

1. 서 론
2. 데이터 수집 및 변수 구성
2.1 연구 지역 및 변수 선정
2.2 데이터 수집 및 공간 변수 매핑
2.3 변수 간 상관성 분석 및 최종 데이터셋 구성
3. 인공지능 기반 예측 모델 구축 및 결과 분석
3.1 불균형 처리 및 평가 지표
3.2 모델 구조 및 학습 설정
3.3 학습 결과 및 분석
3.4 변수 중요도 분석
4. 결 론
1. 서 론
국토교통부에 따르면 지반함몰(Ground subsidence)은 지표면이 여러 요인에 의해 일시에 붕괴되어 국부적으로 수직 방향으로 꺼져 내려앉는 현상으로 정의된다(국토교통부, 2015). 우리나라의 경우 지질이 주로 화강암과 편마암 등의 기반암으로 구성되어 있어, 자연적 요인보다는 인위적인 요인에 의해 지반함몰이 발생하는 경우가 대부분이다. 주요 인위적 원인으로는 지하수의 과다한 사용, 노후화된 관거의 손상, 지하 공사 및 굴착 활동 등이 있으며(한국시설안전공단, 2015), 이로 인해 지반 내 간극수가 빠져나가거나 토사가 유실되면서 지반 구조의 불연속성이 확대되어 함몰이 발생한다.
지하안전정보시스템의 통계에 따르면, 최근 수년간 전국적으로 매년 100건 이상의 지반함몰이 보고되고 있다(지하안전정보시스템, 2024). 그러나 국내의 대응 체계는 여전히 사전 예측 및 위험도 평가보다는 사고 이후의 복구 중심으로 운영되고 있다(Kim et al., 2025). 예를 들어, 2025년 3월 24일 서울 강동구 명일동에서 발생한 폭 20m, 깊이 20m 규모의 대형 지반함몰 사고는 사전에 균열 및 도로 침하 등 전조 현상이 관찰되었음에도 불구하고(서울특별시, 2023), 적절한 대응이 이루어지지 않아 인명피해로 이어졌다. 이러한 사례는 보다 체계적인 지반함몰 분석 및 예방 시스템 구축의 시급성을 보여준다.
지반함몰은 인명 및 재산 피해뿐만 아니라 사회기반시설의 신뢰성에도 심각한 영향을 미치므로, 발생 원인을 과학적으로 규명하고 사전에 예방하는 것이 매우 중요하다. 선행연구에서는 주로 지반함몰의 발생 메커니즘과 영향인자 분석에 초점을 두었다. 예를 들어, Kwak et al.(2019)은 노후 관거의 손상으로 인한 하수의 누출이 지반 내 토사 유실을 유도하고, 최종적으로 지반함몰로 이어지는 과정을 제시하였다. 한편, Ryu et al.(2017)은 강우의 지속시간 및 누적 강수량이 지반 내 수리적 안정성에 영향을 미치며, 지반함몰 발생 확률과 통계적으로 유의한 상관관계를 갖는다는 점을 분석하였다. 그러나 이러한 연구들은 주로 개별 요인에 대한 메커니즘 분석에 집중되어 있어, 다양한 환경, 지반, 요인을 종합적으로 고려한 사전 대응에는 한계가 있다.
최근에는 지반함몰 발생 가능성을 정량적으로 예측하기 위해 머신러닝 기반 기법을 활용하는 연구가 증가하고 있다. Kim et al.(2021)은 서울시 하수관로 정보와 지반함몰 발생 위치 자료를 활용하여 랜덤 포레스트 기반 예측 모델을 구축하였으며, 하수관 속성만을 이용한 경우에도 상당히 높은 예측 성능을 확보할 수 있음을 확인하였다. 그러나 해당 연구는 하수관 정보에 국한된 단일 자료 기반 분석이라는 점에서, 강우·지질·노후 건축물 등 다양한 지반·도시환경 요인을 통합적으로 반영하기에는 한계가 있다. 한편, Lee et al.(2023)은 지하 관로 손상이 도시 지반함몰의 주요 원인이라는 점에 착안하여, 대상 지역을 격자 단위로 분할하고 관로 속성 정보와 지반함몰 이력 데이터를 머신러닝 기법에 적용함으로써 지반함몰 위험 예측 가능성을 제시하였다. 해당 연구는 격자 기반 분석을 통해 고위험 지역을 선별하고, 이를 정밀 조사와 연계하는 관리 방안의 가능성을 제시하였다는 점에서 의의를 가진다. 또한, Lee et al.(2024)은 지반함몰 이력과 지하 시설물 속성 정보에 더해 투수계수, 지층 두께, 고도 등 지반공학적 특성 인자를 함께 고려한 머신러닝 기반 지반함몰 위험 예측 모델을 제안하였다. 해당 연구는 관로 중심 분석에서 나아가 지반 특성 정보를 추가로 적용하였다는 점에서 의미가 있으나, 지반함몰이 복합적인 요인에 의해 발생하는 현상인 만큼 예측 신뢰도 측면에서 한계를 가진다. 이처럼 기존 연구들은 지반함몰 예측 가능성을 제시하였으나, 대부분 특정 자료에 의존하거나 변수 범위가 제한되는 경향이 있다.
본 연구는 광주광역시를 연구 대상 지역으로 설정하고, 지반함몰 발생과 관련된 누적 강수량, 지질 정보, 건물 노후도 등 다양한 공공데이터를 통합하여 공간 단위의 다변량 데이터를 구축하였다. 이를 기반으로 DNN(Deep Neural Networks), Random Forest, XGBoost(Extreme Gradient Boosting) 세 가지 인공지능 모델을 적용하여 지반함몰 발생 가능성을 예측하고, 모델 간 성능을 비교·평가하였다. 또한 변수 중요도 분석을 통해 지반함몰 발생에 영향을 주는 주요 변수를 파악하였다. 특히, 기존 선행연구가 특정 자료에 의존하거나 변수 범위가 제한적이었던 한계를 보완하고자, 강우, 지질 분포, 건물 노후도 등 공공데이터 기반 다변량(Geospatial multivariate) 데이터를 활용하여 지반함몰 발생 가능성을 평가하였다. 이를 통해, 주요 요인을 규명함으로써 향후 도시지역의 종합적인 지반함몰 위험도 분석과 예방적 관리체계 구축에 기여하고자 하였다.
본 연구의 주요 목적을 정리하면 다음과 같다.
1. 공공데이터를 활용하여 지반함몰 발생과 관련된 주요 변수를 수집 및 정리한다.
2. 연구 대상 지역을 선정하고, 각 공간 단위별 변수와 지반함몰 발생 여부를 매핑하여 학습용 데이터셋을 구축한다.
3. 구축된 데이터셋을 기반으로 다양한 인공지능 모델의 적용성을 평가하고 지반함몰 발생 가능성을 분석한다.
4. 변수 중요도 분석을 통해 지반함몰 발생에 영향을 미치는 주요 인자를 도출한다.
2. 데이터 수집 및 변수 구성
2.1 연구 지역 및 변수 선정
2.1.1 지반함몰 발생 통계 및 연구 지역 선정
본 연구에서는 데이터의 수집 가능 여부와 학습 효율성을 고려하여 최근 5년(2019–2023년)간의 지반함몰 발생 자료를 기반으로 분석을 수행하였고, 해당 기간 동안 전국적으로 총 940건의 지반함몰이 보고되었다. 연구 대상 지역 선정에 있어 지반함몰 발생 현황과 함께 데이터의 공개성 및 접근성을 주요 기준으로 설정하였다. 광주광역시는 지반함몰 발생 이력뿐만 아니라, 강우량, 지질 분포, 건물 노후도 등 본 연구에서 활용한 주요 변수들이 모두 공공데이터 형태로 제공되고 있어, 별도의 지자체 협조 없이도 동일한 공간 단위로 데이터 구축 및 연계가 가능하다는 장점을 가진다. 특히 기상청, 국토교통부, 국가공간정보포털 등에서 제공하는 공개 데이터를 활용하여 시 전역에 대해 일관된 기준의 공간 단위 다변량 데이터셋을 구축할 수 있었다. 광주광역시의 지반함몰 발생 현황은 Fig. 1과 같이 월별 발생 빈도로 제시하였으며, 여름철(6–8월)에 집중되는 경향을 보여 강우와 같은 계절적 요인과 밀접하게 관련되어 있음을 시사한다.
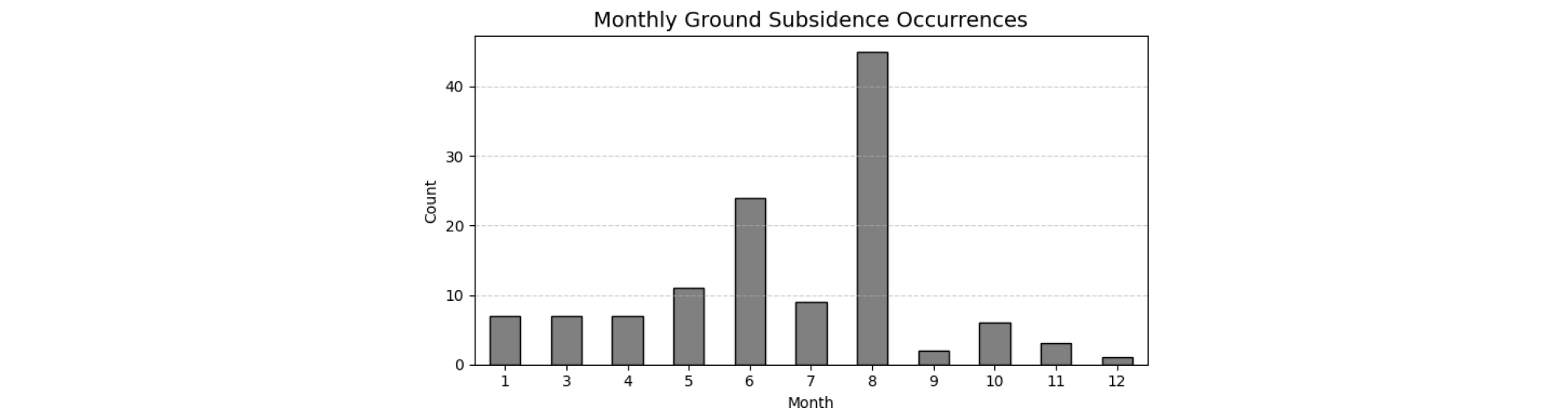
Table 1은 원인별 발생 통계를 나타낸 것으로, 전체 122건 중 79건(64.8%)이 관로 손상(Pipeline damage)에 의한 것으로 조사되었다. 이는 노후화된 상·하수도 및 공동구의 균열 또는 누수로 인한 것임을 보여준다. 이러한 통계적 분석 결과를 바탕으로, 본 연구에서는 지반함몰의 주요 영향 인자를 도출하고, 이를 인공지능 기반 예측모델의 입력 변수로 활용하기 위한 변수 구성과정을 다음절에 제시하였다.
Table 1.
Ground subsidence causes in Gwangju (2019-2023)
| Cause of Occurrence | Number of Cases | Percentage (%) |
| Pipeline Damage | 79 | 64.8 |
| Unknown Cause | 17 | 13.9 |
| Poor Compaction | 15 | 12.3 |
| Heavy rainfall | 6 | 4.9 |
| Others | 5 | 4.1 |
| Total | 122 | 100.0 |
2.1.2 주요 원인 분석 및 변수 선정
지반함몰은 다양한 인위적·자연적 요인이 복합적으로 작용하여 발생하는 현상이다. 최근 5년간의 지반함몰 통계분석에 따르면, 전국적으로 발생한 지반함몰의 주요 원인 중 일부는 관로 손상이 전체의 약 38%로 가장 높은 비율을 차지하였다. 그 외에도 다짐 불량 11%, 집중호우 5.7%, 인근 공사 6.6% 등이 주요 원인으로 나타났다(Kim et al., 2025). 연구 대상 지역인 광주광역시에서도 관로 손상이 64.8%로 가장 높은 비율을 보였으며, 다짐 불량과 집중호우 등이 주요 원인으로 나타났다(Table 1). 따라서, 지반함몰 발생에 영향을 미치는 주요 원인은 강수량, 지하 매설물, 지질 특성, 지하수위, 주변 굴착 공사 등으로 확인되었다.
본 연구에서는 공공데이터를 기반으로 확보 가능한 변수 중 강수량, 노후건물수, 지질정보를 주요 입력변수로 선정하였다. 강수량은 지반함몰이 주로 장마철에 집중되는 계절적 특성과 밀접하게 관련되어 있으며, 특히 집중호우가 주요 원인으로 지적된 점을 고려하였다. 또한 지반함몰과 누적강수량의 상관성을 제시한 기존 연구를 참고하여(Choi et al., 2022), 단기 및 장기적 수문학적 특성을 반영하기 위해 7일 누적 강수량과 30일 누적 강수량을 추가 변수로 포함하였다.
한편, 지하시설물의 밀집도 및 노후화 정도는 지반함몰에 영향을 미치는 주요 인자중 하나로 알려져 있다(Kim et al., 2021). 그러나 지하매설물의 노후화 상태를 직접 반영할 수 있는 공개 자료가 부재하므로, 본 연구에서는 이를 대체할 수 있는 지표로 노후건물수를 활용하였다. 이는 노후 건물 하부에 노후 관거가 밀집되어 있을 가능성이 높다는 가정에 근거한 것이다.
이와 같이 본 연구에서 사용된 변수들은 모두 공공데이터를 기반으로 수집되었기 때문에, 지반함몰과 같은 복합적인 발생 메커니즘을 완전히 반영하기에는 한계가 존재한다. 그럼에도 불구하고, 본 연구는 공공 데이터만을 활용하여 인공지능 학습용 데이터셋을 구축하고, 이를 기반으로 지반함몰 예측을 시도하였다는 점에서 의미가 있다.
2.2 데이터 수집 및 공간 변수 매핑
본 연구에서는 수집된 공공데이터를 공간정보 기반의 학습 데이터로 구축하였다. 공간 매핑 및 시각화 과정에는 오픈소스 지리정보시스템 소프트웨어인 QGIS를 활용하였다(QGIS Development Team, 2024). 연구 대상 지역은 약 5km 간격의 격자(grid) 레이어로 구분하였으며, 총 5x6개의 격자(30개 구간)를 설정하여 공간적 이질성을 반영하였다. 격자 크기는 분석 효율성과 데이터 분해능을 동시에 고려하여 여러 차례 검토 후 결정하였다. 격자가 지나치게 크면 공간적 특성이 단순화되어 모델 학습의 정확도가 저하되고, 반대로 지나치게 작을 경우 데이터 구축 및 매핑 과정에서 과도한 연산과 시간이 소요되므로, 5km 간격이 최적의 균형을 제공한다고 판단하였다.
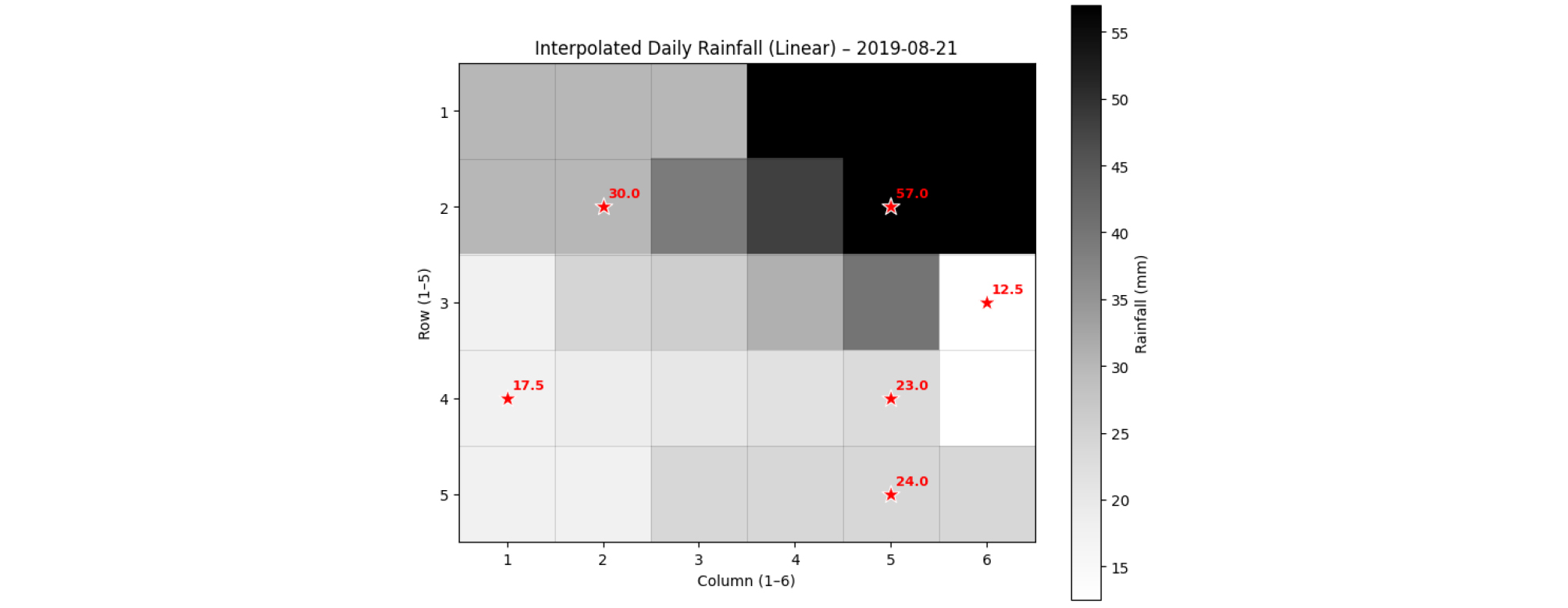
강수량 데이터는 기상청 방재기상관측망(Automatic Weather System, AWS)에서 수집하였다. 연구 대상 지역 내에는 총 6개의 관측소가 위치하여, 이를 기반으로 각 격자 구간별 일 강수량을 추정하기 위해 정규 크리깅(Ordinary kriging) 공간보간 기법을 적용하였다(Cho and Jeong, 2006). Fig. 2는 2019년 8월 21일의 일 강수량 보간 결과를 나타낸 것으로, 별표(★) 표시는 관측소의 위치를 의미한다. 보간된 일 강수량 자료를 기반으로 누적 강수량을 계산하였으며, 초기 구간(2019년 1월)의 데이터 불연속성을 보완하기 위해 연구기간 이전(2018년 12월)의 강수량 자료를 추가로 활용하였다. 이를 통해 최종적으로 7일 누적 강수량 및 30일 누적 강수량을 산정하였다.
지질정보는 지오빅데이터 오픈 플랫폼에서 제공하는 1:250,000 축척의 전국 수치지질도를 활용하여 연구 대상 지역의 광역 지질 특성을 반영하였다. 대상 지역의 지질은 세립질 화강암, 편마암, 화강암, 충적층, 산성 화산암, 염기성 화산암 등 6가지로 분류되었다. 하나의 격자 내에 복수의 지질 정보가 포함되는 경우에는 격자 구간에서 비율이 가장 큰 지질을 해당 격자의 대표 지질로 선정하였으며, 선정된 지질 범주는 모델 입력을 위해 원-핫 인코딩(one-hot encoding)으로 변환하여 변수로 사용하였다.
노후건물 수는 앞서 언급한 바와 같이 해당 지역의 노후 관로 분포를 간접적으로 반영할 수 있는 지표로 활용하였다. 일반적으로 노후 건물 하부에는 노후화된 상·하수도관 및 매설물이 분포할 가능성이 높아, 지반함몰 발생 확률을 증가시킬 수 있다. 이에 따라 생활안전지도 서비스에서 제공하는 건축물 연령 정보를 활용하였으며, 건축 후 30년 이상 경과한 건축물의 수를 공간 구간별로 집계하여 변수로 사용하였다.
지반함몰 발생 위치는 공공데이터포털(Open API)을 통해 제공되는 지하안전정보 시스템의 발생 주소 좌표(위도·경도)를 이용하여 공간 매핑하였다. 이와 함께, 앞서 선정한 강수량, 지질정보, 노후건물수를 각각의 격자 구간에 매핑하여 구역별 변수 데이터를 구축하였으며, 동시에 각 구간의 지반함몰 발생 여부(0 또는 1)를 대응시켜 학습용 데이터셋을 완성하였다. 날짜 정보는 단순히 데이터 구축의 기준으로 활용되었기 때문에 데이터셋에서는 제외하였다.
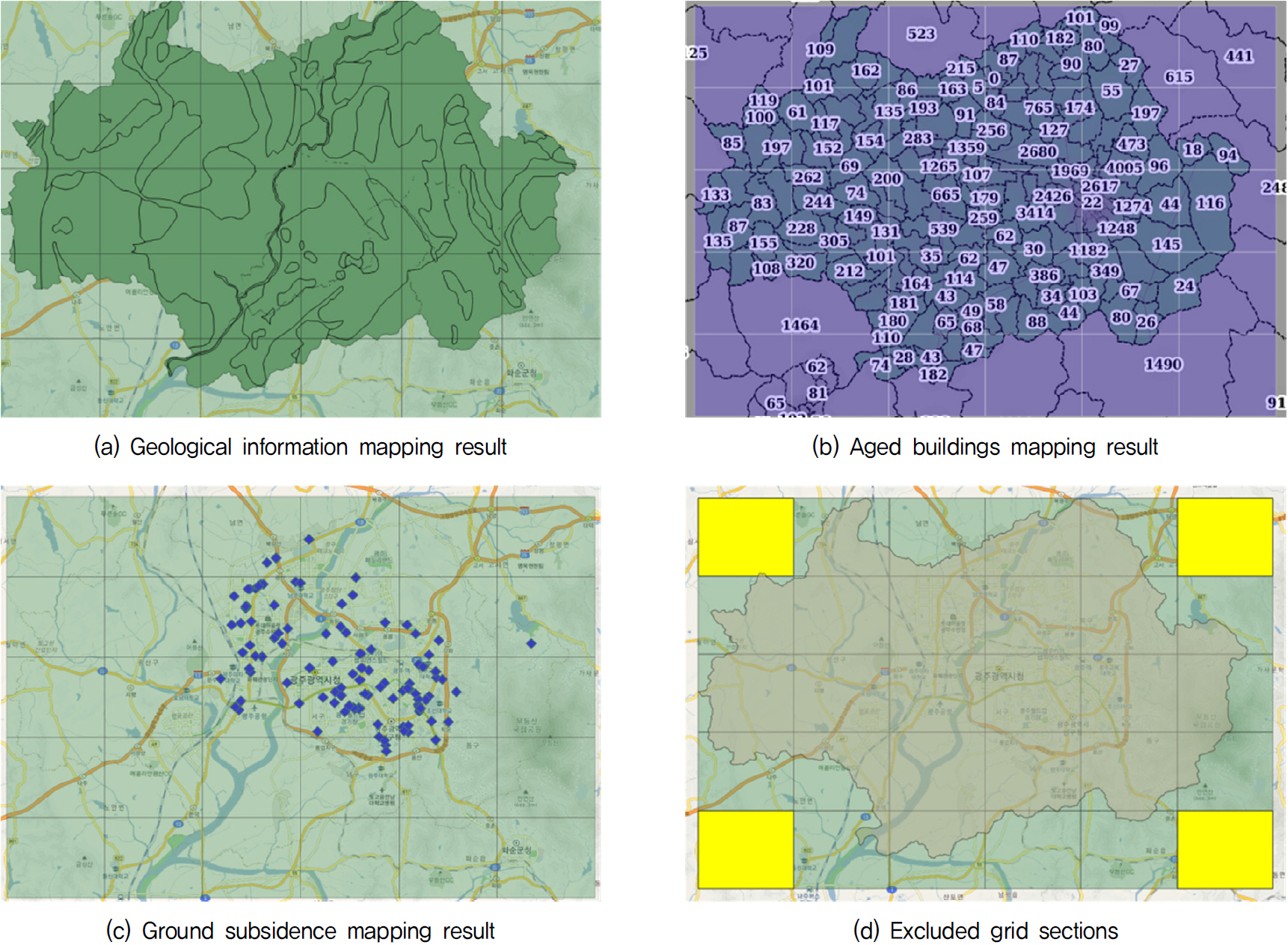
최종적으로 구축된 데이터셋은 강수량(일 강수량, 7일 및 30일 누적 강수량), 지질정보, 노후건물수, 구간, 지반함몰 발생 여부로 구성되며, 그 일부를 Table 2에 제시하였다. 각 변수의 공간 매핑 결과는 Fig. 3에 나타내었으며, 연구 대상 외곽에 해당하는 4개의 구간은 유효 데이터가 부족하여 학습에서 제외하였다(Fig. 3(d)의 노란색 영역). 이와 같이 구축된 공간 매핑 결과를 바탕으로, 다음절에서는 변수 간 상관성 분석 및 최종 데이터셋 구성을 기술하였다.
Table 2.
Summary of variable mapping results for the study area
| Region |
rainfall [mm] |
rainfall (7d) [mm] |
rainfall (30d) [mm] | Geology type | Aged Buildings | Occur |
| 2 | 0.17 | 0.17 | 0.17 | PCEsgrgn | 15695 | 0 |
| 25 | 12.5 | 21.37 | 25.66 | Kav | 8648 | 1 |
2.3 변수 간 상관성 분석 및 최종 데이터셋 구성
본 연구에서는 앞서 구축한 변수들을 기반으로 인공지능 학습을 수행하기에 앞서, 데이터 전처리 과정을 수행하였다. 이를 위해 변수 간 다중공선성(Multicollinearity)을 검토하고 상관관계 분석을 통해 입력 변수의 독립성을 확보하였다. 다중공선성은 독립 변수 간 상관성이 높을 경우 모델의 안정성과 예측 정확도를 저하시킬 수 있는 요인으로, 이를 사전에 확인하여 제거하는 과정이 필요하다. 본 연구에서는 다중공선성 진단을 위해 분산팽창계수(Variance Inflation Factor, VIF)와 피어슨 상관계수(Pearson Correlation Coefficient)를 병행하여 분석하였다.
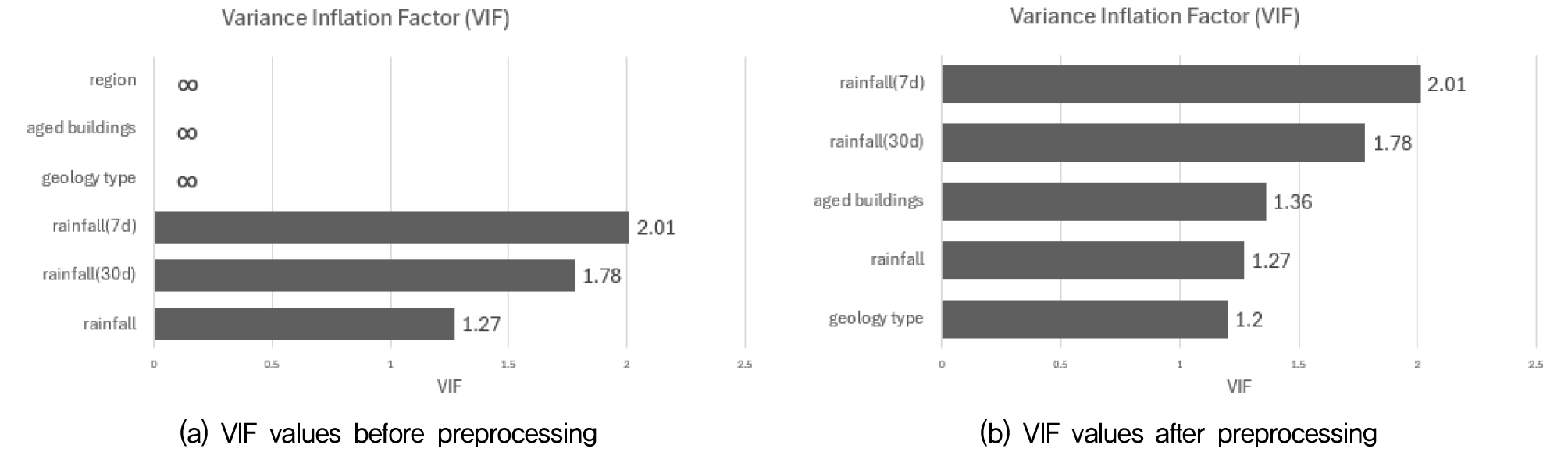
분산팽창계수(VIF)는 각 변수의 분산이 다른 변수들과의 선형 상관관계로 얼마나 팽창되었는지를 나타내는 지표로, 일반적으로 10을 초과할 경우 다중공선성이 존재한다고 판단한다(Shrestha, 2020). 본 연구의 초기 변수들에 대해 VIF를 산정한 결과, 지질정보, 노후건물수, 구간(Region) 변수에서 무한대(∞) 값이 도출되어 강한 공선성이 존재함을 확인하였다. 이에 따라 세 변수 중 지반함몰 발생에 직접적인 영향을 미치는 지질정보와 노후건물수를 유지하고, 구간 변수는 제거하였다. 전처리 전후 VIF 분석 결과는 Fig. 4에 제시하였다.
추가적으로, 변수 간 상관성을 검토하기 위해 피어슨 상관계수 분석을 수행하였다. 피어슨 상관계수는 두 변수 간 선형 관계의 강도를 –1에서 1사이의 값으로 표현하며, 절댓값이 0.8 이상일 경우 높은 상관성을 가지는 것으로 간주된다(Shrestha, 2020). 본 연구에서는 수치형 변수인 일 강수량, 7일 누적 강수량, 30일 누적강수량, 노후건물수를 대상으로 분석을 수행하였다. 분석 결과, 상관계수의 최대값은 0.66으로 나타나, 높은 상관성을 가지는 변수는 존재하지 않는 것으로 확인되었다. 피어슨 상관계수 분석 결과는 Fig. 5에 제시하였다.
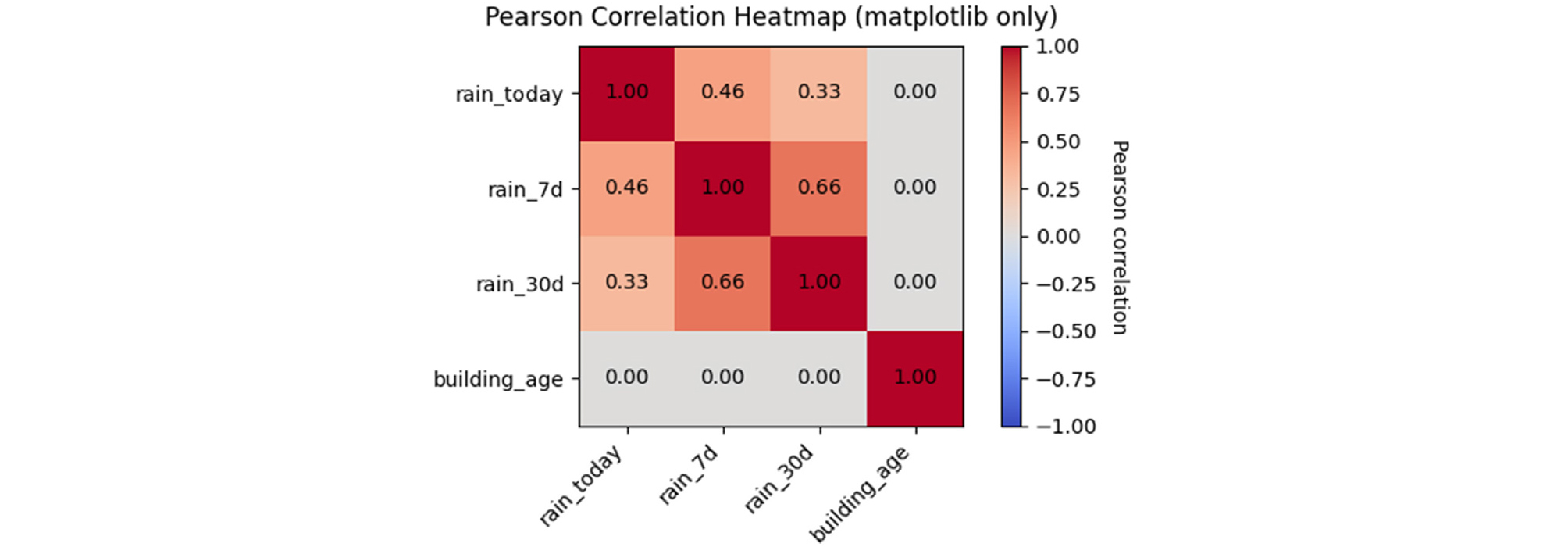
이상의 검토를 통해 본 연구에서는 일 강수량, 7일 및 30일 누적 강수량, 노후건물수, 지질정보를 최종 입력 변수(Input data)로 선정하였다. 출력 변수(Output data)는 원인 불명이 제외된 105건의 지반함몰 발생 데이터로 구성하였다. 데이터 전처리 과정에서 중복값을 제거한 후, 최종적으로 총 33,645개의 데이터셋을 구축하였다. 이 중 비발생(Negative, 0)데이터는 은 33,540개(99.69%), 발생(Positive, 1) 데이터는 105개(0.31%)로, 지반함몰 데이터는 현저히 불균형한 클래스 분포를 보였다. 이는 실제 지반함몰 현상이 매우 희귀하게 발생하는 현상을 반영한 결과로, 인공지능 모델 학습 시 클래스 불균형 보정을 위한 과정이 필요함을 의미한다(Kumar et al., 2021) (Table 3).
3. 인공지능 기반 예측 모델 구축 및 결과 분석
3.1 불균형 처리 및 평가 지표
3.1.1 불균형 데이터 처리 기법
본 연구에서는 앞서 선정된 학습 변수(일 강수량, 누적 강수량 7일·30일, 노후건물수, 지질 정보)를 입력 변수로 활용하였으며, 출력 변수는 지반함몰 발생 여부(발생: 1, 비발생: 0)를 나타내는 이진 분류 형태로 구성하였다. 데이터셋의 클래스 비율은 발생(Positive) 0.31%, 비발생(Negative) 99.69%로, 심한 불균형 특성을 보였다. 이러한 데이터 불균형은 모델 학습 시 소수 클래스(지반함몰 발생)의 인식률을 저하시킬 수 있으므로, 학습 단계에서 불균형 완화를 위한 보정 기법이 필요하다.
본 연구에서는 불균형 데이터의 특성과 지반함몰 발생 변수의 특성을 고려하여, 다음의 대표적인 네 가지 데이터 불균형 처리 기법을 비교·적용하였다.
• Random Undersamping : 다수 클래스의 표본을 무작위로 제거하여 소수 클래스의 표본 수에 맞추는 기법이다. 계산 비용이 낮고 구현이 간단하다는 장점이 있으나, 다수 클래스의 데이터가 손실되어 정보의 다양성이 감소할 수 있다. 해당 기법의 개념도는 Fig. 6(a)에 나타내었다.
• SMOTE(Synthetic Minority Over-sampling Technique): K-최근접이웃(K-Nearest Neighbors) 알고리즘을 기반으로 소수 클래스의 주변 데이터를 보간하여 인공 데이터를 생성하는 방식이다(Chawla et al., 2002). 이를 통해 소수 클래스의 학습 다양성을 확보할 수 있으나, 노이즈가 함께 증폭될 위험이 있다. 해당 기법의 개념도는 Fig. 6(b)에 제시하였다.
• Class Weight Adjustment: 손실 함수(Loss function)에 클래스별로 서로 다른 가중치를 부여하여, 모델이 소수 클래스를 더 중요하게 인식하도록 하는 방법이다(Mulyanto et al., 2020). 각 클래스의 비율에 따라 자동으로 가중치가 계산되므로 효율적이나, 가중치가 과도할 경우 과적합이 발생할 수 있다.
• Focal Loss: Lin et al.(2017)에 의해 제안된 방법으로, 손실 함수의 형태를 조정하여 예측이 어려운 샘플에 더 큰 가중치를 부여한다. 예측 확률이 높은 샘플의 가중치는 감소하고, 예측이 어려운 샘플의 가중치는 증가함으로써, 모델이 어려운 사례에 집중하여 학습할 수 있도록 유도한다. 이는 불균형한 데이터셋을 다루는 딥러닝 모델에서 효과적인 접근법으로 알려져 있다.
3.1.2 사용 모델
본 연구의 예측 모델은 지반함몰의 발생 여부를 판단하는 이진 분류 모델로 구성하였다. 입력 변수들 간에는 비선형적 관계가 존재할 가능성이 높으므로, 비선형 패턴 학습에 강한 다음 세 가지 알고리즘을 비교·적용하였다.
• DNN(Deep Neural Network): 다중 은닉층을 통해 복잡한 비선형 관계를 학습할 수 있는 심층 신경망 기반의 모델이다. 비선형 함수의 조합을 통해 변수 간 비선형 상호작용을 효과적으로 학습할 수 있다는 장점이 있다.
• Random Forest Classifier(Breiman, 2001): 다수의 의사결정나무(Decision Trees)를 무작위로 학습시킨 후 결과를 결합하는 Bagging 기반 앙상블 기법으로, 과적합에 강하고 변수 중요도 해석이 용이하다.
• XGBoost(Extreme Gradient Boosting)(Chen and Guestrin, 2016): 기존 Gradient Boosting 알고리즘을 개선한 모델로, 약한 학습기를 순차적으로 결합하여 예측 성능을 향상시킨 Boosting 기반 알고리즘이다. 규제항(Regularization)과 학습률(Learning rate) 제어를 통해 정확도와 계산 효율성을 동시에 확보할 수 있다.
위 세 가지 모델의 개념적 구조는 Fig. 7에 나타내었다.
3.1.3 평가지표
본 연구의 모델 성능 평가는 혼동행렬(Confusion matrix)을 기반으로 수행하였다. 주요 평가지표로는 정밀도(Precision), 재현율(Recall), F1-score를 사용하였으며, 불균형 데이터셋에서의 민감도와 정밀도 간 균형을 시각적으로 확인하기 위해 Precision-Recall Curve(PRC)를 추가적으로 활용하였다(Davis and Geadrich, 2006).
혼동행렬의 기본 구조는 Table 4와 같이 표현되며, 참/거짓 및 양성/음성의 조합으로 네 가지 결과를 생성한다. 즉, 실제 양성(True Positive, TP), 실제 음성(True Negative, TN), 거짓 양성(False Positive, FP), 거짓 음성(False Negative, FN)으로 구분된다.
정밀도, 재현율, F1 score의 정의는 다음과 같다.
PRC 곡선은 정밀도와 재현율 간의 관계를 나타내며, 소수 클래스의 예측 성능에 민감하게 반응한다. 불균형 데이터셋에서 모델의 유용성을 평가할 때 적합한 지표로, Baseline은 무작위 분류기의 양성 비율을 의미한다. PRC 곡선이 Baseline보다 위에 위치할수록, 모델이 어려운 데이터에서도 상대적으로 우수한 분류 성능을 보인다고 해석할 수 있다(Saito and Rehmsmeier, 2015).
본 연구는 발생 비율이 매우 낮은 극심한 불균형 데이터셋을 대상으로 하였기 때문에, F1- score만으로는 모델의 종합적 성능을 평가하기 어렵다고 판단하였다. 따라서 PRC 곡선의 면적을 의미하는 AUPRC(Area Under the Precision-Recall Curve)을 추가적인 성능 지표로 사용하였다. 관련 개념도는 Fig. 8에 제시하였다.
3.2 모델 구조 및 학습 설정
본 연구의 전체 데이터는 학습용 70%, 테스트용 30%으로 분할하였으며, 학습 데이터의 20%는 검증 데이터로 사용하였다. 각 모델의 학습은 Table 5에 제시된 하이퍼파라미터 설정값을 기반으로 반복 수행하였다.
Table 5.
Hyperparameter tuning for each classification model
딥러닝 모델인 DNN의 경우, 다양한 은닉층 구조를 조합하여 실험적으로 검토한 결과, 64-32-1 구조가 안정적이며 우수한 성능을 보였다. 모델의 일반화 성능 향상을 위해 Dropout 비율은 0.3으로 설정하였으며, 과적합을 방지하기 위해 EarlyStopping 기법을 적용하였다. 또한, 학습 데이터의 효율적 활용을 위해 3-Fold 교차검증을 수행하여 학습 효율을 향상시키고자 하였다.
트리 기반 모델인 Randomforest 및 XGBoost의 경우, RandomizedSearchCV를 이용한 하이퍼파라미터 자동탐색을 수행하였다. 이후 탐색된 최적 하이퍼파라미터를 고정하여 모든 학습과정에 일관되게 적용하였다. Table 5는 각 모델의 주요 학습 구조와 불균형 데이터 처리 방식에 대한 설정을 요약한 것이다.
불균형 데이터 처리는 앞서 제시한 네 가지 기법을 단계적으로 비교·적용하였다. 먼저, Class weight는 트리 기반 모델에서 자동 가중치 방식으로 적용되어, 소수 클래스의 중요도를 반영하였다. Focal loss는 DNN 모델에 적용하여, 학습 시 소수 클래스의 학습 효과를 강화하였다. 한편, Undersampling과 SMOTE는 데이터 비율 조정을 통해 학습 조건의 차이를 비교하기 위해 적용하였으며, 정상:비정상 비율을 1:2, 1:5, 1:10으로 설정하여 다양한 조건을 실험하였다. 모든 모델은 불균형 처리 여부와 관계없이 임계치(Threshold)를 자동 탐색하여 최적의 F1-score를 도출하였으며, 이를 통해 각 모델별 성능 차이를 비교·분석하였다. 임계치 최적화는 검증 데이터셋(Validation set)을 기반으로 수행하였으며, 검증 단계에서 도출된 최적 임계치는 최종 테스트 평가 시 동일하게 적용하였다.
3.3 학습 결과 및 분석
본 연구에서는 주요 평가지표로 F1-score와 AUPRC (Area Under Precision-Recall Curve)를 사용하였다. 동일한 학습 조건(3.2절)에서 각 모델별 학습을 수행하였으며, F1-score 결과는 Fig. 9와 Table 6에 정리하였다. 본 연구에서 사용된 데이터는 지반함몰 발생 비율이 약 0.3%로 매우 불균형하며, 강수량 변수 또한 비선형성이 강하고 예측이 어려운 특성을 가진다. 이러한 데이터 구조로 인해, 발생 데이터의 부족과 불균형 처리 과정에서 노이즈 유입으로 모델의 F1-score가 전반적으로 낮게 나타난 것으로 판단된다.
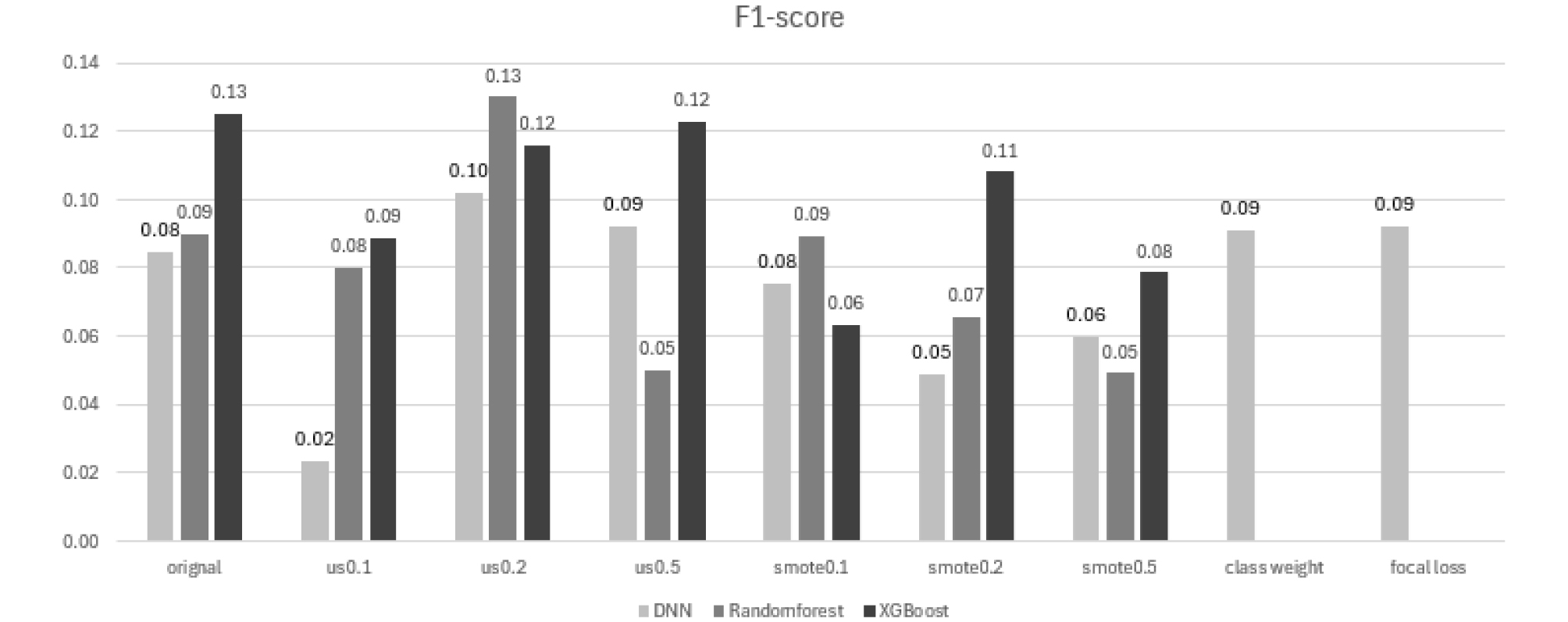
Table 6.
F1-scores of each classification model
F1-score 결과를 중심으로 살펴보면, 세 모델 중 불균형 처리를 수행하지 않고 자동 임계치를 적용한 XGBoost 모델이 가장 높은 예측 성능을 보였다. 대부분 불균형 처리 기법(Undersampling, SMOTE, Class weight, Focal loss)에서도 XGBoost 모델의 상대적 성능이 우수하게 나타났다. 특히, 모든 모델에서 불균형 처리를 수행하지 않은 원본 데이터의 F1-score가 가장 높게 나타났는데, 이는 지반함몰과 같이 발생 빈도가 낮고 불확실성이 큰 사건의 경우, 단순 데이터 비율 조정이 실제 분포를 왜곡하거나 노이즈를 유발할 가능성이 있음을 시사한다(Kim, 2021).
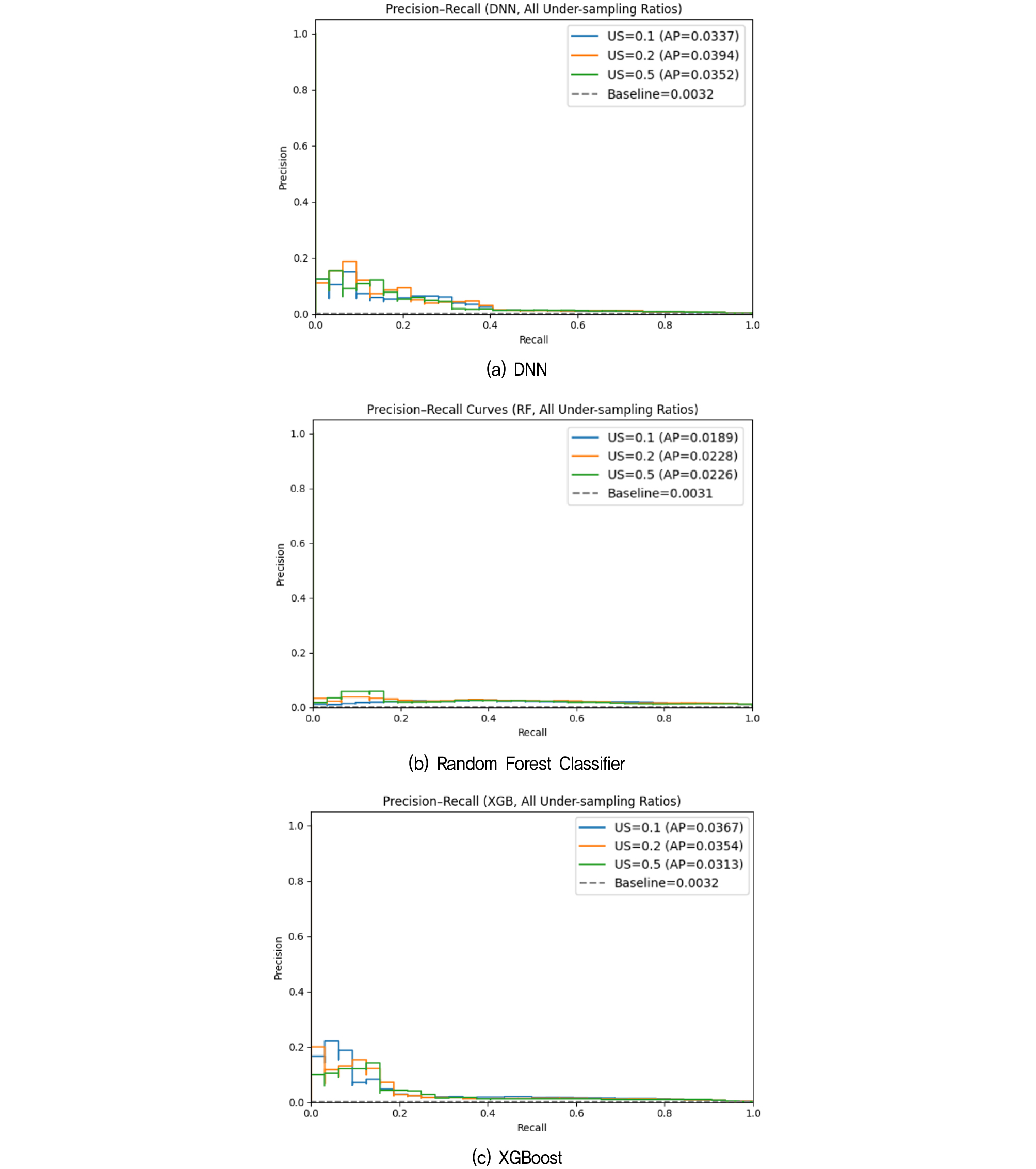
F1-score는 지반함몰 발생과 같이 클래스 불균형이 극심한 데이터에서 모델의 탐지 성능을 충분히 반영하지 못할 수 있다(Richardson et al., 2024). 이에 본 연구에서는 Precision-Recall Curve (PRC)를 추가적으로 활용하여 모델의 세부 성능을 평가하였다. 불균형 처리 기법을 적용하지 않은 원본데이터의 PCR 결과는 Fig. 10에 제시하였다. Baseline(Positive ratio)은 0.0032로 매우 낮게 나타났으나, 세 모델 모두 Baseline을 상회하는 곡선을 형성하여 일정 수준의 분류 성능을 확보한 것으로 확인되었다.

모델별로 비교해 보면, 딥러닝 기반 DNN보다 트리 기반 모델(Random Forest, XGBoost)의 PRC 곡선이 전반적으로 상위에 위치하였다. 특히, XGBoost는 지반함몰과 같은 비선형·복합적 관계를 효과적으로 학습하여, 상대적으로 높은 정밀도-재현율 균형을 달성하였다.
Undersampling 기법을 적용한 경우, 각 모델의 PRC 곡선은 Fig. 11에 나타내었다. 데이터 수를 감소시킨 조건에서도 모든 모델의 PRC 곡선이 Baseline보다 상위에 위치하였으나, 원본 데이터 대비 곡선의 폭이 줄어들어 분류 성능이 전반적으로 저하되었다. 이는 Undersampling 과정에서 일부 데이터의 정보 손실이 발생하였기 때문으로 판단된다.
한편, SMOTE 기법을 적용한 경우의 PRC 결과는 Fig. 12에 제시하였다. DNN과 XGBoost에서는 PRC 곡선이 Undersampling 대비 상위에 위치하여 학습 효율이 향상된 것으로 나타났으나, RandomForest에서는 SMOTE 적용 시 과적합 또는 중복 샘플링으로 인한 노이즈 증가로 성능이 오히려 저하되는 경향을 보였다.
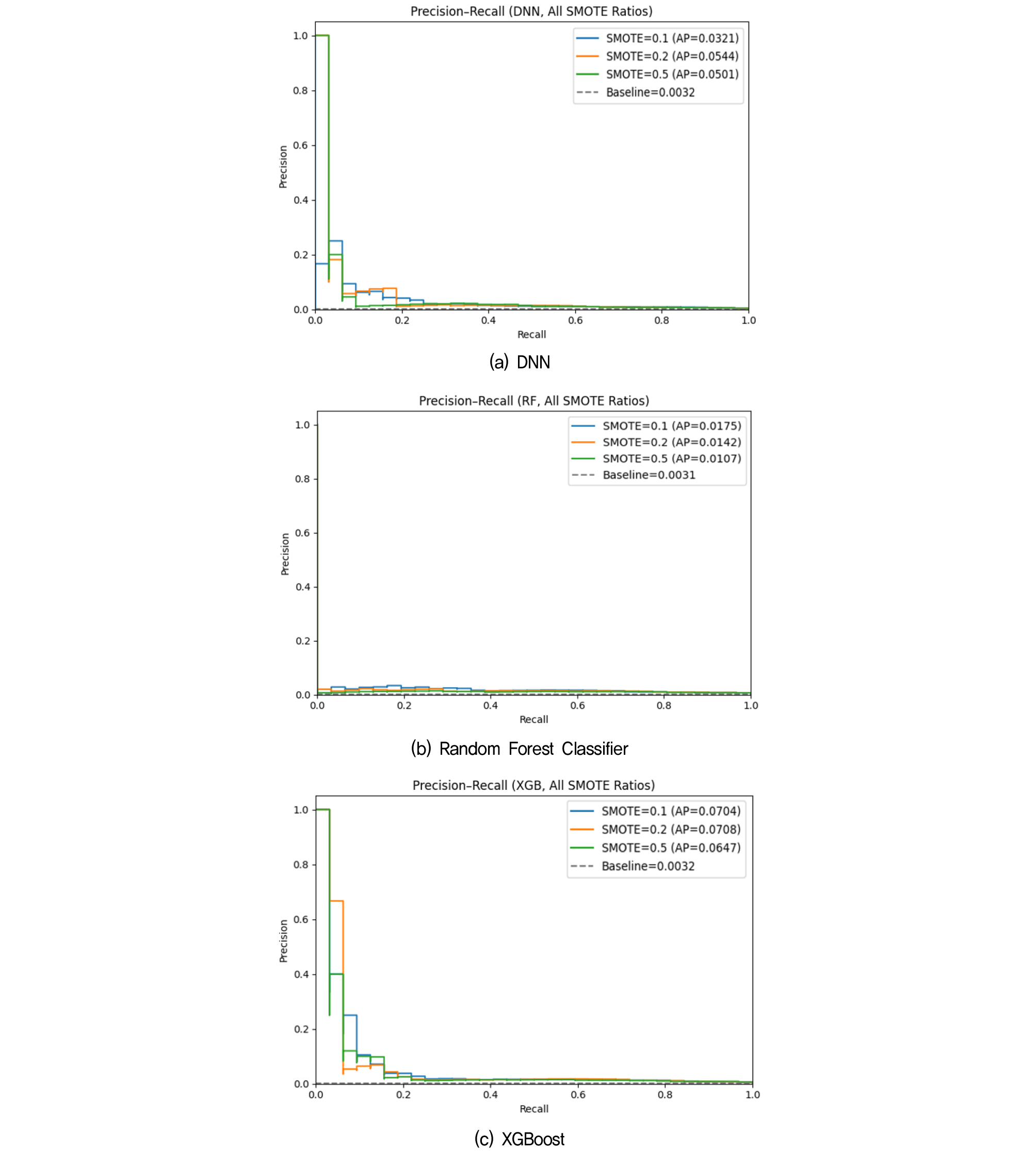
모든 모델에서 재현율(Recall)이 증가할수록 정밀도(Precision)는 감소하는 전형적인 trade-off 특성을 보였고, 이는 희귀 사건 예측에서 나타나는 일반적인 경향이다. 결과적으로 F1-score가 낮게 나타난 주요 원인은 모델의 예측 성능보다는 데이터의 극심한 불균형과 학습 데이터의 제한된 수량으로 인한 노이즈의 영향으로 해석된다. PRC 분석 결과는 F1-score와 유사한 경향을 보였다. DNN보다 Random Forest 및 XGBoost 모델이 지반함몰 발생 여부를 상대적으로 더 정확하게 분류하였으며, 특히 XGBoost 모델은 학습 안정성과 예측 성능면에서 비교적 우수한 결과를 보였다.
이상의 F1-score와 PRC 결과를 종합적으로 분석한 결과, 지반함몰과 같이 발생 확률이 극히 낮고 비선형적 특성이 강한 사건의 경우 단순한 데이터 비율 조정이나 가중치 기법만으로 불균형 문제를 해결하기 어려운 것으로 판단된다. 특히 oversampling 및 SMOTE 기반 불균형 처리 기법은 소수 클래스의 희귀 패턴뿐만 아니라 해당 클래스에 포함된 노이즈까지 함께 증폭시키는 문제가 있으며, 선형 보간 특성으로 인해 비선형적 특성이 강한 강수량 변수에서는 실제 분포를 왜곡할 가능성이 높다(Kim, 2021). 또한 클래스 가중치 조정은 모델이 소수 클래스를 과도하게 민감하게 인식하도록 만들어 false positive 증가로 이어지고, 이로 인해 정밀도(Precision)를 크게 저하될 수 있다. 이러한 이유로 본 연구에서는 불균형 처리를 적용하지 않은 원본 데이터 기반 학습이 가장 안정적인 성능을 보였다고 판단된다.
따라서, 본 연구에서는 불균형 처리를 적용하지 않은 원본 데이터 기반 학습이 가장 안정적인 결과를 보였으며, 세 모델 중에서는 트리 기반의 XGBoost 모델이 불확실한 사건을 예측하는 비교적 효과적인 모델로 나타났다.
3.4 변수 중요도 분석
비록 전체 학습 성능은 다소 낮게 나타났으나, 각 모델별로 예측 결과에 주요하게 작용한 변수를 파악하기 위하여 변수 중요도(Feature Importance) 분석을 수행하였다. 트리 기반 모델과 딥러닝 기반 모델은 변수 중요도 산정 방식이 상이하므로, 본 적에서는 두 모델을 구분하여 각각 분석하였다.
3.4.1 트리 기반 모델(Random Forest, XGBoost) 변수 중요도 분석
트리 기반 모델은 학습 과정에서 각 변수가 불순도 감소(Impurity reduction)에 기여한 정도를 정량적으로 평가할 수 있다(Breiman, 2001). 본 연구에서는 모델에 내장된 변수 중요도 산정 지표를 활용하여, 각 변수가 분류 성능에 기여한 상대적 비율을 계산하였다. 변수 중요도는 전체 합이 1로 정규화되며, 값이 클수록 해당 변수가 모델의 예측에 더 큰 영향을 미쳤음을 의미한다.
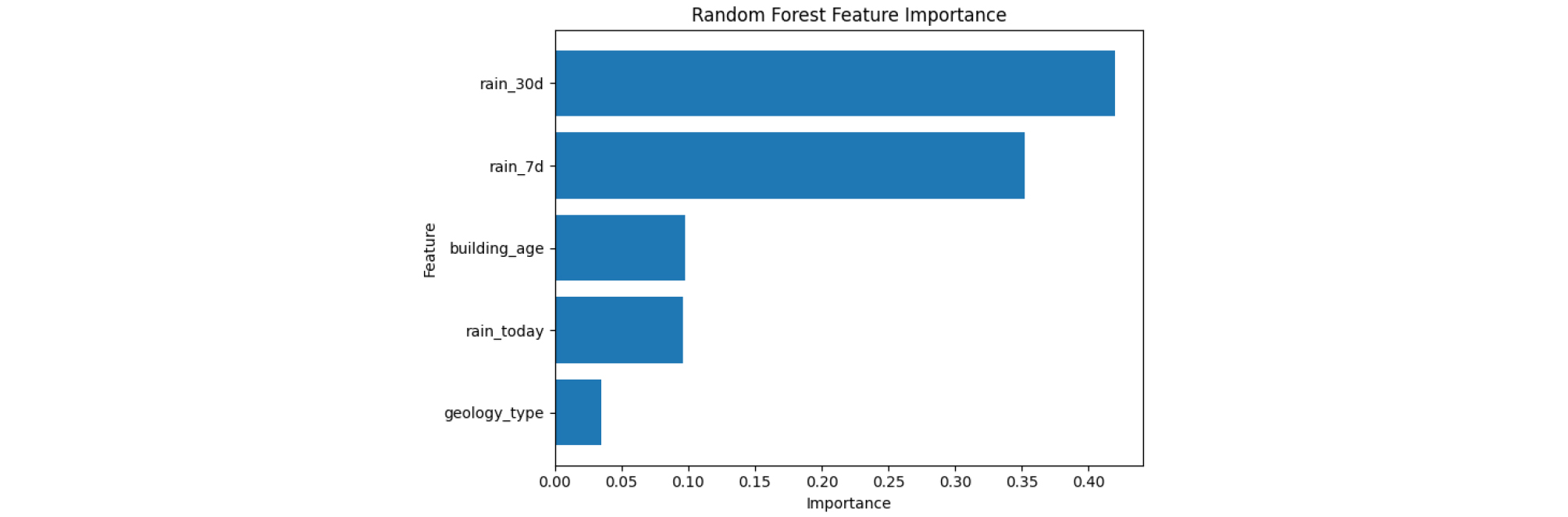
Random Forest 모델의 변수 중요도 결과(Fig. 13)에 따르면, 누적 30일 강수량과 누적 7일 강수량이 가장 높은 중요도를 보였다. 그 뒤를 노후건물수, 일 강수량, 지질정보가 차지하였다. 특히, 누적 강수량(7일, 30일)의 총 기여도가 약 75%에 달해, 강우의 지속성과 누적량이 지반함몰 발생 예측에서 핵심적 역할을 함을 보여준다.
한편, XGBoost 모델의 변수 중요도 결과(Fig. 14)에서는 노후건물수가 가장 높은 중요도를 나타냈으며, 다음으로 누적 30일 강수량, 누적 7일 강수량, 지질정보, 일 강수량 순으로 나타났다. 노후건물수의 기여도는 약 30%, 누적 강수량(7일, 30일)의 합은 약 40%를 차지하였다. 즉 XGBoost 모델은 Randomforest와 유사한 경향을 보이면서도 인위적 요인(노후건물수)의 중요도를 상대적으로 더 크게 평가하였다.
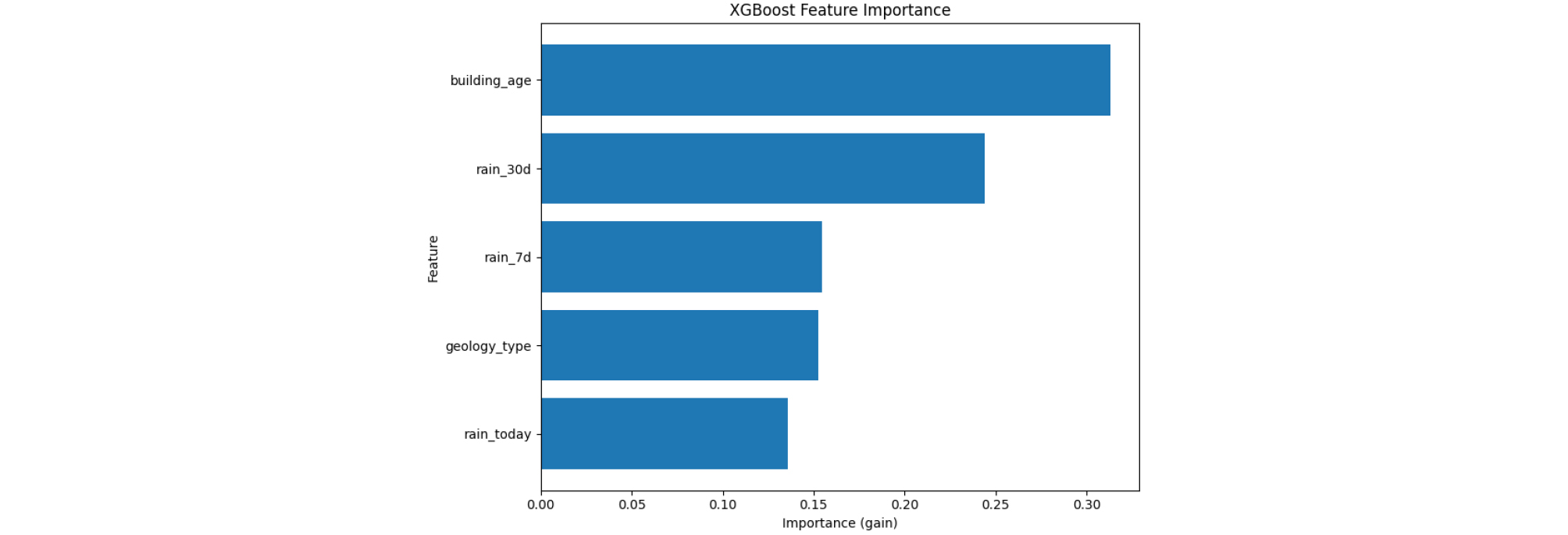
두 모델의 결과를 비교하며, 강우 관련 변수가 공통적으로 높은 중요도를 보였으며, 특히 누적 강우량(7일, 30일)은 지반함몰 발생의 주요 요인임을 확인할 수 있다. 이는 단기적 집중호우뿐만 아니라 장기적인 누적 강수의 영향이 토사 유실 및 관로 주변 지반 약화에 영향을 미치는 것으로 해석할 수 있다. 또한 노후 건물수는 인위적 기반 시설의 영향을 간접적으로 반영하는 변수로, 도시지역 지반함몰의 잠재적 취약성을 보여주는 유효한 지표임을 보여준다.
트리 기반 모델의 변수 중요도 분석 결과는 이후 제시할 딥러닝(DNN) 모델의 가중치 기반 변수 영향도 분석과 비교하여 종합적으로 해석하였다.
3.4.2 DNN 모델 SHAP(Shapley Additive exPlanations) 분석
딥러닝 기반 모델(DNN)은 트리 기반 모델과 달리 변수 중요도 지표가 존재하지 않기 때문에, 본 연구에서는 SHAP(Shapley Additive exPlanations) 분석 기법(Lundberg and Lee, 2017)을 활용하여 각 입력 변수의 기여도를 정량적으로 평가하였다. SHAP 분석은 게임이론의 셰플리 값(Shapley value)을 기반으로, 개별 예측값에 대해 각 입력 변수가 모델의 예측 결과에 미치는 영향을 정량적으로 산출하는 방법이다. 즉, 각 변수의 변화가 모델 출력(예측 확률)에 미치는 평균적인 영향도를 계산함으로써, 모델의 ‘결정 과정’을 해석 가능하게 한다.
본 연구에서 계산된 SHAP 값은 전반적으로 낮은 수준을 보였는데, 이는 지반함몰의 발생 확률 자체가 매우 낮기 때문에 모델 출력 확률이 작게 산정된 결과로 해석된다. 따라서 절대적인 SHAP 값의 크기보다는 변수 간 상대적 영향력과 기여 방향성에 초점을 두어 해석하였다.
DNN 모델의 SHAP 결과는 Fig. 15에 나타내었다. Fig. 15(a)는 각 변수의 값에 따른 SHAP 값의 분포를 보여주는 Beeswarm plot으로, 색상은 변수의 실제 값(고/저)을, 수평축은 모델 출력에 대한 영향도를 의미한다. Fig. 15(b)는 모든 데이터 샘플에 대한 SHAP 절댓값의 평균을 나타낸 평균 중요도 결과이다.
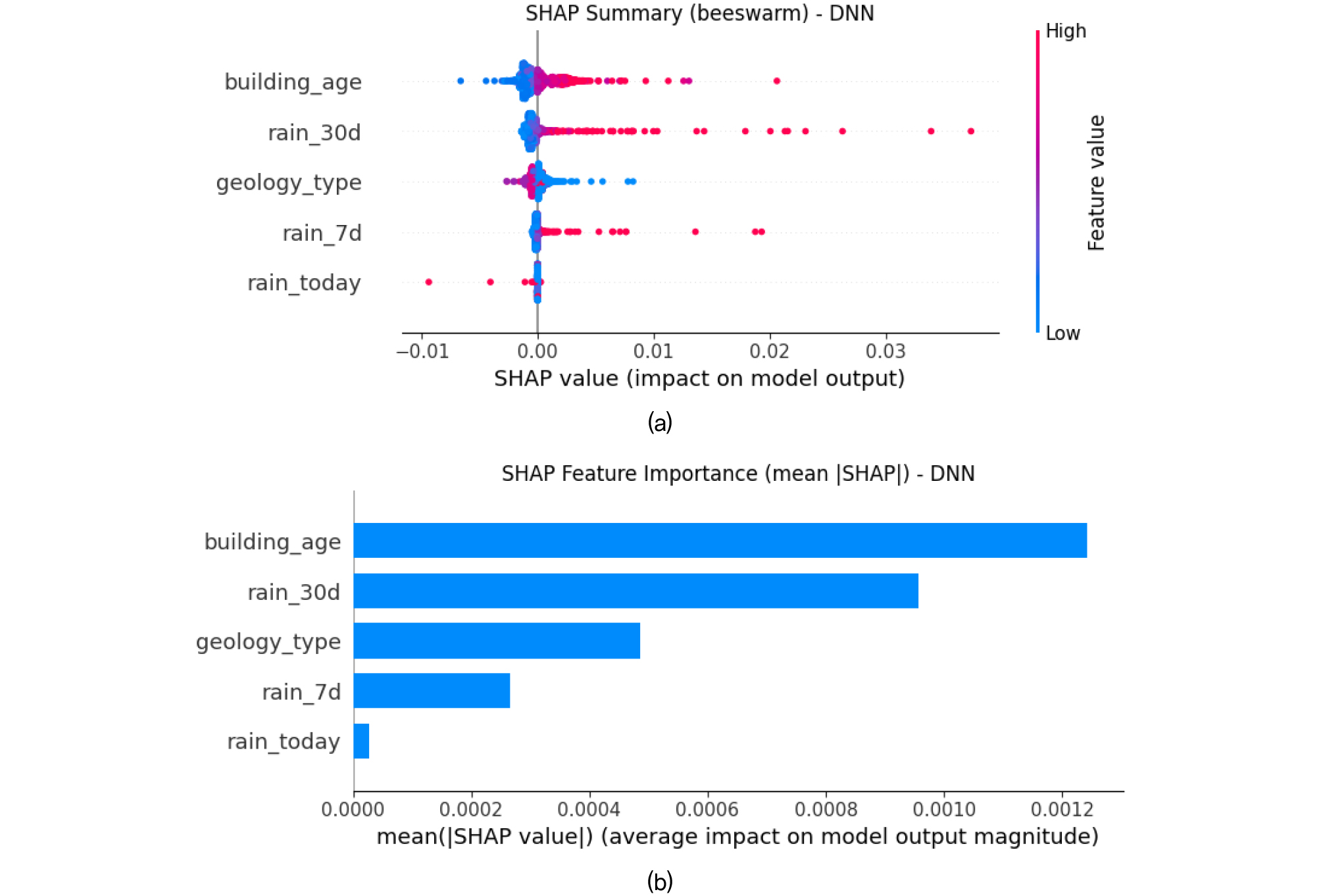
분석 결과, 노후건물수와 누적 30일 강수량이 가장 높은 중요도를 보였으며, 그 다음으로 지질정보, 누적 7일 강수량, 일 강수량 순으로 나타났다. 특히 Fig. 14(a)에서 확인되듯이, 노후건물수 값이 증가할수록 SHAP 값이 양의 방향으로 커지는 경향을 보여, 노후건물이 밀집된 지역일수록 지반함몰 발생 확률이 높아짐을 알 수 있다. 또한, 누적강수량(7일 및 30일) 역시 값이 증가할수록 양의 SHAP 값이 커지는 것으로 나타나, 장기적 강우 영향이 지반함몰 발생 확률을 증가시키는 주요 요인임을 확인하였다.
세 모델(DNN, Random Forest, XGBoost)의 변수 중요도 결과를 종합적으로 비교하면, 노후건물수와 누적 30일 강수량이 공통적으로 높은 중요도를 보였다. 이는 지반함몰 발생이 단기적 강우보다는 장기적인 누적 강수량과 인위적 노후화(매설물 노후화)에 의해 복합적으로 영향을 받음을 시사한다. 또한, 지질 정보 변수 역시 DNN 모델에서 상대적으로 높은 기여도를 보였는데, 이는 지역별 지반 구성 특성(예, 화강암질 기반, 충적층, 사질층 등)이 강우 침투 특성 및 지반 구조 차이를 유발하기 때문으로 해석할 수 있다.
결과적으로, 지반함몰은 단일 요인으로 설명하기 어려운 복합·누적 현상으로, 지속적인 강수 영향(누적 강수량)과 지하매설물의 노후화에 따른 구조적 약화, 지질 특성 등이 상호작용하여 발생할 가능성이 높음을 확인하였다. 특히 본 연구는 기존 하수관 중심의 단일 자료 기반 분석과 달리(Kim et al., 2021), 강우·지질·건물 노후도 등 다양한 공공데이터를 통합하여 지반함몰의 다변량적 영향 구조를 확인했다는 점에서 차별성이 있다. 이러한 다중 요인 기반의 비교 분석을 통해, 지반함몰이 개별 요인보다 복합적·누적적 요인의 상호작용에 의해 발생함을 확인하였다. 따라서 향후 지반함몰 예방 및 체계적 관리를 위해서는 공간적·시간적 요인을 통합한 다변량 분석과 물리 기반 해석의 연계가 필요할 것으로 판단된다.
4. 결 론
본 연구에서는 공공데이터를 활용하여 지반함몰 발생 가능성을 예측하기 위한 인공지능 기반 다변량 분석을 수행하였다. 강수량, 노후건물수, 지질정보 등 주요 변수를 수집·매핑하여 학습용 데이터셋을 구축하고, 불균형 데이터 처리 기법과 세 가지 예측 모델(DNN, Random Forest, XGBoost)을 적용하였다. 모델 비교 결과, 전체적인 예측 성능은 낮게 나타났으나, 트리 기반의 XGBoost 모델이 상대적으로 가장 안정적이고 우수한 분류 성능을 보였다. 이는 지반함몰과 같이 발생 확률이 낮고 비선형성이 강한 문제에 대해 트리 기반 알고리즘이 보다 효과적으로 작동함을 보여준다. 변수 중요도 분석 결과, 모든 모델에서 노후건물수와 누적 강수량(특히 30일 누적 강수량)이 공통적으로 높은 중요도를 나타내었다. 이는 도시지역 지반함몰 발생이 단기적 요인보다는 장기적 강수 누적과 지하매설물 노후화에 의한 복합적 영향으로 발생함을 시사한다. 또한, 지질정보 역시 지역적 지반 특성을 반영하는 주요 변수로 작용하여, 지반함몰 예측 시 지역별 지질 조건을 고려한 공간적 분석의 필요성이 확인되었다. 결과적으로 본 연구는 지반함몰 예측에 있어 공공데이터 기반 인공지능 기법의 적용 가능성과 한계를 제시하였다.
다만 본 연구는 다만 본 연구는 격자 기반 데이터 구성으로 인해 공간적으로 인접한 지역 간 영향이 완전히 배제되지 않았을 가능성이 있으며, 공공데이터 사용으로 변수 해상도와 정확도에 한계가 존재한다는 점에서 한계를 가진다. 따라서 향후 연구에서는 지역 단위의 공간 검증 체계 도입, 지하매설물 상태 등 고해상도 지하 공간 정보의 확보, 나아가 강우–지하수–지반거동을 고려한 물리 기반 해석과 데이터 기반 기법의 융합을 통해 보다 정밀하고 신뢰도 높은 지반함몰 예측체계로 발전시킬 필요가 있다.
