

1. 서 론
2. 지반조사보고서 데이터 추출 자동화
2.1 추출 자동화 기법 개요
2.2 딥러닝 기반 지반시험 페이지 분류
2.3 텍스트마이닝 기법을 활용한 페이지 분류 정확도 향상
2.4 페이지 추출 영역 결정 및 데이터 추출
3. 결과 및 분석
3.1 보고서 페이지 분류 결과
3.2 데이터 추출 결과 및 데이터셋 구축
4. 사용자 인터페이스 기반 추출 프로그램
5. 결 론
1. 서 론
신뢰도 높은 설계 및 시공을 위해서는 현장 지반 정보가 필수적이며, 이를 위해 시공 이전 혹은 시공 중에 다양한 현장 및 실내 시험이 수행된다. 일련의 지반조사에서 획득된 지반정수 데이터는 지반조사보고서 형태로 작성되고, 그 형식은 작성 시기, 작성 기관, 지반조사 수행 업체 등에 따라 상이하게 나타난다. 작성된 보고서는 시공사 및 설계사에 유통되며 향후 설계와 참조를 위해 디지털 형식 데이터베이스로 저장된다. 특히 국토교통부는 국내 지반정보의 통합관리 목적을 위해 ‘국토지반정보 포털시스템’을 운영하고 있으며, 프로젝트 정보 및 수행한 지반조사 결과를 중심으로 지반 데이터베이스를 구축하고 있다. 이러한 지반 데이터베이스는 설계 및 시공 과정을 효율적으로 향상시킬 수 있고, 향후 인공지능(artificial intelligence) 혹은 데이터 분석 기술을 활용하여 최적화된 지반 상관관계를 도출할 수 있다(Ma and Yun, 2022; Murlidhar et al., 2020; Park et al., 2020; Pham et al., 2020; Samui and Sitharam, 2010). 이에 따라 지반정수 데이터의 디지털 데이터베이스화 및 빅 데이터(big data)를 구축하는 것이 요구되고 있다.
그러나 현재 지반조사보고서의 디지털 데이터베이스 입력은 사람이 직접 보고 입력하는 수동 추출로 진행되고 있다. 이는 인력과 시간이 많이 소요되고, 데이터 오류 혹은 누락이 발생하기도 한다. 이에 따라 보고서 데이터 자동 추출이 요구되나, 데이터 자동 추출은 지반조사보고서의 비구조성(unstructured format)에 의해 한계가 존재한다. 현장마다 수행한 지반조사의 종류가 상이함에 따라 지반조사보고서를 구성하는 세부 지반시험이 다양하고, 동일한 지반시험 결과 보고서에서도 다양한 형식이 존재하기 때문이다. 세부 지반시험 결과 보고서 형식 또한 그림과 표가 혼재한 복잡한 형태를 갖춰 사람이 읽을 수 있는(human-readable) 문서 형식을 띄고 있다.
최근 연구자들은 사람이 읽을 수 있는(human-readable) 비구조적 문서에서 기계가 읽을 수 있는(machine-readable) 데이터를 추출하기 위한 목적으로 이미지 기반 딥러닝 기술, 자연어 처리 기술(natural language processing) 및 다양한 규칙 기반(rule-based) 알고리즘 방법을 도입해왔다. 합성곱 신경망(convolutional neural network, CNN) 기반 딥러닝 모델을 통해 문서 페이지의 타입 분류를 성공적으로 수행할 수 있고(Bakkali et al., 2020; Tensmeyer and Martinez, 2017; Kang et al., 2014), 서술되어 있는 텍스트(narrative text)에서 유효한 데이터를 구조적으로 추출하기 위해 자연어 처리 기술을 활용할 수 있다(Brekke et al., 2021; Faraji et al., 2021; Ma et al., 2022). 또한, 엄격한 규칙 기반 방법을 사용하여 표 형태의 문서에서 데이터를 추출하거나(Adamo et al., 2015; Shigarov et al., 2018), 시추주상도에서 데이터를 추출하는 방법이 제안된 바 있다(Zhang et al., 2020a; Zhang et al., 2020b). 그러나, 다양한 종류의 지반시험 결과 페이지가 포함된 지반조사보고서에서 추출하고자 하는 지반시험을 분류하고, 해당 페이지의 복잡한 레이아웃에서 원하는 지반 데이터를 추출하는 통합 추출 프레임워크는 제안되어 있지 않다.
따라서, 본 연구에서는 인공지능 및 텍스트 마이닝 기법을 활용하여 비구조적 형식의 지반조사보고서에서 유효한 지반 데이터를 자동으로 추출하고자 하였다. 지반조사보고서를 구성하는 각각의 세부 지반시험 결과 보고서 페이지를 딥러닝 기반 분류 모델 및 텍스트 마이닝 알고리즘을 활용하여 구분 및 분류하고, 컴퓨터 비전 알고리즘을 통해 페이지 내 레이아웃을 분석하였다. 분석한 레이아웃을 기반으로 보고서 텍스트 추출 및 전처리를 통해 엑셀 형식의 지반 데이터셋을 생성하였다. 제안한 보고서 데이터 추출 모델을 실무에 직접적으로 활용할 수 있도록 사용자 인터페이스 기반 프로그램을 개발하여 실무 지원 모델을 구현하였다.
2. 지반조사보고서 데이터 추출 자동화
2.1 추출 자동화 기법 개요
현재 국내에 유통되는 지반조사보고서는 일반적으로 본문과 부록으로 구성된다. 본문은 현장 프로젝트 개요, 수행한 현장 및 실내 지반시험에 대한 방법론적 내용과 각 시험 결과에 대한 내용이 포함되어 있으며, 부록은 현장 지반조사위치도, 지반시험 원본 결과 보고서와 현장 사진첩 등으로 구성된다. 본문은 정성적 기술 형식으로 상세한 지반시험 결과 데이터는 요약되어 작성된 경우가 다수이며, 설계에 직접적으로 활용할 수 있는 지반정수 데이터 값은 시험 결과 보고서에 포함되어 있다. 이에 따라 본 연구에서 추출하고자 하는 상세한 지반정수 데이터는 부록 내 원본 지반시험 결과 보고서에서 추출할 수 있다.
지반조사보고서 데이터 추출 자동화는 보고서 내 세부시험 결과 보고서 페이지 분류, 페이지 내 레이아웃 분석 및 레이아웃 기반 데이터 추출로 나눌 수 있다(Fig. 1). 우선 표지와 본문, 다양한 지반시험 결과 보고서로 복잡하게 구성된 지반조사보고서를 딥러닝 및 텍스트 마이닝 기법을 활용하여 페이지 별로 유형을 분류한다. 이 때 페이지 유형은 표지, 본문, 혹은 수행한 지반시험 결과 보고서의 종류를 나타내는 라벨(label)을 의미한다(e.g., 본문, 시추주상도, 공내전단시험). 특정 페이지가 어떤 지반시험 결과 보고서인지 알았다면, 컴퓨터 비전 알고리즘 기반의 페이지 레이아웃 분석을 통해 추출하고자 하는 데이터 존재 영역을 결정한다. 마지막으로 데이터 존재 영역 내에서 텍스트를 추출하고 가공하여 데이터셋을 만든다.
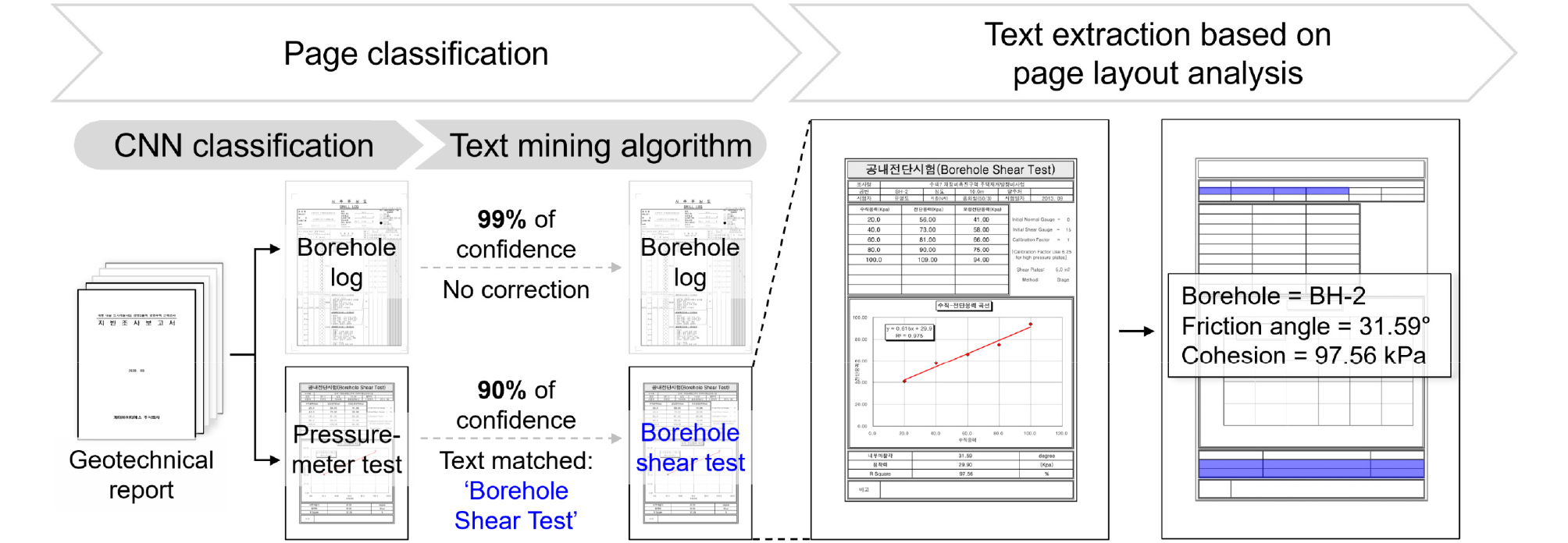
2.2 딥러닝 기반 지반시험 페이지 분류
2.2.1 합성곱 신경망 기반 분류 모델
합성곱 신경망 모델은 이미지 데이터에 특화된 딥러닝 모델로, 객체 분류, 검출(detection) 및 추출(segmentation) 문제에 뛰어난 성능을 보이고 있다(Kheradmandi and Mehranfar, 2022; Kim and Yun, 2021; Park et al., 2023; Park et al., 2024; Seo et al., 2022). 이에 따라 문서 페이지를 이미지로 인식하여 문서 분류, 레이아웃 분석, 필기 문자 인식 등을 수행하는 문서 이미지 분석(document image analysis, DIA) 분야에서 활발히 활용되고 있으며(Harley et al., 2015; Shen et al., 2021; Weng and Xia, 2020), 특히 국내 시주주상도 페이지 내 지반 데이터 추출을 목적으로 한 시추주상도 타입 분류에 뛰어난 성능을 보임이 제안된 바 있다(Park et al., 2021).
CNN 모델은 합성곱 층(convolutional layer) 및 풀링 층(pooling layer)을 통해 입력 이미지에서 특징맵(feature map)을 추출하고, 추출된 특징맵과 정답 라벨 사이 관계를 학습한다. 합성곱 층은 합성곱(convolution) 연산을 이용하여 입력 이미지에서 다양한 스케일(scale)의 특징맵을 추출하고, 풀링 층은 오버피팅 및 과도한 연산량 방지를 위해 특징맵의 사이즈를 줄이는 역할을 수행한다. 일반적으로 CNN 분류 모델은 일련의 합성곱 층과 풀링 층을 거쳐 출력된 최종 특징맵을 완전연결계층(fully connected layer, FC layer)을 통해 1차원 벡터화(flatten)시킨 후 소프트맥스 함수를 통해 각 라벨에 대한 정답일 확률(confidence score)을 예측한다. CNN 모델 학습은 역전파(backpropagation) 알고리즘을 통해 오차함수(loss function)를 최소화하는 방향으로 모델 내 학습이 가능한 파라미터를 업데이트함으로써 최적화된다.
CNN 모델 및 성능이 지속적으로 발전됨에 따라 거대한 데이터셋을 이용해 사전학습(pre-trained)된 다양한 구조의 모델이 제안되어 왔다. 본 연구에서는 2019년 ImageNet 챌린지에서 정확도 1위를 달성한 EfficientNet을 이용하여 전이학습(transfer learning) 방법으로 페이지 분류 모델을 구축하였다(Tan and Le, 2019). EfficientNet은 합성곱 층(i.e., convolutional layer), MBConv 층(i.e., mobile inverted bottleneck convolution layer) 및 최종 완전연결계층을 통해 라벨을 출력하는 구조를 가지며(Fig. 2), 풀링 연산은 각 합성곱 층 연산 내부에 포함되어 있다. MBConv 층이란 일반 합성곱 층과 달리 깊이별 분리 합성곱(depthwise separable convolution)과 bottleneck 구조를 적용하여, 보다 적은 파라미터 및 연산량으로 높은 정확도를 내기 위해 고안된 연산 레이어이다. 최종적으로 EfficientNet 기반 페이지 분류 모델은 보고서 페이지를 이미지로 변환하여 모델에 입력하여, 일련의 다양한 합성곱 층을 거친 후 소프트맥스 함수로 구성된 완전연결계층을 통해 각 라벨에 대한 예측 확률(i.e., 신뢰 점수 벡터, confidence score vector)을 출력한다.
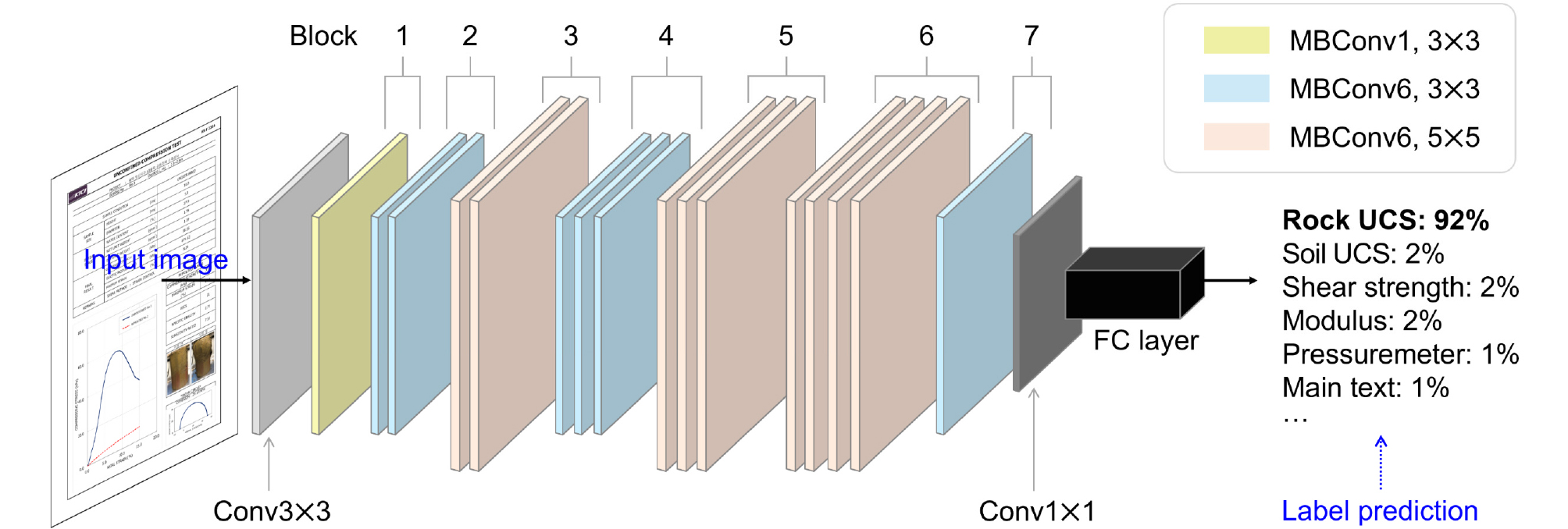
2.2.2 페이지 분류 모델 학습 과정
지반조사보고서 데이터 추출 모델 구축을 위해 208개 현장에서 확보한 총 318개의 지반조사보고서 데이터셋을 확보하였다. 데이터셋은 전체 50,323장의 페이지로 구성되어 있으며, 표지, 본문 및 공내재하시험, 시추주상도, 암석일축압축강도시험과 같은 각 세부 지반시험 결과 보고서를 포함해 전체 54개의 페이지 라벨이 존재하였다. CNN 기반 페이지 분류 모델 데이터셋 구축을 위해 각각의 보고서 페이지를 PNG 이미지 형태로 변환하여 저장하였으며, 사람이 직접 페이지 별 레이블링 작업을 수행하였다. 모델 학습을 위한 학습(train) 및 테스트(test) 데이터셋은 8:2 비율로 분할하였다.
향상된 모델 성능을 위해 사전학습된 가중치(pre-trained weight)로 초기화된 EfficientNet 모델을 활용하여, 확보된 데이터셋 기반의 재학습 및 파라미터 미세 조정을 거치는 전이학습(transfer learning)을 사용하였다. 입력 이미지는 모델의 사전학습 세팅과 동일하게 너비 250, 높이 354 픽셀 크기의 이미지로 변환하고, 색상 전처리를 수행하였다. 모델이 학습 데이터셋에 대해 한 번 학습을 완료한 에포크(epoch)마다 검증(validation) 단계를 거쳤는데, 과적합 방지를 위해 k-fold 교차검증(cross validation)을 적용하였다(k=5). 학습 시 최적 모델을 획득하기 위해 다양한 하이퍼 파라미터(hyperparameter)를 변화시키며 학습을 수행하였고, 최종적으로 0.001의 학습률, 16의 배치 사이즈를 적용하여 모델을 최적화시켰다.
딥러닝 모델 학습 및 추론은 Windows 10, Intel Xeon CPU Gold 6226R(22 M Cache, @ 2.90GHz), 4개의 GPU(NVIDIA GeForce RTX 3090, 24GB) 하드웨어를 사용하였으며 파이썬 기반 파이토치(PyTorch) 프레임워크를 사용하였다.
2.3 텍스트마이닝 기법을 활용한 페이지 분류 정확도 향상
수행한 지반시험의 종류에 따라 통용되는 결과 보고서 형식이 다르고, 추출하고자 하는 데이터가 다르며 이에 따른 텍스트 표현 형식 또한 상이하다. 이에 따라 정확도 높은 데이터 추출을 위해선 선행 단계인 페이지 분류를 정확하게 수행하는 것이 필요하다. 학습을 통해 최적화된 CNN 모델로 페이지 라벨을 예측하였지만, 모든 이미지를 100%의 정확도로 예측하는 것은 한계가 있으며, 역설적으로 100%의 정확도는 확보한 데이터셋에서만 높은 성능을 보이고 일반화 성능이 떨어지는 과적합(overfitting)이 발생했다고 판단할 수 있다. 이에 따라 텍스트 마이닝 알고리즘을 통해 과적합 혹은 과잉학습이 발생하지 않은 최적 CNN 모델의 분류 예측 결과를 보완하고 추가적인 모델 학습 없이 분류 정확도를 향상시키고자 하였다.
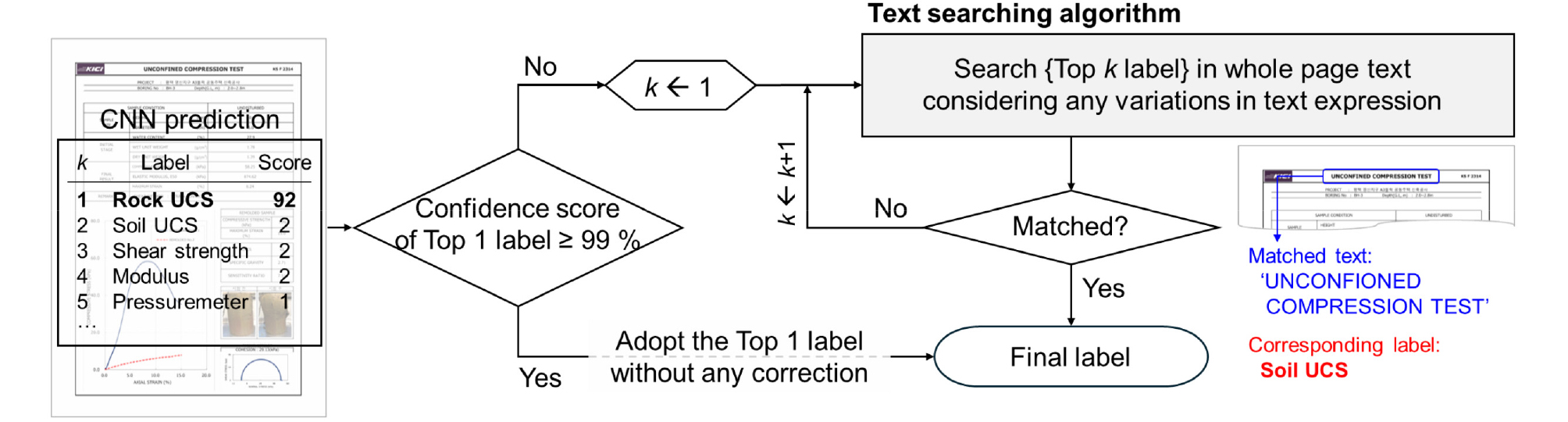
본 연구에서 적용한 텍스트 마이닝 알고리즘은 Fig. 3과 같다. 선행 단계인 CNN 모델은 신뢰점수 벡터(confidence vector)를 출력한다. 이 때 신뢰 점수(confidence score)는 입력 이미지에 대해 특정 라벨로 분류될 확률을 의미하여, 이에 따라 신뢰 점수 벡터는 각 라벨에 대한 신뢰 점수로 이루어진 벡터를 의미한다. 일반적으로 CNN 분류 결과는 가장 신뢰 점수가 높은(i.e., k=1, Top-1) 라벨을 이용하나, 본 연구에서는 CNN 결과를 보완하기 위해 Top-1 라벨뿐 아니라 신뢰 점수 벡터를 고려하였다. 예측된 CNN의 Top-1 라벨에 대한 신뢰 점수가 99%이상이라면, 추가적인 결과 보완 없이 해당 라벨을 그대로 이용한다. 반면, 99%에 미치지 못하는 경우 텍스트 서칭 알고리즘(text searching algorithm)을 적용한다. 텍스트 서칭 알고리즘은 주어진 라벨에 해당하는 텍스트가 페이지 내에 존재하는지 검색하고, 해당 텍스트가 있다면 이에 상응하는 라벨을 부여한다. 이 때 불필요한 띄어쓰기 및 오탈자를 제거하여 유효한 텍스트 테이터만을 처리하는 전처리 과정을 거쳤으며, 특정 라벨이 보고서 내에서 나타날 수 있는 모든 표현 형식을 고려하여 텍스트를 분류하고 라벨을 부여하였다. 만약 페이지 내 해당 텍스트가 존재하지 않는다면, 다음 예측 (i.e., k+1)에 해당하는 라벨에 대한 검색을 수행하며 만약 Top-5 라벨까지 텍스트 서칭이 일치하지 않는 경우 CNN예측 Top-1 라벨을 최종 라벨로 결정하였다.
2.4 페이지 추출 영역 결정 및 데이터 추출
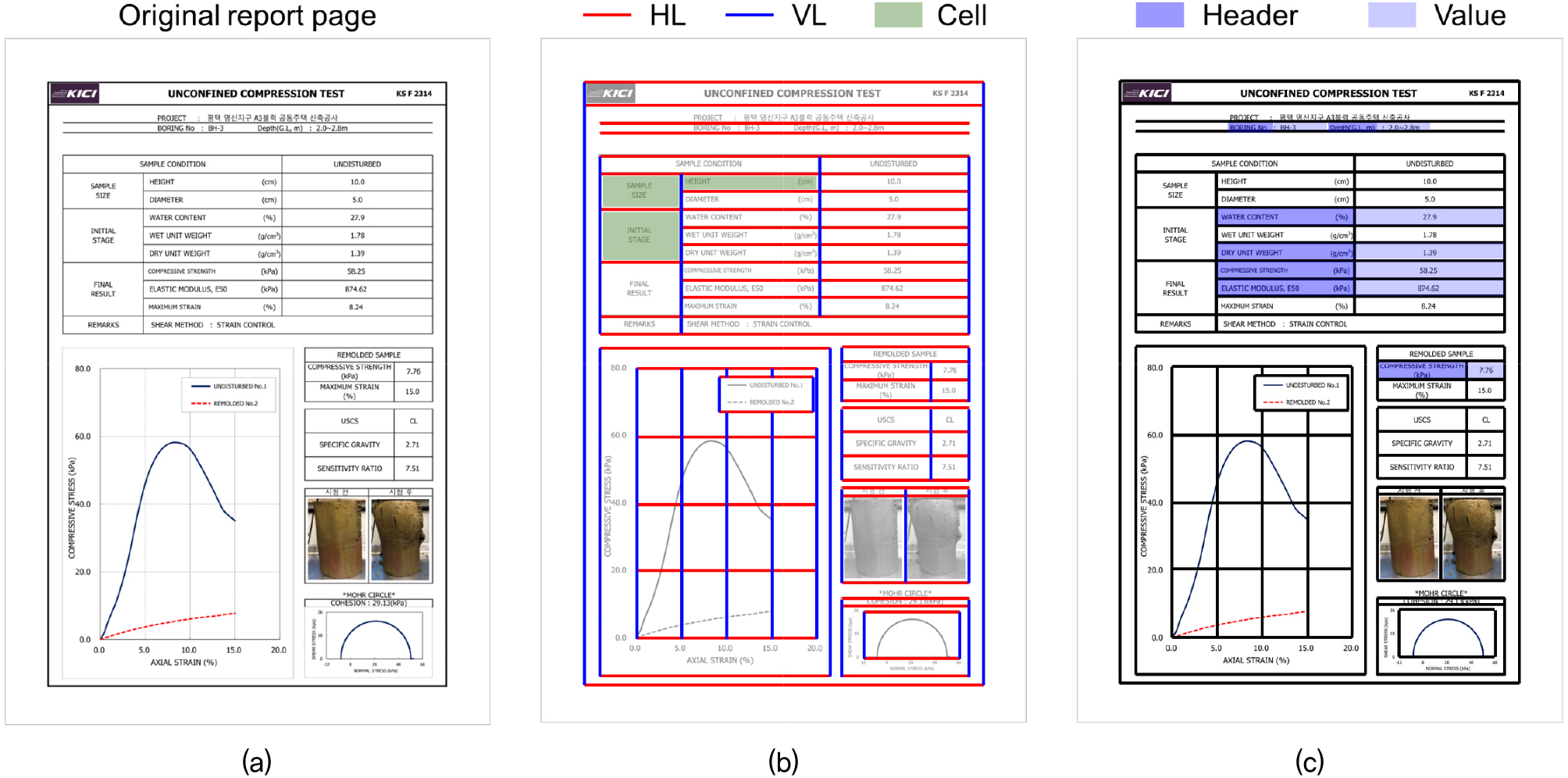
페이지 분류 단계로부터 어떤 세부시험 결과 보고서인지 결정됐다면, 페이지 내에서 불필요한 데이터는 제외하고 필요한 데이터만을 추출하기 위해 유효한 데이터 영역을 결정하는 것이 필요하다. Fig. 4는 페이지 내 데이터 추출 영역 결정을 위한 레이아웃 분석 기법을 나타낸다. 일반적으로 지반시험 결과 보고서는 표 형태로 존재하는 경우가 다수이며, 이에 따라 보고서 페이지 레이아웃 분석은 표 분석을 위한 선 구조 탐지를 기반으로 수행되었다.
보고서 페이지 이미지를 이진화(binarization)한 후 컴퓨터 비전 기반 이미지 필터를 활용하여 페이지를 구성하는 가로선 및 세로선을 추출한다(Fig. 4(b)). 이미지 필터는 세로선, 혹은 가로선 상응하는 픽셀이 존재할 때 그 픽셀을 결과로 출력한다. 이 때, 최소 길이 기준을 적용함으로써 길이가 너무 짧은 선은 탐지하지 않고(i.e., 글자 내부를 구성하는 선), 보고서 레이아웃에 영향을 미치는 유효한 선만 탐지하였다. 추출된 선 구조를 기반으로, 선 구조에 의해 완전히 분할(partition)된 사각형 구역은 텍스트가 존재할 수 있는 텍스트 셀(cell) 영역으로 볼 수 있다.
세부 지반시험 결과 보고서 내 데이터는 데이터 항목 이름인 헤더(header)과 이에 상응하는 실제 데이터 값(value)으로 나눌 수 있다. 각 시험 별로 추출해야 하는 데이터 항목은 사전에 결정되어 있으며, 항목 이름에 해당하는 텍스트 셀은 헤더 셀 영역으로 판단될 수 있다. 이 때, 사전 입력된 데이터 항목 이름은 모든 텍스트 표현을 고려해야 한다. 즉, ‘COMPRESSIVE STRENGTH, ‘Unconfined strength’ 등의 텍스트 표현을 모두 동일하게 ‘일축압축강도’로 매칭하고 유의미한 데이터로 분류 및 해석하는 것을 포함한다. 데이터 항목 이름에 상응하는 데이터 값은 보고서 형태에 따라 헤더 셀 영역에서 오른쪽에 위치하거나, 아래에 위치한다. 세부 지반시험 보고서 내 헤더 셀 간 상대적인 위치와, 지반 정수에 해당하는 데이터 값이 가질 수 있는 값의 유효한 형식(e.g., 숫자 형식)등을 고려하여 데이터 값 영역을 결정할 수 있다. 특히, 헤더 셀 간의 상대적인 위치 분석을 통해 세부시험 보고서가 셀 형식으로 나뉘어져 있지 않는 경우도 적절하게 헤더 셀과 데이터 값 셀 영역을 구분할 수 있다(upper part in Fig. 4(c)). 최종적으로 각 셀 영역에서의 텍스트 추출 및 공백 제거 등의 후처리를 통해 최종 데이터셋을 구축할 수 있다.
3. 결과 및 분석
3.1 보고서 페이지 분류 결과
Fig. 5a는 CNN 모델 기반의 지반시험 페이지 분류 결과, Fig. 5b는 텍스트마이닝 알고리즘에 의한 CNN 모델 예측 보완 결과를 나타낸다. 혼돈 행렬(confusion matrix)의 각 수치는 실제 라벨(true label)에 대한 예측 라벨(predicted label)의 비율을 의미하며, 실제 라벨과 예측 라벨이 동일할 때(i.e., 대각선) 모델이 정확하게 예측하였다고 간주한다. CNN 분류 모델은 공내재하시험 라벨을 제외하고 모두 97% 이상의 정확도를 보임을 확인할 수 있다(Fig. 5a). 공내재하시험 결과 보고서 페이지의 경우, 유통되고 있는 형식이 22개 이상으로 매우 다양하고, 각 형식마다의 레이아웃 편차가 커 상대적으로 낮은 87%의 정확도를 보였다. CNN 예측 결과를 보완하고 분류 정확도를 향상시키기 위해 텍스트마이닝 알고리즘을 적용한 결과, 주요 지반시험 페이지를 모두 100%의 정확도로 분류하였다(Fig. 5b). 이에 따라 본문 및 다양한 지반시험 결과 보고서로 복잡하게 구성된 지반조사보고서를 필요한 지반시험 결과 보고서만을 선별하여 분류할 수 있었다.
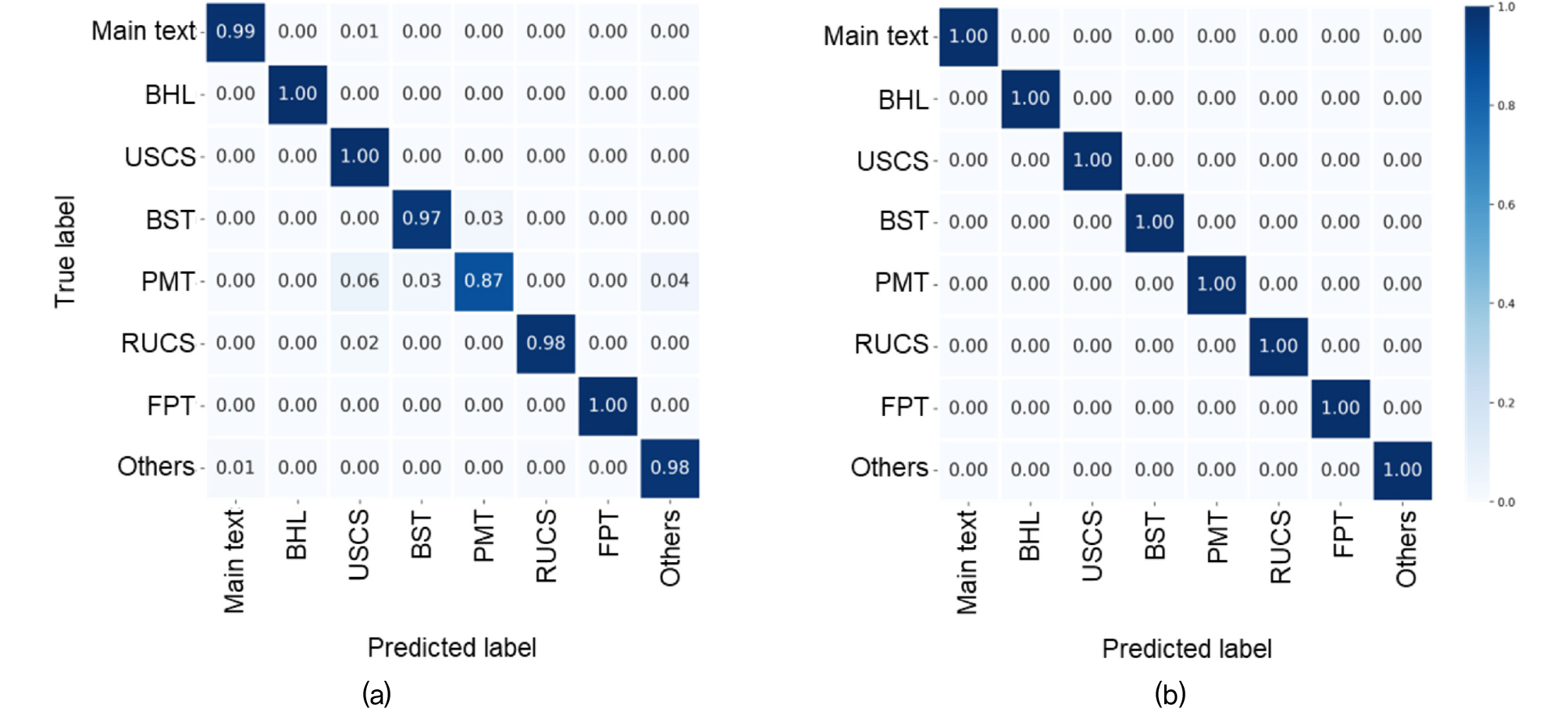
Fig. 5
Result of page classification: (a) based on only CNN without any correction, (b) fine-tuned by text mining algorithm. The names of labels are as follows; BHL: borehole log; USCS: soil laboratory test; BST: borehole shear test; PMT: pressuremeter test; RUCS: rock unconfined strength test; FPT: field permeability test
3.2 데이터 추출 결과 및 데이터셋 구축
확보된 지반조사보고서 데이터셋을 분석한 결과 현장 및 실내에서 수행하는 지반시험 종류는 전체 39가지로 나타났으며, 시공 현장 및 수행 시기 등에 따라 그 종류와 수가 상이하게 나타났다. 본 연구에서는 추출 알고리즘의 범용성을 높이기 위해 다양한 현장에서 공통적으로 수행하며, 설계 및 시공 시 활용도가 높은 지반시험을 선정하여 추출하고자 하였다. 표준관입시험 데이터 결과인 N값은 시추주상도 결과 보고서에서 확인할 수 있는데, 국내 말뚝 설계 기준에서는 N값을 바탕으로 말뚝 지지력을 산정하고 있으며(Gang et al., 2018), N값과 상관관계 경험식을 통해 전단파 속도, 탄성계수 등을 결정할 수 있다(Cubrinovski and Ishihara, 1999; Imai and Tonoughi, 2021). 이외에도, 다양한 경험식을 통해 특정 지반 정수로부터 설계를 수행하거나 상관관계를 통한 지반 물성을 예측할 수 있는 식이 제안되어 왔다(Stark and Hussain, 2013; Varol et al., 2021; Zhou et al., 2016). 이에 따라 중요도가 높은 지반정수 데이터가 포함되어 있어, 최종 추출하고자 하는 지반시험 결과 보고서는 시추주상도 및 공내전단시험, 공내재하시험, 하향식탄성파시험, 실내토질시험, 토질일축압축시험, 암석일축압축시험 보고서이며 각 시험에서 추출할 데이터 항목은 Table 1과 같다.
Table 1.
Types of subsurface investigations and corresponding data items to be extracted from each test
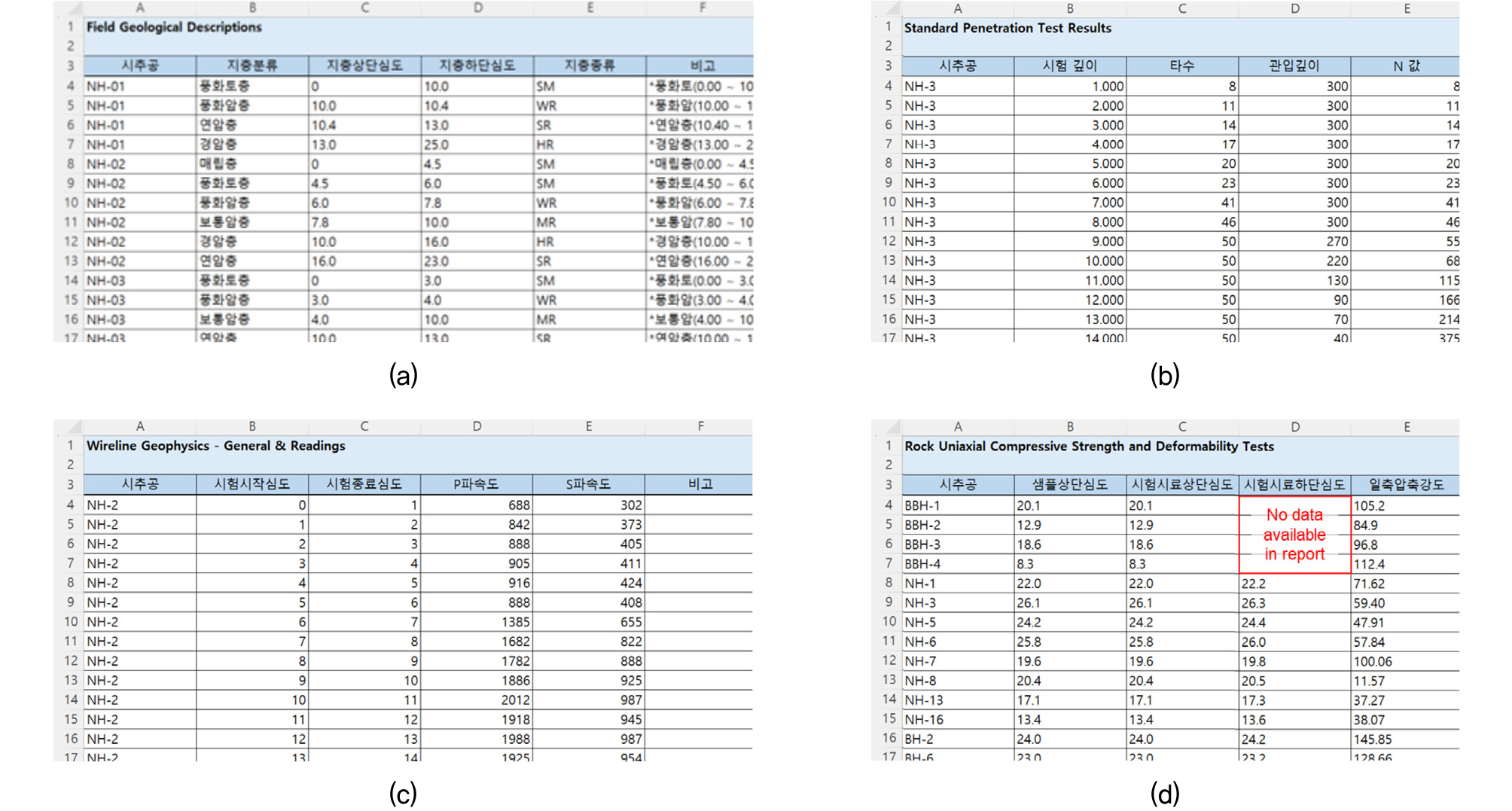
추출한 데이터는 설계 및 시공에 직접적으로 활용할 수 있도록 AGS 형식(association of geotechnical and geoenvironmental specialists data format)의 엑셀 파일 형식 데이터셋으로 정리하였다. 추출 시험 및 추출 데이터의 종류에 따라 다른 데이터 탭 시트에 기술되며, 기본적으로 지반시험을 수행한 시추공을 기준으로 데이터셋이 구축된다. Fig. 6은 저장 데이터 엑셀 시트의 예시를 나타낸다. Fig. 6a는 시추주상도에서 추출할 수 있는 지층 정보를 나타내며, 특히 전문가의 정성적 해석이 포함된 지층기술(description) 부분은 비고란에 따로 저장함으로써 추후 데이터셋 참조성을 향상시키고자 하였다. 깊이에 따른 N치 및 탄성파 속도 또한 지층 별 요약 기술이 아닌 깊이 별 측정값을 누락없이 작성하였다(Fig. 6b, 6c). 일부 시추공에서 특정 깊이의 샘플 시료를 채취하여 시험을 수행하는 실내시험의 경우, 해당 시추공 번호 및 샘플 채취 깊이를 기준으로 데이터셋을 구성하였다(Fig. 6d). 추가적으로, 결과 보고서의 형식에 따라 보고서에 기재되어 있지 않은 데이터 항목이 존재해도 해당 보고서의 누락없이 해당 데이터만 공란으로 처리하였다(Fig. 6d).
본 연구에서 제안한 지반조사보고서에서의 최종 추출 성능을 평가하기 위해 정확도(accuracy) 지표를 도입하였다. 정확도는 해당 지반시험 결과 보고서 전체 개수 중 정확하게 추출한 결과 보고서 개수를 의미하며, 다음 식 (1)을 이용하여 계산하였다.
확보한 지반조사보고서 중 일부는 텍스트를 추출할 수 없는 PDF 파일 속성을 가지고 있으며, 이에 따라 최종적으로 텍스트 읽기가 가능한 205개의 지반조사보고서에서 추출을 수행하였다. 각 지반조사보고서에는 상이한 종류의 세부 지반시험 결과 보고서가 모두 포함 되어있고, 데이터 추출은 지반시험 별로 독립적으로 수행된다. 따라서 정확도 분석은 각 지반시험 결과 보고서를 기준으로 평가하였다. 추출 결과, 주요 8개의 시험에서 모두 83% 이상의 높은 추출 정확도를 보였으며, 평균 93.0%의 추출 정확도를 확인할 수 있었다(Fig. 7). 정확하게 추출되지 않은 결과 보고서의 경우 소수의 복잡한 형식으로 구성되어 있었으며, 향후 페이지 레이아웃 분석 및 텍스트 후처리 과정을 정밀하게 고도화한다면 정확도를 향상시킬 수 있을 것으로 기대된다.
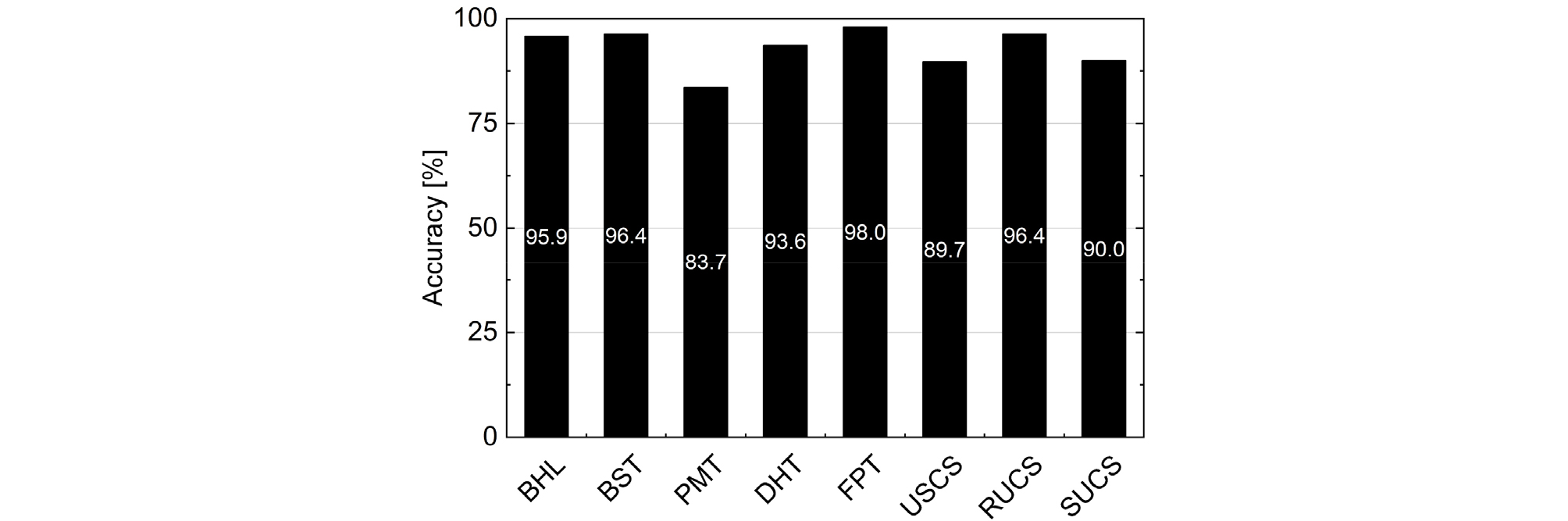
Fig. 7
The result accuracy of data extraction. The names of tests are as follows; BHL: borehole log; BST: borehole shear test; PMT: pressuremeter test; DHT: downhole test; FPT: field permeability test; USCS: soil laboratory test; RUCS: rock unconfined strength test; SUCS: soil unconfined strength test
4. 사용자 인터페이스 기반 추출 프로그램
지반조사보고서 데이터 자동 추출 모델의 실무 적용성을 향상시키기 위해, 사용자 인터페이스(user interface) 기반의 Windows 10 독립 실행형 프로그램(stand-alone executable program)을 개발하였다. 프로그램은 사용자 상호작용(interaction)을 기반으로 수행되며, 주요 기능은 추출할 지반조사보고서 파일 업로드, 보고서 세부 구성 지반시험 분석, 추출하고자 하는 지반시험 보고서 내 데이터 추출 기능으로 이루어진다.
프로그램의 전체 화면은 Fig. 8과 같으며, 크게 상단 메뉴바(i.e., File, Process, Options, Help)와 메인 화면으로 구성된다. 메인 화면 내 Explorer 섹션은 업로드한 지반조사보고서 PDF 파일 목록을 볼 수 있으며, 메인 화면 중앙 상단에 각 지반조사보고서 별 수행 단계 안내 및 단계 별 수행 버튼 섹션이 존재한다(i.e., Process navigator). 하나의 지반조사보고서를 구성하는 세부 지반시험 결과 보고서의 종류 및 해당하는 페이지는 Tests 섹션에서 확인할 수 있으며, 최종적으로 추출이 완료된 데이터는 Geo Data sheet 섹션에 표시된다. 이 때, Geo Data sheet는 최종적으로 저장되는 AGS 형식의 엑셀과 동일한 탭 이름 및 데이터 항목 이름을 가진다. 또한 Viewer 섹션을 통해 사용자가 직접 실제 지반조사보고서를 페이지별로 확대/축소하며 확인할 수 있는 기능을 제공하였다.
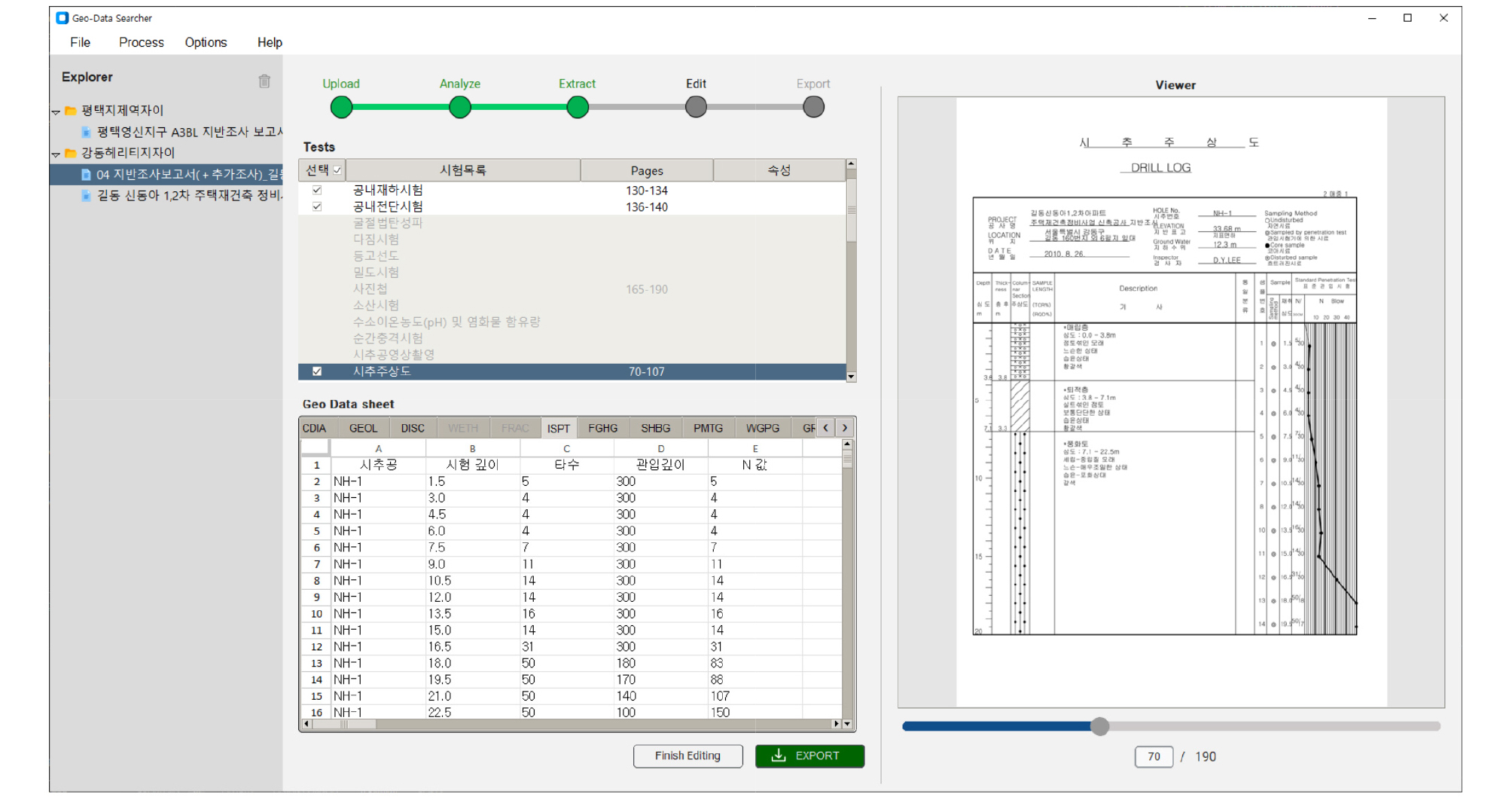
개발된 프로그램을 통한 데이터 추출 주요 흐름은 다음과 같다. 우선 프로그램 내 파일 업로드 기능(i.e., 메뉴바 > [File] > Upload 혹은 Process navigator > [Upload])을 통해 지반조사보고서 PDF 파일을 업로드한다. Explorer 섹션에서 추출하고자 하는 지반조사보고서를 선택한 후 보고서 구성 분석 수행 버튼을 클릭하면(i.e., 메뉴바 > [Process] > Analyze 혹은 Process navigator > [Analyze]), 지반조사보고서를 구성하는 세부 지반시험 결과 보고서의 종류와 상응하는 페이지 위치가 Tests 섹션에 표시된다. 이 때, 표시되는 항목은 CNN 모델 및 텍스트 마이닝 기법이 모두 적용된 최종 페이지 분류 및 분석 결과이다. 이후 추출하고자 하는 세부 지반시험을 복수선택하고 데이터 추출 버튼을 클릭하면(i.e., 메뉴바 > [Process] > Extract 혹은 Process navigator > [Extract]), 페이지 레이아웃 분석을 기반으로 한 데이터 추출이 수행되고 최종적으로 Geo Data sheet 섹션에 탭 별로 추출 데이터가 표시된다. 또한 Geo Data sheet 섹션은 프로그램 내부에서 직접 사용자 입력이 가능한데, Viewer 섹션을 통해 사용자가 실제 지반조사보고서를 확인하면서 데이터를 추가하거나 수정할 수 있다. 본 기능은 사용자가 추가적으로 다른 데이터를 입력하고자 하거나 추출 오류 혹은 누락이 발생하였을 때 유용하게 사용할 수 있으며, 이를 통해 프로그램 활용성 및 편리성을 향상시켰다. 최종 Export 버튼을 통해 저장할 파일 경로를 선택하면 Geo Data sheet 섹션 표시된 대로 데이터셋이 엑셀 파일로 추출된다.
5. 결 론
지반조사보고서는 설계 및 시공 과정에 필수적인 현장 지반 정수 데이터를 포함하고 있으나, 현장 특성, 작성 시기, 지반조사 수행 업체 등에 의해 보고서마다 형식이 상이하게 존재한다. 지반조사보고서 부록을 구성하는 세부 지반시험 결과 보고서 또한 종류 및 형식이 매우 다양하고, 사람만이 읽기 쉬운 비구조적 문서 형식을 갖고 있다. 이에 따라 현재 지반정수의 디지털 데이터베이스 입력은 전문가의 수동 입력을 기반으로 이루어지고 있다. 본 연구에서는 지반조사보고서 데이터 자동 추출을 통한 효율적인 지반 데이터베이스 구축을 위해 딥러닝 및 텍스트 마이닝 기법을 도입하고, 이미지 기반 페이지 레이아웃 분석법을 적용하였다.
(1) 지반조사보고서는 다양한 종류의 세부 지반시험 결과 보고서가 포함되어 있으며, 지반시험 별로 추출하고자 하는 데이터 항목이 다르므로 선행적으로 지반조사보고서를 구성하는 시험 결과 보고서 종류를 분류하는 것이 필요하다. 이미지 기반 분류 문제에 뛰어난 성능을 보이는 합성곱 신경망 기술을 도입하여, 사전 학습된 EfficientNet-b0 구조의 딥러닝 모델을 전이학습을 통해 최적화시키고 페이지 분류를 수행하였다. 그 결과 87%의 정확도를 보이는 공내전단시험 보고서 페이지를 제외하고 모두 97% 이상의 분류 정확도를 보임을 확인하였다.
(2) 딥러닝 기반 페이지 분류를 통해서도 충분한 분류 성능을 제공하지만, 더욱 정확도 높은 데이터 추출을 위해선 오류 없이 정확한 시험 라벨로 분류하는 것이 중요하다. 이에 따라 선행한 딥러닝 기반 분류 결과를 보완하기 위한 텍스트 서칭 알고리즘 기법을 도입하였다. 딥러닝 결과로 출력된 페이지 라벨 별 신뢰 점수 벡터를 활용하여 페이지 내 해당 텍스트의 존재 여부를 탐색하였다. 이를 통해, 최종적으로 주요 지반시험 결과 보고서를 100%의 정확도로 분류할 수 있음을 확인하였다.
(3) 컴퓨터 비전 기법을 활용하여 지반시험 페이지 내 선 구조 탐지를 기반으로 레이아웃을 분석하고, 이에 따른 유효한 데이터 추출 영역을 자동으로 결정하였다. 최종 데이터 추출은 지반시험에 따라 추출하고자 하는 데이터 항목과 상응하는 지반 데이터를 텍스트 분석을 통해 구조적으로 추출하였다. 추출된 데이터는 설계 및 시공에 직접적으로 활용될 수 있도록 엑셀 형식의 정리된 데이터셋으로 정리하였으며, 그 결과 주요 지반시험 데이터를 평균 93%의 정확도로 추출이 가능하였다. 이에 따라 복잡한 레이아웃의 지반시험 결과 보고서에서 필요한 지반 데이터를 효과적으로 추출할 수 있음을 확인하였다.
(4) 추출 모델의 실무 적용성을 향상시키기 위해, 사용자 인터페이스 기반 Windows 프로그램을 개발하였다. 해당 프로그램은 사용자 상호작용을 기반으로 수행되며, 지반조사보고서 PDF 파일을 업로드하고 자동으로 보고서 구성을 분석, 데이터를 추출하는 기능을 제공하고 각 단계별 결과 가시화를 구현하였다. 또한, 자동 추출된 데이터를 프로그램 내에서 직접 확인하고 편집할 수 있는 기능을 제공함으로써 확장된 실무 적용성을 제시하였다. 이를 통해 지반조사보고서의 디지털화 및 지반 데이터베이스 구축이 더욱 경제적이고 정확하게 이루어질 수 있을 것으로 기대된다.
