

1. 서 론
2. 시추주상도 DB 입력 및 오류 처리
3. 딥러닝을 이용한 시추주상도 양식 분류
3.1 이미지 데이터준비, 학습모델 구성, 모델 학습
3.2 모델의 평가
4. 시추주상도 자동 DB화
4.1 시추주상도 자동 DB화를 위해 고려해야 할 사항
4.2 시추주상도 내 지반정보 자동 DB화
5. 요약 및 결론
1. 서 론
국토교통부에서는 지반정보를 체계적으로 관리하고 공유할 목적으로 지반조사 자료를 한데 모아 국토지반정보 포털시스템을 운영, 관리하고 있다(Fig. 1). 이는 중복 조사 방지, 그로 인한 예산절감, 그리고 지반정보의 활용성 향상 등의 다양한 효과를 가지고 있다. 최근 지반조사 결과의 활용범위는 설계, 시공, 지하안전관리, 재해재난 분야 등으로 점차 확대되고 있으며, 특히, 지반침하 및 지반함몰 등 지하안전사고 및 지진 발생 증가로 인해 지반정보의 활용이 급증하고 있는 상황이다.
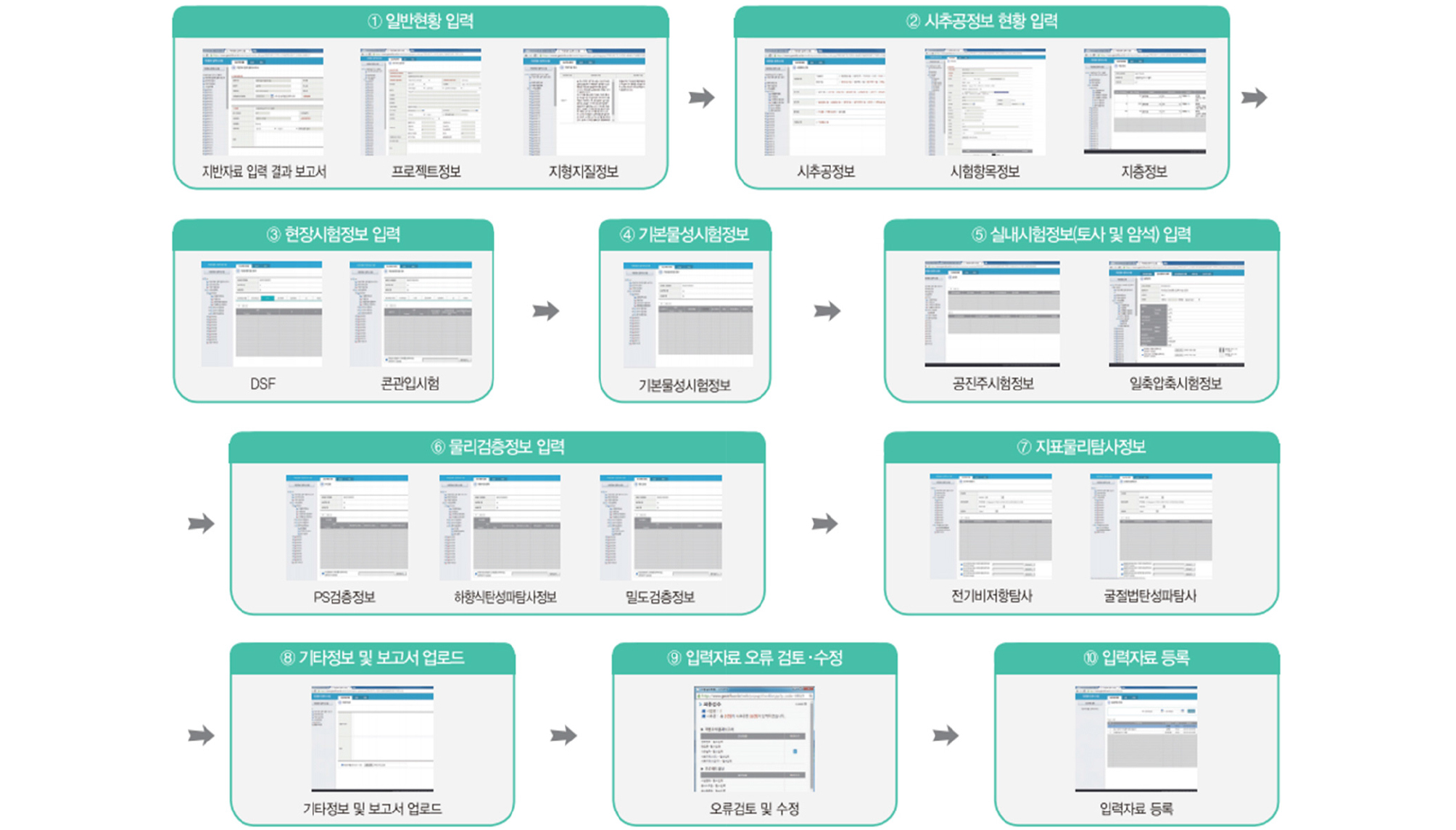
이처럼 종이문서(스캔된 문서)가 디지털 데이터베이스(DB)화 되는 것은 비단 건설분야 뿐만 아니라 정부의 데이터댐 구축사업과 같이 각 분야에서 동시다발적으로 일어나고 있는 추세이다(Yoo, 2020; Kong et al., 2020; Kim and Lee, 2020). 4차산업 혁명시대를 맞이하여 머신러닝 혹은 딥러닝 등을 이용하여 데이터를 분석하고 의미있는 결과를 도출하기 위해서는 방대한 양의 질 좋은 빅데이터를 구축하는 것이 중요하기 때문이다(Lee et al., 2020). 한편, 지반공학 분야에서는 2007년부터 지반정보가 DB화 되어 보급되기 시작하였기 때문에 상당히 오래전부터 정보가 디지털 DB화 되어 관리가 되고 활용이 되고 있음을 알 수 있다. 그럼에도 불구하고 현재 자료를 DB로 구축하는 과정은 Fig. 2와 같이 사람이 직접 PDF 파일을 보고 일일이 타이핑을 하여 진행되기 때문에 많은 인적, 시간적 자원이 소모되며, 정확도 문제가 빈번히 발생한다.
국토지반정보 포털시스템에서 제공하는 지반정보에는 프로젝트 정보, 지형지질 정보, 시추공 정보, 지층 정보, 현장시험 정보, 물성시험 정보, 토사시험 정보, 암석시험 정보, 물리탐사 정보, 지표물리탐사 정보, 전문가 의견 정보 등이 있다. 이 중에서도 시추주상도는 시추조사의 최종 성과물로서 조사 위치별로 지반 상태를 심도에 따라 기록하는 결과물로, 국토지반정보 포털시스템에 구축된 데이터베이스에서 입력 필수항목에 해당하기 때문에 데이터베이스의 대부분을 차지하며 그 결과의 활용도가 매우 높다. 특히 시추주상도에 기록되고 있는 표준관입시험은 국내에서 가장 보편적으로 활용되고 있는 현장시험 중 하나로 국내 설계기준에서는 표준관입시험을 통해 산정된 N값을 바탕으로 지반정수를 산정할 수 있는 여러 경험식을 제시하고 있고(Kang et al., 2018). 따라서, 시추주상도 내 표준관입시험 결과, 지층정보 및 지하수위 등의 지반정보가 제대로 DB화 되어야 지반정수 활용 시 결과의 신뢰도를 확보할 수 있게 된다.
본 연구에서는 현재 지반정보를 구축하는 과정에서 발생할 수 있는 사람의 입력 오류를 최소화함으로써 garbage data를 줄이고 입력 효율 및 정확도를 제고하고자 PDF 형태의 시추주상도 내 데이터를 자동으로 DB화(테이블 형태의 자료화) 하는 방안에 대해 고찰하였다. 국내에서 적용되는 시추주상도 양식은 구조물별로, 발주처에서 요구하는 형식에 따라 매우 다양하게 나타나고 있다(Lee et al., 2005). 따라서 본 연구에서는 파이썬(Python)을 이용하여 다양한 양식을 구별할 수 있도록 딥러닝 기법 중 합성곱 신경망(Convolutional Neural Network, CNN) 구조로 이미지 인식분야에서 특히 높은 성능을 보이는 ResNet 34를 적용하여 시추주상도 양식을 구별하고자 하였으며, 양식을 구별, 분리한 후에는 각 양식에 대하여 데이터를 자동으로 추출할 수 있도록 로보틱 자동 처리기법을 이용하여 PDF 내 텍스트를 자동으로 읽어 들인 후 시추주상도 내 일반정보, SPT(Standard Penetration Test) 정보 및 지층정보에 대해 데이터를 추출, 분리하여 이 값들을 기존 국토지반정보 포털시스템에서 제공하는 형태와 동일한 형태의 DB로 구축하도록 구현하였다.
2. 시추주상도 DB 입력 및 오류 처리
Fig. 3과 같이 지반조사(현장시험) 단계부터 데이터베이스 구축까지 1) 시험자체의 오류, 2) 데이터 오기로 인한 오류, 3) 국토지반정보 포털시스템에 입력할 때 발생할 수 있는 입력의 오류와 같이 총 3단계에서 오류가 발생할 수 있다. 국토지반정보 포털시스템에 현재까지 구축된 시추공 정보는 약 300,000 공 이상으로 집계되고 있다(2021년 10월 기준). 그러나 실제로 국토지반정보 포털시스템에 지반정보를 신청해서 수령하게 되면 지반조사보고서 내에 시추정보가 존재함에도 불구하고 DB에 지층정보 및 표준관입시험 결과 등이 누락된 시추공이 상당수 확인된다. 이로 인해 시추공 수와 표준관입시험 공수, 지층정보가 있는 시추공 수가 서로 불일치하게 되며, 데이터 값의 오류도 빈번하게 확인된다. 이를 해결하기 위하여 National Disaster Management Research Institute(2021)은 데이터 품질관리 기법을 제안하여 데이터 정제를 수행하거나 Park et al.(2021)은 딥러닝을 이용하여 데이터 품질관리 기법을 제안한 바 있다. 또한, Ji et al.(2021)은 결측치 보정, 정규화 등 데이터 전처리를 통해 지반정보의 신뢰도를 높인 후 MLP(Multi-Layer Perceptron) 기반으로 서울시 3차원 지반모델링에 관한 연구를 수행한 바 있다. 그러나, 데이터 정제 후 데이터의 수가 초기 데이터 수에 비하여 현저하게 적어지게 되거나, 대다수의 garbage data가 존재할 경우에는 데이터 품질관리 만으로는 데이터의 품질을 확보할 수 없게 된다(Korea Database Promotion Center, 2009). 즉, 데이터 입력단계에서 오류를 최소화할 수 있는 방안을 마련해야 한다.

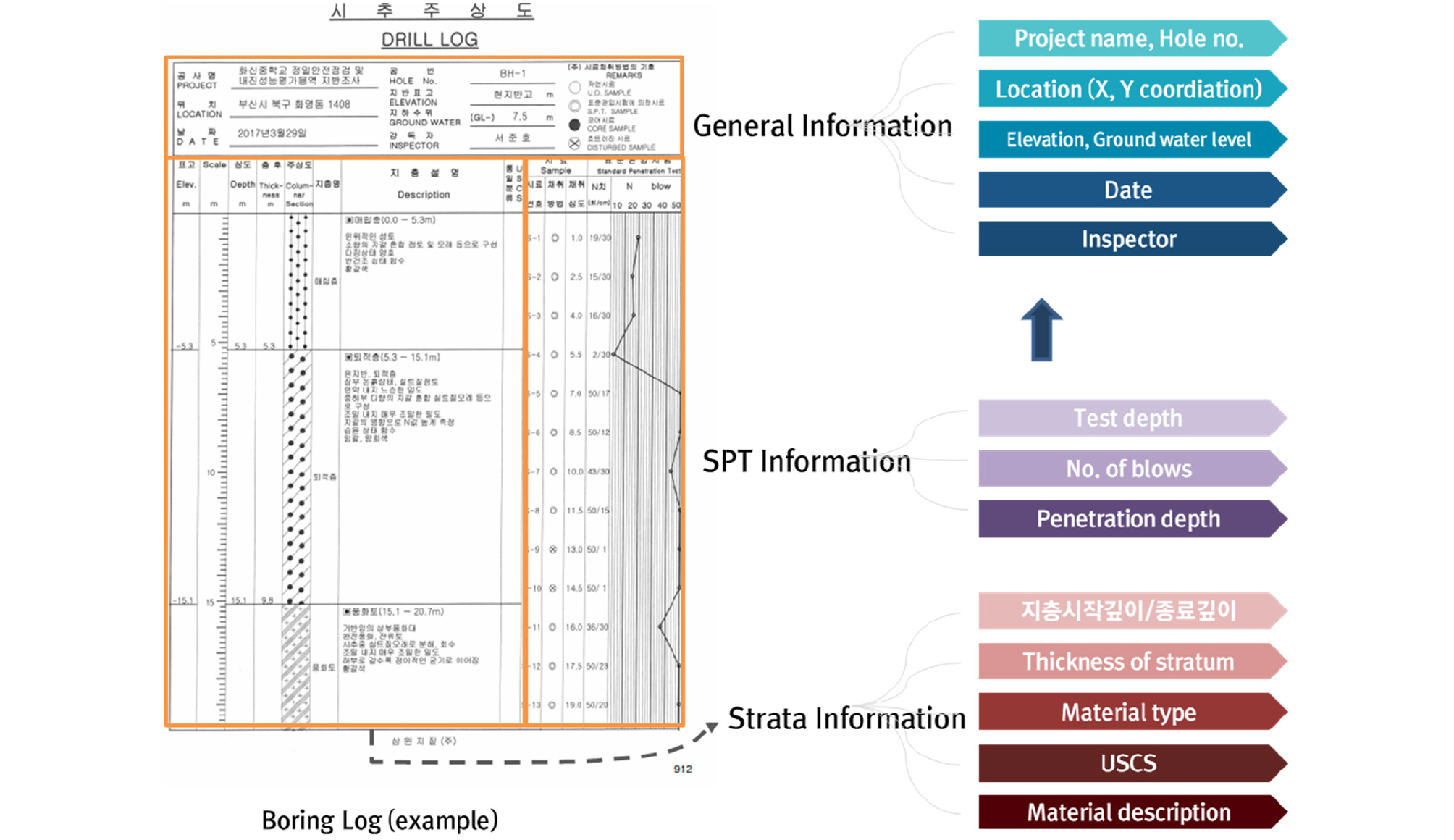
시추주상도를 자동으로 데이터베이스화 하기 위해서는 일반적인 시추주상도에 기록되는 정보를 확인해야 한다. 일반적으로 시추주상도는 Fig. 4와 같다. 대상 구조물, 발주처, 작성시기, 작성자에 따라 시추주상도의 양식은 상이하지만 담고 있는 내용은 거의 유사한데 보통 일반정보, 지층정보, 표준관입시험정보로 구성이 되어 있다. 일반적으로 시추주상도 가장 상단에 일반사항이 위치하게 되는데, 일반사항으로는 공사명, 위치(X, Y 좌표), 시추목적, 날짜, 공번, 지반표고, 지하수위, 감독자 등을 기재하도록 되어 있다. 좌측 하단에는 지층정보로 심도, 표고, 두께, 지층명, USCS(Unified Soil Classification System, 통일분류법), 지층상세설명을 기재하도록 되어있다. 지층상세설명에는 토사층의 경우 시추주상도 양식별로 어느정도 상이하나 대개는 흙의 분류, 상대밀도, 연경도 등을 표시하며 함수상태, 색조 등을 기재한다. 암반층의 경우에는 암반의 기본색, 불연속면의 간격, 암석의 풍화상태, 암석의 강도, 암석의 코어형상, 절리면 거칠기 등의 내용을 기재한다. 우측 하단에는 SPT 시험정보인 시험심도, 표준관입시험/타격회수, 표준관입시험/관입깊이 등을 기재하도록 되어 있다. 국토지반정보 포털시스템에서 관리하는 지반정보 데이터베이스에서는 이 지층정보와 표준관입시험 정보가 다시 프로젝트명, 시추공명, X, Y 좌표와 같은 시추공 일반정보와 연결되어 관리된다.
3. 딥러닝을 이용한 시추주상도 양식 분류
국내에서 유통되는 시추주상도 양식은 구조물별, 발주처 별로 상이하며, 작성시기나 업체별로 달라지기도 한다(Lee et al., 2005). 따라서, 적게는 수십개에서 많게는 수백가지의 시추주상도 양식이 존재할 것으로 추정된다. 따라서 아무리 좋은 모델로 데이터를 추출하더라도 양식이 상이하기 때문에 예외가 존재할 수 있다. 이러한 문제를 해결하기 위해서 본 연구에서는 시추주상도의 양식을 딥러닝 모델을 통해 자동으로 분류하는 방법을 제안하고자 하였다. 각각의 시추주상도 양식을 텍스트가 아닌 하나의 이미지로 인식하여 분류하는 방식으로, 합성곱 신경망을 가진 딥러닝 모델 ResNet 34를 미세조정(fine-tuning)하여 시추주상도 양식 분류를 가능하게 할 최적화된 모델을 고안하였다. 시추주상도 양식을 분류할 수 있는 딥러닝 모델을 학습하는 과정을 거쳐서 최적화시켰다. 본 장에서는 딥러닝 모델을 이용한 시추주상도 양식 분류에 대하여 상세하게 설명하고자 한다.
3.1 이미지 데이터준비, 학습모델 구성, 모델 학습
한국건설기술연구원에서 수집한 6가지 시추주상도 양식은 Fig. 5와 같고, 총 673개(A:247, B:99, C:200, D:30, E:91, F:6) PDF 형태의 컴퓨터 파일을 이용하여 연구를 하였다. 딥러닝 모델을 학습시키기 위해 우선 준비된 PDF파일들은 PDF 이미지 변환 전용 라이브러리를 통해 JPG 형태의 컴퓨터 그림파일로 변환하였다.

양식 이미지화를 통한 시추주상도 양식 분류를 위해서 합성곱 신경망 구조의 딥러닝 모델을 고안하였다. 이미지 인식분류 분야에서 특히 높은 성능을 보이는 ResNet 34 모델(He, K. et al., 2016)을 이용하였으며 그 모델 구조는 Fig. 6과 같다. 본 연구에서 사용한 모델은 단순한 합성곱 층 누적으로 이루어진 깊은 신경망의 학습 효과 저해문제를 잔차학습(Residual lerning) 방법으로 해결한 모델이다. 본 연구에서는 학습과정에 학습속도 및 성능향상 도움을 주기위해 ImageNet 백만개의 영상에 대해 사전 훈련된 버전을 미세조정을 하여 적용하였다(M. S. Hanif and M. Bilal., 2020). PyTorch(version 1.7.1)의 오픈소스 라이브러리인 torchvision의 모델을 미세조정하여 사용하였다. 합성곱 신경망 적용시 각 양식의 이미지를 높이, 너비, 색채널을 가진 3차원의 행렬의 형태 값으로 변환하였다. 얻어진 3차원 행렬 값은 네트워크 입력 전에 다시 224 × 224 사이즈로 축소하였다. 연구에 쓰인 미세조정은 다음과 같다. 학습에 쓰일 이미지 증대(augmentation)를 위해 상하좌우 반전(vertical/horizontal flipping), 회전, 이동, 이미지 크기 변화(shift, scale, rotate), 밝기 및 명암 변화(brightness, contrast), 표준화(normalization)를 이용하였다. 이미지 배치사이즈(batch size)는 36, 학습률(learning rate)는 0에서 0.0003사이의 값을 이용하여 Adam Optimizer로 30 에폭(epochs) 학습시켰다.

3.2 모델의 평가
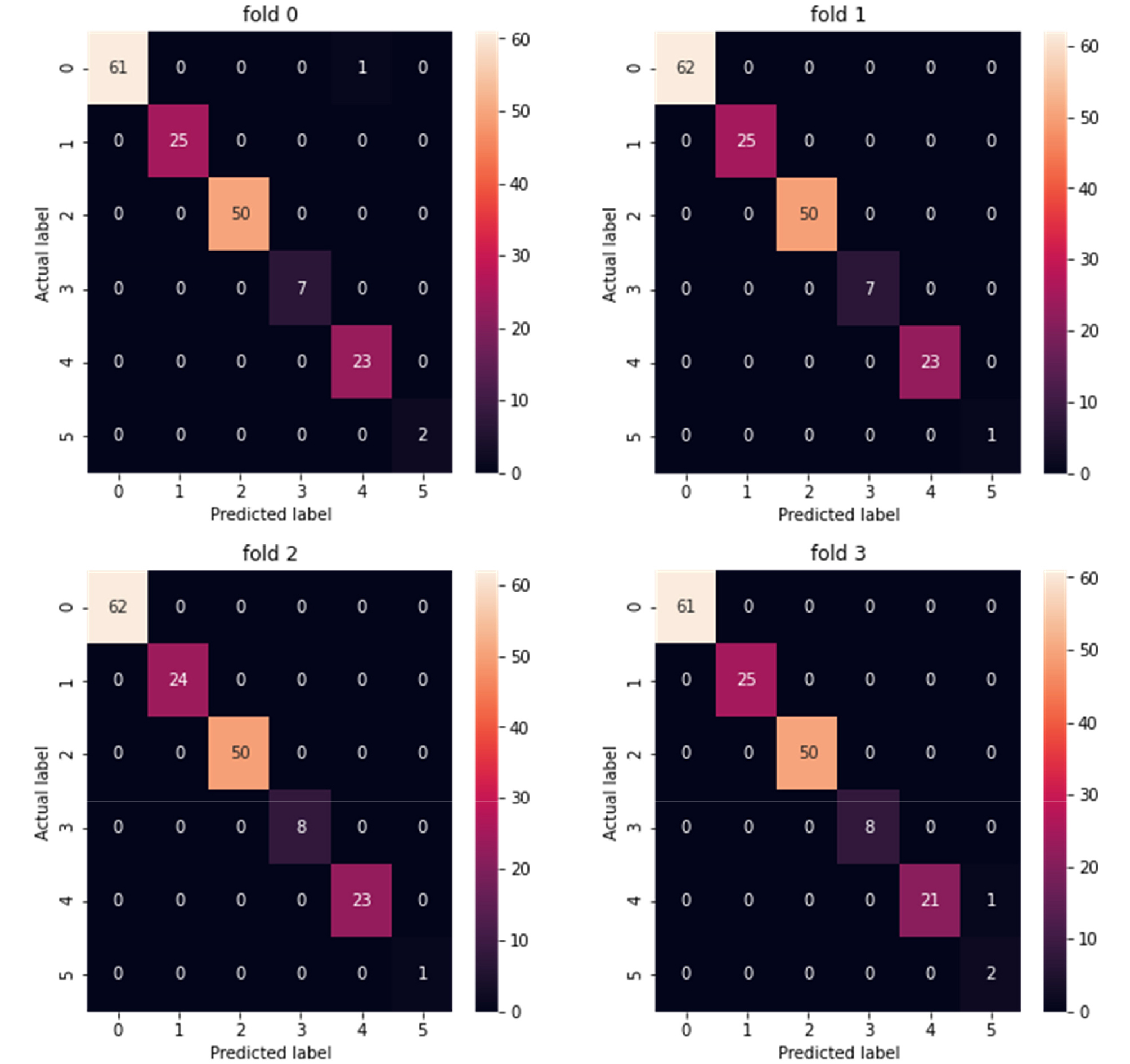
딥러닝 모델의 학습은 Fig. 7과 같이 4-fold validation(전체 이미지의 75퍼센트는 학습, 나머지 25퍼센트는 검증)방법을 이용하였다. 이 방법은 총 데이터 개수가 적은 데이터 셋에 대하여 정보 누설에 따른 모델의 일반화 성능 왜곡을 막을 수 있다는 장점이 있다. 일반적으로 분류기의 성능을 측정하기 위해 오차행렬(confusion matrix)이 사용되며, 분류기의 예측 값과 실제 값 사이의 관계를 세분화하여 성능지표를 다음 식 (1)~(4)와 같이 정의한다(M. Sokolova and G. Lapalme, 2009).

이 때, TP는 true positive의 약자로, 실제로 true이고 분류모델에서 예측이 true인 경우이며, TN는 true negative의 약자로, 실제로 true이고 분류모델에서 예측이 false인 경우이며, FP는 false positive의 약자로, 실제로 false이고 분류모델에서 예측이 true인 경우이며, FN는 false negative의 약자로, 실제로 false이고 분류모델에서 예측이 false인 경우를 의미한다.
정확도(accuracy)는 전체 샘플 중 맞게 예측한 샘플 수의 비율을 뜻하며, 높을수록 좋은 모형이다. 정밀도(precision)은 양성 클래스에 속한다고 출력한 샘플 중 실제로 양성 클래스에 속하는 샘플 수의 비율을 말한다. 재현율(recall)은 실제 양성클래스에 속한 표본 중에 양성 클래스에 속한다고 출력한 표본 수의 비율을 뜻한다. 정밀도와 재현율의 가중조화평균(weight harmonic average)을 F점수라고 하며, 이때 가중치가 1인 경우를 특별히 f1 점수라고 한다. 또한, ROC는 receiver operating characteristic의 약자로 분류기의 성능을 볼 때 사용하는 그래프이다. ROC 그래프를 해석하는 방법으로 그래프 아래의 면적을 구하는 AUC(area under curve)가 있으며, AUC 계산값이 1에 가까울수록 분류기는 좋은 성능을 낸다고 볼 수 있다. 본 연구에서는 딥러닝 모델의 성능을 평가하기 위해 정확도, 정밀도, 재현율, f1-score, AUC를 이용하였다. 그 결과, 전체 정확도는 99.7, AUC는 1.0 이었다. 정확도, 정밀도, 재현율, 정확도, f1-score 계산에 이용된 오차행렬의 결과는 Fig. 8과 같다. Table 1과 같이 각 양식별로 정밀도는 67-100, 재현율은 95-100, f1-score는 0.9-1.0 사이 값을 보였으며, 매우 높은 성능으로 시추주상도 양식을 분류하는 것을 확인하였다. 향후 이를 보완하기 위해 더 많은 자료를 통한 검증이 필요할 것으로 보인다. 다만, 양식 F의 경우 학습에 사용된 모델의 수가 매우 적었기 때문에 정밀도가 다소 낮게 평가된 것으로 보이며, 이 부분도 추후 학습에 더 많은 데이터를 이용할 경우 다른 양식과 마찬가지로 정밀도가 향상될 것으로 판단된다.
4. 시추주상도 자동 DB화
4.1 시추주상도 자동 DB화를 위해 고려해야 할 사항
종이문서(스캔된 문서)를 디지털 데이터베이스화 하기 위한 방안을 모색하기 위해 Table 2와 같은항목에 대한 검토를 진행하였다. 먼저, 종이문서 자체에 대한 검토가 필요한데 종이문서의 양식, 폰트, 특징에 대한 검토가 필요하며, 이 중에서도 어떤 내용을 추출할 것인지에 대한 고려가 필요하다. 또한, 어떤 파일 형태로 기존 문서가 보관되어 있는지를 검토해야 한다. 본 연구에서 시추주상도에 대하여 검토한 결과 양식은 매우 다양하나, 포함하고 있는 내용은 거의 유사한 것을 확인하였다. 이 문제는 3장에서 기술한 딥러닝 기반의 시추주상도 양식 구분 기술 개발로 해결하고자 하였다. 이 후, 데이터베이스화 과정에서는 어떤 포맷으로 데이터베이스화 할 것인지에 대한 결정이 필요하다. 본 연구에서는 현재 국토지반정보 포털시스템에서 제공받는 엑셀 형식으로 DB화를 진행하였으며, 향후 연구에서는 전문 DBMS(Database Management System)을 활용할 예정이다. 마지막으로 텍스트 추출방법을 결정해야 한다. 텍스트를 추출하는 방식으로 광학문자인식(Optical character recognition, OCR) 기법과 PDF 파일 읽기가 가능한 모듈을 사용하는 경우에 대하여 검토하였으며, 검토 결과 OCR 오픈소스의 경우 특히 한글에 대해 성능이 매우 떨어져서 커스터마이징이 추가로 필요함을 확인하였고(Kang et al., 2018; Sung et al., 2020), PDF 파일 읽기가 가능한 모듈을 사용한 경우 높은 인식률과 정확도를 확인하였으며, 이를 적용하였다.
Table 2.
Pre-considerations for automatic DB construction of boring log
4.2 시추주상도 내 지반정보 자동 DB화
본 연구에서 제안하는 시추주상도 자동 디지털 데이터베이스화 방안은 다음과 같다. 시추주상도 PDF 파일로부터 데이터를 자동으로 읽어들여서 DB를 생성하고 추가하는 프로그램이며, 로보틱 처리 자동화를 이용하여 이전에 존재하는 자료뿐만 아니라 새로 갱신되는 정보를 효율적으로 DB화 함으로써 시추주상도 내 일반정보, 지층정보 및 표준관입시험결과 데이터를 빠르고 정확하게 구축할 수 있도록 구현하였다. 로보틱 처리 자동화란 컴퓨터로 하는 반복적인 업무를 로봇 소프트웨어를 통해 자동화하는 기술을 의미한다(Hong, 2019). 파이썬을 이용하였으며, PDF 리딩 라이브러리를 이용해서 PDF 파일을 인식 후, 텍스트로 변환하고 원하는 값을 추출하여 DB로 구축하였다.
Fig. 9는 시추주상도 내 표준관입시험 정보 자동 DB화 흐름도를 나타낸다. 먼저 3장에서 설명한 딥러닝을 통하여 시추주상도 양식을 구별해 낸 후에 6개의 각양식에 맞게 미세조정된 알고리즘에 따라 데이터를 추출한다. PDF 파일 내 각 페이지 위쪽에 있는 일반정보인 공사명(프로젝트명), 공번(시추공명), 위치(X, Y 좌표)를 얻고, PDF 파일 내 각 페이지 우측 하단 부분에서 채취심도에 해당하는 값과 표준관입시험이라고 표기되어있는 부분의 값을 쌍을 이루어 추출해 낸다. 이 후, 이 값들을 각 항목(시험심도, 표준관입시험_타격회수, 표준관입시험_관입깊이)에 맞게 분리하는 작업을 거쳐 최종적으로 값들을 추출하여 엑셀로 변환하는 작업을 수행한다. 표준관입시험 정보 추출 결과는 Fig. 10과 같다.
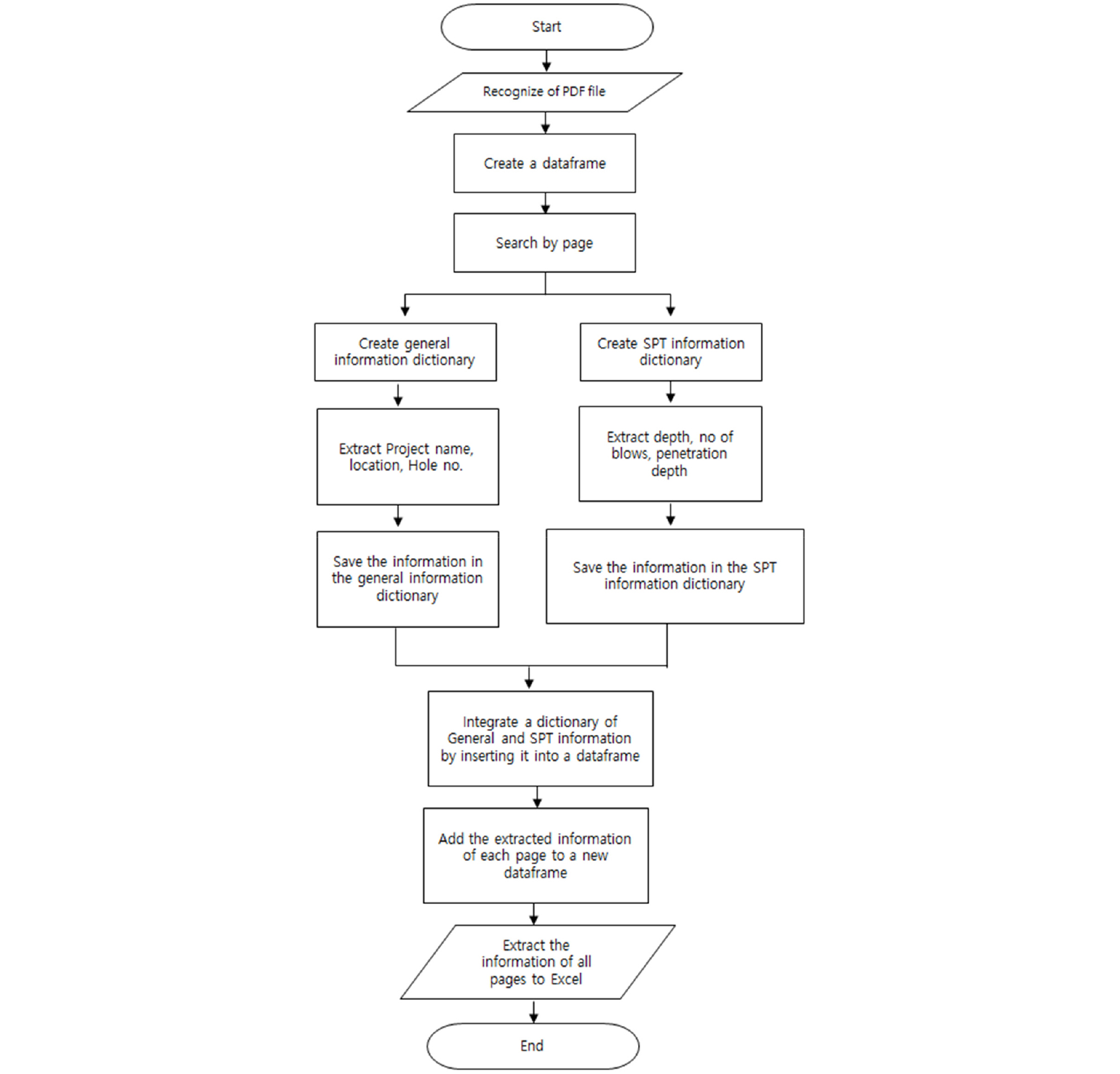
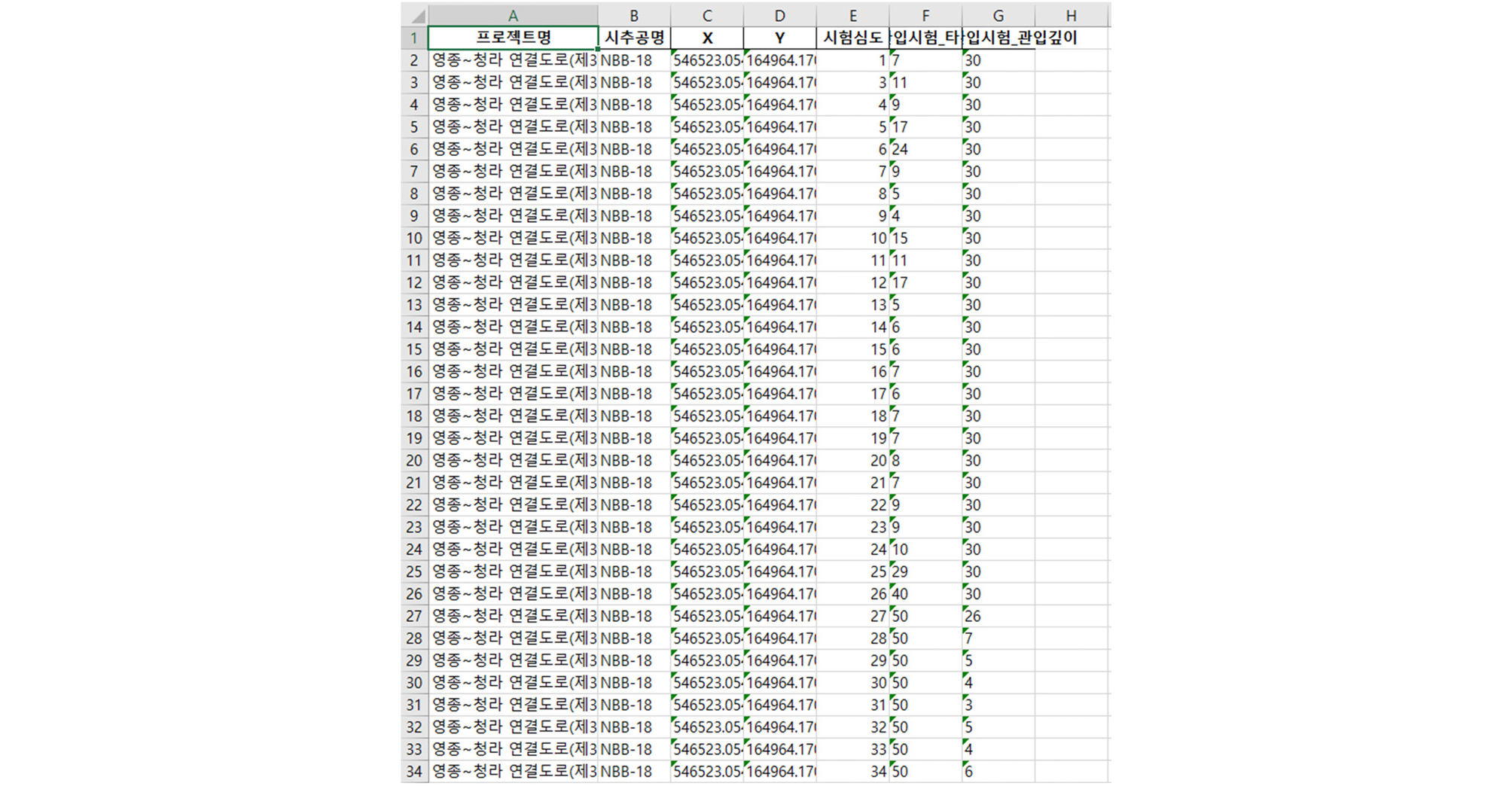
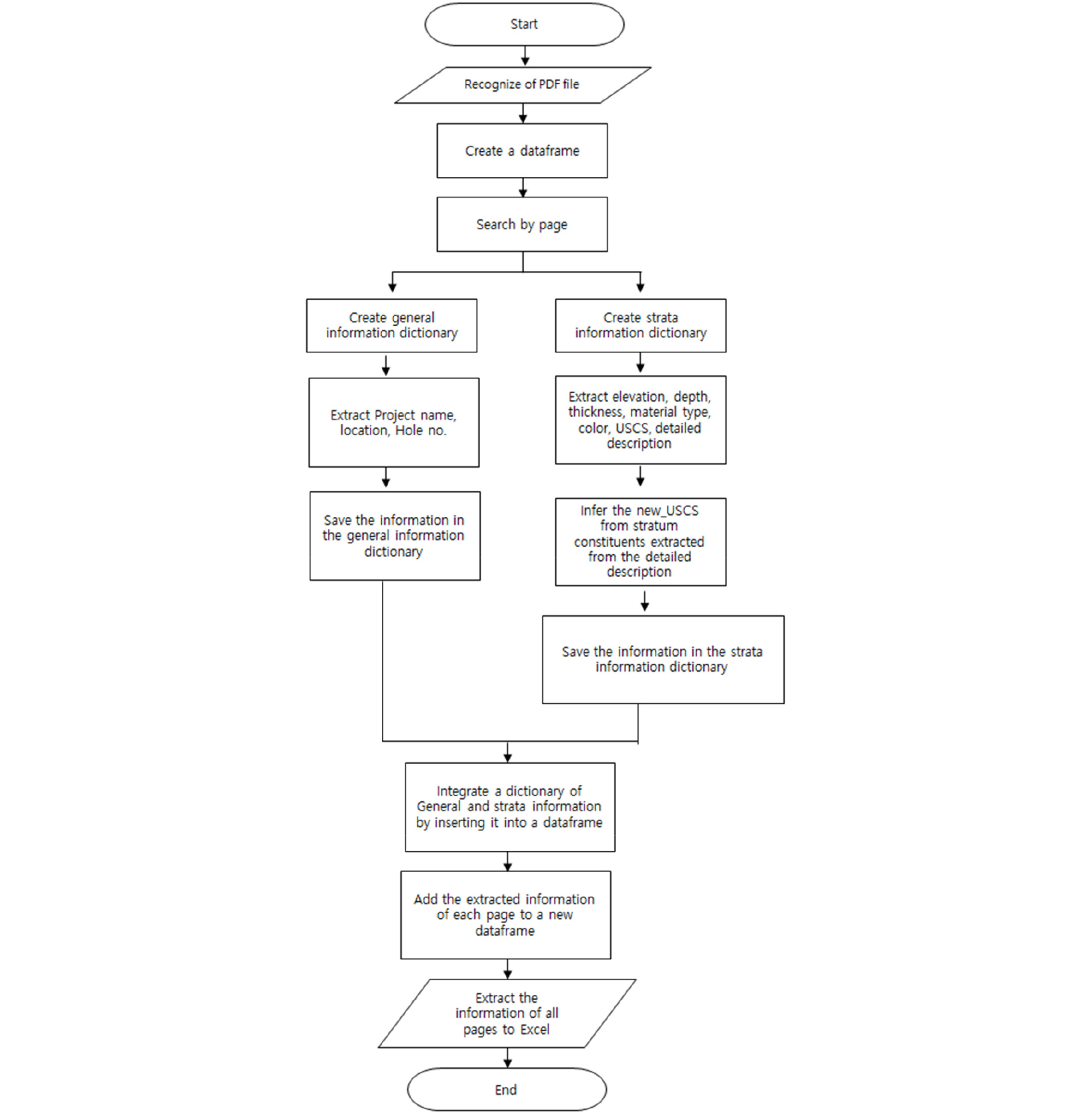
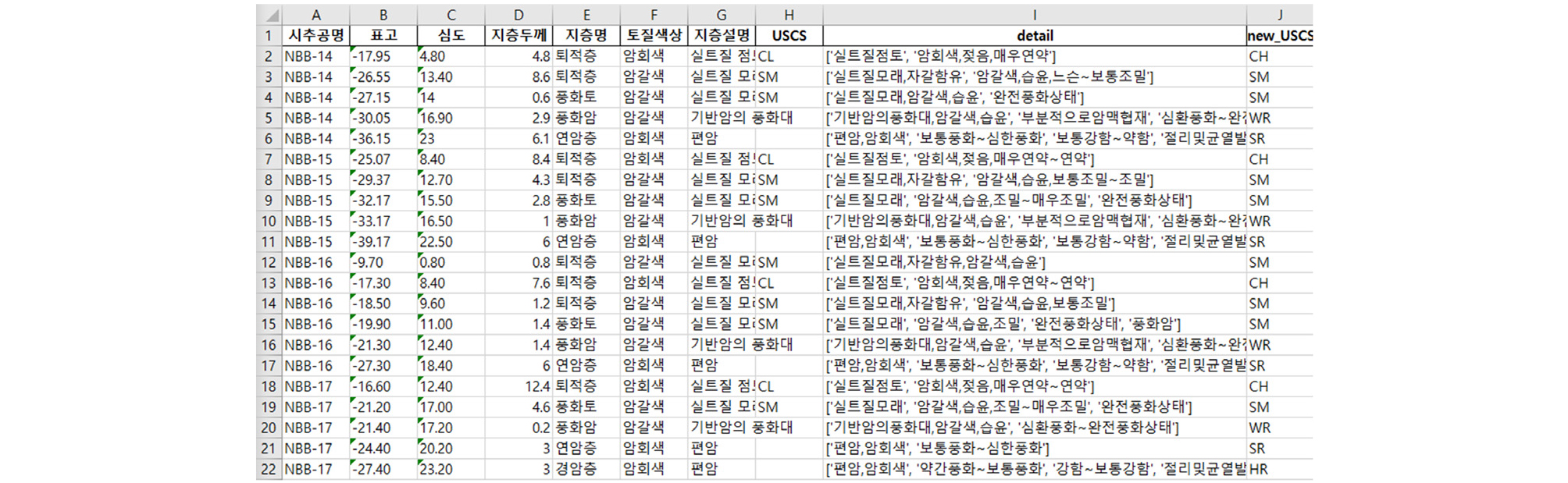
Fig. 11은 시추주상도 내 지층정보 자동 DB 화 흐름도를 나타낸다. 지층정보의 경우에는 심도, 지층두께, 지층명, 토질색상, USCS를 추출하였고, 각 항목에 맞게 분리하는 작업을 거쳤다. 시추주상도 내 지층 상세설명도 추출하여 주구성, 부구성 물질, 조밀한정도, 습윤상태 등에 관한 상세설명을 추출하였다. 한편, 지반공학적으로 통일분류법으로 흙을 분류한 결과가 매우 중요함에도 불구하고, 시추주상도 양식 별로 USCS가 기록되지 않는 경우가 상당부분 존재한다. 본 연구에서는 이 문제를 해결하기 위하여 National Disaster Management Research Institute(2021)에서 제안하는 지반정보 품질관리에 따라 지층명이 토사층에 해당하는 경우, 지층 상세설명 내 주구성 및 부구성 물질로부터 USCS를 추정하여 그 값을 추출할 수 있도록 하였다. 주구성 및 부구성 물질로부터 USCS를 추정한 경우 new_USCS로 표시하여 시추주상도 원본에 기재되어 얻어진 USCS값과 구별할 수 있도록 구현하였다. 지층정보 추출 결과는 Fig. 12와 같다. 그 결과, 기존 국토지반정보 포털시스템에서 제공하는 표준관입시험 및 지층정보 DB테이블과 동일한 형식으로 DB테이블을 구축할 수 있었다. 또한, PDF 파일 내의 모든 페이지를 검색하여 시추주상도 결과가 있는 페이지에서 초당 140페이지의 속도로 자동으로 DB화 할 수 있었다. 해석에 사용한 컴퓨터의 사양은 Intel(R) Core(TM) i5-10400F 2.90GHz CPU with 24GB RAM and NVIDIA GeForce RTX 2070 8GB GPU 이다.
5. 요약 및 결론
최근 지반조사 결과의 활용은 설계, 시공, 지하안전관리, 재해재난 분야 등으로 점차 다양하게 확대되고 있다. 현재 DB 구축방식은 사람이 직접 PDF 파일을 보고 일일이 타이핑을 하기 때문에 인적, 시간적 자원 소모가 크며, 정확도의 문제가 빈번히 발생한다. 따라서 본 연구에서는 사람의 입력 오류를 최소화하여 지반정보의 정확도를 제고하고자 PDF 형태의 시추주상도 내 지반정보를 자동으로 DB화 하는 방안에 대하여 고찰하였다. 구조물, 발주처, 작성 시기나 업체별로 상이하게 나타나는 다양한 시추주상도 양식에 대해서도 예외없이 데이터를 자동으로 데이터베이스화 하기 위해서 딥러닝 모델 ResNet 34을 이용하여 시추주상도 양식분류를 하였으며, 총 6가지 시추주상도 양식에 대해 이미지 분류를 진행하여 전체 정확도는 99.7, ROC_AUC score는 1.0의 매우 높은 성능으로 시추주상도 양식을 분리할 수 있었다. 이 후, 각각의 양식에 대하여 미세조정된 로보틱 처리 자동화 기법을 이용하여 PDF 내 텍스트를 자동으로 읽어 들인 후 시추주상도 내 일반정보, 표준관입 시험정보 및 지층정보에 대해 데이터를 추출, 분리하여 이 값들을 기존 국토지반정보 포털시스템에서 제공하는 형태와 동일한 형태의 DB로 구축하도록 구현하였다. 그 결과, 최종적으로 기존 국토지반정보 포털시스템에서 제공하는 형태와 동일한 형태로 표준관입시험 결과 값을 초당 140페이지의 속도로 자동으로 DB화 할 수 있었다. 다만, 현재는 제한된 종류와 제한된 수의 시추주상도 양식에 대해서만 딥러닝을 수행하였는데 향후 보다 다양한 시추주상도 형태에 대해서 연구를 진행한다면 정확하고 신속하게 시추주상도 내 정보를 자동으로 데이터베이스화 하여 지반정보의 활용도와 신뢰도를 크게 향상시킬 수 있을 것이다.
