

1. 서 론
2. 국토지반정보 포털시스템에서 획득한 지반정보의 오류 사례 및 기존 품질관리 기법
3. 데이터 수집 및 전처리
4. AI를 이용한 지반정보 품질관리 기법
4.1 학습모델
4.2 모델 구성 및 성능평가 지표
4.3 모델의 평가
5. 요약 및 결론
1. 서 론
국내의 지반정보는 국토지반정보 포털시스템에 디지털 데이터베이스(Database, DB)화 되어 관리 및 공유되고 있다. 2022년 1월 현재 국토지반정보 포털시스템에는 약 31만공의 데이터가 구축된 것으로 보고되고 있다. 이 방대한 양의 지반정보는 설계, 시공, 지하안전관리, 재해재난 평가 등 다양한 분야에서 폭넓게 활용되고 있으며, 점차 그 활용이 증가하고 있는 추세이다(Park et al., 2021a).
그러나 전국적으로 기 구축된 지반정보를 상세히 살펴보면, 누락되거나 잘못된 정보를 다수 포함하고 있어서 데이터 분석 시 신뢰성을 크게 저해하고 있으며, 이에 지반정보의 정제(품질관리)의 필요성이 꾸준하게 제기되어 오고 있다(Kim et al., 2011; Kim et al., 2012; Kim et al., 2014; Lee et al., 2017a; Lee et al., 2017b; Lee et al., 2018). 이에 National Disaster Management Research Institute(2021)은 액상화 위험도 평가를 위하여 지반정보의 품질관리 기법 및 절차를 제안한 바 있다. 그러나 이 방법은 데이터의 이상치 탐지 조건을 사람이 일일이 결정하고 설정해서 사전에 파악하지 못한 오류에 대해 대응이 어렵고 효율성이 떨어진다는 단점이 있다(Park et al., 2021b). 여기서 이상치 탐지란 정상상태를 크게 벗어나는 데이터 샘플을 탐지하는 것을 의미한다(Knorr and Ng, 1999).
한편, 데이터 이상탐지는 금융, 의료, 보안, 제조업 등의 분야에서 활발하게 연구되어 오고 있다. 토목분야에서도 최근 상수도 관망 누수, 이상 수질자료, 이상 강우 발생, 구조물 이상 관측 데이터 등을 탐지하기 위한 다양한 이상치 탐지 연구가 진행되어 오고 있다(Kim et al., 2016; Kim et al., 2018; Park and Ha, 2021; Liu and Zou, 2022; Shao et al., 2022). 일반적으로 데이터 이상탐지에는 통계적 기법, 머신러닝, 딥러닝 등이 널리 적용되고 있다. 특히, 인공지능 기반의 이상탐지 기법은 기계가 대량의 정보를 미리 학습하게 하여 인간이 발견하기 어려운 정보 안의 패턴을 식별하고 이를 기반으로 예측, 분류 등을 수행하기 때문에 기존의 전통적 방식(규칙 및 사람에 의한 수동적 탐지) 보다 정확성, 신규패턴 발견 가능성, 속도, 편리성 등을 크게 향상시킬 수 있다는 장점이 있다.
본 연구에서는 딥러닝 기법 중 하나인 인공신경망(Neural Network, NN) 기법을 활용하여 지반정보를 자동으로 품질관리 하는 방안에 대하여 제안하고자 한다. 특히, 가장 일반적으로 사용되는 정보인 표준관입시험결과와 지층정보를 결합한 자료를 이용하여 지반정보의 이상치를 탐지하였다. 서울시 지반정보를 학습 데이터로 활용하였으며, 국토지반정보 포털시스템에서 획득한 기본정보만 포함하여 분석(Model-1)과 심도관련 새로운 변수를 추가하여 분석(Model-2)한 경우에 대하여 분석하였다. 그 결과 심도관련 새로운 변수를 추가하여 분석한 결과 이상치 탐지 모델의 예측 정확률을 94.6%까지 높일 수 있음을 확인하였고, 딥러닝 기법을 이용하여 지반정보의 이상치를 효율적을 탐지할 수 있음을 확인하였다.
2. 국토지반정보 포털시스템에서 획득한 지반정보의 오류 사례 및 기존 품질관리 기법
일반적으로 국토지반정보 포털시스템에서 제공하는 지반정보에는 프로젝트 정보, 지형지질정보, 시추공 정보, 지층 정보, 현장시험 정보, 물성시험 정보, 토사시험 정보, 암석시험 정보, 물리탐사 정보, 지표물리탐사 정보, 전문가 의견 정보 등으로 구성된다. 가장 일반적으로 사용되는 지반정보는 지층정보와 표준관입시험 결과이다. 지층정보는 프로젝트코드, 프로젝트명, 시추공코드, 시추공명, x, y 좌표, 고도, 지하수위, 지층코드, 지층시작심도, 지층종료심도, 지층두께, 토목용 지층명(USCS), 한글지층명, 토질색상, 비고의 항목으로 구성되어 있다. 표준관입시험 결과는 프로젝트코드, 프로젝트명, 시추공코드, 시추공명, x, y 좌표, 시험심도, 표준관입시험_타격회수, 표준관입시험_관입깊이의 항목으로 구성된다.
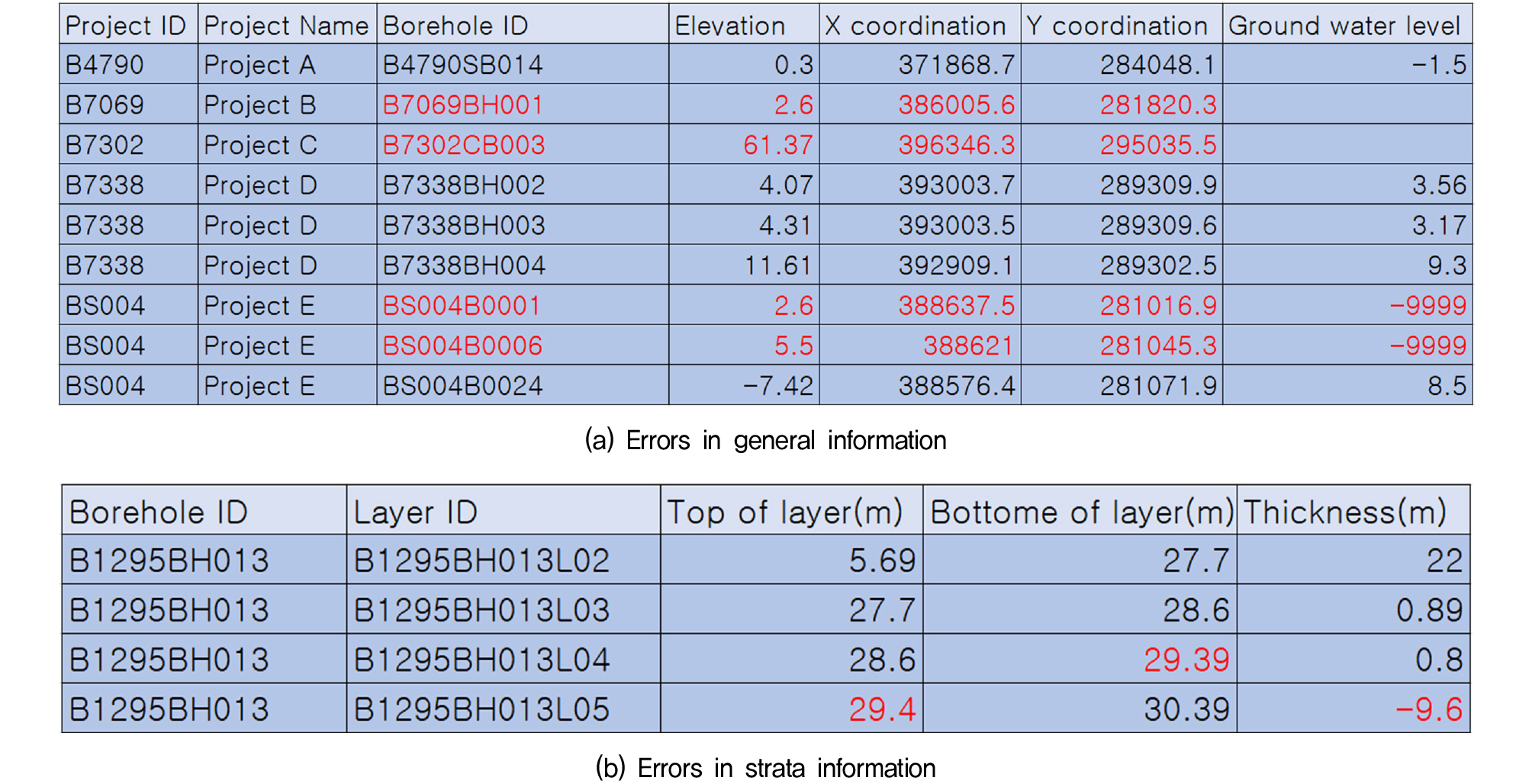
본 연구에서는 국토지반정보 포털시스템에서 획득한 지반정보의 이상치를 탐지하기 전 사전작업으로 발생 가능한 오류 사례에 대하여 검토하고, Fig. 1에 대표 오류 사례를 나타내었다. 국토지반정보 포털시스템에 지반정보를 구축할 때 지반조사 보고서를 보고 사람이 일일이 입력을 해서 진행하기 때문에 정확하지 않은 정보가 기입되는 사례가 자주 발생한다. 첫번째로 지반정보의 x, y 좌표가 대상 영역을 벗어나는 경우나 각각 뒤바뀌어 기입되는 경우가 확인되었다(Fig. 1(a)). 고도나 지하수위가 누락된 경우 혹은 -9999, -99999, 문자 등으로 기입되는 사례도 발생하였다. 지층정보에서는 지층시작심도와 지층심도가 같게 나오거나 뒤바뀌어 작성되는 경우가 확인되었다. 또한 지층 두께의 경우에는 지층시작심도와 종료심도의 차로 계산됨에도 불구하고 이 결과와 상이한 경우가 다수 존재하였다(Fig. 1(b)). 이 밖에도, 한글지층명, USCS, 비고 항목 등에서도 누락과 오타가 발생하는 경우도 다수 존재하였다. 표준관입시험 결과에서는 시험심도, 타격횟수, 관입깊이의 정보가 누락되는 경우와 잘못된 값이 기입되는 경우가 다수 존재하였다.
이에 National Disaster Management Research Institute(2021)은 액상화 위험도 평가를 위하여 지반정보의 품질관리 기법 및 절차를 Fig. 2와 같이 제안하였다. 액상화 위험도 평가를 위하여 필요한 지반정보는 일반적으로 사용되는 지반정보와 동일하게 시험정보, 지층정보, 표준관입시험정보 3가지 정보이다. 기 제안된 품질관리 기법의 1단계에서는 지층정보 데이터 중 심도데이터의 불일치 유무, 지층종류 불일치 유무를 판단하여 필터링을 수행하며, 2단계에서는 SPT 실험 데이터 중 타격횟수가 50회 이상이거나 관입깊이가 30cm 이상인 경우에도 이상치로 간주하고 제외한다. 다만, 이 방법은 오류나 이상치에서 신규패턴이 발생하는 경우에 대응이 어려울 수 있다는 단점이 존재한다.
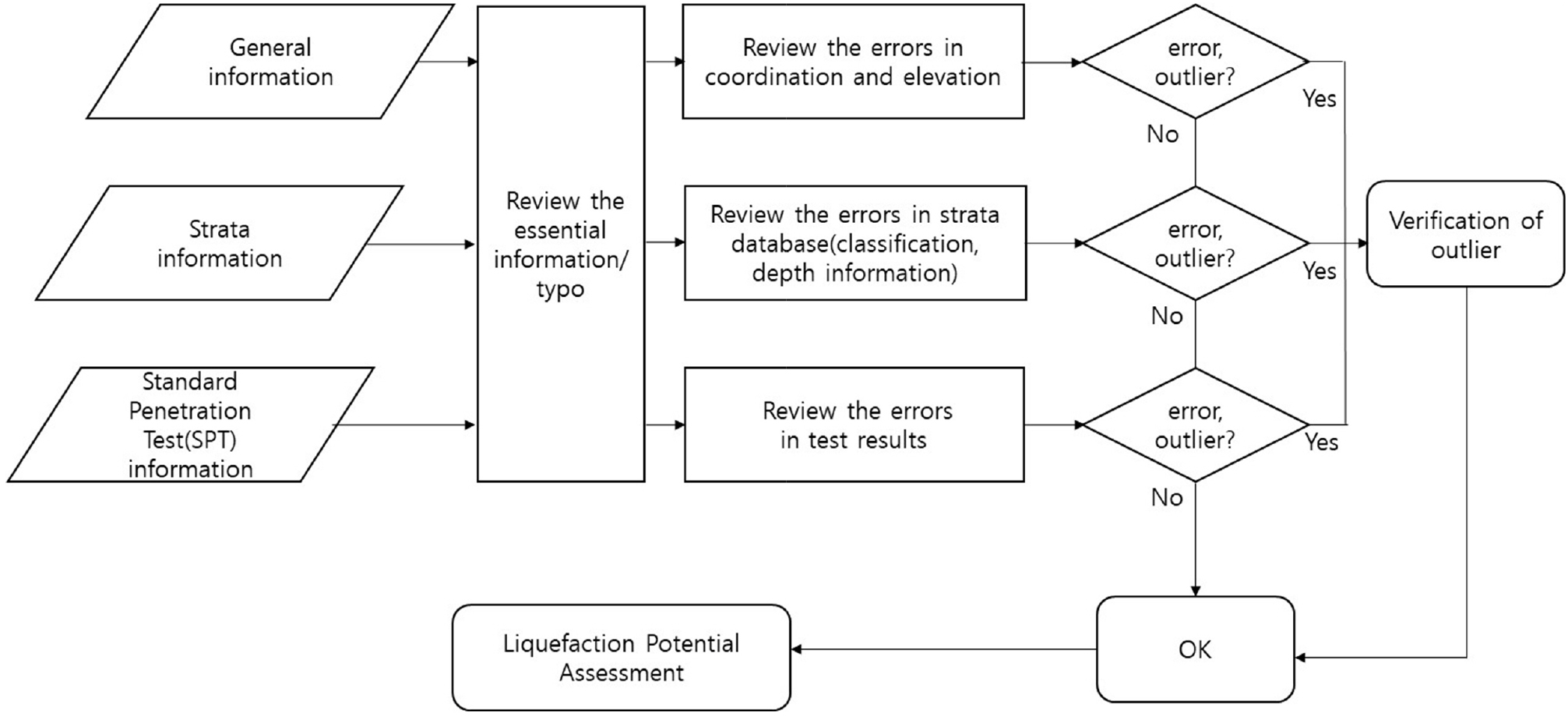
Fig. 2
Flow chart of quality control procedures for liquefaction potential assessment (National Disaster Management Research Institute, 2021)
3. 데이터 수집 및 전처리
본 연구에서는 국토지반정보 포털시스템으로부터 서울특별시의 원본 지반정보(지층정보, 현장시험 정보 중 표준관입시험정보)를 각각 20,270공, 13,688공 획득하였고, 학습에 사용하기 위하여 데이터 전처리를 수행하였다. 데이터 전처리 과정은 표준관입시험 결과와 지층정보를 시추공번호를 기준으로 심도별로 각 정보를 하나로 결합하는 과정을 포함한다. 지층명을 구별하는 방식은 다양할 수 있으나 본 연구에서는 한글지층명을 기준으로 토사와 암반층의 두가지로만 구분하여 지층분류(soil classification) 컬럼을 추가하였다. 토사층의 경우 1, 암반층의 경우에 0으로 표시하였다.
일반적으로 지층정보의 심도는 지층의 종류를 기준으로 작성이 되고, 표준관입시험결과의 정보는 표준관입시험을 실시한 심도(1m 혹은 1.5m 간격)로 작성이 된다. 이처럼 표준관입시험결과 파일의 시험심도와 지층정보의 지층구분 심도가 다르기 때문에 표준관입시험결과 데이터테이블의 시험심도를 기준으로 지층정보에서 해당층의 지층정보를 추출하였다. 누락된 데이터는 삭제하였고, ET 또는 기타로 표기되어서 토사층인지 암반층인지 구별할 수 없는 경우와 잘못 기입된 지층정보의 경우에도 관련 시추공을 제외하였다. 표준관입시험은 30cm를 관입시키는데 필요한 타격횟수를 측정하는 방법이나, 50타 이상의 타격 시 30cm 미만의 관입량이 측정되는 경우 50타에 해당하는 관입량을 측정하여 기입한다. 따라서, 표준관입시험의 타격회수가 50 초과거나 표준관입시험 심도가 30미만인 경우에는 제외 처리하였다. 그 결과, 10,444공(개별 91,1989 개의 데이터)이 분석 대상 시추공으로 분류되었다. 전처리된 파일에는 프로젝트 코드, 프로젝트명, 시추공코드, 시추공명, x, y 위치정보의 시추공 일반정보와 시험심도(depth), 표준관입시험_타격회수(spt_count), 표준관입시험_관입깊이(spt_depth), 지층분류(soil classification)의 시험정보가 남게 된다.
이렇게 데이터 전처리한 결과 파일을 이용하여 데이터 분포를 확인하였다. 분석에 사용한 변수는 지반정보가 공간정보임을 감안하여 일반정보 중에서 x, y 좌표를 포함하였고, 이외에도 시험정보인 시험심도, 표준관입시험_타격회수, 표준관입시험_관입깊이, 지층분류(soil classification)의 총 6가지를 사용하였다.
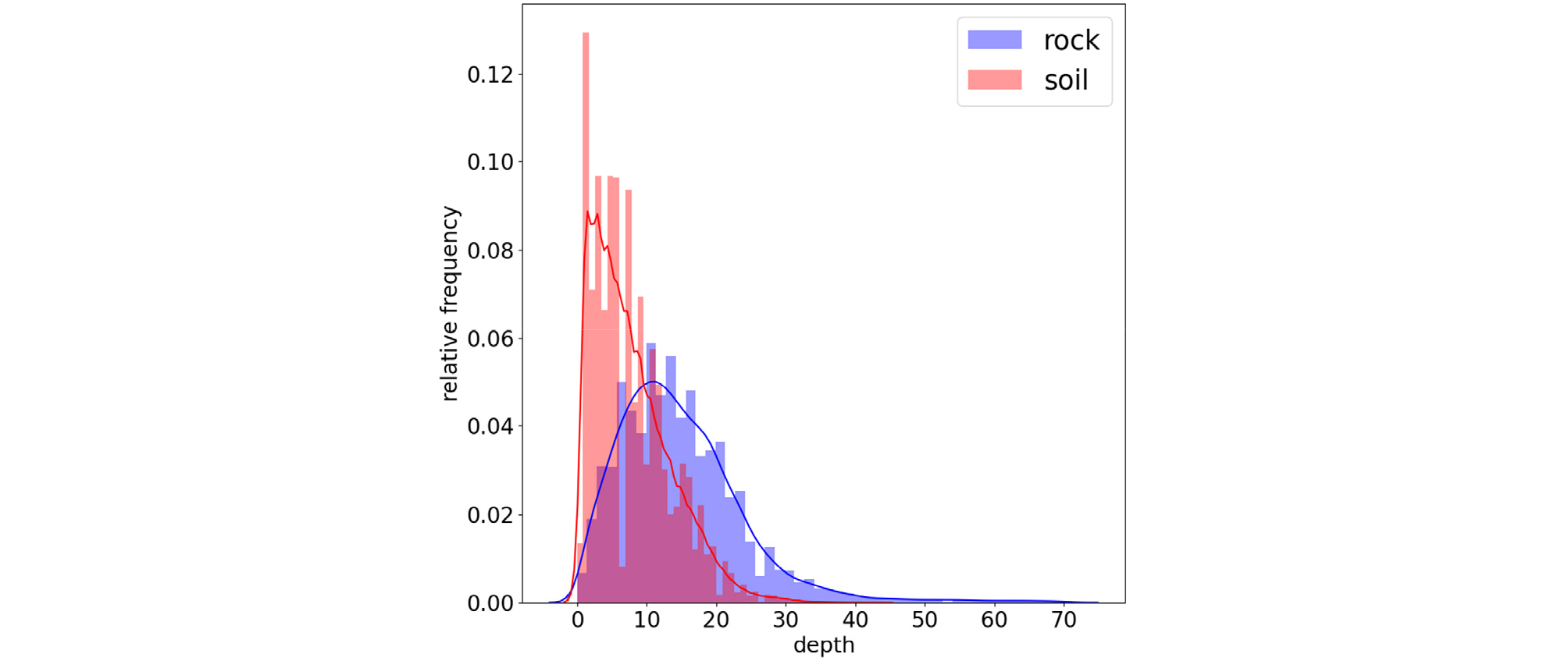
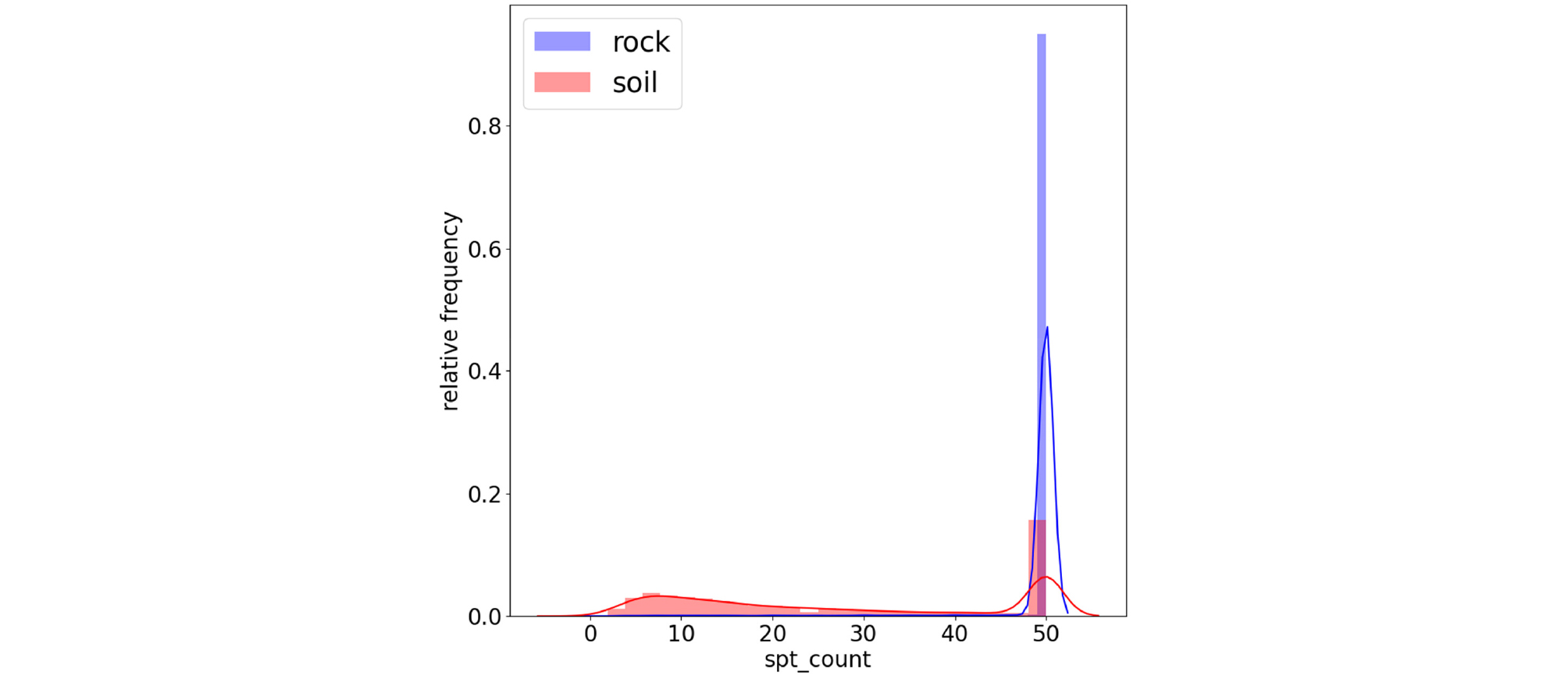
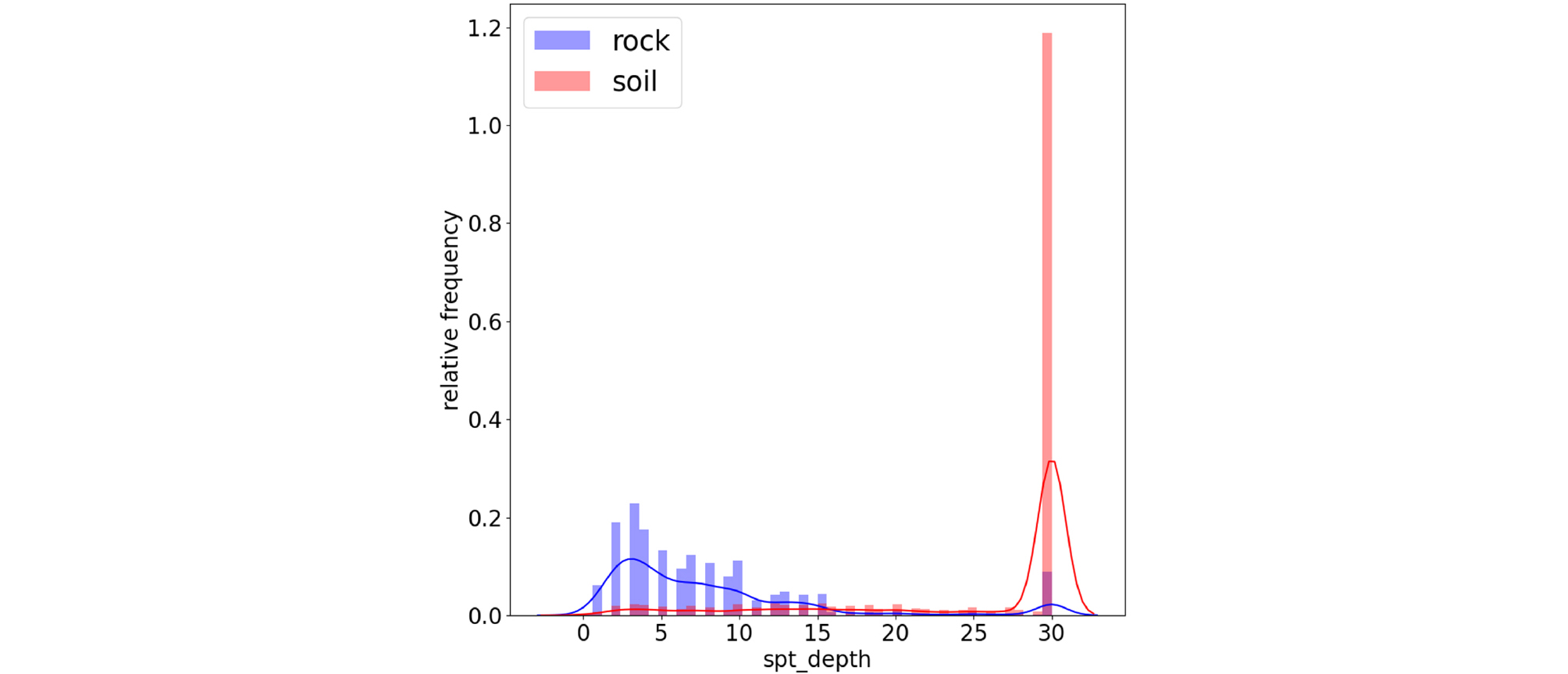
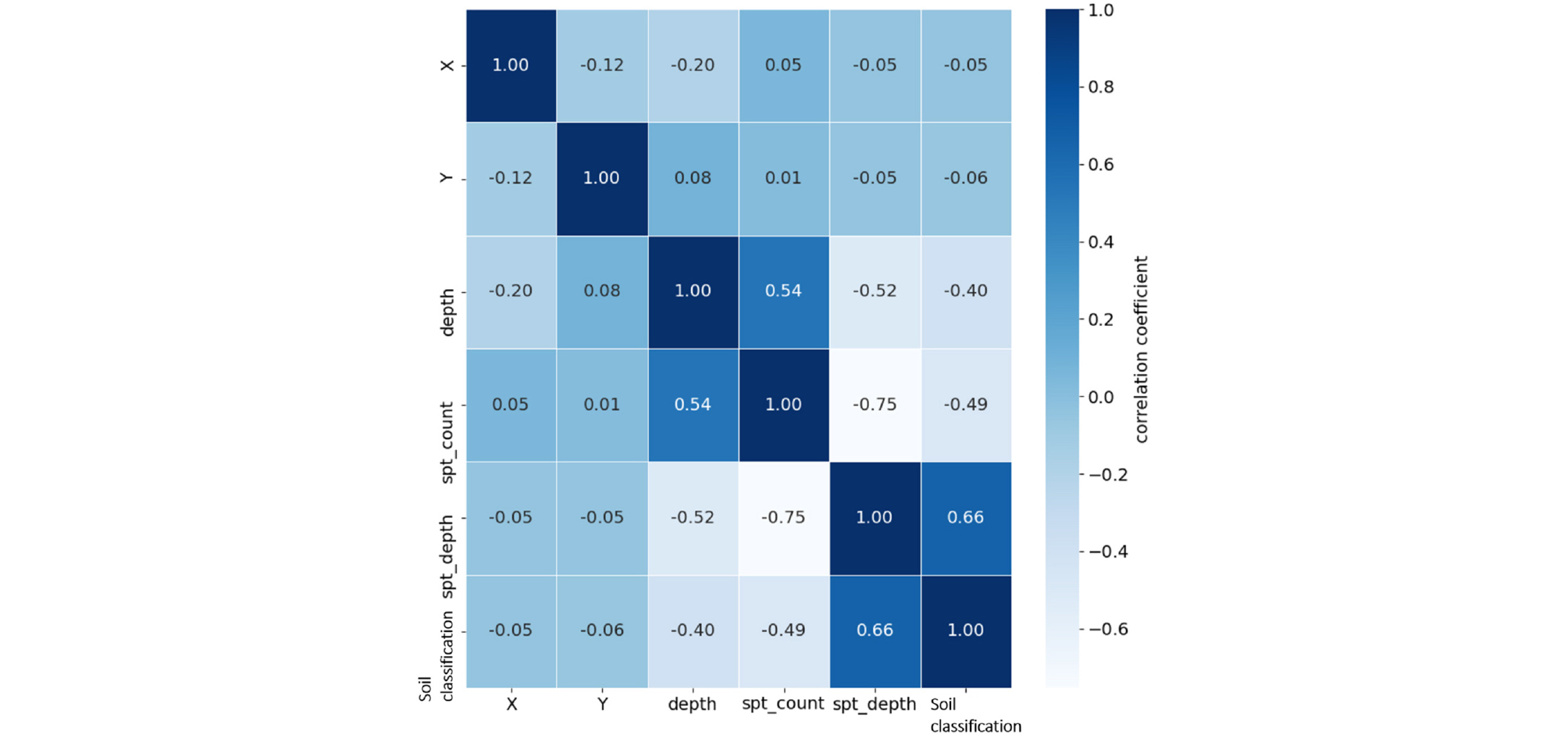
Fig. 3은 토사층과 암반층의 시험심도의 상대 도수분포이며, 빨간색은 토사층의 도수분포이고 파란색은 암반층의 도수분포를 나타낸다. Fig. 3에서 볼 수 있듯 토사층의 경우에 얕은심도에 분포하고 있으며, 암반층의 경우 토사층보다 더 깊은 심도에 분포하고 있는 것을 알 수 있다. Fig. 4는 토사층과 암반층의 표준관입시험_타격회수 상대도수분포를 나타낸 것이다. 데이터 전처리 과정에서 표준관입시험 값과 관련된 이상치를 제외하였기 때문에 데이터의 분포는 0~50 사이의 값을 갖는 것을 확인할 수 있고, 암반층의 경우 토사층의 경우보다 타격횟수가 클 뿐만 아니라 대부분의 시험값이 모두 50에 분포하고 있는 것을 알 수 있다. Fig. 5는 토사층과 암반층의 표준관입시험_관입깊이 상대도수분포를 나타낸 것이다. 토사층의 경우에는 대부분의 시험 정보가 30cm 관입했을 때 타격횟수를 나타내는 경우가 많기 때문에 값 30에 도수분포가 몰려있는 것을 확인하였고, 암반층의 경우에는 50회 타격했을 때 관입심도를 나타내는 경우가 많기 때문에 시험값이 30보다 작은 수치에 고르게 분포하는 것으로 확인했다. 데이터 간의 상관관계를 시각화하여 확인하기 위하여 Fig. 6과 같이 히트맵을 작성하였다. 그 결과 시험정보인 시험심도, 표준관입시험_타격회수, 표준관입시험_관입깊이와 지층분류(soil classification) 간의 높은 상관관계를 확인할수 었었다.
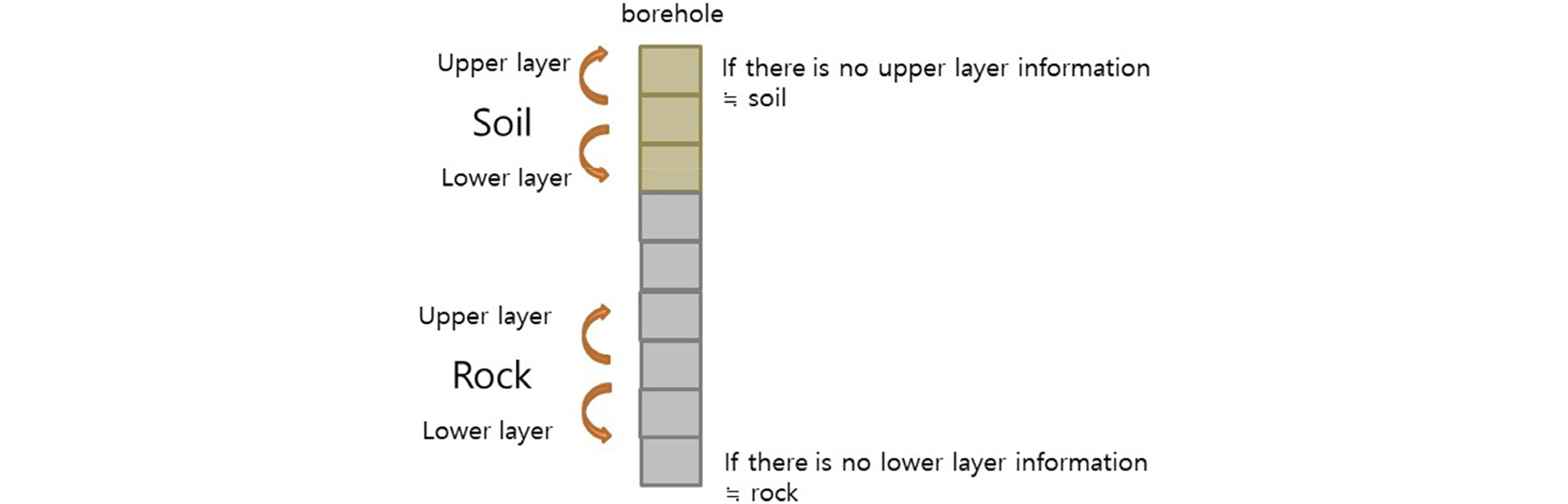
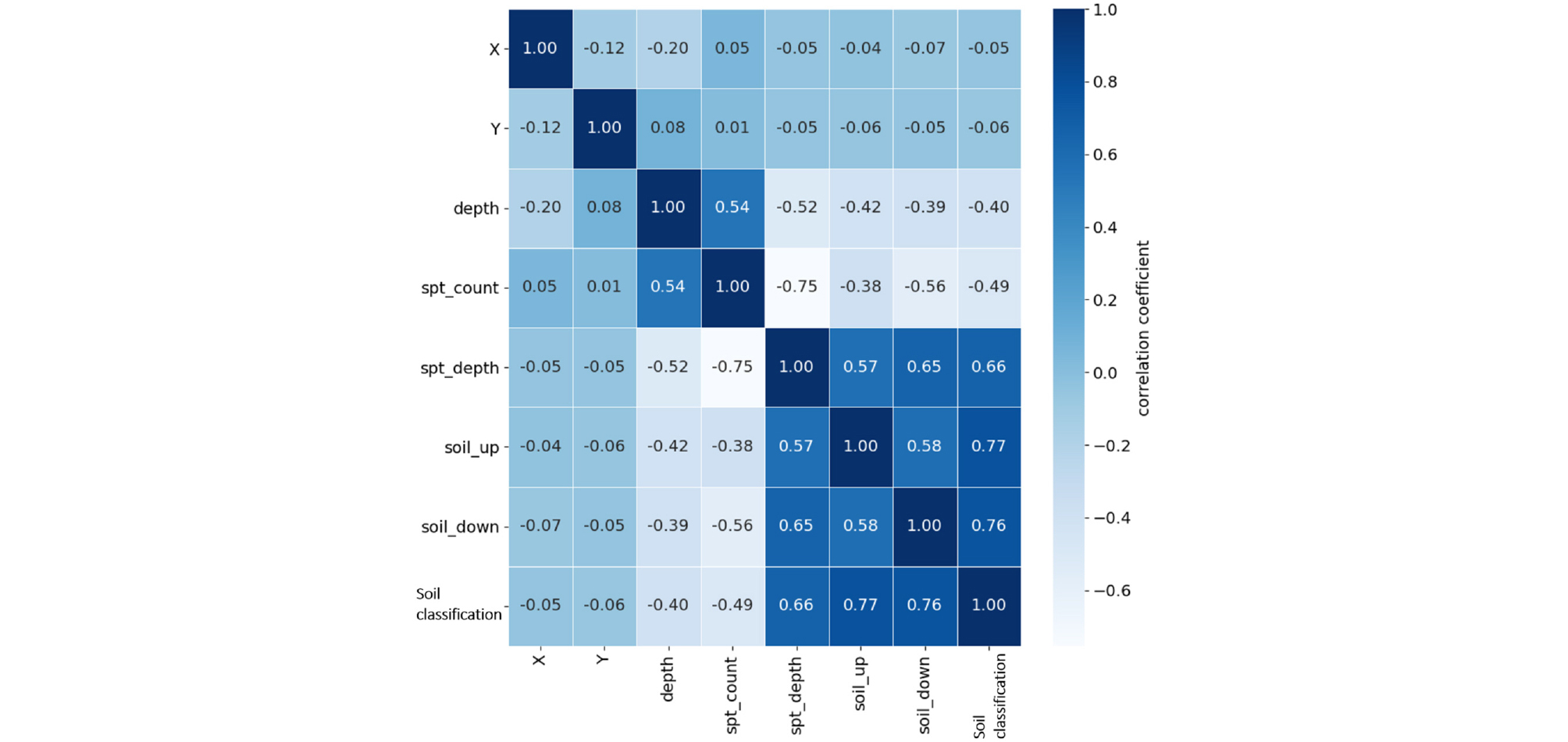
한편, 동일 좌표(x, y) 내 특정 심도의 지반이 토사층인지 암반층인지 여부는 Fig. 7과 같이 이전 심도(상부)와 이후 심도(하부)의 지층분류(soil classification)에 영향을 받는다. 특정심도의 지층분류(soil classification)는 상부 및 하부층이 토사인지 암반인지에 따라 결정될 수 있다. 상부층 및 하부층이 모두 토사층인 경우에는 해당심도를 토사로 분류할 수 있으며, 상부층 및 하부층이 모두 암반인 경우에는 암반으로 분류해볼 수 있다. 상부층만 토사층인 경우에는 암반 또는 토사 중에 분류할 수 있으며, 하부층만 암반인 경우에도 해당층을 암반 또는 토사층으로 분류할 볼 수 있다. 따라서 특정 위치의 지반이 토사인지 암반인지 여부를 예측하는데 있어서 직전 상하부의 지층정보가 토사층인지 여부의 정보를 함께 분석하였다. 단, 상부층의 정보가 없는 경우에는 최상층이라고 가정할 수 있기 때문에 상부층의 정보는 토사층으로 가정을 하고, 하부층의 정보가 없는 경우에는 하부층의 정보를 암반층으로 가정을 하였다. Fig. 8과 같이 상부층의 정보와 하부층의 변수를 추가하여 데이터 간의 상관관계를 히트맵을 작성 후 확인하였다. 그 결과 시험정보인 시험심도, 표준관입시험_타격회수, 표준관입시험_관입깊이 외 동일좌표_상부_지층종류(soil_up) 및 동일좌표_하부_지층종류(soil_down)와 같이 새롭게 생성한 변수의 경우에도 지층분류(soil classification)와의 높은 상관관계를 확인할 수 있었다.
4. AI를 이용한 지반정보 품질관리 기법
4.1 학습모델
본 연구에서는 딥러닝 기법의 일종인 완전연결 신경망 (fully connected neural network, FCNN) 모델을 사용하여 입력항목과 지층분류(soil classification) 간의 관계를 학습하였다. Biswas et al.(2020)은 완전연결신경망을 이용하여 SPT 값과 깊이 간의 상관관계에 관한 연구를 수행한 바 있다. 또한, 완전연결 신경망은 Fig. 9와 같은 구조로 각 층(layer)의 모든 뉴런이 그 다음 층(layer)의 모든 뉴런과 연결된 구조를 가지는 신경망으로서, 학습대상에 대한 사전지식 필요없이 데이터 간의 비선형적 관계를 비교적 쉽게 학습할 수 있다는 장점이 있다(Jou et al., 1994; Murino, 1998; Glorot and Bengio, 2010; Dean et al., 2012; Raiko et al., 2012).
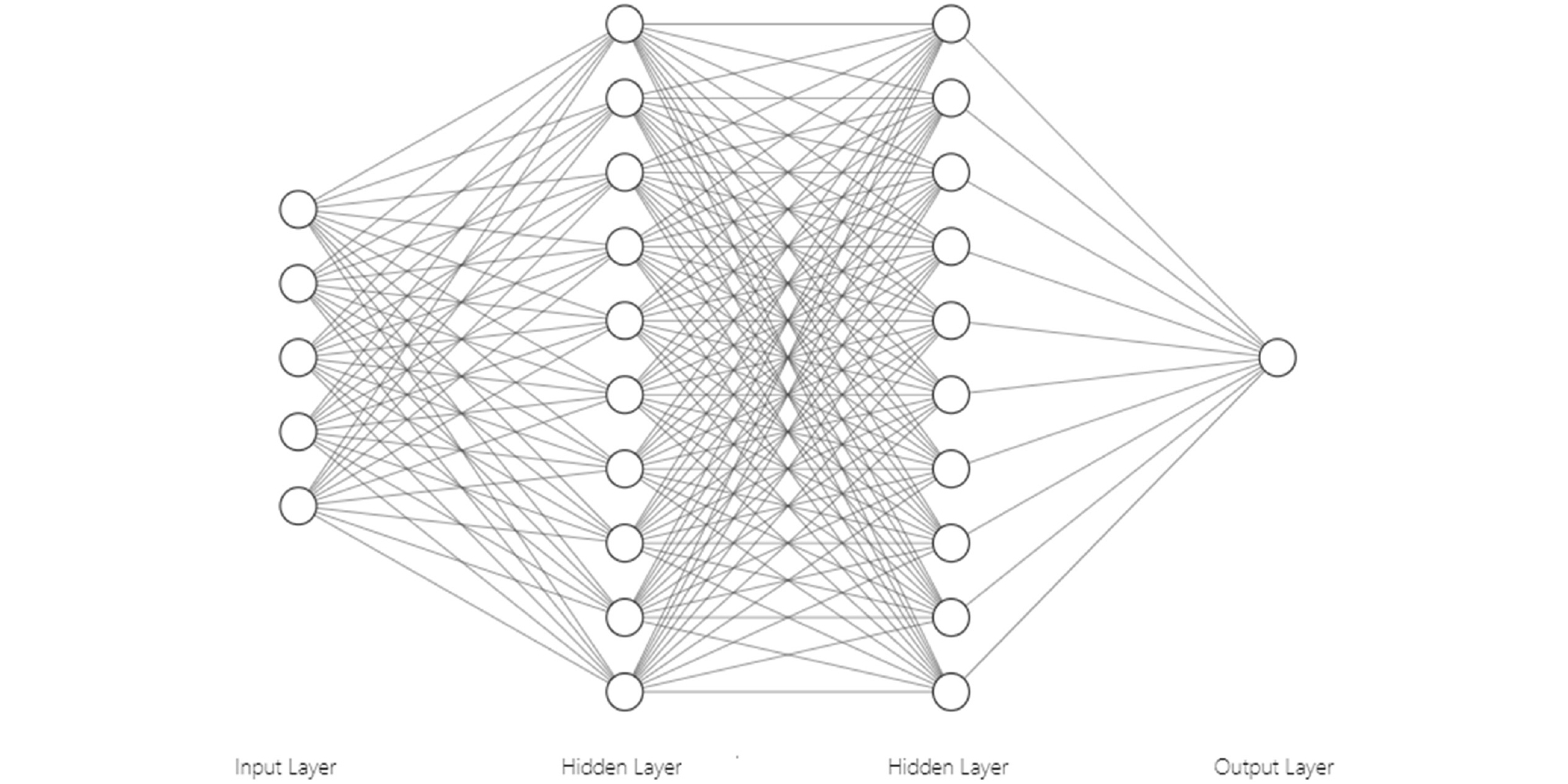
본 연구에서는 서울시 지반정보를 완전연결 신경망의 학습데이터로 사용하였으며, 전체 서울시 지반정보 데이터 총 91,198 개중 80%를 학습데이터로, 나머지 20%를 검증데이터로 사용하였다. 기본정보만 포함하여 분석(Model-1)한 결과와 새롭게 심도관련 변수를 추가하여 분석(Model -2)한 결과를 비교하였으며, 각 케이스에 대한 완전연결 신경망의 입출력 구성은 다음과 같다. Model -1에서는 ‘시험심도’, ‘표준관입시험_타격회수’, ‘표준관입시험_관입깊이’의 3개 항목을 입력값으로, ‘지층분류(soil classification)’를 출력값으로 구성하였다. Model -2에서는 ‘시험심도’, ‘표준관입시험_타격회수’, ‘표준관입시험_관입깊이’, ‘동일좌표_직전심도_지층종류’, ‘동일좌표_직후심도_지층종류’의 5개 항목을 입력값으로, ‘지층분류(soil classification)’를 출력값으로 구성하였다. 이 때 출력값은 0에서 1사이의 값을 가지는데 0.5 미만일 경우에는 암반층, 0.5 이상일 경우에는 토사층으로 판단하였다.
4.2 모델 구성 및 성능평가 지표
완전연결 신경망 모델은 은닉층 개수, 은닉층별 뉴런 개수 등의 내부 구조에 따라 예측성능이 달라지게 된다. 최적의 완전연결 신경망 모델을 찾기 위해 은닉층 수(2~7), 은닉층당 뉴런 수(30, 50, 70)를 바꿔가며 모델성능을 비교했으며, 모델의 성능지표로는 검증데이터에 대한 예측값과 실제값의 평균제곱근오차(Root mean square error)를 사용하였다. 모델성능 평가에는 전체 서울시 지반정보 데이터 중 80%에 해당하는 학습데이터를 활용했다. 그 결과, Table 1에 나타낸 바와 같이 은닉층 수 3개, 은닉층당 뉴런 수 50개로 구성된 경우 모델성능이 가장 우수한 것으로 나타나, 이를 기준으로 완전연결 신경망 모델을 구성하였다.
Table 1.
RMSE according to the combination of number of hidden layer and number of neurons per hidden layer
No. of hidden layer No. of neurons per hidden layer | 2 | 3 | 4 | 5 | 6 | 7 |
| 30 | 0.190 | 0.189 | 0.189 | 0.189 | 0.189 | 0.191 |
| 50 | 0.187 | 0.185 | 0.187 | 0.191 | 0.187 | 0.188 |
| 70 | 0.192 | 0.189 | 0.189 | 0.189 | 0.191 | 0.189 |
실제 모델 구현은 python의 PyTorch 프레임워크에서 이루어졌으며, 세부 구성으로는 Adam 최적화, Relu 활성화함수, 학습률 0.001, Epoch횟수 100, Batch 정규화가 적용되었다.
4.3 모델의 평가
앞서 언급한 바와 같이, 본 연구에서는 전체 서울시 지반정보 데이터 중 80%를 학습데이터로, 나머지 20%를 검증데이터로 사용하였다. 80%의 학습데이터로 학습시킨 완전연결 신경망 모델(은닉층 수 3개, 은닉층 당 뉴런 수 50개)을 통해 나머지 20%의 검증데이터를 예측하여, 예측 정확률(precision ratio)를 평가했다. 예측 정확률은 예측된 지층정보(토사층 혹은 암반층) 중 실제 지층정보와 일치하는 비율(%)로 산정했으며, 그 결과는 Tables 2~3과 같다. 기본정보만 포함하여 분석(Model-1)한 결과를 보더라도 토사층의 경우 암반층보다 높은 정확률로 예측하고 있었으며, 검증 데이터에 대한 예측 정확률은 87.9%로 나타났다. 새롭게 심도관련 변수를 추가하여 분석(Model-2)한 경우에 예측 정확률이 94.6%로 Model-1에 비하여 6.7% 증가한 것을 확인할 수 있었다. 두 경우 모두 토사층에 대한 예측 정확률이 암반층에 비해 높게 나타나는데, 이는 전체 데이터에서 토사층이 차지하는 비중이 상대적으로 크기 때문에 모델 학습과정에서 토사층에 대한 bias가 발생하기 때문으로 추정된다.
Table 2.
Precision ratio for verification data (Model-1)
| Soil | Rock | Total | |
| No. of prediction | 14,106 | 4,134 | 18,240 |
| No. of matches | 13,115 | 2,909 | 16,025 |
| Precision ratio | 91.0% | 76.1% | 87.9% |
Table 3.
Precision ratio for verification data (Model-2)
| Soil | Rock | Total | |
| No. of prediction | 14,106 | 4,134 | 18,240 |
| No. of matches | 13,732 | 3,517 | 17,249 |
| Precision ratio | 97.3% | 85.1% | 94.6% |
Model-2에 대한 검증데이터에 대한 오분류 비율은 5.4% 정도로, 해당 데이터들은 대다수의 나머지 데이터들과는 다른 패턴을 가진 이상치 데이터에 해당한다. 신경망 모델에서 이상치로 분류된 5.4% 정도의 데이터들만을 2차적으로 사람들이 검사함으로써, 전체 데이터를 대상으로 이상치 데이터를 검사하는 경우보다 효율적으로 이상치 데이터를 검출할 수 있을 것으로 기대된다.
본 연구에서는 히트맵 분석을 통하여 상관계수가 높은 변수를 확인하고 지반정보 품질관리 모델 개발에 사용하였다. 그러나 실제 지반의 분포는 x, y 위치정보에 영향을 받기 때문에 이를 고려한 연구가 필요하며, 반경 내 지층분류(soil classification)를 변수로 추가하여 모델을 개선하는 연구가 필요하다. 또한, 지층을 단순히 토사층과 암반으로만 분류하였다는 한계가 있어 향후 자갈, 모래, 실트, 점토, 암반으로 지층을 세분화하여 모델을 더 발전시킬 필요가 있다.
5. 요약 및 결론
본 연구에서는 인공신경망 기법을 이용하여 지반정보를 자동으로 품질관리 하는 방안에 대하여 제안하였다. 분석에는 서울시 지반정보 데이터를 사용하였으며, 데이터 전처리를 통하여 지층정보와 표준관입 시험정보를 결합하였고 이 단계에서 기존의 조건문에 의한 이상치 탐지 과정을 포함하였다. 이 후, 히트맵 분석을 통하여 상관계수가 높은 변수를 확인하고 기본정보만 포함하여 분석(Model-1)한 결과와 새롭게 심도관련 변수를 추가하여 분석(Model-2)한 결과를 비교하였다. 그 결과, 심도 관련 변수를 추가하여 분석한 결과 이상치 탐지 모델의 예측 정확률을 94.6%까지 높일 수 있었다. 이 경우 검증데이터에 대한 오분류 비율은 5.4%로 나타났으며, 이 모델로부터 이상치로 분류된 데이터만을 2차적으로 사람들이 검사함으로써 전체 데이터를 대상으로 이상치를 검사하는 경우보다 훨씬 효율적이고 정확하게 이상치 데이터를 검출할 수 있을 것으로 기대된다.
다만, 그러나 실제 지반의 분포는 x, y 위치정보에 영향을 받기 때문에 이를 고려한 연구가 필요하며, 반경 내 지층분류(soil classification)를 변수로 추가하여 모델을 개선하는 연구가 필요하다. 또한, 지층을 단순히 토사층과 암반으로만 분류하였다는 한계가 있어 향후 자갈, 모래, 실트, 점토, 암반으로 지층을 세분화하여 모델을 더 발전시킬 필요가 있다.
