의 접촉 또한 동일한 Hertz-Mindlin 모델을 적용하여 모델의 일관성을 유지하였다.
Table 2.
Properties of soil particles in DEM simulation
| Mass density (kg/m3) | 2,700 | (N/m) | 4.98 × 1010 |
| Young’s Modulus (GPa) | 70 | (N/m) | 6.4 × 1010 |
| poisson’s ratio | 0.25 | ||
| coefficient of friction | 0.5, ≃26.5° |
여기서, , 는 각각 전단탄성계수, 포아송비이다.
DEM해석에 적용된 시간 적분 간격은 2×10-6초이며, 낙사 과정을 시각적으로 나타낸 시뮬레이션 결과를 Fig. 3에 시간 단계별 형상과 최종 형성된 시료로 제시하였다.
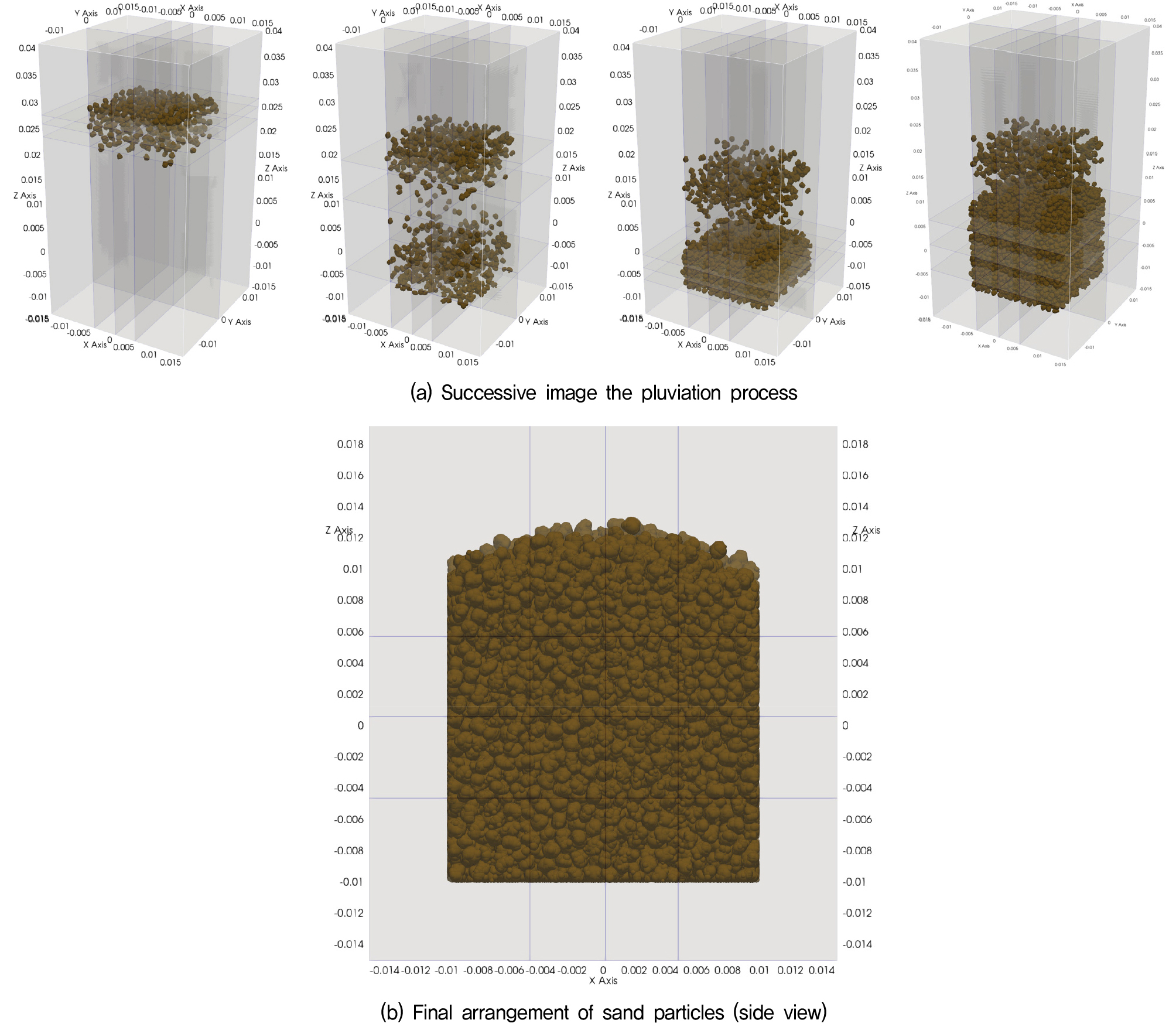
시뮬레이션에 사용된 사질토 입자의 불규칙 형상을 모사하기 위해 구형 입자의 표면을 극 방향()과 방위각 방향()으로 각각 5등분하여 총 25개의 구역으로 분할하여 격자화 하였다. 사질토 입자의 불규칙한 표면은 분할된 격자의 격자점을 기준으로 반지름을 임의로 축소하여 불규칙 형상을 생성하였다. 이렇게 생성된 복잡한 형상의 입자를 DEM에서 모델링하기 위해, 2차원에서는 다수의 원, 3차원에서는 구형입자를 결합하여 실제 입자와 유사한 형상을 갖는 Multi-sphere로 표현하는 방식이 널리 사용된다. 대표적으로 Wang 등(Wang et al., 2007)은 입자의 표면에 위치한 작은 입자들의 중심 좌표를 기준으로, 가장 큰 반지름을 갖는 대체 입자를 반복적으로 탐색한 후 해당 영역의 작은 입자들을 제거하고, 새로운 큰 입자로 치환하는 절차를 제안하였다. Multi-sphere생성 종료 조건은 더 이상 큰 입자로 치환할 수 없을 때이다. 이 방법은 Burn 알고리즘이라 하며, 비교적 적은 수의 입자를 이용하여 불규칙 입자형상을 구성할 수 있는 장점이 있어 상용 DEM 소프트웨어인 PFC3D에 구현되어 있다. Multi-sphere입자의 개수가 많을수록 불규칙 입자의 형상을 유사하게 묘사할 수 있지만 DEM해석에 사용되는 입자의 개수가 증가하여 해석시간이 크게 증가하는 단점이 있다. Fig. 4는 Multi-sphere생성에 사용된 구형입자의 개수 21, 352개에 따른 입자 표현의 차이를 도시하였다.
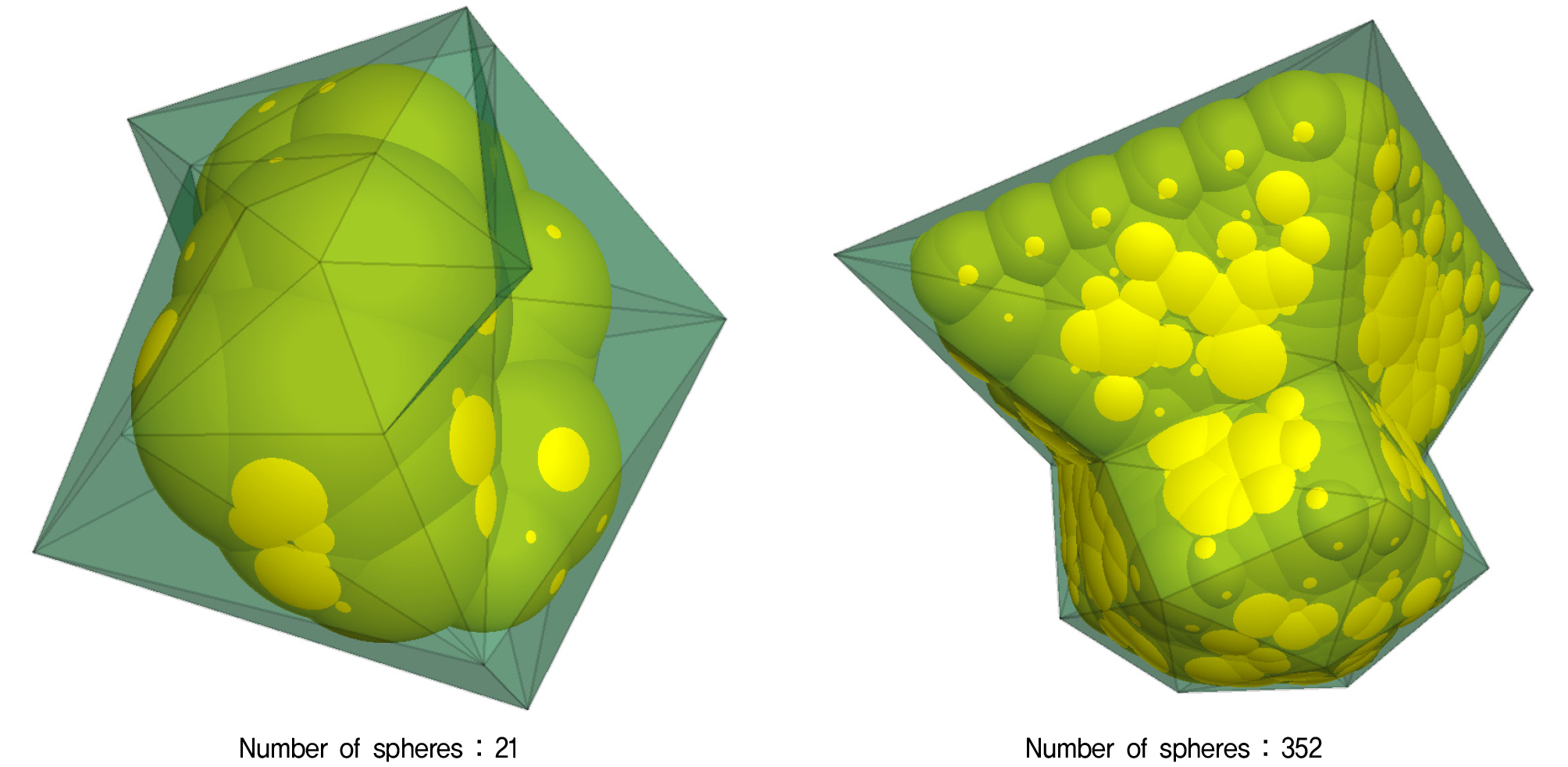
많은 구형입자를 사용할수록 정밀한 표현이 가능하나, DEM해석시 연산부하가 가중되는 문제가 발생한다. 따라서, 본 연구에서는 연산부하의 증가가 가중되지 않는 선에서 불규칙한 사질토 입자를 표현할 수 있도록 약 21 ~ 38개의 구형입자로 채워 결합되는 Multi-sphere입자를 생성하였다. 이와 같은 방식으로 총 20개의 상이한 형상을 가지는 Multi-sphere 입자들을 생성하여, DEM해석에 사용되었다. 생성된 20개의 입자형상을 사용된 구형입자의 개수(N)과 함께 Fig. 5에 도시되어 있다.

5. 해석 최적화
LAMMPS와 같이 병렬 해석을 지원하는 프로그램의 성능 평가는 일반적으로 고정 크기(fixed-size) 또는 확장 크기(scaled-size) 시뮬레이션을 통해 수행된다. 고정 크기 벤치마크는 동일한 입자 수를 가진 모델을 서로 다른 수의 프로세서에서 실행하여 병렬화에 따른 실행 시간 단축 효과를 분석하는 방식이다. 반면, 확장 크기 벤치마크는 프로세서 수에 비례하여 모델의 크기(입자 수)를 증가시키며 실행 시간을 측정함으로써 시스템의 확장성(scalability)을 평가하는 데 활용된다. 본 연구에서는 고정크기 벤치마크 방식을 채택하였다. 제 4 장에서 설명한 바와 같이, 2cm × 2cm × 2cm 크기의 정육면체 박스 내에 불규칙한 형상의 사질토 입자를 낙하시켜 시료를 조성하는 데 소요되는 시뮬레이션 시간을 측정하였고, 이를 기반으로 최적의 해석 조건을 도출하였다. 성능 평가는 다음의 네 가지 항목을 중심으로 수행되었다.
(1) MPI 프로세서 수(rank) 변화에 따른 병렬 확장 효율평가
(2) 가속옵션 사용에 따른 해석시간 단축효과
(3) AMD Zen 3 아키텍처 기반 CPU와의 성능 비교
(4) Load Ballancing 효과의 평가
5.1 병렬 확장성 평가: MPI 프로세서 수(rank) 변화에 따른 시뮬레이션 성능 분석
본 절에서는 4개의 NUMA 노드를 갖는 시스템에서 MPI 프로세스 수(rank)를 변화시키며 시뮬레이션 수행 시간을 측정하고, 이를 바탕으로 병렬 확장성(parallel scalability)을 평가하였다. 본 해석에서는 분산 메모리 기반의 MPI 라이브러리를 이용하여 해석 모델을 영역 분할하고, 각 영역에 독립된 프로세스를 할당하며, 이들을 고유한 식별자인 rank로 구분한다. Rank 수가 증가할수록 분할된 영역의 크기는 작아지고, 각 영역 내의 DEM 입자 수가 감소하여 rank당 연산 부하는 줄어드나, 반면 영역 간 통신 부하는 증가하게 된다. 일반적으로 MPI를 이용한 병렬 해석에서는 rank당 하나의 물리 코어(CPU)를 할당하여 수행하는 것이 효율적이다. 확장성 평가에 사용된 시뮬레이션 모델은 앞서 설명된 Fig. 3과 같다. 계산효율을 높이기 위하여 프로세서 간 경계(ghost region)에서 발생하는 중복계산은 한쪽 프로세서에서만 수행하고, 그 결과를 인접 프로세서와 공유하는 방식으로 처리하였다. 이는 LAMMPS에서 “newton on” 옵션을 활성화한 경우에 해당하며, 중복 계산을 제거하여 연산량을 줄일 수 있으나, 프로세서 간 통신량이 증가하는 특성이 있다. 반대로 “newton off” 옵션을 적용하면 각 프로세서가 자신이 보유한 입자에 대한 상호작용을 독립적으로 계산하므로 통신량은 줄어들지만, 전체 계산량은 증가하게 된다. 해석에 사용된 Intel Xeon® Gold 6252 CPU는 소켓당 24개의 물리 코어를 제공하며, 2소켓 구성으로 총 48개의 물리코어를 사용할 수 있다. NUMA 아키텍처에 따라, 4개의 NUMA 노드를 기준으로 물리 코어는 4의 배수로 균등하게 할당되었다. 확장성 평가에 적용된 물리 코어(rank) 수, NUMA 노드당 코어 수, LAMMPS 실행 명령어 옵션, 그리고 각 시뮬레이션별 수행 시간을 Table 3에 정리하였다. 평가결과, 해석을 위한 rank의 수가 증가할수록 해석시간이 단축됨을 알 수 있으며, 16개 미만의 rank증가에 비하여 그 이상 증가에 따른 해석시간 단축효과는 크게 나타나지 않았다. 따라서, 본 논문에 사용된 해석모델은 cpu 코어당 약 6,000개의 이하의 DEM입자에 대해서 최적 성능을 나타낸다고 평가할 수 있다.
Table 3.
Summary of simulation time, rank distribution per NUMA node, and MPI command options for different processor configurations
5.2 하드웨어 가속옵션의 평가
본 절에서는 5.1절에서 평가된 DEM해석모델의 영역분할을 이용한 병렬확장에 추가하여, DEM연산을 가속할 수 있는 가속옵션에 대한 성능평가를 실시하였다. LAMMPS에서 지원하는 대표적인 가속옵션은 공유메모리를 이용한 OMP, 고급벡터확장 AVX512, GPGPU가속이 있다. 본 절에서는 LAMMPS의 Glanular모델에 적용가능한 가속옵션인 OMP와 AVX512에 대한 성능평가를 실시하였다.
5.2.1 Hybrid : OMP + AVX512
OMP는 공유 메모리 기반의 병렬 프로그래밍 모델로, 하나의 노드 내 멀티코어 자원을 효율적으로 활용하여 계산 성능을 향상시킬 수 있다. LAMMPS는 OMP를 지원하며, -sf omp 또는 -sf hybrid omp 옵션을 통해 MPI와 병행하는 하이브리드 병렬 처리가 가능하다. 또한 -sf intel 패키지는 OMP와 함께 AVX-512와 같은 SIMD(Single Instruction, Multiple Data, 단일 명령 다중 데이터) 명령어 집합을 활용하여 벡터화(vectorization) 성능을 극대화할 수 있다. AVX-512는 한 명령어로 512비트 폭의 데이터를 처리할 수 있어, 입자 간 상호작용 계산과 같이 반복 연산이 많은 LAMMPS 시뮬레이션에서 계산 효율을 크게 향상시킬 수 있다. 본 연구에서는 5.1절에서 도출된 최적 병렬 해석 조건(총 48개 물리 코어 사용)을 기반으로 하이퍼스레딩을 활성화하여 확장된 96개 논리 코어 환경에서 OMP 및 AVX-512 명령어 집합을 병행 적용하였다. 그 결과, 시뮬레이션에 소요된 시간은 총 18시간 15분 11초였으며, 이는 연산 부하(overhead)의 증가로 인해 물리 코어만을 사용한 경우인 12시간 25분(Table 3)보다 오히려 효율이 저하됨을 나타낸다(Table 4). 추가로, CPU의 물리 코어만을 이용한 하드웨어 가속 성능을 평가하기 위하여, 12개의 MPI rank를 3개씩 4개의 NUMA 노드에 균등하게 할당하고, 나머지 36개 코어를 rank당 4개씩 OMP 및 AVX-512 연산에 활용하도록 설정하였다. 이 경우 시뮬레이션에 소요된 시간은 총 24시간 36분 54초로, 12개 MPI rank만을 사용한 병렬 해석 결과인 23시간 38분(Table 3)보다 오히려 시간이 증가하였다. 따라서 본 연구에서 수행한 DEM 해석 조건 하에서는 OMP 및 AVX-512를 병행 적용한 하드웨어 가속이 오히려 연산 부하를 증가시켜 전체적인 계산 효율이 감소하는 것으로 확인되었다.
Table 4.
Summary of benchmark simulation environment and results using hybrid parallelization (OMP + AVX-512)
5.2.2 OMP
본 절에서는 5.2.1절에서 사용된 해석 조건을 기준으로, AVX-512를 제외하고 OMP만을 적용하여 시뮬레이션 소요 시간을 측정하였다. 동일 조건에서, 해석에 소요된 시간은 각각 15시간, 19시간 18분으로 나타났다. 하이퍼스레딩을 이용한 논리코어 확장을 이용한 OMP가속은 연산부하로 인하여 OMP 미적용시 (12시간 25분, Table 3)대비 해석시간이 소폭증가 (15시간)함이 확인되었다. 반면, 12개의 MPI rank를 물리 코어에 고정 배치한 후, 여유 코어 36개를 각 rank에 3개씩 할당하여 OMP 가속에 활용한 경우에는 해석 시간이 19시간 18분으로 측정되었으며, 이는 OMP 미적용 시의 23시간 38분(Table 3) 대비 약 18.3% 단축된 결과이다. OMP 가속을 이용한 해석 결과 및 실행 옵션은 Table 5에 정리하였다.
Table 5.
Summary of benchmark simulation environment and results using hybrid parallelization (OMP Only)
5.2.3 AVX-512
AVX(Advanced Vector Extensions)는 벡터 연산을 효율적으로 수행하기 위해 설계된 SIMD(Single Instruction, Multiple Data) 명령어 집합으로, 일반적으로 고급 벡터 연산으로 분류된다. 하나의 명령어로 여러 개의 데이터를 동시에 처리할 수 있어, 고성능 과학 연산 분야에서 널리 활용된다. 초기 AVX는 256비트 레지스터를 기반으로 8개의 32비트 실수 또는 4개의 64비트 실수를 병렬 처리할 수 있었으며, 이후 도입된 AVX-512는 512비트 폭의 레지스터를 통해 최대 16개의 32비트 실수 또는 8개의 64비트 실수를 동시에 처리할 수 있도록 확장되었다. AVX-512는 2013년 Intel Xeon Phi “Knights Landing”을 시작으로, Xeon Scalable 시리즈 및 일부 Core X/i9 시리즈 등에 도입되었으며, 행렬 곱셈, 벡터 연산, 반복 루프 기반 계산 등 높은 병렬성이 요구되는 과학적 연산에 최적화되어 있다. 반면, AMD는 Zen 4 아키텍처부터 AVX-512를 지원하였으나, Intel의 단일 512비트 레지스터 처리와 달리 2개의 256비트 레인(dual 256-bit)으로 구현되어 명령어 실행 효율 및 벡터화 성능에서 상대적으로 불리하다. LAMMPS는 -sf intel 또는 -sf hybrid intel 스타일을 통해 AVX-512 기반 벡터 연산 최적화를 지원하며, 특히 입자 간 상호작용(pair style) 계산에서 반복 루프가 벡터화되어 CPU 자원 활용도를 높일 수 있다. 단, AVX-512는 넓은 레지스터 폭과 높은 전력 소모로 인해 일부 CPU에서는 클럭 쓰로틀링이 발생할 수 있으며, 이러한 성능 저하를 완화하기 위해서는 데이터 정렬, 캐시 구조 최적화, 스레드 및 메모리 바인딩과 같은 프로세스 최적화 기법이 병행되어야 한다. 본 연구에서는 AVX-512만을 적용한 조건에서의 계산 성능을 평가하였으며, 관련 결과를 Table 6에 정리하였다. 48개의 물리 코어에 대해 하이퍼스레딩을 활성화하여 총 96개의 논리 스레드로 AVX-512 가속을 수행한 경우, 해석 시간은 약 13시간으로 측정되었다. 이는 동일한 조건에서 MPI만 적용한 결과인 12시간 25분(Table 3)에 비해 다소 증가한 수치이다. 반면, 48개의 물리 코어 중 12개를 MPI rank에 할당하고, 나머지 36개를 AVX-512 연산용으로 지정한 구성에서는 총 해석 시간이 22시간 20분으로 나타났다. 이는 동일한 MPI 조건에서 AVX-512를 사용하지 않은 경우의 23시간 38분(Table 3)과 비교해 약 5.82% 단축된 결과이다. 이상의 결과로부터, 5.2.2절의 OMP를 활용한 가속 방식과 비교할 때 AVX-512 단독 적용에 의한 계산 성능 향상은 상대적으로 제한적인 것으로 확인된다.
Table 6.
Summary of simulation time, core distribution per NUMA node, and MPI command options for AVX-512 configurations
5.3 AMD CPU
본 절에서는 CPU아키텍쳐에 따른 연산성능비교를 위하여 벤치마킹에 사용된 Intel Xeon® Gold 6252 CPU와 비교적 동일한 세대의 AMD CPU를 비교하였다. 5.1, 5.2절에서 벤치마크에 사용된 Xeon® Gold 6252 CPU는 인텔의 14나노미터 공정을 기반으로 한 Cascade Lake 아키텍처로 2019년 출시되었으며, 본 절에서 비교로 사용된 AMD CPU는 TSMC 7나노미터 공정기반 Zen3 아키텍쳐로 2022년 출시되었다. Table 1의 인텔 CPU와 비교할 수 있도록 AMD CPU의 제원을 Table 7에 정리하였으며, 해석을 위한 워크스테이션 시스템 구성은 Fig. 6과 같다. Fig. 6은 시스템의 구성으로, CPU소켓은 1개로 AMD사의 멀티칩 구조내에서 독립적인 4개의 NUMA노드를 구성하고 있다. 따라서, NUMA노드 간 L3캐시 메모리의 공유는 이루어지지 않아, 서로 다른 NUMA노드 간의 통신지연이 발생할 수 있는 구조이다.
Table 7.
System architecture and processor specifications of the AMD Ryzen Threadripper PRO 5975WX used in the benchmark tests
DEM 해석모델은 동일하며, AMD Ryzen Threadripper PRO 5975WX의 물리코어는 32개로 이를 최대로 활용하여 동일 물리코어를 사용한 Intel CPU의 해석결과(Table 3)와 비교하였다. AMD Zen3 아키텍쳐에서는 AVX-512를 지원하지 않으므로, 하드웨어 가속기능은 OMP만을 적용하였다. 해석결과는 Table 8에 정리하였다. 4개의 NUMA 노드에 각각 8개의 MPI rank를 할당하여 해석한 결과 소요된 시간은 26시간 13분으로 동일한 조건의 Intel CPU해석결과인 14시간 12분에 비하여 약 1.85배의 해석시간이 소요되었다. 이는 AMD의 Threadripper PRO 5975WX가 단일 소켓 내부에 4개의 CCD(Core Complex Die)로 구성된 멀티칩 구조를 사용하며, CCD간 메모리 접근이 infinity fabric(Advanced Micro Devices, 2022)을 통해 이루어져 MPI를 이용한 병렬해석시 영역경계의 ghost 입자간 발생하는 통신지연(latency)으로 발생하는 것으로 추정된다. 반면, Intel사의 Xeon Gold 6252는 각 CPU가 단일 다이(Monolithic Die) 기반으로 제작되어 MPI를 이용한 병렬해석시 core사이의 통신이 단일다이 내에 위치한 캐시 메모리 안에서 이루어지므로 지연이 발생하지 않기 때문이다. 이러한 차이를 규명하기 위하여, Threadripper PRO 5975WX의 총 32개 코어 중 CCD당 1개 또는 2개의 코어만을 MPI자원으로 활용하고, 나머지 인접 물리코어는 OpenMP 스레드를 활용한 Hybrid 병렬처리의 효과를 각각 평가하였다. Hybrid 병렬처리 결과, CCD당 2개의 코어를 MPI 자원으로 활용한 Hybrid 해석시간이 26시간에서 약 17시간으로 크게 단축되었다. 그러나, CCD당 1개의 코어를 MPI 자원으로 활용한 Hybrid 해석시간은 약 29시간 45분으로 해석시간이 증가되었다. 따라서, 멀티 CCD구조를 사용하는 AMD CPU를 이용하여 MPI해석을 시행하는 경우 적정개수의 Rank와 OpenMP 스레드를 사용한 Hybrid 해석의 최적조건을 확인하는 것이 필요하다.
Table 8.
Summary of simulation time, core distribution per NUMA node, and MPI command options for AMD Threadripper 5975WX configurations
5.4 동적부하균형(DLB, Dynamic Load Balancing)
LAMMPS는 영역 분할(Domain Decomposition)을 기반으로 한 MPI 병렬화 기법을 채택하고 있으며, 이 경우 각 프로세서(Rank)에 할당되는 입자의 수가 유사할 때 연산 부하가 균등하게 분산된다. 연산 부하에 차이가 발생할 경우, 전체 계산은 가장 느린 프로세서에 의해 병목이 발생하고, 이로 인해 동기화 대기 시간이 증가하여 병렬 효율이 저하된다. 이러한 문제를 해결하기 위해 LAMMPS는 동적 부하 분산(DLB, Dynamic Load Balancing) 기능을 제공한다. 시뮬레이션 도중 입자의 공간 분포가 변화하여 부하 불균형이 발생하면, fix balance 명령을 통해 서브 도메인의 크기(경계)를 주기적으로 조정함으로써 각 프로세서에 균등한 연산량이 분배되도록 한다. 이를 통해 시뮬레이션의 계산 효율과 병렬 성능을 지속적으로 향상시킬 수 있다. 본 논문에서 시뮬레이션 된 사질토의 낙사해석은 Fig. 7과 같이 해석시간에 따라 입자의 공간내 분포의 변화가 크게 발생한다. Fig. 7 a)는 DLB를 시행하지 않은 경우 프로세서(Rank)별 연산 영역에서의 입자 분포이며, Fig. 7 b)는 DLB를 시행한 경우의 분포이다. 해석시간의 차이는 Table 9에 정리하였다. DLB의 유무로 인하여 해석시간이 약 2배 이상 차이가 발생함이 확인되어 DLB의 효과가 상당함을 알 수 있다.
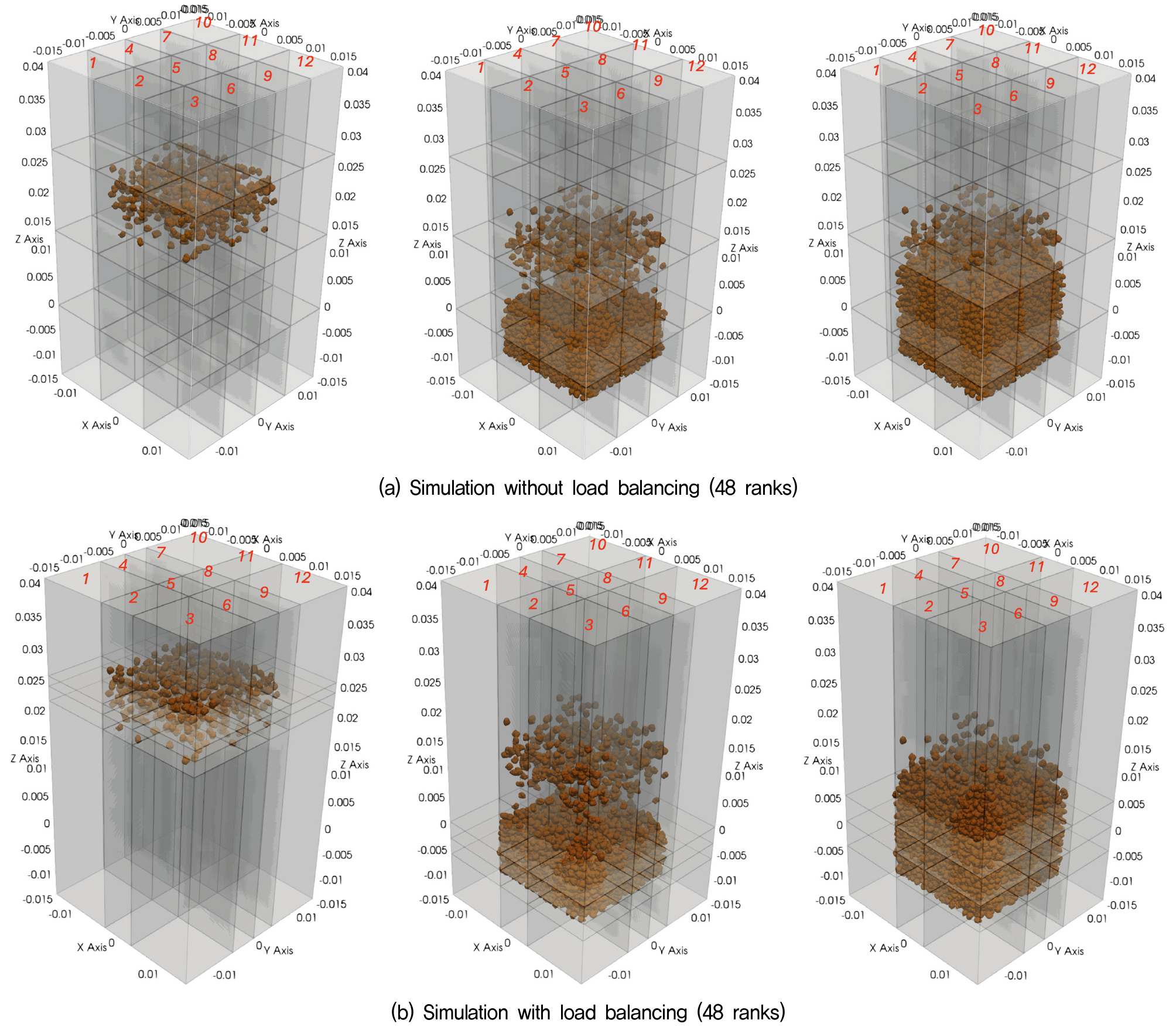
Table 9.
Simulation time summary relative to dynamic load balancing usage
5.5 평가결과
5.1 ~ 5.4절의 벤치마크 결과를 Fig. 8의 비교 그래프로 나타내었다. Intel CPU에서는 MPI병렬 해석을 이용한 확장성 평가시 프로세서(rank) 수를 증가시킴에 따라 해석시간은 일정 수준까지 급격히 감소하였으나, 일정 코어 수 이상에서는 통신 오버헤드로 인해 성능 향상폭이 둔화되는 것이 확인 되었다. 반면, 멀티 CCD구조를 가지는 AMD Threadripper PRO 5975WX는 높은 클럭 속도와 대용량 캐시를 제공함에도 불구하고, MPI병렬 해석시 CCD사이의 통신이 필요한 멀티 CCD 구조로 인하여 병렬 확장성은 Intel Xeon Gold 6252에 비해 낮은 것으로 나타났다. 그러나 OpenMP 기반 병렬화 활용한 Hybrid 해석시, AMD 플랫폼도 상당한 성능 향상이 가능하였다. 따라서, AMD CPU에서는 적정 rank수에서 남는 코어자원을 OMP로 활용하는 Hybrid기법이 유리함을 알 수 있었다.
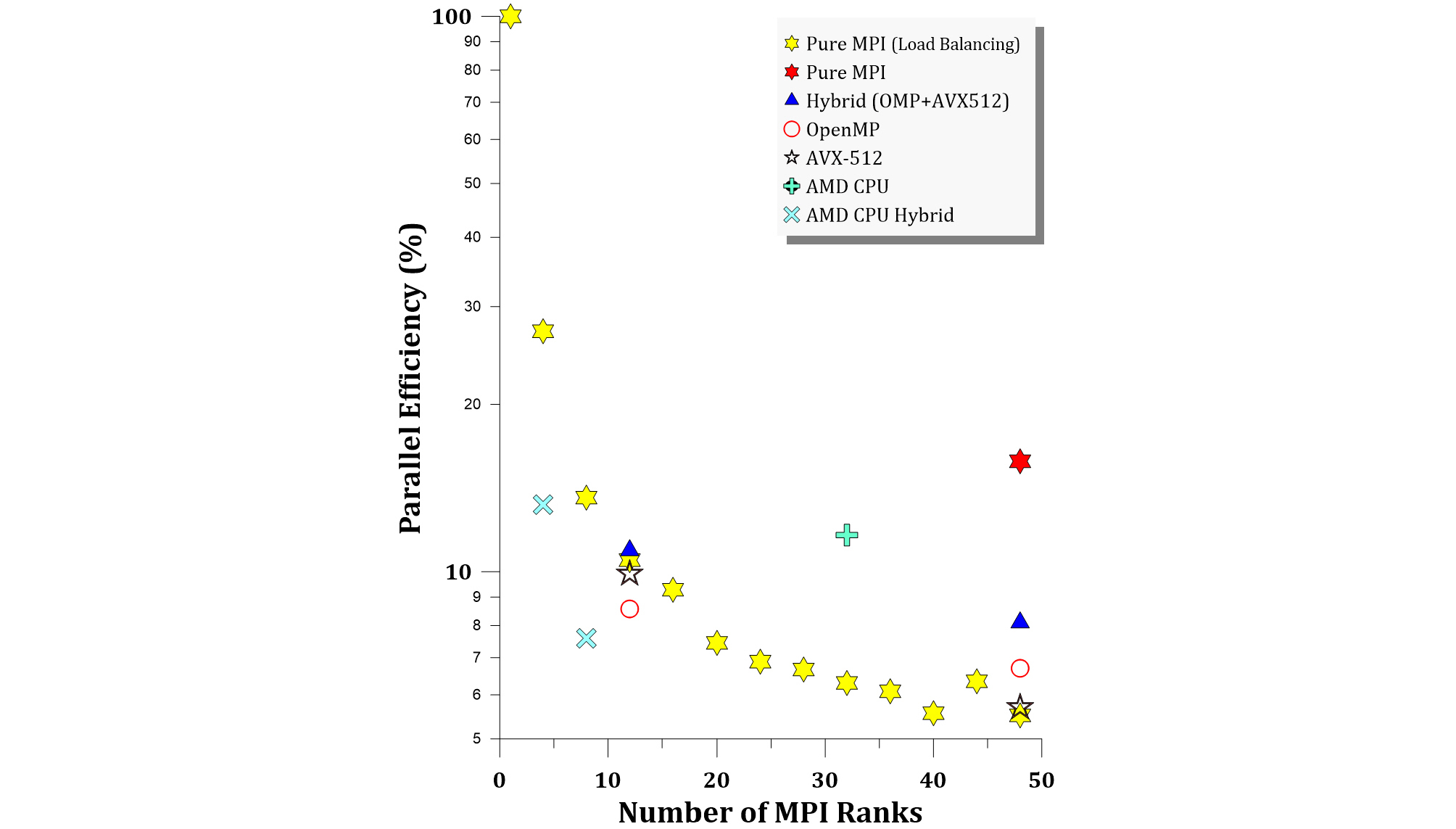
Intel CPU에서 OMP기반 멀티스레딩과 AVX-512 벡터 연산 명령어 집합의 적용은 MPI rank에 물리코어를 할당 후 여유 프로세스 자원을 활용시 연산 가속에 일부 기여하였지만, 확장된 논리 코어를 활용시 연산부하로 인하여 오히려 효율이 저하되었다. 마지막으로 LAMMPS에서 제공하는 DLB는 매우 효율적인 연산을 가능케 하였다. Fig. 8의 비교 그래프에서 확인할 수 있듯이 최대 MPI Rank 수에서 DLB를 적용한 경우 해석 시간이 약 65% 이상 단축할 수 있음을 확인하였다.
6. 결 론
사질토 지반의 미시적 거동을 정밀하게 모사하기 위해 개별요소법(Discrete Element Method, DEM)을 활용하는 경우, 수천에서 수십만 개에 이르는 입자 간의 접촉력 및 운동을 시간에 따라 계산해야 하므로 막대한 연산량이 요구된다. 특히, 불규칙한 사질토 입자의 형상을 Multi-sphere 방식으로 표현할 경우 입자의 수가 크게 증가하게 되며, 이는 연산량 증가의 주요 원인이 된다. DEM을 이용한 사질토 지반의 실내시험 시뮬레이션 과정에서 초기 단계인 낙사를 이용한 시료 조성 과정은 입자 간 충돌 및 접촉 입자의 변화가 빈번하게 발생하여, 초기응력 재하나 전단응력 재하 단계에 비해 상대적으로 높은 연산 부하를 유발한다. 따라서 이러한 해석을 단일 프로세서 기반의 계산으로 수행하는 데는 한계가 있으며, 고성능 컴퓨팅 기술과 병렬 해석의 최적화 전략은 DEM 해석에서 필수적인 요소로 간주된다. 이에 본 연구에서는 LAMMPS 시뮬레이션 플랫폼을 기반으로 사질토 낙사 과정을 모사하는 DEM 해석모델을 설정하고, 병렬 해석 성능을 평가하여 최적화 방안을 도출하고자 하였다. 연구는 다음 네 가지 측면에 중점을 두어 수행되었다.
(1) MPI 기반 병렬 확장성 분석
(2) OMP 및 AVX-512 명령어 기반 연산 가속 효과 평가
(3) 서로 다른 CPU 아키텍처(Intel Xeon 및 AMD Threadripper) 간의 성능 비교
(4) 동적 부하 분산(Dynamic Load Balancing, DLB)의 효율성 분석
MPI 기반 병렬성의 확장성 분석결과, 프로세서(rank) 수를 증가시킴에 따라 해석시간은 일정 수준까지 급격히 감소하였으나, 일정 코어 수 이상에서는 통신 오버헤드로 인해 성능 향상폭이 둔화되는 것이 확인 되었다. OMP기반 멀티스레딩과 AVX-512 벡터 연산 명령어 집합의 적용은 MPI rank에 물리코어를 할당 후 여유 프로세스 자원을 활용시 연산 가속에 일부 기여하였지만, 확장된 논리 코어를 활용시 연산부하로 인하여 오히려 효율이 저하되었다. CPU 아키텍처 간 비교결과, AMD Threadripper PRO 5975WX가 높은 클럭 속도와 대용량 캐시를 제공함에도 불구하고, CPU다이 간 통신이 필요한 멀티 CCD 구조의 한계로 인해 MPI 기반 병렬 성능은 Intel Xeon Gold 6252에 비해 낮은 것으로 나타났다. 그러나 OpenMP 기반 병렬화 활용한 Hybrid 해석시, AMD 플랫폼도 상당한 성능 향상이 가능하였다. 특히, DLB의 효과는 매우 두드러졌는데, 동일 MPI 프로세서 수에서 DLB를 적용한 경우 해석 시간이 약 65% 이상 단축될 수 있음이 확인 되었다. 이러한 결과는 DEM 해석의 최적화는 단순히 코어 수의 증가만으로 달성할 수 없으며, 하드웨어 구조, 메모리 접근 패턴, 명령어 최적화, 그리고 시뮬레이션 중 발생하는 연산 부하의 동적 변화에 적절히 대응할 수 있는 기능(DLB 등)을 통합적으로 고려해야 함을 보여준다. 따라서 본 연구는 LAMMPS를 활용한 사질토 입자 해석에서 병렬 최적화를 통해 해석 시간을 획기적으로 단축하고 대규모 시뮬레이션을 현실화하는 데 필요한 기술적 방향성을 제시하였다. 향후 연구에서는 GPU가속 기법(Kokkos, CUDA 등)과 병행한 하이브리드 모델에 대한 추가 분석, 다중 클러스터 환경에서의 스케일업 테스트 등이 필요할 것으로 판단된다.
