

1. 서 론
자연재해의 일환인 산사태는 다수의 피해를 발생시켜 지반공학적인 측면의 조사를 통해 산사태 위험 지역을 사전에 설정하는 것이 필요하다. 이를 수행하기 위하여 많은 연구자들이 산사태 위험 지역을 결정하는 방법을 제시하고 활용하고 있다. Hong and Jeong(2019)는 강우로 인해 발생하는 산사태와 토석류를 복합적으로 분석할 수 있는 연계해석 기법을 제안하여 지리정보시스템 기반의 광역적인 위험 지역을 이해할 수 있는 결과를 제시하였다. Jeon et al.(2021)은 암반 비탈면에 인장균열이 발생하는 원인 및 대책 방안과 함께 전기비저항 탐사를 통해 인장균열 위치를 찾을 수 있는 방안도 제공하였다. 최근에는 벌목한 비탈면의 위험 지역을 결정할 수 있도록 무인항공기를 활용하여 영상분석 방안을 소개하고 지반공학적인 분석을 시도한 연구도 진행되었다(Kim et al., 2022). 또한 machine learning의 일환인 다층 퍼셉트론(multilayer perceptron) 신경망을 통해 사면의 안전율과 임계활동면의 관계를 도출하였으며, 이를 통해 원호 파괴면을 예측하고 위험지역을 결정할 수 있는 결과도 제시되고 있다(Ma and Yun, 2022).
한편 Jun et al.(2017)은 산사태 위험지역을 합리적으로 결정할 수 있도록 8개의 주요한 지반공학 물성치를 선정하였으며, 이는 산사태 안전점검을 다수 수행한 경험이 있는 전문가 그룹의 설문조사와 Analytic Hierarchy Process(AHP) 분석으로 수행하였다. 8개의 지반공학 물성치는 세립분 함량, 표층 두께, 간극률, 탄성계수, 전단강도, 투수계수, 포화도 및 함수비로 결정하였으며, 해당 기법은 high risk area(HRA)로 불린다. 물론 더욱 정밀하게 산사태 위험 지역을 선정하기 위해서는 지질 및 지형적인 특성이 고려되어야 하지만, 해당 방법에서는 현장을 이해하기 위해 필수적으로 수행하는 현장 조사와 소수의 실내 실험 만으로 위험 지역을 선정할 수 있도록 방법을 제시한 것에 특징이 있다. HRA 방법은 경험식으로 만들어져 각각의 지반공학 물성치 간에 단위 및 값 범위에 따라 상이한 결과를 줄 수 있는 한계가 있다. 이를 극복하고자 Min and Yoon(2021)은 machine learning 기법 기반의 deep neural network 방법으로 HRA의 활용성을 검증하였으며, 8개의 지반공학 물성치 중 위험 지역 설정에 가장 큰 영향을 미치는 인자도 제시하였다. 해당 연구에서는 이미 선행연구를 통해 검증된 HRA 방법의 활용성을 높이기 위하여 machine learning 기법 중 분류 방법을 통해 대상 위치의 안전율 분포를 예측하고자 하였다. 이를 위해 대상 사면을 1m × 1m의 정사각형의 격자로 구분하였으며, 모든 지역의 지반 공학 물성치를 획득하기에는 한계가 있어 측정된 일부 값으로 크리깅(kriging)을 통해 전체 지역의 물성치를 확보하였다. 분류 방법을 적용하기 위해서는 다양한 범위의 안전율 값에 해당하는 지반공학 물성치가 존재해야 하나, 대상 사면 특성상 일부 범위의 안전율 값만 보여주는 한계가 있다. 해당 논문에는 데이터 개수를 증폭 시킬 수 있는 oversampling 기법 중 synthetic minority over-sampling technique(SMOTE)를 적용하여 소수의 데이터 개수를 증폭하여 합리적인 분류 결과가 도출될 수 있도록 도모하였다.
해당 논문은 분류 알고리즘의 배경이론의 설명으로 시작되며, 입력 데이터를 추출하는 과정에 대해서도 설명하였다. 이를 통해 분류 결과를 도시하였으며, 최종적으로는 oversampling 기법으로 분류의 정확도를 향상시킬 수 있는 방안을 제시하였다.
2. 배경이론
2.1 분류 알고리즘
해당 논문에서 사면의 안전율 분류를 위해 사용한 방법은 decision tree(DT), K-Nearest Neighbor(KNN), logistic regression(LR) 그리고 random forest(RF)로 각각의 특징은 다음과 같다. DT는 Fig. 1(a)와 같이 의사결정나무로 다양한 의사결정 경로와 결과를 나무 형태로 표현하여 질문의 참 값과 거짓 값으로 입력 값의 최종적인 분류를 수행하는 방식이다. 질문의 형태와 종류가 최종 결과의 신뢰성에 영향을 미치며 입력 인자를 무작위로 선별해서 수행하는 bootstrap aggregation 방법이 이용된다. KNN은 목표한 데이터로부터 가장 근접한 데이터는 동일한 분류에 포함된다는 가정으로 입력 데이터의 특성을 결정하는 방식이다. Fig. 1(b)와 같이 유클리드 거리 계산 방법으로 결정된 K 값의 영향 범위를 통해 각각의 데이터 분류를 시도하는 특징이 있다. LR 방법은 확률적인 값 기반으로 입력 데이터의 분류를 수행하는 방법으로 Fig. 1(c)와 같이 입력 데이터 간의 특성을 회귀형태로 분석 후 분류를 시도한다. 해당 방법은 회귀 방식으로 데이터가 특정 값으로 분류될 가능성을 0과 1로 구분하여 확률 값으로 결과를 제공하는 특징이 있다. 마지막으로 RF는 Fig. 1(d)과 같이 다수의 의사결정나무를 가지고 있으며, 이를 통해 분류를 수행하며 Fig. 1(a)처럼 입력 데이터의 신뢰성을 증대시키기 위하여 bootstrap aggregation 방법을 적용한 후 결과를 도출한다(Kim et al., 2021).
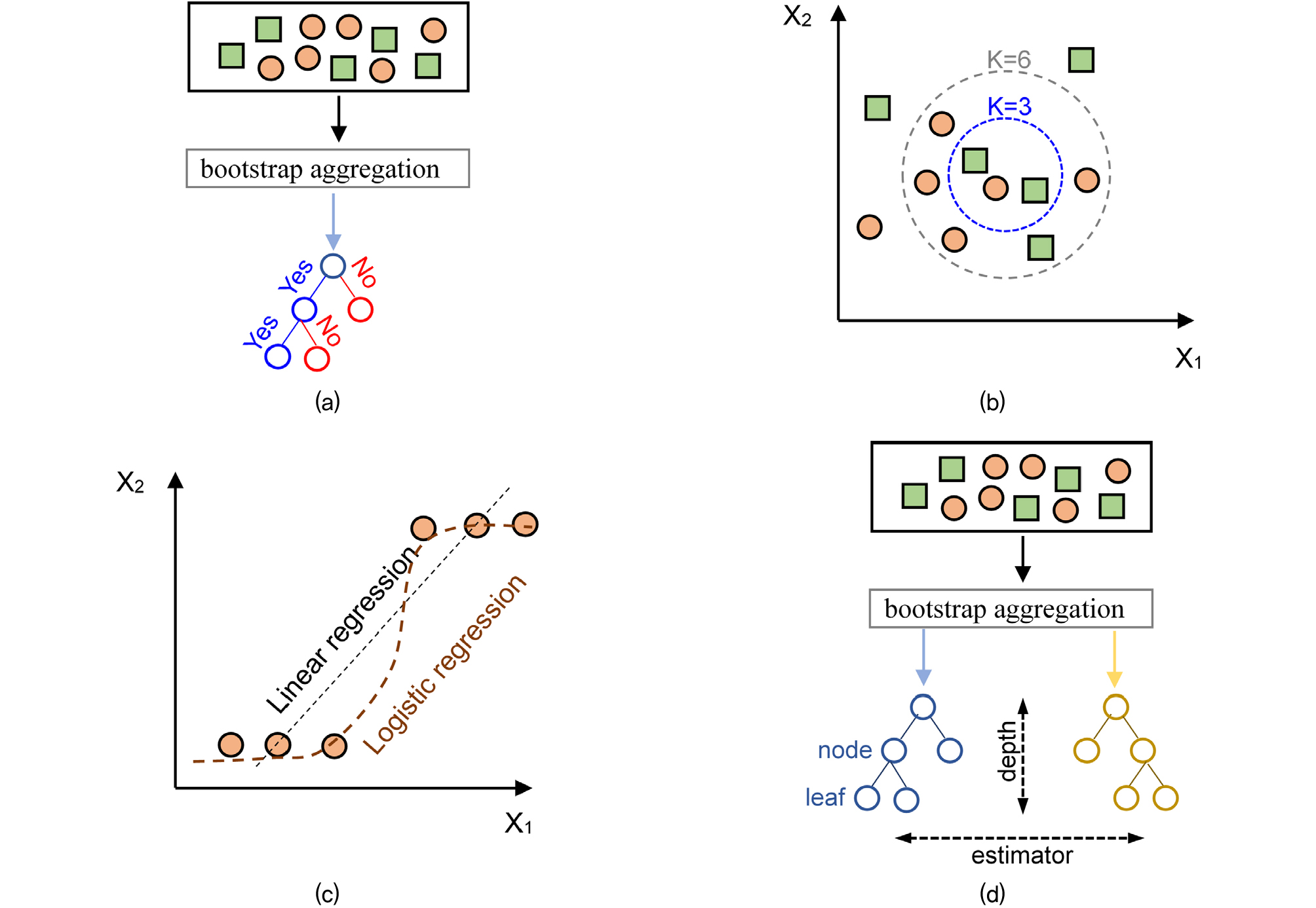
Fig. 1
Graphical explanations of applied algorithms in this study: (a) decision tree; (b) K-Nearest Neighbor; (c) logistic regression; (d) random forest. The Figure was modified with reference to a study conducted by Lee et al. (2022)
2.2 Oversampling 알고리즘
Machine learning의 분류 알고리즘 활용 시 데이터의 편향성을 개선하고자 다수의 데이터의 특성을 차지하는 그룹에서 데이터의 개수를 조정하고 소수의 데이터 그룹에서는 특성을 확장할 수 있도록 다양한 형태의 oversampling 알고리즘이 제시되고 있다. 그 중 synthetic minority over-sampling technique(SMOTE)는 다수와 소수를 구성하는 데이터의 균형성을 맞추기 위하여 고안된 방법으로 KNN 알고리즘의 거리 계수를 활용하여 다수와 소수 데이터의 영향 범위를 결정 후 분포 특성을 재구성하는 방식이다(Chawla et al., 2002). SMOTE는 기존 데이터의 정규분포 특성을 기반으로 데이터의 증폭 및 감소를 구현하며 해당 연구에서는 분류 알고리즘을 실행하기 위한 데이터 개수가 부족하여 기존 데이터를 증폭하는 목적으로 해당 알고리즘을 활용하였다. 새로운 데이터는 기존 데이터에 가중치를 부여하는 형태로 증폭되며, 가중치는 수식 (1)과 같이 0~1 범위로 거리 계수를 기반으로 무작위로 부여 된다.
여기서 SMOTEoversampling은 SMOTE를 통해 증폭된 데이터 개수이며, OD 기존 데이터를 의미한다. ω와 k는 가중치와 거리 계수를 의미한다.
3. 입력 데이터 특성
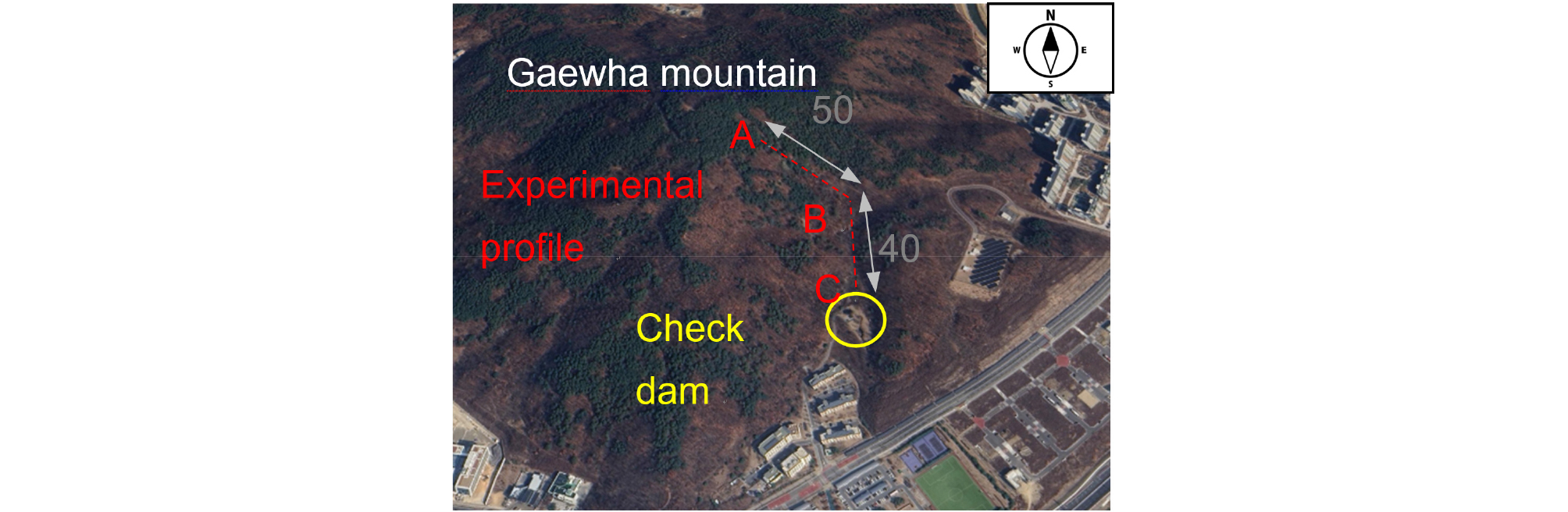
산사태 위험지역을 분류하기 위하여 대상으로 설정한 지역은 세종시 인근에 위치한 괴화산으로 Fig. 2에 현장의 사진을 수록하였다. 괴화산은 이미 산사태가 발생한 지역으로 추가적인 피해가 예상되어 대상 현장으로 선정하였다. 괴화산의 정상부 좌표는 36.49°N, 127.31°E 이며, 전체적인 고도는 24-155m의 높이를 보이고 있다. 해당 지역은 이미 기존에 토석류가 발생하여 하부에 사방댐이 설치되어 있으며, 8가지 지반공학 물성치를 획득하기 위하여 수행된 실험의 측선은 AB 그리고 BC 각각 50m와 40m 이다. 또한 A, B 그리고 C 위치에서 수평 방향으로 각각 20m 길이를 추가하여 수직 방향뿐만 아니라 수평 방향 특성도 함께 살펴보고자 하였다. 현장 실험은 수직 및 수평 방향에서 각각 10m 간격으로 수행되었으며, 현장 실험이 진행된 지역 인근에서 실내 실험을 위하여 교란 시료도 채취하였다. 현장 실험은 탄성파 탐사, 전기비저항 탐사, 동적 콘 관입 실험 및 time domain reflectometry(TDR)을 수행하였으며, 측정된 값과 경험식을 활용하여 탄성계수, 투수계수, 표층두께 그리고 포화도를 추정하였다. 나머지 입력인자인 간극률, 세립분함량, 전단강도 그리고 함수비는 현장에서 채취한 시료로 실내실험을 통해 도출하였다. 현장 실험을 통해 획득한 탄성계수, 투수계수, 표층두께 그리고 포화도는 평균적으로 116kPa, 0.000113m/s, 0.8m 그리고 4 2%로 나타났으며, 실내 실험으로 도출된 간극률, 세립분함량, 전단강도 그리고 함수비는 각각 0.6, 6%, 3kPa 그리고 21% 값을 보였다.
해당 지역의 상세한 안전율 분포를 이해하기 위하여 실험 지역을 포함하여 대상 지역의 20m × 90m(가로 × 세로)의 면적을 1m × 1m의 정사각형의 격자로 구분하였으며, 총 1800개의 격자를 생성하였다. 하지만, 현장 및 실내 실험이 진행된 지역은 총 18군데이므로 사면의 전체적인 특성을 이해하기에는 한계가 있다. 이를 극복하기 위해서 지구통계학 기반의 크리깅 기법을 활용하였으며, 획득한 데이터를 통해 가우시안 함수 기반의 베리오그램을 구축하였다. 베리로그램은 nugget, sill 그리고 range 로 구성되며, 일반적으로 nugget과 sill의 비율이 최소가 될 때 신뢰성 높은 베리오그램이 구축된 것으로 본다(Kumar et al., 2012). 8개 지반공학 물성치의 특성을 반영하여 각각의 물성치에 해당하는 베리오그램을 완성하였으며, 이를 통해 해당 지역의 격자를 모두 포함할 수 있는 1,800개의 지반공학 특징을 추출하였다. 해당 논문에서는 대상 지역의 안전율 분포를 machine learning 기법 중에 하나인 분류 기법으로 적용하는 것이 목적이므로, 이미 구축된 데이터 베이스를 활용하였다. 따라서 해당 지역에서 수행된 각각의 현장 실험, 실내 실험 방법론 및 전체 데이터의 특성은 지면상 생략하였으며, 이와 관련된 구체적인 내용은 Min and Yoon(2021)의 연구를 참고하길 바란다.
4. 분류 결과
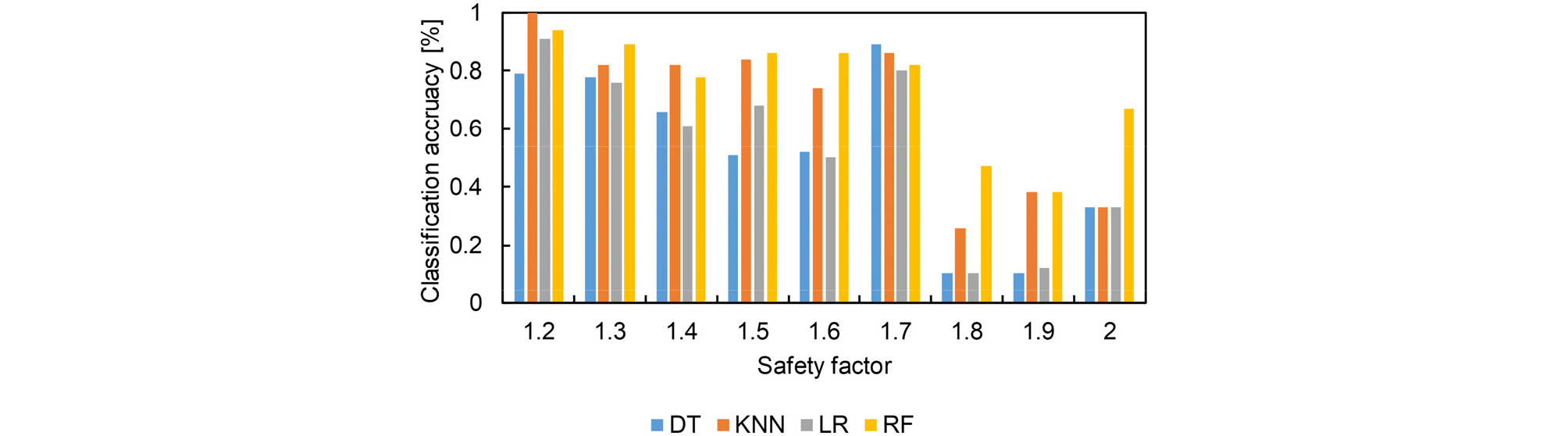
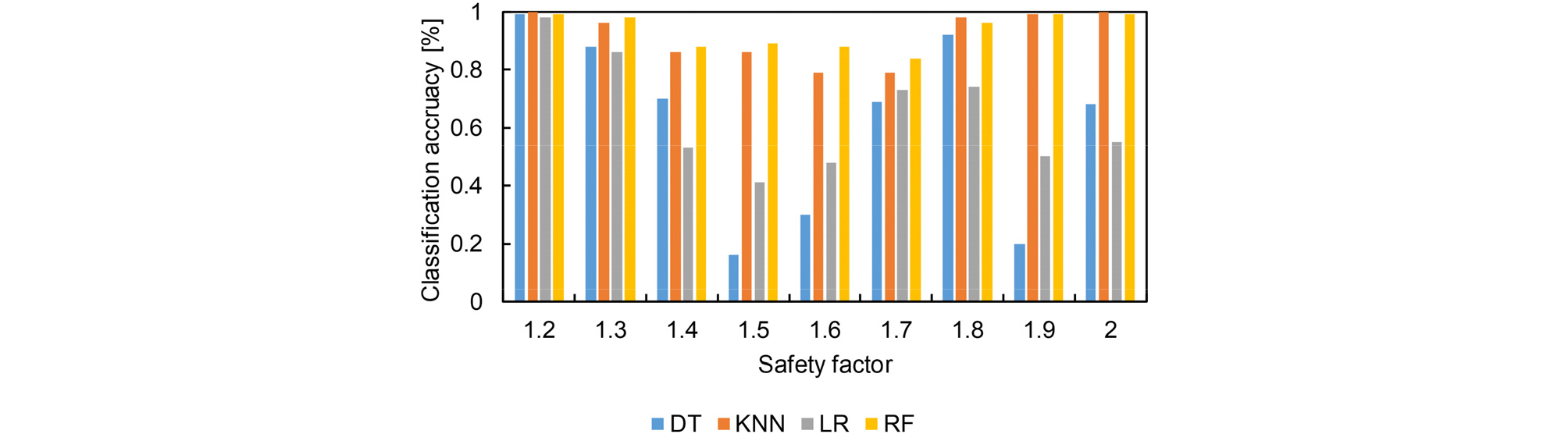
앞서 설명한 decision tree(DT), K-Nearest Neighbor(KNN), logistic regression(LR) 그리고 random forest(RF) 알고리즘을 활용하여 1,800개 격자에서 구축된 데이터의 안전율 분류를 수행하였다. DT와 RF 알고리즘의 하이퍼파라미터인 sample spilt, leaf 그리고 leaf node 는 각각 2, 2, 그리고 10개로 설정하였으며, 깊이는 5개로 지정하였다. RF 알고리즘은 추가적으로 나무의 개수를 10개로 확장하여 DT 알고리즘 보다 해당 데이터의 특성을 잘 분류할 수 있도록 하였다. 또한 KNN의 거리계수인 K 값은 5로 설정하였으며, 각각의 알고리즘에서 결정한 하이퍼파라미터는 선행연구를 통해 범위를 설정하고 시행착오 방법을 통해 최종적으로 결정하였다. 입력 인자로는 HRA 모델에 포함되는 8개의 지반공학 물성치이며, 출력 인자는 안전율로 설정하였다. 여기서 안전율은 무한사면에서 Mohr-Coulomb 파괴이론으로 유도된 수식을 활용하였다. 안전율의 범위는 1.2~2.0 사이이며, 안전율을 0.1 간격으로 증가하여 8개의 지반공학 물성치와의 관계를 분류 알고리즘의 정확도로 도시하였다. 여기서 정확도는 2 × 2 형태의 혼동 행렬(Confusion mateix)를 통해 계산되었으며, 참값과 오차값을 얼마나 정확하게 분류할 수 있는지를 의미한다(Ji et al., 2021). 즉, 8개의 지반공학물성치 그룹이 정확한 안전율 값에 포함될 확률과 타 안전률 범위에 포함되지 않는 확률을 의미한다. 따라서 값이 1에 가까울수록 분류 알고리즘의 신뢰성이 높다는 것을 보여준다.
각 알고리즘으로 분류된 정확도는 Fig. 3에 도시하였으며, 안전율이 1.2 및 1.7일 경우 모든 알고리즘의 정확도가 평균적으로 0.91 및 0.84로 상대적으로 타 안전율의 분류 정확도 보다 높게 나타났다. 각 알고리즘 마다 알고리즘 자체의 특성으로 가장 신뢰성이 우수하게 나타난 안전율 범위는 다소 상이하게 나타났다. DT와 KNN 알고리즘은 안전율 값이 1.7의 경우에 가장 분류가 잘 되는 정확도인 0.89와 0.86의 값을 보였다. LR과 RF 알고리즘은 1.2의 안전율 값에서 높은 정확도를 보였으며, 그 값은 각각 0.91과 0.94로 나타났다. 해당 연구에서 활용한 4가지 알고리즘 중에 RF 알고리즘이 가장 우수한 정확도 값을 보여주는 것으로 나타났다. 반면에 가장 낮은 정확도 값은 DT, KNN 그리고 LR 알고리즘에서 안전율이 1.8일때 각각 0.1, 0.26 그리고 0.1의 값을 보였다. RF 알고리즘은 1.9의 안전율 범위에서 0.38의 정확도를 보였다. RF 알고리즘으로 계산 한 정확도는 모든 안전율 범주에서 가장 낮은 값이 0.38로 나타나 타 알고리즘 보다 상대적으로 높은 신뢰성이 보여주는 것을 알 수 있으며, 이는 앞서 설명한 정확도가 높은 알고리즘이 RF 인 것과 동일한 결과를 보여준다.
Fig. 3은 1.2~2.0 범위의 안전율 값에서 각각의 알고리즘의 신뢰성이 우수하게 나타나는 거동이 상이한 것을 알 수 있다. 특히 안전율이 1.8 이상 되는 구간에서는 활용한 모든 알고리즘의 정확도가 상대적으로 매우 낮은 값을 보인다. 이와 같은 결과는 알고리즘 자체의 성능 보다는 입력 데이터의 영향이 큰 것으로 보이며, 입력 데이터 개수를 고려하여 분류 알고리즘의 성능을 향상시킬 수 있는 방안이 필요하다.
5. Oversampling 결과
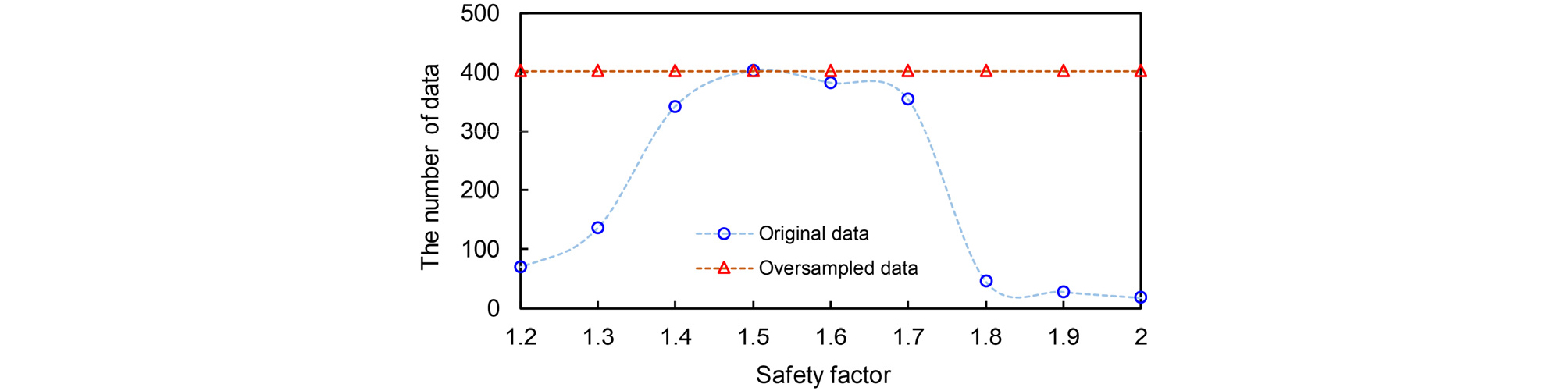
HRA의 구성 요소 8가지 인자를 통해 안전율 분류의 신뢰성을 향상시키기 위하여 각 안전율 마다 입력 데이터 개수를 Fig. 4에 도시하였다. 입력 데이터 수는 안전율 1.5 구간에서 402개로 가장 많은 입력 데이터가 분포하는 것으로 나타났으며, 안전율이 2.0 에서는 상대적으로 작은 데이터 개수인 18개가 입력 데이터로 활용하였다. 또한 안전율이 1.8 및 1.9 에서도 데이터 개수는 46 및 28개로 나타나 분류 알고리즘으로 충분한 학습을 진행하기 어려운 조건에서 결과가 도출 된 것으로 사료된다. 즉, 1.2-2.0 범위의 해당 안전율에 포함되는 데이터 개수가 8개의 지반공학 물성치의 특징을 적절하게 추출할 수 있도록 데이터의 증폭 과정이 필요하다. 해당 연구에서는 다양한 증폭 알고리즘 중 synthetic minority over-sampling technique(SMOTE)를 선정하여 각 안전율에 해당하는 데이터 개수를 증대시키고자 하였다.
증폭된 데이터 개수는 기존 데이터 개수와 비교하여 Fig. 4에 도시하였다. 증폭된 데이터 개수는 기존 데이터 개수 중에 제일 많은 분포를 보이는 안전율 1.5에 해당하는 개수인 402개를 기준으로 모든 안전율에 적용하였다. 따라서 1.2~2.0의 모든 안전율 구간에 데이터 개수를 402개로 동일하게 설정하였으며, 안전율 1.2부터 증폭된 데이터 개수는 266, 60, 0, 20, 48, 356, 374, 384 그리고 395 이다. 안전율 1.7~2.0 구간에서 300개 이상으로 다수의 데이터가 증폭된 것을 알 수 있으며, 2.0 안전율에서는 400개에 가까운 데이터가 증폭되었다. 새롭게 증폭된 데이터를 기반으로 분류 알고리즘을 적용하였으며, 그 결과는 다음과 같이 토론 부분에 정리하였다.
6. 토 론
모든 안전율 구간에서 402개의 데이터로 증폭된 새로운 데이터 그룹을 활용하여 앞서 설명한 decision tree(DT), K-Nearest Neighbor(KNN), logistic regression(LR) 그리고 random forest(RF) 알고리즘을 적용하였다. 하이퍼파라미터는 데이터를 증폭 하기 전에 적용한 값을 그대로 적용하여 데이터 증폭으로 인한 신뢰성 변화를 고찰하고자 하였다. 증폭된 데이터로 분류를 수행하여 계산한 정확도는 Fig. 5에 도시하였으며, 앞서 살펴본 분류 정확도인 Fig. 3과 다소 상이한 결과 값을 보여준다. Fig. 3에서 DT, KNN, LR 그리고 RF의 정확도는 평균적으로 각각 0.52, 0.67, 0.53 그리고 0.74를 보이지만, 데이터를 증폭하여 분류 알고리즘을 적용한 결과는 0.61, 0.91, 0.64 그리고 0.93으로 정확도가 상승한 결과를 보여준다. 이와 같은 결과는 각 안전율 범위 마다 증폭된 데이터 개수로 인해 지반공학 물성치의 특징 추출이 적절하게 이루어진 것으로 사료된다. 모든 알고리즘에서 안전율이 1.2일 때 가장 높은 정확도를 보였으며, DT, KNN, LR 그리고 RF 알고리즘 순서대로 0.99, 1, 0.98 그리고 0.99로 거의 1에 가까운 값을 보였다. 이와 같은 결과는 데이터 증폭이 분류의 성능을 전반적으로 향상 시킬 수 있는 가능성을 보여준다.
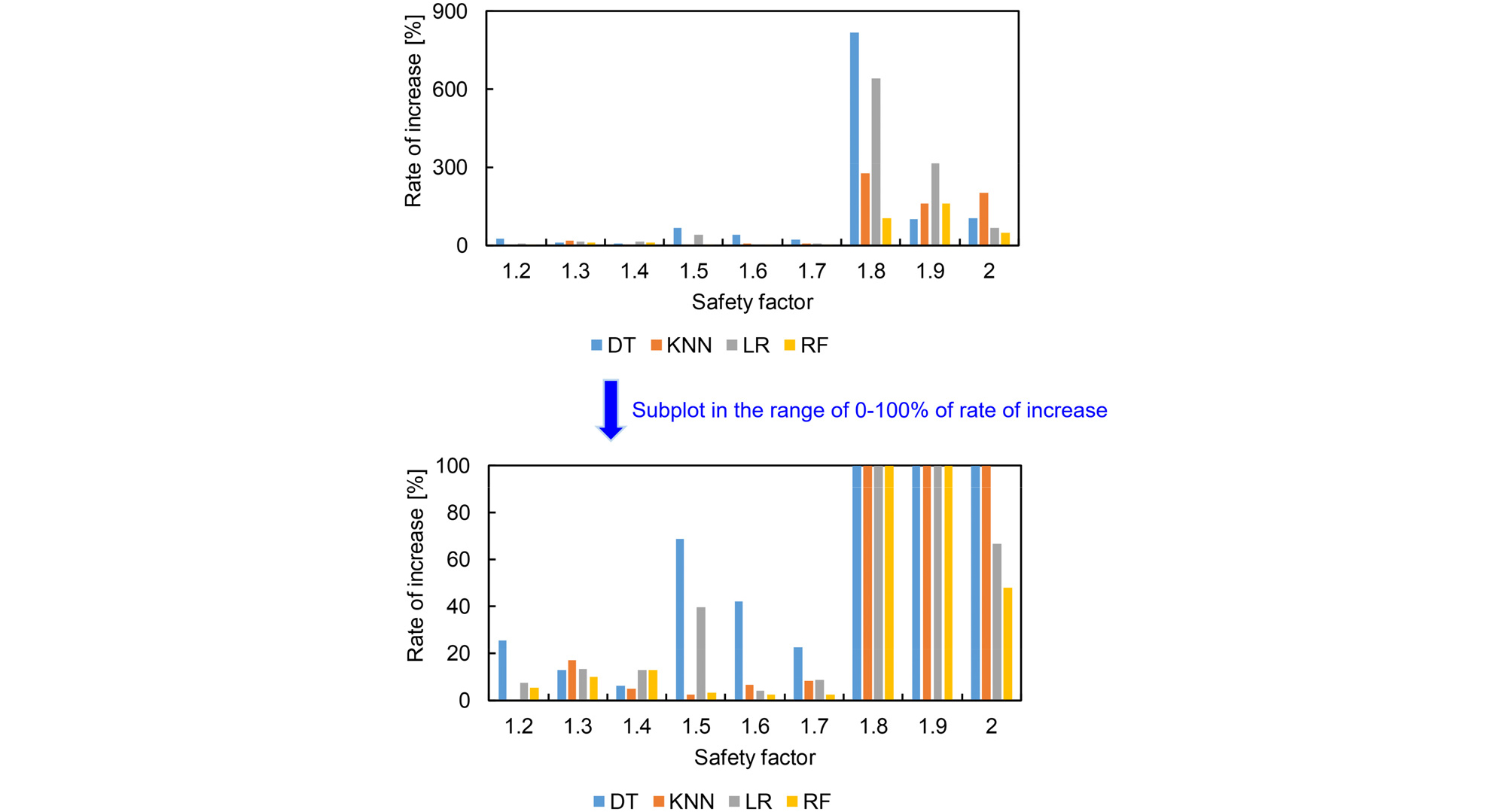
기존 데이터와 증폭된 데이터를 활용하여 분류 알고리즘을 적용한 결과의 증가율을 계산하여 Fig. 6에 도시하였다. 안전율이 1.8, 1.9 그리고 2.0 구간에서 상대적으로 높은 증가율을 보이며, 그 값은 평균적으로 각 안전율 마다 460%, 184% 그리고 105% 증가한것으로 나타났다. Fig. 4에서도 도시하였듯이 해당 논문에서 활용한 입력 데이터는 안전율 1.8~2.0 구간에서 데이터가 부족한 것으로 나타나 이를 SMOTE로 해결하면 상당히 높은 수준의 정확도 값이 향상되는 것을 확인하였다. 해당 결과의 증가율 구간을 0~100%로 축소하여 다양한 안전율 범위에서 정확도 변화를 관찰할 수 있도록 구체적으로 도시하였다. 평균적으로 정확도는 안전율 1.2~1.7 범위 내에서 9%, 13%, 9%, 28%, 13% 그리고 10% 상승한 것으로 나타났다. 비록 안전율 1.2~1.7 구간에서는 안전율 1.8~2.0 구간과 같이 정확도의 증가가 대폭적으로 이루어진 구간은 없지만, 대부분 소폭 상승하여 SMOTE 알고리즘을 활용한 데이터 증폭이 분류 알고리즘의 신뢰성을 향상시킬 수 있는 대안으로 적용될 수 있음을 보여준다.
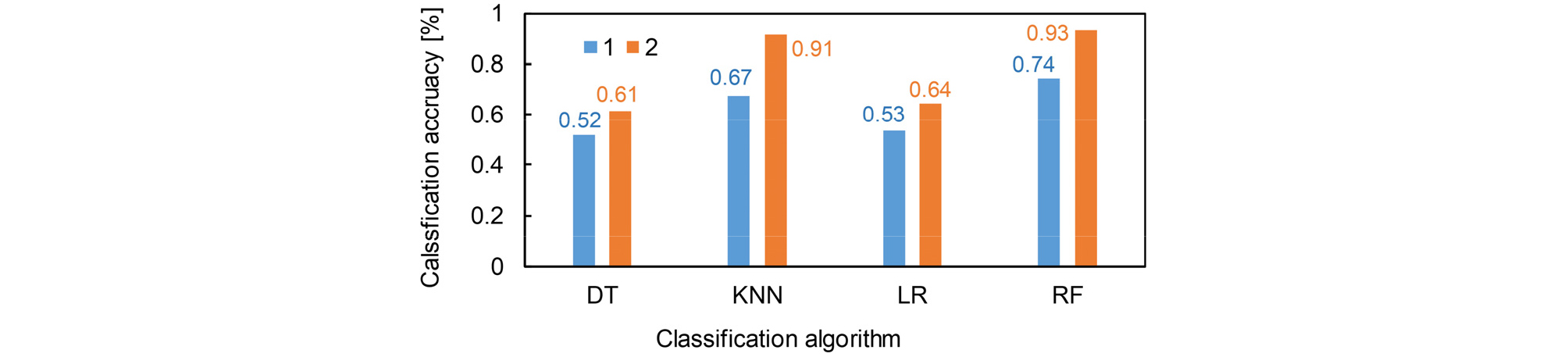
해당 연구에서 활용한 4가지 알고리즘에서 나타난 정확도를 평균적으로 비교하기 위하여 데이터 증폭 전과 후의 결과 값을 Fig. 7에 도시하였다. 1로 표시한 부분이 기존 데이터를 활용한 결과이며, 데이터 증폭 후 나타난 결과는 2로 표시하였다. DT와 LR 알고리즘은 기존에 0.52와 0.53의 비슷한 정확도를 보였지만, SMOTE 알고리즘 적용 후에는 전체적으로 소폭 상승한 0.61과 0.64의 정확도를 보여준다. 하지만, KNN과 RF 알고리즘은 기존에 0.67과 0.74를 보이던 정확도가 대폭 상승하여 0.91과 0.93의 정확도의 결과를 보여준다. 이와 같은 결과는 증폭된 데이터의 특성을 KNN과 RF 알고리즘이 적절하게 추출하여 우수한 결과가 나타난 것으로 사료된다. SMOTE 알고리즘을 활용하여 데이터 증폭 시 KNN과 RF 알고리즘이 우수한 결과가 나왔지만, 이는 해당 논문에서 사용한 데이터 분포도에 국한된 결과로 다른 데이터를 활용할 경우 상이한 결과가 나올 가능성이 있다. 따라서 사용자는 해당 논문에서 제시한 방법과 같이 다양한 알고리즘을 적용하여 신뢰성을 평가하는 것을 추천한다.
7. 결 론
해당 논문에서는 HRA 모델을 통해 산사태 위험 지역을 machine learning 기법 중 분류 기법을 통해 정량적으로 평가할 수 있는 방법론을 제시하였다. 현장실험을 통해 탄성계수, 투수계수, 표층두께 그리고 포화도를 추정하였으며, 간극률, 세립분함량, 전단강도 그리고 함수비는 실내실험을 통해 측정하였다. 해당 연구를 통해 도출한 결론을 요약하면 다음과 같다.
(1) 해당 연구에서 활용한 분류 알고리즘은 decision tree(DT), K-Nearest Neighbor(KNN), logistic regression(LR) 그리고 random forest(RF) 이며, HRA에 포함되는 8가지 지반공학 물성치를 입력 인자로 활용하였다. 또한 위험지역을 정량적으로 분류하기 위하여 출력 값은 Mohr-Coulomb 파괴이론으로 계산된 값을 활용하였다.
(2) 분류 결과 안전율이 1.2~1.7 범위에서는 높은 정확도가 나타났지만, 안전율이 1.8~2.0 사이에서는 상대적으로 낮은 정확도를 보였다. 이와 같은 이유를 확인하기 위하여 각 안전율 범위에 해당하는 입력 데이터 개수를 비교하였으며, 안전율이 1.8~2.0 사이는 상대적으로 입력 데이터의 개수가 부족한 것으로 나타났다.
(3) 데이터 개수 부족을 해결하기 위하여 synthetic minority over-sampling technique(SMOTE) 방법을 적용하였으며, 이를 통해 수행한 분류 결과를 기존 데이터와 비교하여 고찰하였다. 데이터가 부족했던 안전율 1.8~2.0 구간은 정확도가 평균적으로 약 250% 증가한 것으로 나타났으며, 나머지 구간도 정확도가 소폭 증가한 것을 보여줬다. 따라서 해당 연구에서 제안하는 방법은 지반공학 분야의 데이터 부족 현상을 해결할 수 있는 방법론으로 활용될 수 있다.
