

1. 서 론
2. 인공신경망 이론
3. 방법론
3.1 데이터 수집 및 전처리
3.2 MS-ANN 모델 설계
3.3 학습 및 검증
3.4 MS-ANN 모델 구조
4. 의사결정 분석 모델 개발
4.1 학습 결과
4.2 검증 결과
4.3 실무적 적용
5. 결 론
1. 서 론
폐광산 지역의 지반침하(Ground Subsidence)는 건축물 및 인프라의 안정성을 위협하는 주요 지질재해로, 심각한 경우 생명과 재산 피해를 초래한다(Waltham et al., 2007; Lee et al., 2012). 지반침하는 채굴 방식, 지질 구조, 지하수 흐름 등 복합적 요인에 의해 발생하며, 정확한 예측과 적절한 보강방법(Reinforcement Method) 선정은 안정성 확보와 경제적 대응에 필수적이다(Siddique and Mahmud, 2022). 2023년 산업통상자원부 통계에 따르면, 국내 광산 5,498개소 중 폐광산(Abandoned Mine)은 5,137개소(93.4%)로, 지반침하 방지와 환경 복구가 시급한 과제이다(Fig. 1).

국내 폐광산은 불규칙한 지질구조, 급경사 지형, 복잡한 지하수 체계, 불완전한 채굴 기록 등 특수한 조건을 가지며, 이는 기존 침하 예측 이론의 직접 적용을 어렵게 한다(Korean Mine Reclamation Corporation, 2016; Yang and Lee, 2017). 기존 국내 연구에서는 응력아치-체적팽창법(Stress Arch-Volume Expansion Method), 수치해석법(Numerical Analysis), 퍼지추론기법(Fuzzy Inference)(Choi et al., 2009) 등 다양한 접근(Park et al., 2024)이 시도되었다. 그러나 응력아치-체적팽창법(Park et al., 2024)을 사용한 연구는 침하 발생 여부를 92.3% 정확도로 평가하지만, 침하 규모나 범위 예측에는 한계가 있다. 수치해석법은 침하 깊이 추정 시 72.3% 정확도를 보이나, 침하 폭 추정에서는 성능이 저하된다. 또한, 주성분분석(Principal Component Analysis)과 Ryu et al.(2007)의 확산방정식(Diffusion Equation) 기반 접근은 영향인자의 기여도를 분석했으나, 요인 간 비선형 상호작용을 충분히 모델링하지 못했다.
국외에서는 인공신경망(Artificial Neural Network, ANN) 기반 모델이 비선형 관계 모델링에 강점을 보여 지반침하 예측에 활용되고 있다. 예를 들어, Li et al.(2024)은 앙상블 신경망(Ensemble Neural Network)을 통해 탄광의 침하 예측 정확도를 향상시켰으며, Zhang et al.(2022)은 베이지안 신경망(Bayesian Neural Network)으로 불확실성을 정량화했다. 그러나 이러한 모델은 해외 광산의 지질 조건과 채굴 방식에 최적화되어 있어 국내 폐광산의 특수성을 반영하기 어렵다(Bui et al., 2016). 국내 ANN 기반 모델의 연구는 지속되고 있지만, 지역적 특성과 불확실성을 통합적으로 고려한 사례가 부족하다.
MS-ANN은 침하 가능성 판별, 침하 범위 예측, 보강방법 추천을 계층적으로 수행하는 인공신경망 모델이다. 이 모델은 한국광해광업공단의 247개 침하 사례와 30개 영향인자를 활용해 구축되었다. RPROP(Resilient Backpropagation) 알고리즘을 통해 학습된 본 모델은 국내 폐광산의 특수성을 반영한 세분화된 데이터 처리와 불확실성 정량화 기법을 통합하여 예측 정확도를 높였다. MS-ANN은 침하 위험 평가와 보강 공법 추천을 위한 신속한 의사결정 지원을 통해 폐광산 복구 사업의 효율성을 향상시키고, 지질재해 관리 및 지속가능한 토지 이용에 기여할 것으로 기대된다.
2. 인공신경망 이론
인공신경망(Artificial Neural Network, ANN)은 뉴런과 시냅스의 상호작용을 모사하여 복잡한 비선형 문제를 해결하는 기계학습 모델이다(Kriegeskorte, 2015). ANN은 입력층(Input Layer), 은닉층(Hidden Layer), 출력층(Output Layer)으로 구성되며, 데이터의 패턴을 학습해 예측 및 분류를 수행한다(Fig. 2). 특히, 지반침하(Ground Subsidence)와 같이 다변수와 비선형 상호작용이 복잡한 지질공학 문제에 적합하다(Bui et al., 2016). ANN의 주요 아키텍처에는 피드포워드 신경망(Feedforward Neural Network, FNN), 심층 신경망(Deep Neural Network, DNN), 순환 신경망(Recurrent Neural Network, RNN) 등이 있다. FNN은 단방향 정보 흐름을 통해 간단한 구조로 높은 예측 성능을 제공하므로 본 연구의 MS-ANN에 적합하며, Fig. 2는 ANN의 기본 구조와 FNN의 정보 흐름을 나타낸다.
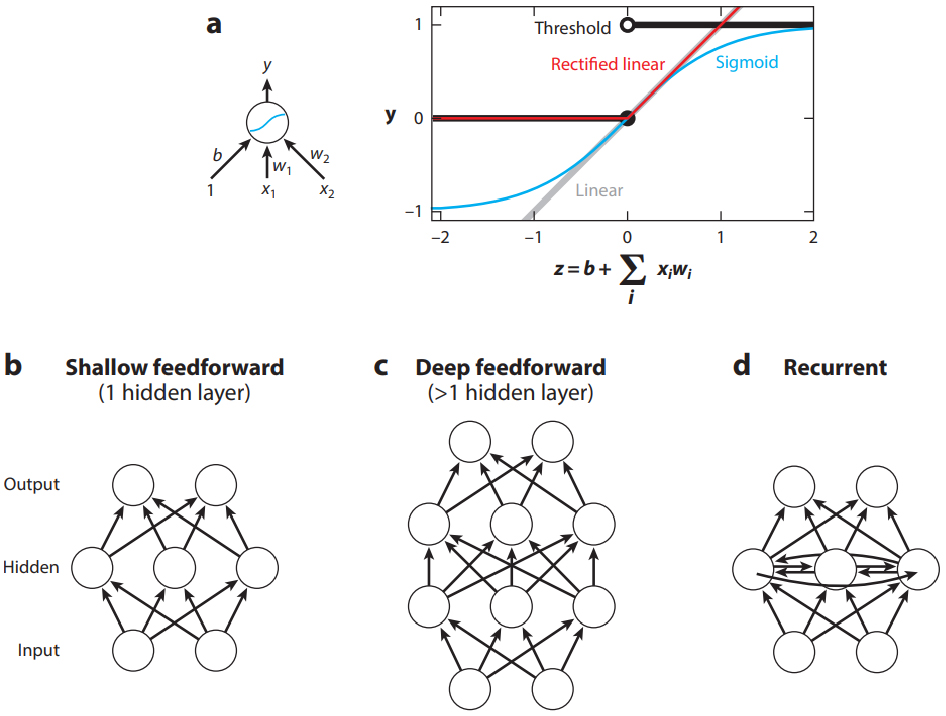
ANN 학습은 역전파(Backpropagation) 알고리즘을 통해 가중치를 조정하며, RPROP는 학습 속도와 안정성을 향상시킨다(Riedmiller and Braun, 1994). 본 연구는 FNN 기반 MS-ANN을 설계하고, RPROP를 활용해 국내 폐광산의 특수한 지질 조건과 침하 사례 데이터를 학습하였다. MS-ANN은 침하 가능성, 범위, 보강방법을 계층적으로 예측하도록 설계되었다. 이를 위해 입력층은 침하지 정보(침하 유형, 깊이 등), 채굴 정보(채굴 방식, 광물 종류 등), 암반 및 토지이용 데이터를 처리하며, 출력층은 침하 발생 여부, 조사 필요성, 보강 공법을 예측한다.
3. 방법론
3.1 데이터 수집 및 전처리
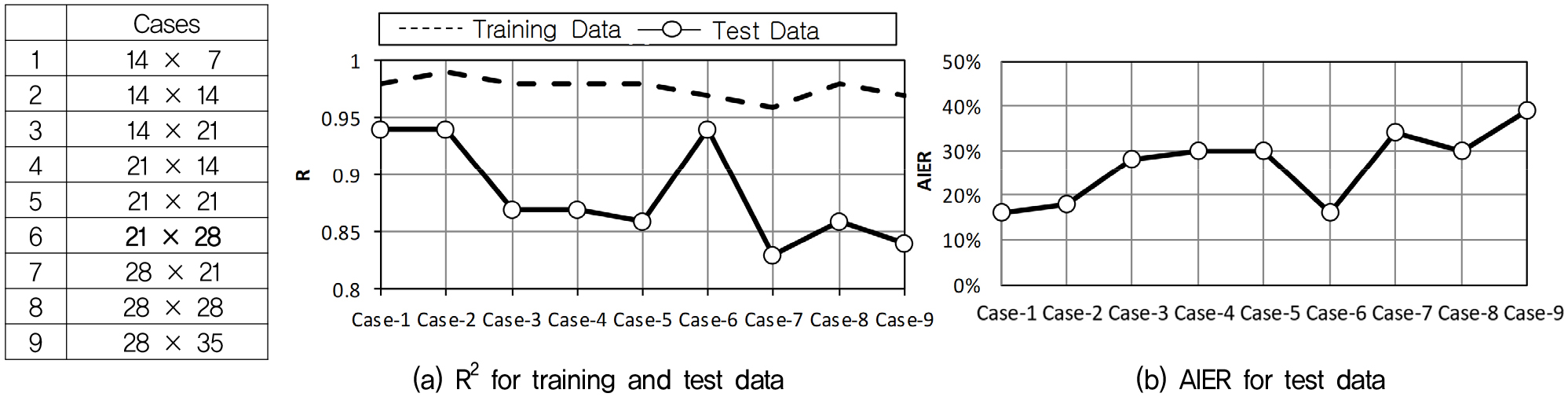
본 연구는 폐광산의 247개 지반침하(Ground Subsidence) 사례를 활용하였다. 데이터는 27개 폐광산(Abandoned Mine) 지역(석탄광 17개, 일반광 10개)에서 수집되었으며(Fig. 3), 문헌 조사로 선정한 30개 영향인자를 기반으로 구성되었다(Korean Mine Reclamation Corporation, 2011). 영향인자는 침하지 정보(5개: 침하 유형, 원인, 폭, 길이, 깊이), 채굴 정보(11개: 채굴 방식, 광물 종류, 채굴 기간 등), 암반 정보(9개: 암석 종류, 압축 강도, 투수계수 등), 토지이용 정보(2개: 용도 유형, 지표 구조물), 보강 정보(3개: 조사 필요성, 보강 공법)로 분류되었다(Table 1).
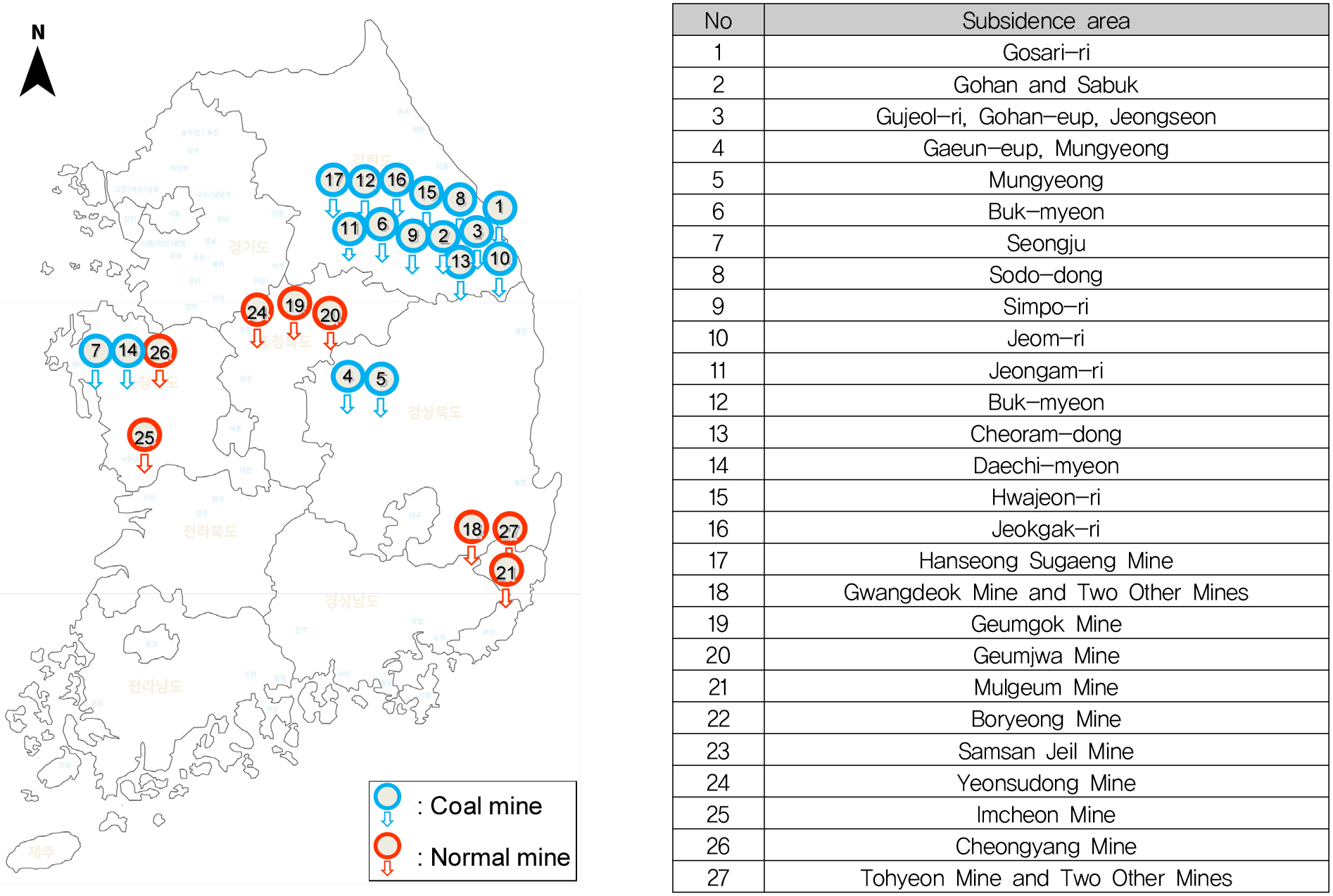
Table 1.
Standardized node table for ground subsidence analysis in abandoned mines
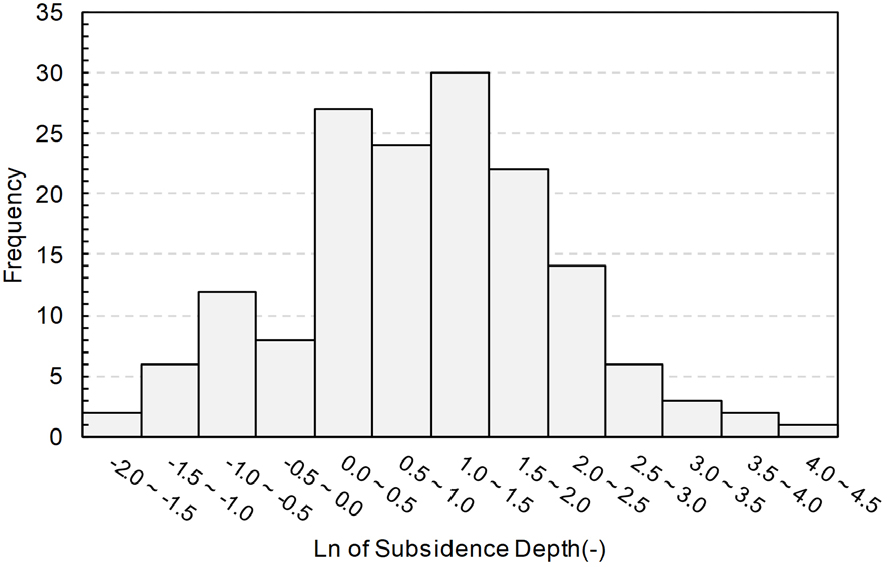
데이터 전처리의 결측값은 지역별 평균값 또는 유사 사례의 데이터를 대체하여 처리하였으며, 연속형 변수(예: 침하 깊이, 투수계수)는 정규화(Normalization)를 통해 [0, 1] 범위로 변환하였다. 범주형 변수(예: 침하 유형, 채굴 방식)는 연속형 노드(Sequential Node)를 적용하으며 최종적으로 229개 사례를 학습 데이터(Training Data), 18개 사례를 시험 데이터(Test Data)로 분할하였다. 토지이용 정보는 국립지리원의 용도지역 분류를, 보강 정보는 광해방지기술기준에 따라 표준화하였다. Fig. 4(a)에서는 침하 깊이에 자연로그(Ln) 변환을 적용한 결과가 대체로 정규분포를 보이며, 이는 극단적인 침하 사례가 적고 평균값을 중심으로 안정적으로 분포함을 의미하며 석탄광산에서 침하 발생 빈도가 가장 높게 나타났으며, 기타 비금속광산, 금속광산, 금광 순으로 빈도가 낮아지는 경향을 보였다.
3.2 MS-ANN 모델 설계
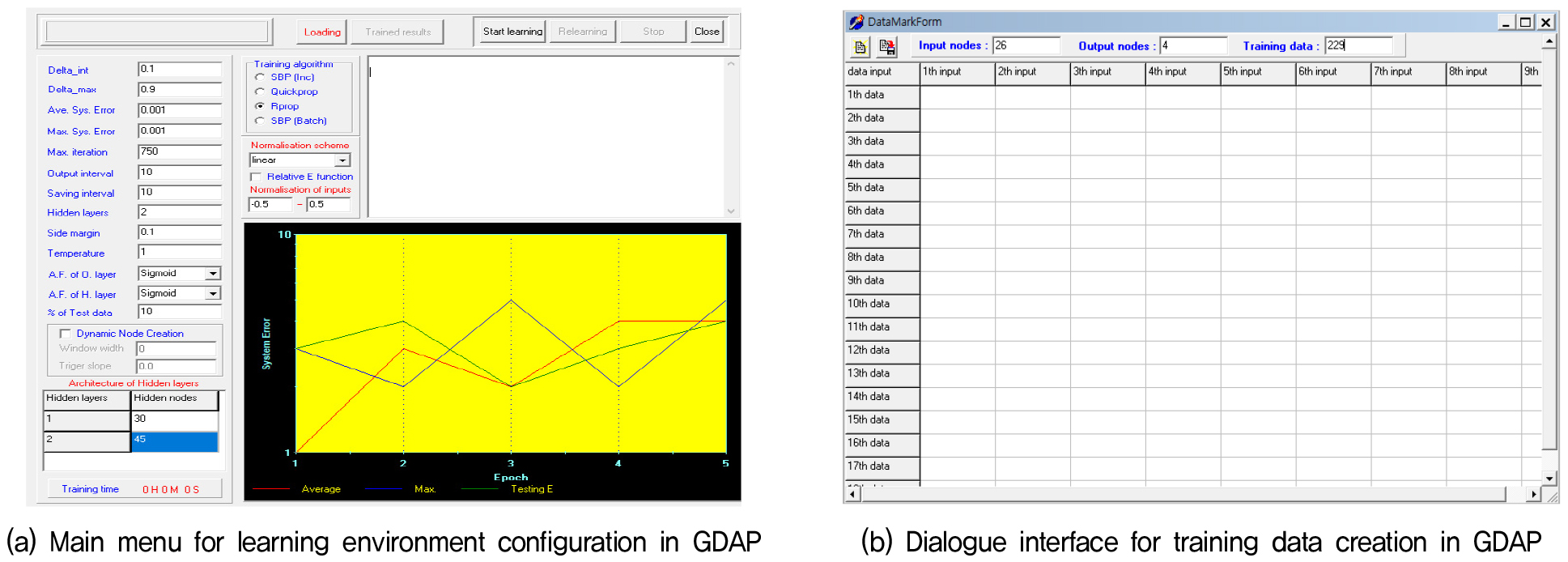
MS-ANN은 피드포워드 신경망(Feedforward Neural Network, FNN)을 기반으로 설계되었다. 모델은 Generalized Data Analyser and Predictor(GDAP) 소프트웨어를 활용해 구현되었다(Shin, 2001). 학습 알고리즘은 RPROP를 사용하였으며, 감소계수(Reduction Factor) 0.5, 증가계수(Increase Factor) 1.2, 초기 델타값 0.1, 최대 델타값 50으로 설정하였다(Riedmiller and Braun, 1994). 활성화 함수로는 시그모이드 함수(Sigmoid Function)를 적용하여 비선형 관계를 구성하였다. Fig. 5(a)는 GDAP의 학습 환경 설정 인터페이스를 나타내며, Fig. 5(b)는 입력창을 나타낸다.
3.3 학습 및 검증
학습은 229개 학습 데이터를 대상으로 RPROP 알고리즘을 통해 수행되었으며 시스템 오차(System Error)는 0.0001, 최대 반복 횟수는 조기 종료(Early Stopping) 기법을 적용해 320회로 설정하였다. 학습 과정에서 과적합(Overfitting)을 방지하기 위해 교차검증(Cross-Validation)을 실시하였다. 시험 데이터(18개)를 활용한 검증에서는 결정계수(R2)와 평균 추론 오차율(Average Inference Error Rate, AIER)을 평가하였으며, AIER은 수식 (1)를 통해 계산되었다.
여기서, 은 측정치, 은 추론치, n은 추론에 사용된 자료 수이다.
3.4 MS-ANN 모델 구조
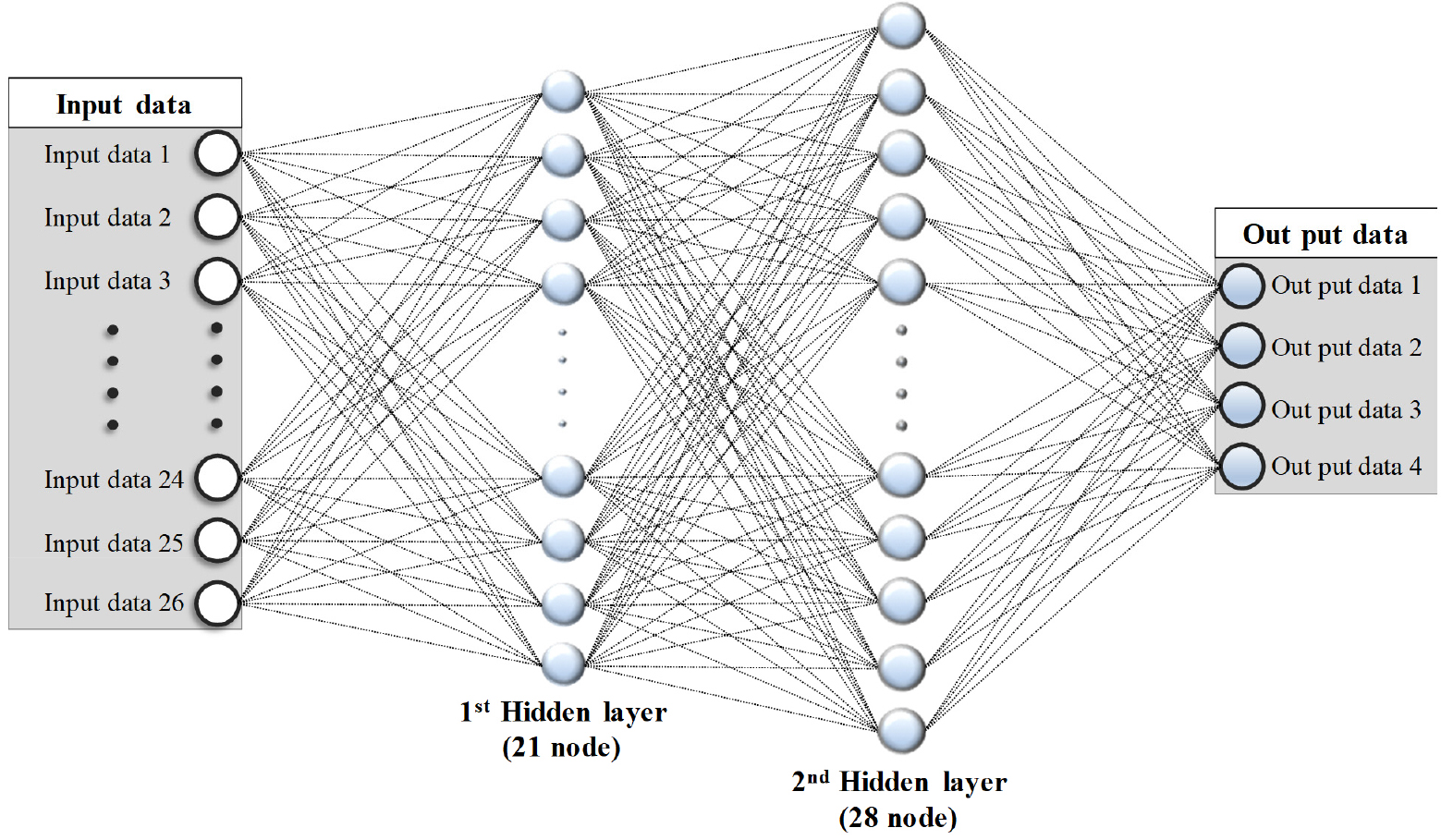
최적 구조는 입력층 21개 노드, 은닉층 2개(21개, 28개 노드), 출력층 9개 노드로 구성되었다. Fig. 6은 다양한 노드 수에 따른 학습 및 시험 데이터의 결정계수(R2)와 AIER 변화를 보여준다. Case 6에서 시험 데이터의 결정계수가 높고 AIER이 낮아 최적 구조로 선정하였다. Fig. 7과 같이 입력층은 침하지, 채굴, 암반, 토지이용 데이터를 처리하며, 출력층은 침하 여부, 정밀조사 필요성, 보강방법을 예측한다.
4. 의사결정 분석 모델 개발
4.1 학습 결과
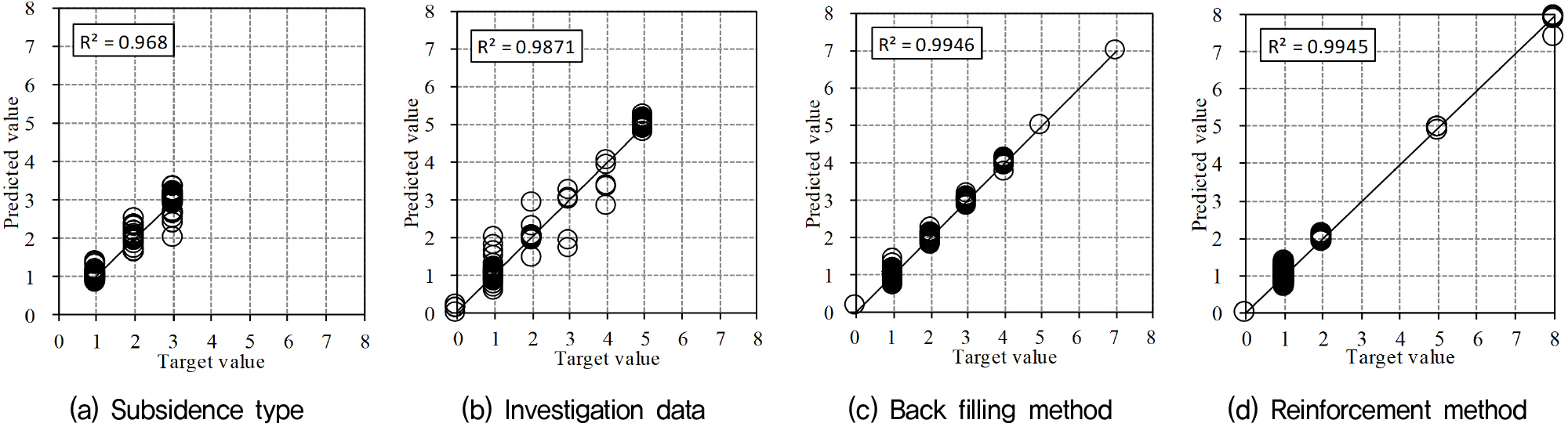
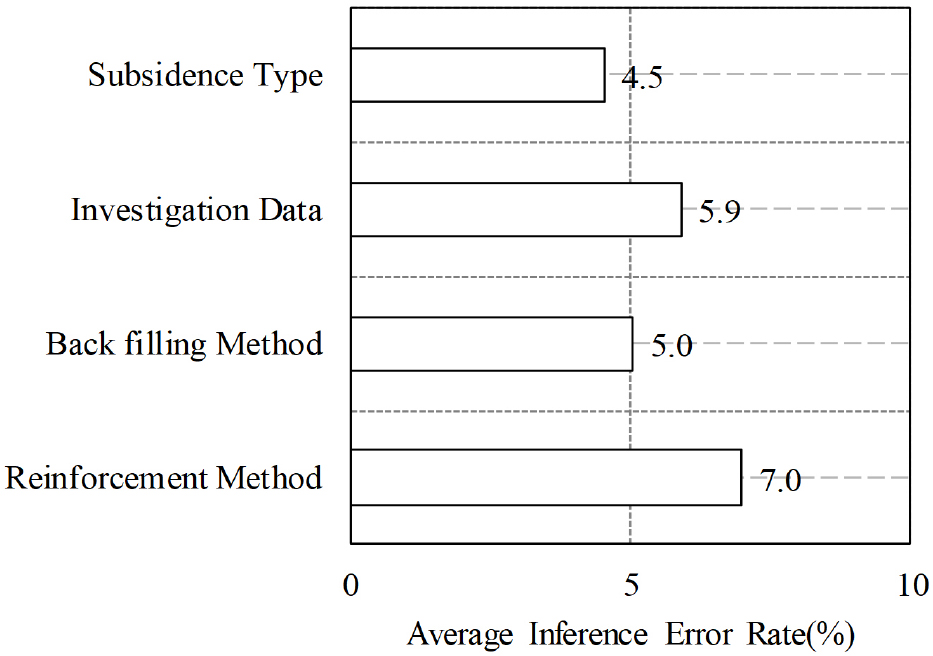
MS-ANN은 229개 학습 데이터(Training Data)를 대상으로 RPROP 알고리즘을 통해 훈련되었다. Fig. 8과 같이 학습 결과 결정계수(R2)는, 침하 유형(Subsidence Type) 추론 결정계수(R2)는 0.968, 조사 필요성 추론은 0.9871, 뒷채움공법은 0.9946, 보강정보는 0.9945로 높은 예측 정확도를 달성하였다. 또한, 평균 추론 오차율(Average Inference Error Rate, AIER)은 침하 유형 4.5%, 조사 필요성 5.9%, 뒷채움공법 5.0%, 보강정보 7.0%로 나타났다(Fig. 9). 이는 MS-ANN이 다양한 출력 항목에 대해 안정적이고 신뢰성 있는 예측 성능을 보였다. 특히, 침하 유형과 뒷채움공법에서 상대적으로 낮은 오차율(4.5% 및 5.0%)을 기록하며, 복잡한 지질 조건에서도 일관된 성능을 유지하였다.
4.2 검증 결과
시험 데이터(Test Data) 18개를 활용하여 MS-ANN 모델의 예측 정확성을 검증하였다. Fig. 10은 시험 데이터의 예측값(Predicted Value)과 목표값(Target Value) 간 관계를 나타내며, 각 출력 항목별 결정계수(R2)는 다음과 같다. 침하 유형(Subsidence Type) 추론 결정계수(R2)는 0.9961, 조사 필요성(Investigation Data)은 0.9903, 뒷채움공법(Back-filling Method)은 0.9855, 보강정보(Reinforcement Method)는 0.9855를 기록하였다.
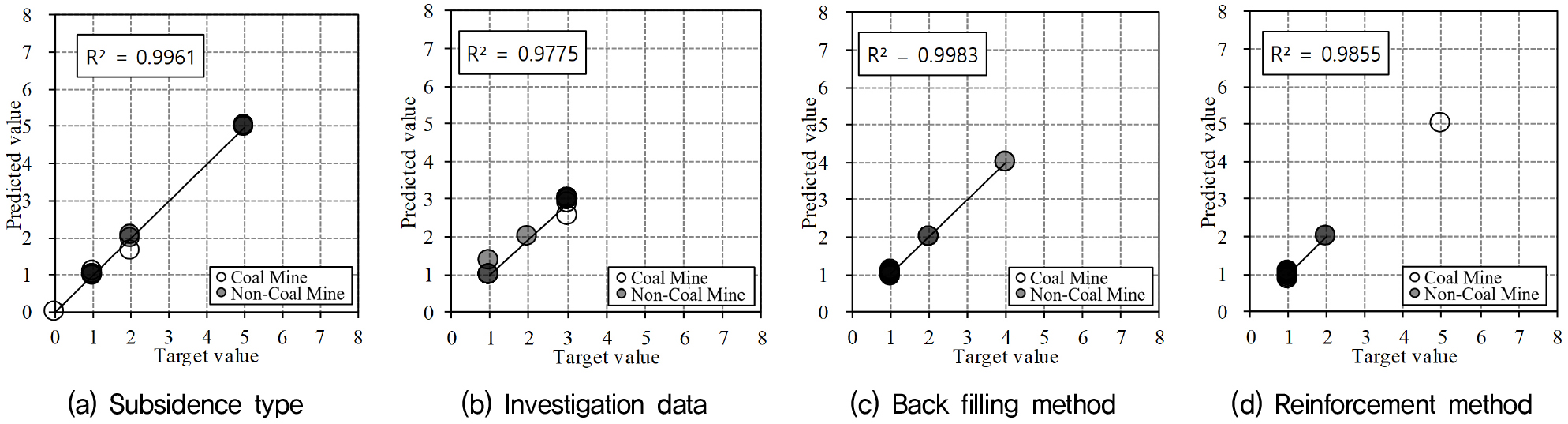
이는 모든 항목에서 높은 결정계수(R2)를 달성하여 모델의 우수한 예측 성능을 입증한다. 특히, 침하 유형과 조사 필요성의 결정계수(R2)가 각각 0.9961과 0.9903으로 매우 높게 나타나, MS-ANN이 복잡한 지질 조건에서도 안정적으로 침하 발생과 조사의 필요성을 판별할 수 있음을 보여준다. 또한, MS-ANN 모델의 평균 추론 오차율은 Fig. 11에 제시된 바와 같이, 각 광종(석탄광 및 일반광) 및 전체 데이터를 구분하여 분석했을 때 의미 있는 결과를 보였다.
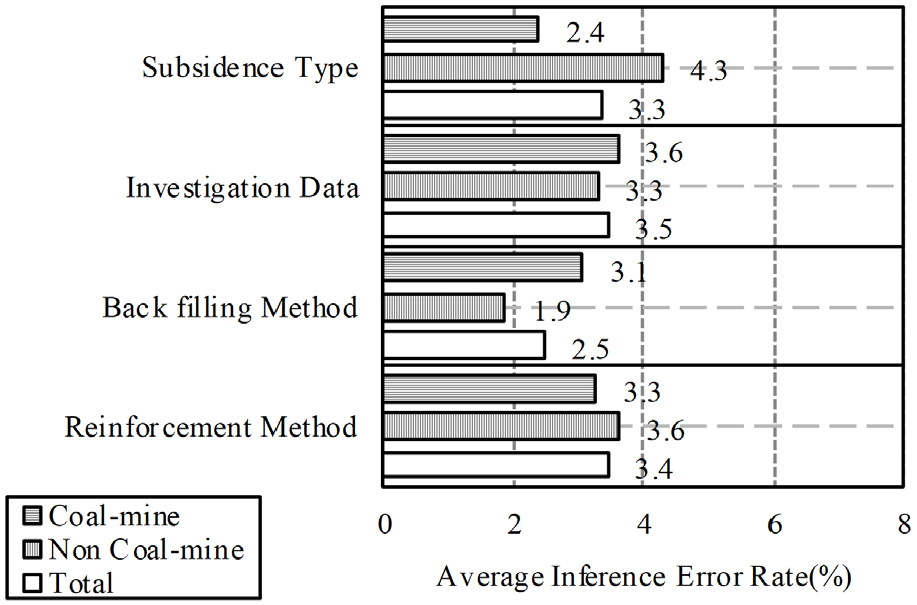
구체적으로 살펴보면, 전체 데이터 기준으로 침하 유형 3.3%, 조사 필요성 3.5%, 뒷채움공법 2.5%, 보강정보 3.4%의 AIER을 나타냈다. 이는 학습 데이터의 AIER (4.5~7.0%, Fig. 8)보다 전반적으로 낮은 결과로, MS-ANN 모델의 우수한 일반화 성능을 입증한다. 특히, 광종별로 AIER을 세분화하여 분석한 결과, 석탄광 데이터에서는 침하 유형 2.4%, 조사 필요성 3.6%, 뒷채움공법 1.9%, 보강정보 3.3%를, 일반광 데이터에서는 침하 유형 4.3%, 조사 필요성 3.3%, 뒷채움공법 2.5%, 보강정보 3.6%를 기록하였다. 세부적으로는, 뒷채움공법의 AIER이 전체 데이터 기준 2.5%로 가장 낮았고, 특히 석탄광에서는 1.9%로 낮은 오류율을 보여 보강 공법 추천에 있어 매우 높은 신뢰성을 나타냈다. 이는 석탄광의 경우 뒷채움공법 관련 데이터가 다른 광종에 비해 명확하거나 패턴화되기 쉬운 특성이 반영된 결과로 해석될 수 있다. 반면, 조사 필요성과 보강정보의 AIER은 전체 기준 3.5% 및 3.4%로 상대적으로 높게 나타났으나, 광종별로 살펴보면 일반광의 침하 유형(4.3%)과 보강정보(3.6%)에서 상대적으로 높은 오류율을 보였다.
4.3 실무적 적용
4.3.1 예측 성능 기반 실무적 유효성
MS-ANN 모델의 시험 데이터 결정계수는 침하 유형, 조사 필요성, 보강 공법 예측 성능을 나타낸다. 침하 유형의 결정계수 0.9961은 폐광산 지역 침하 발생 판별의 높은 신뢰성을 보여주며, 불규칙한 지질구조와 급경사 지형으로 침하 예측이 어려운 국내 폐광산에서 초기 위험 평가와 침하 지역 선별에 활용할 수 있다. 시험 데이터의 낮은 평균 추론 오차율(AIER)은 모델의 안정성과 일반화 성능을 보여준다. 석탄광 뒷채움공법의 AIER 1.9%는 보강 공법 추천의 높은 신뢰성을 입증한다. 불완전한 채굴 기록과 복잡한 지질 조건으로 보강 공법 선정이 어려운 국내 폐광산에서 MS-ANN은 30개 영향인자를 종합 분석하여 데이터 기반 접근법을 제공하며, 예산 제한 프로젝트에서 비용 효율적인 뒷채움공법 우선순위 설정에 기여한다.
4.3.2 실무 적용성 및 의사결정 체계화
국내 폐광산은 지반침하로 토지이용이 제한되어 지역 경제와 환경에 영향을 미치며, MS-ANN은 침하 예측을 통해 지속가능한 토지 이용에 기여할 수 있다. MS-ANN은 침하 위험이 낮은 지역을 식별하여 농업용지, 공공시설, 재생에너지 설비 부지로의 전환을 가능하게 한다. 계층적 예측 구조(침하 가능성 → 범위 → 보강 공법)는 의사결정을 체계화하여 전문가와 정책 결정자의 복구 계획 수립을 지원한다. 석탄광과 일반광 데이터를 구분한 분석은 광종별 맞춤형 의사결정을 통해 복구 사업 계획 수립에 기여한다.
5. 결 론
본 연구는 247개 침하 사례와 30개 영향인자(지질 12개, 채굴 10개, 침하지 4개, 토지이용 4개)를 활용하여 국내 폐광산 지반침하 예측 및 보강 공법 결정을 위한 MS-ANN 모델을 개발하였다. 입력층 21개, 은닉층 2개(21개, 28개 노드), 출력층 9개 노드로 구성된 최적 구조를 RPROP 알고리즘으로 학습하여 침하 발생, 범위, 보강 공법을 계층적으로 예측한다.
성능 검증 결과, 시험 데이터에서 결정계수(R2) 0.9855~0.9961, 평균 추론 오차율(AIER) 2.5~3.5%를 달성하여 학습 데이터(R2 0.968~0.9946, AIER 4.5~7.0%) 대비 향상된 일반화 성능을 보였다. 특히 침하 유형 예측에서 R2 0.9961을 기록하여 복잡한 지질 조건에서도 높은 신뢰성을 확인하였다. 뒷채움공법 예측의 AIER 2.5%는 4개 출력 항목 중 가장 낮아 보강 공법 추천 시스템으로서의 실용성을 입증하였다.
광종별 성능 분석에서 석탄광은 침하 유형 AIER 2.4%, 뒷채움공법 1.9%를, 일반광은 각각 4.3%, 2.5%를 기록하였다. 석탄광 뒷채움공법의 1.9% AIER은 전체 예측 항목 중 최고 성능으로, 석탄광 데이터의 명확한 패턴화 특성이 반영된 결과이다. 일반광에서 상대적으로 높은 오차율(침하 유형 4.3%)을 보였으나, 공학적 허용 범위 내에서 두 광종 모두 실무 적용이 가능한 수준이다.
MS-ANN의 계층적 예측 구조(침하 가능성 → 범위 → 보강 공법)는 복구 사업 의사결정 과정을 체계화한다. 높은 예측 정확도를 바탕으로 침하 위험 등급화와 보강 공법 우선순위 설정이 가능하며, 이는 불완전한 채굴 기록과 복잡한 지질 조건으로 어려움을 겪는 국내 폐광산 복구 사업에서 제한된 예산의 효율적 배분과 지질재해 2차 피해 예방에 직접적으로 기여한다. 석탄광과 일반광 데이터 분리 분석을 통한 광종별 특성 고려는 맞춤형 의사결정을 지원하며, 국가 지질재해 관리 정책의 데이터 기반 의사결정 도구로 활용 가능하다.
모델의 한계점으로는 일반광 데이터에서 침하 유형(4.3%)과 보강정보(3.6%)의 상대적 높은 AIER이 확인되었다. 이는 일반광의 다양한 광물 특성과 불규칙한 채굴 패턴으로 인한 데이터 복잡성에 기인한다. 또한 제한된 시험 데이터(18개, 전체의 7.3%)는 모델 일반화 성능 평가에 통계적 제약을 가한다. 향후 지역별, 광종별 다양성을 포함한 대규모 데이터셋(목표 500개 이상) 확보와 베이지안 접근법 등 불확실성 정량화 기법 통합을 통해 모델 적용 범위 확장과 예측 신뢰성 향상이 필요하다.
