

1. 서 론
2. 순환 신경망을 활용한 콘크리트궤도 침하 예측 모델
2.1 콘크리트궤도 침하 데이터베이스
2.2 침하 예측을 위한 순환 신경망 구축 및 학습
2.3 학습 전략
3. 순환 신경망을 활용한 콘크리트궤도 침하 예측
3.1 침하 예측 성능 평가
4. 결론 및 요약
1. 서 론
콘크리트궤도는 부담력 및 저항력이 자갈도상 궤도에 비하여 매우 크기 때문에 궤도틀림(Track Irregularity)이 거의 발생되지 않아 궤도 보수 비용을 대폭 절감시킬 수 있는 궤도 구조이다. 또한, 콘크리트궤도 적용 시, 선로의 양호한 선형을 지속적으로 유지할 수 있어 고속 및 고밀도의 운행선로에서의 차량 주행안정성이 높고 이용승객에게 좋은 승차감을 제공할 수 있으며 생애주기비용(Life-Cycle Cost, LCC) 측면에서 유리한 것으로 평가되고 있다. 국내에서는 터널구간을 중심으로 한 강성노반에서 콘크리트궤도를 부설한 실적은 많았지만, 토공구간에서는 노반 침하에 따른 문제점 발생에 대한 우려로 콘크리트궤도의 부설 실적이 미미하였다. 하지만, 고속선에서 궤도틀림 및 자갈비산 등 자갈도상 궤도에 대한 문제점이 부각되어 콘크리트궤도 부설이 적극 검토되었으며 경부고속철도 2단계 구간(대구∼부산)과 호남고속철도 1단계 구간(오송∼광주)을 콘크리트궤도로 부설하였다.
한편, 최근 고속철도 이용객 증가로 최근 철도 운행의 안정성 문제가 크게 대두되고 있으며, 철도운행의 안정성 문제는 국부적인 궤도틀림, 침목균열, 노반침하 등으로 인해 유발된다. 그중 노반침하의 경우, 콘크리트궤도부설 완료 후 열차 하중에 의한 압축 침하량을 5mm 이하, 노반의 허용 잔류 침하량을 25mm 이하로 규정하고 있으며(Korea Rail Network Authority, 2013), 이러한 설계기준을 만족하기 위해 토공 구간에 대해서 침하량을 엄격하게 평가하고 있다. 하지만, OO고속철도 토공 구간의 노반 침하로 기인된 콘크리트궤도의 2차적 침하가 발생하는 사례가 빈번히 발생하고 있으며, 일부 구간에서는 허용 설계기준 이상의 침하가 발생한 것으로 확인되었다.
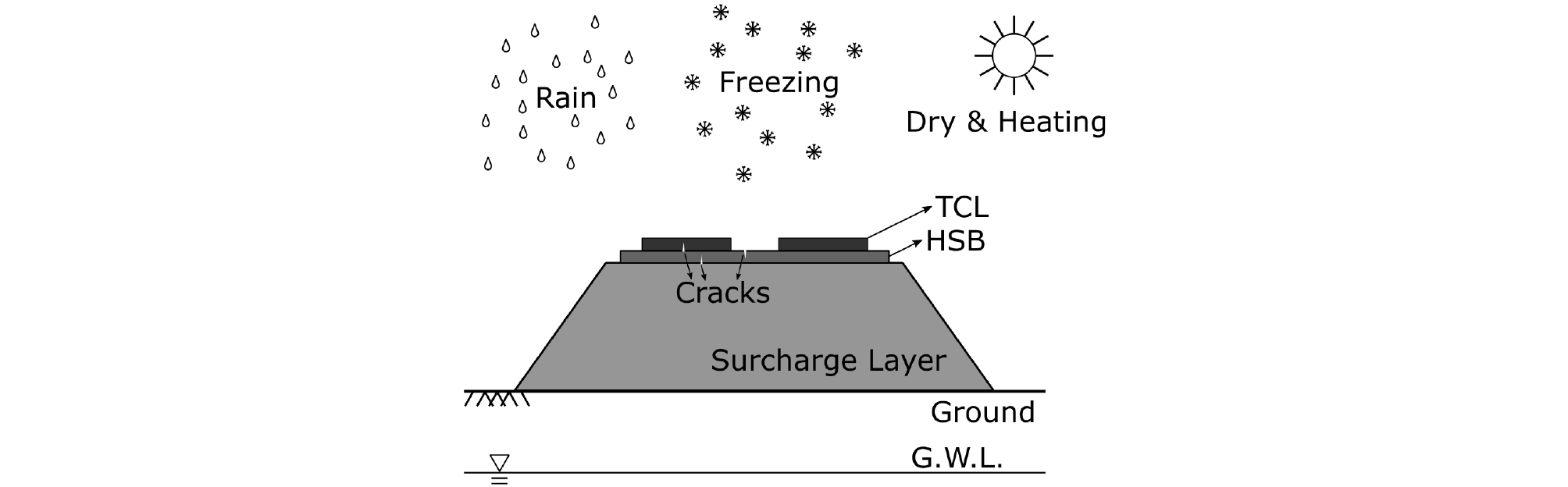
콘크리트궤도의 변형 및 침하를 산정하기 위해, 해석적(혹은 연역적) 방법을 적용할 경우, 궤도의 변형 및 침하에 영향을 주는 인자를 분석하고, 재료, 구조, 토질 역학의 작용 원리를 정확하게 파악하여야 한다. 구조적 관점으로 볼 때, Fig. 1과 같이 하나의 콘크리트궤도는 원지반, 성토체, 기초콘크리트(HSB, Hydraulically Stabilized Base), 궤도콘크리트(TCL, Track Concrete Layer) 등 다양한 부재로 구성되며, 각 부재의 강성, 시공법, 재료 및 시공의 품질은 콘크리트궤도의 변형 및 침하에 영향을 끼치게 된다. 또한, Fig. 1에서 보이듯, 강우에 따른 침투, 지하수위의 변화, 온도 변화에 따른 수축 및 팽창 등 외부 환경적 요인도 콘크리트궤도의 침하 거동에 영향을 끼친다. 따라서, 다양한 재료, 시공 및 환경적 요인들이 복잡한 물리적 법칙에 따라 작용하여 발생하는 콘크리트궤도의 침하를 해석적(혹은 연역적) 방법론을 기반으로 정확하게 산정하는 것은 쉽지 않다. 또한, 토공 노반에서 침하 발생 요인은 성토체 다짐불량, 배수불량, 접속부 처리 미흡 등으로 인한 성토체 침하와 지반 개량 불량, 지하수위 변동 등으로 인한 원지반 침하 등을 생각할 수 있으나, 이들의 인과관계는 아직 명확하지 않다(Tzanakakis, 2013; Soeung et al., 2018).
따라서, 현재 콘크리트 노반의 향후 침하를 예측 및 평가하기 위해 침하 계측 데이터를 이용한 귀납적 방법을 활발하게 적용하고 있으며, 이를 바탕으로 궤도의 유지보수 방안을 결정하고 있다. 노반의 침하는 발생 위치에 따라 매우 다양한 형태로 나타나 일률적인 기준을 적용하기 어려우나, 일반적으로 침하계측자료와 궤도틀림자료를 바탕으로 침하개소를 판별하고, 선정된 침하개소에 대해 정밀한 계측 및 침하예측을 수행하여 향후 유지보수 방안을 결정한다. 현재 콘크리트 노반의 침하를 예측하기 위해서는 쌍곡선법(Tan et al., 1991), 아사오카법(Asaoka, 1978) 등을 사용하고 있다. 하지만, 상기 침하 예측 방법은 두꺼운 점성토 연약지반의 시간에 따른 압밀 침하량을 예측하기 위해 개발되었으며, 입자 재배열 등에 의한 크리프 거동에 의해 주로 발생하는 궤도 노반의 잔류 침하에 대한 이들 방법의 예측 성능엔 의문점이 있다.
따라서, 본 연구에서는 귀납적 방법의 일종인 인공지능 기법을 활용하여 콘크리트궤도의 잔류침하량을 평가하였다. 여러 인공지능 기법 중, 시간에 따른 침하 곡선과 같은 시계열 데이터를 활용한 예측 모델에 널리 활용되고 있는 순환신경망(Recurrent Neural Network, RNN, Rumelhart et al., 1986)을 사용하였으며, OO고속선 침하개소의 정밀 침하계측 자료를 순환신경망의 입력층으로 활용하였다. 예측된 잔류침하량을 현재 가장 널리 사용되는 침하예측 방법인 쌍곡선법과의 비교를 통해 개발된 모델의 예측 안정성과 정확도를 평가하였다.
2. 순환 신경망을 활용한 콘크리트궤도 침하 예측 모델
2.1 콘크리트궤도 침하 데이터베이스
본 연구에서는 2015년 3월부터 2018년 6월까지 상용 운행 개시 후 궤도 유지관리단계에서 OO고속선 상선을 따라 측정된 침하 데이터를 활용하였다. 이 기간 동안, 한국철도공사에서는 선로를 따라 매 5∼10m 마다 그리고 매 2∼3개월마다 궤도콘크리트 중앙에 침하핀을 설치하고 레벨 측량을 통해 침하를 측정하였다. 인공지능의 학습을 위해 본 연구에서는 1개월 단위로 침하 데이터를 구축하였으며, 침하 데이터가 없는 월에는 선형보간을 통해 침하 데이터를 구축하였다. 한국철도공사에서는 개통 이전에 발생한 침하를 기준으로 궤도 노반을 관심, 주의, 경계, 하자의 네 단계로 구분하여, 유지보수단계에서의 침하 관리를 수행하였다. 관심, 주의, 경계 단계로 구분된 구간에서는 년 3회 이하로 궤도의 침하를 측정하여 순환신경망을 적용할 만큼 데이터가 충분하지 않았다. 또한, 개통 이전 침하 자체가 작고 침하가 수렴하는 경향을 보여 노반 허용 잔류 침하량을 초과하는 침하가 발생하지 않을 것으로 판단하였다. 이에 따라, 하자 구간에서 측정된 침하 데이터 중 최종 측정일(2018년 6월)에 침하량을 기준으로 큰 순서대로 200개 지점을 선별하였으며, 이중 무작위로 6개 지점을 선정하여 본 연구에 활용하였다. Table 1은 본 연구에서 인공지능을 활용하여 침하예측을 수행하기 위해 선정된 6개 지점의 위치, 적용된 원지반 개량 공법, 원지반 상부 10m의 평균 N값, 그리고 성토고를 보여준다.
Table 1. Properties of selected locations for the settlement prediction using RNN in this study
| Milepost | Ground improvement | Avg. N | Embankment height (m) |
| A | - | 10.7 | 10.1 |
| B | Replacement with PET Mat | 10.4 | 19.1 |
| C | - | 11.5 | 7.9 |
| D | Replacement | 9.3 | 14.1 |
| E | - | 15 | 8.6 |
| F | Preloading | 11.2 | 8.1 |
2.2 침하 예측을 위한 순환 신경망 구축 및 학습
본 연구는 귀납적 방법인 순환신경망 기법을 기반으로 침하 거동을 분석하고자 한다. 귀납적 방법은 어떤 현상(침하)의 원인(재료 및 환경적 요인)에 집중하기 보다는 결과(침하 데이터)를 분석하여 현상을 예측한다. 현재 자연과학 및 공학 분야에서 가장 활발히 연구되며, 적용되고 있는 머신 러닝 및 인공지능 기법은 대표적인 귀납적 방법이라 할 수 있다. 머신 러닝 기법은 현재 토목 공학 분야에서 이미지 분석(Cha et al., 2017), 콘크리트 강도 예측(Chou et al., 2014) 등 다양한 분야에서 적용되고 있다. 다양한 머신 러닝 기법 중 시간에 따른 침하 데이터와 같은 시계열 자료의 분석에는 일반적으로 Rumelhart et al.(1986)이 제안한 순환신경망(Recurrent Neural Network) 기법이 적용되며, 본 연구에서도 콘크리트궤도의 침하량 예측을 위해 순환신경망을 사용하였다.
Fig. 2는 총 n개의 침하량을 순차적인 침하량을 이용하여, n+1 단계에서의 침하량을 산정하는 순환신경망을 도식화하여 보여준다. Fig. 2에서 S1, S2, S3, …, Sn은 입력층을 구성하는 각 단계별 침하량이며, h은 은닉 벡터를 나타내며, S*n+1은 n+1 단계에 대해 예측한 침하량을 나타낸다. 그리고 U, W 그리고 V는 각각 입력, 은닉, 그리고 출력층을 위한 가중치 행렬이다. 머신 러닝에서 가중치 행렬은 꼭 정방행렬일 필요는 없다. Fig. 2와 같이 본 연구에서 적용한 순환신경망에서는 하나의 출력값 S*n+1를 산정하기 위해서 n개의 입력값(S1, S2, …, Sn)과 n+1개의 은닉 벡터(h0, h1, h2, …, hn)를 사용한다. 각각의 은닉 벡터 ht는 다음식으로부터 산정이 된다.

| $${\mathbf h}_t=f_h\left({\mathbf{Wh}}_{t-1}+s_t\mathbf U\right)$$ | (1) |
식 (1)과 같이 단계 t에서의 은닉벡터 ht는 이전 단계 t-1에서의 은닉벡터 ht−1과 가중치 행렬 W의 곱 Wht−1와 단계 t에서의 입력값 St와 가중치 행렬 U와의 곱 StU을 합한 후, 이를 활성화 함수 fh에 대입하여 산정한다. Fig. 2에서 출력값 S*n+1는 다음식과 같이 마지막 은닉벡터 hn과 가중치 행렬 V의 곱을 활성화 함수 fy에 대입하여 산정한다.
| $$S_{n+1}^\ast=f_y\left({\mathbf{Vh}}_n\right)$$ | (2) |
따라서, 출력값 S*n+1 산정에는 처음부터 현재단계까지의 입력 벡터와 은닉 벡터 모두가 재귀적으로 영향을 주게 된다. 식 (1)와 (2)에서 활성화 함수 fh와 fy로는 일반적으로 tanh 및 softmax 함수 등이 사용된다.
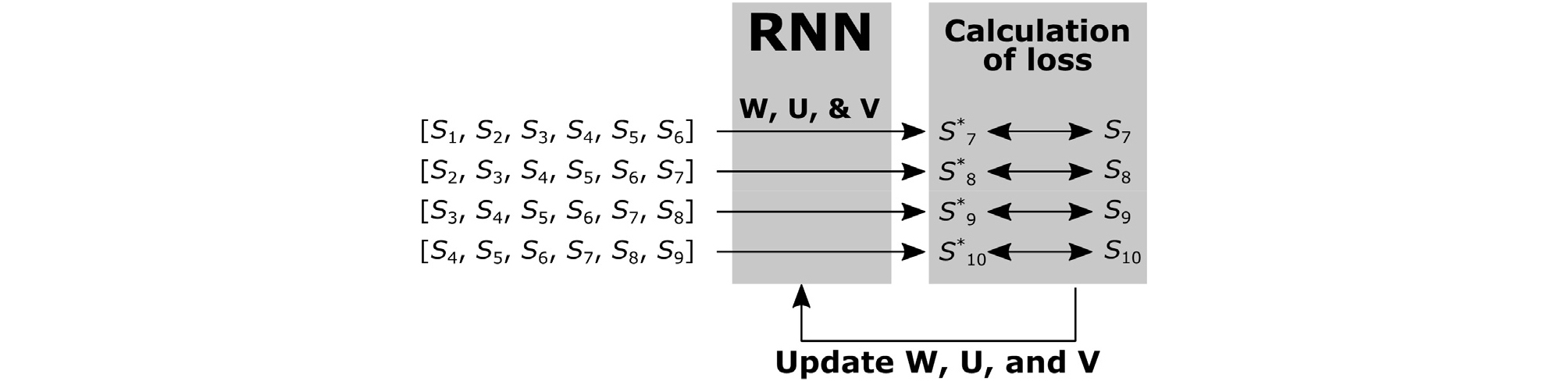
순환 신경망을 사용하기 위해서는 먼저 기존의 데이터를 활용하여 신경망을 학습시켜야 하며, 본 연구에서 이는 단계 n+1에서의 S1∼Sn을 이용하여 산정한 예측값 S*n+1과 실측값 Sn+1의 차이를 최소화하는 가중치 행렬 W, U, 및 V를 결정하는 과정이라 할 수 있다. Fig. 3은 본 연구에서 적용된 학습 과정을 나타낸다. Fig. 3에서 총 침하 데이터는 S1∼S10의 10개가 있으며, 하나의 예측을 위해서는 총 6개의 데이터를 사용한다. 일반적으로 인공지능을 위한 데이터셋은 입력층과 출력값(혹은 레이블 값)으로 구성이 되며, 주어진 10개의 데이터로부터 총 4개의 학습 데이터셋을 Fig. 3과 같이 구성할 수 있다. 침하 데이터 S1∼S6을 입력층으로 하여 순환 신경망에서 현재 설정된 가중치 행렬 W, U, V를 이용하여 예측값 S*7을 산정할 수 있다. 동일한 과정을 각 학습 데이터셋에 적용하여 예측값 S*8, S*9, S*10을 산정할 수 있다. 그 후, 순환신경망을 이용한 예측값 S*7∼S*10와 실제 측정값 S7∼S10를 비교하여 손실률을 산정하며, 이 손실률을 감소시키도록, 가중치 행렬 W, U, V를 갱신한다. 상기 과정을 손실률이 충분히 감소할 때까지 반복하여, 최적화된 W, U, V을 산정하여 추후 침하 예측에 활용한다. Fig. 4는 구축된 순환신경망을 활용한 침하예측을 도식화하여 보여준다. 먼저, 학습을 통해 산정된 가중치 행렬 W, U, V를 활용하여, 마지막 출력 데이터 셋 [S5, S6, S7, S8, S9, S10]을 순환신경망에 입력하여 예측 침하량 S*11을 산정할 수 있다. 그 후, 예측 침하량 S*11을 입력값으로 활용하여 데이터 셋 [S6, S7, S8, S9, S10, S*11]을 구축하고 이를 순환신경망에 입력하여, 예측 침하량 S*12을 산정한다. 위 과정과 같이, 산정된 예측값을 다시 입력값으로 활용하여 순환 신경망에서는 미래의 예측 침하량을 계속적으로 산정할 수 있다. 현재까지 Rumelhart et al.(1986)이 제안한 순환신경망(RNN) 이외에 이를 발전시킨, LSTM(Long Short-Term Memory, Hochreiter and Schmidhuber, 1997), GRU(Gated Recurrent Units, Cho et al., 2014) 등의 기법이 있으며, 본 연구에서는 LSTM을 활용하여 콘크리트궤도의 장기 침하 예측 모델을 개발하였다. 침하예측을 위한 순환신경망 프로그램의 구현을 위해서 본 연구에서는 파이썬과 오픈 소스 신경망 라이브러리인 케라스를 이용하였다.

2.3 학습 전략
콘크리트궤도의 침하는 여러 지점에서 각각 측정되며, 본 연구에서는 하나가 아닌 다수의 시계열 데이터를 다룬다. 이렇게 복잡한 데이터를 이용해야 할 경우, 해석 컴퓨터의 능력 및 용량, 해석 소요 시간 및 효율성, 해석의 적절성을 고려하여 최적의 학습전략을 수립하는 것이 중요하다. Fig. 5는 본 연구에서 여러 개의 시계열 데이터가 존재할 때 가능한 다대일 학습전략을 보여준다. 다대일 학습 전략에서는 침하 데이터만을 활용하여 인공지능을 학습시킬 경우, 순환 신경망은 손실율을 최소화하기 위해 모든 지점의 침하의 평균값을 예측하게 된다. 따라서, 하나의 인공신경망이 각 지점의 침하 특성을 고려하여 침하예측을 수행하기 위해서는 절성토 높이, 지반 복원 공법 종류, 표준관입시험 N값과 같은 각 지점의 특성의 추가 입력이 필요하며, 정확한 침하예측을 위해서는 이 특성들이 침하와 높은 상관도를 가져야 한다.
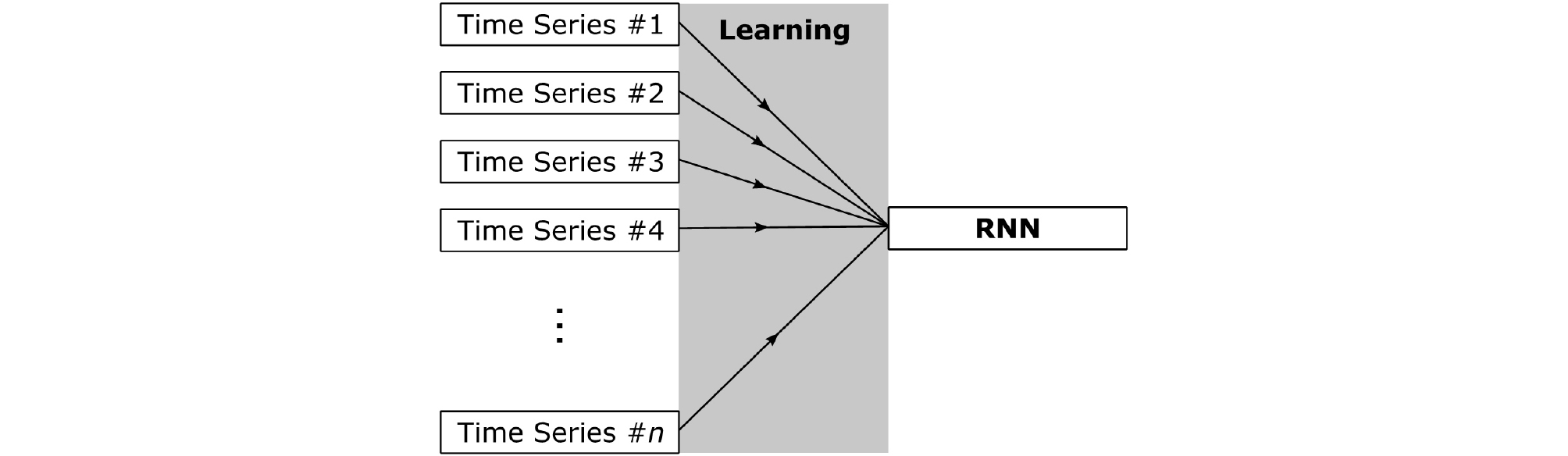
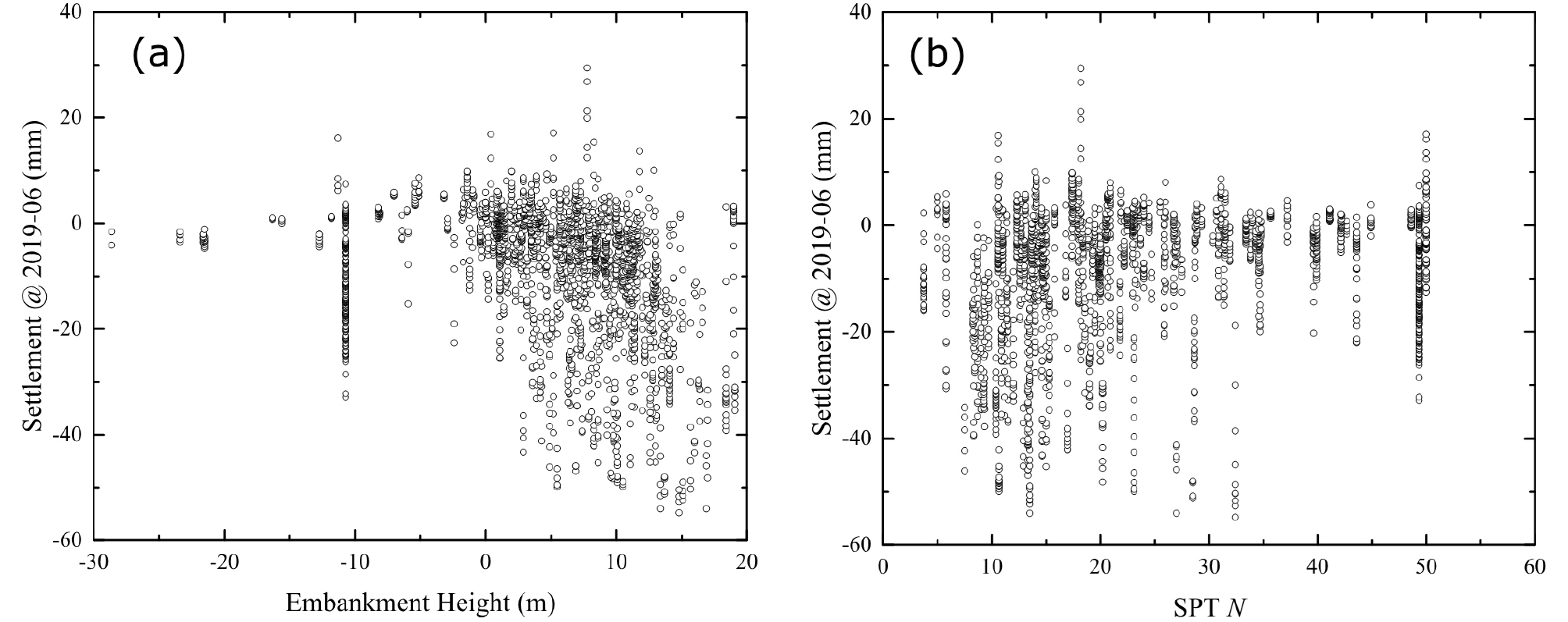
Fig. 6(a)와 (b)는 각각 OO고속선 각 지점에서 2018년도 6월에 측정된 침하량과 절성토 높이 그리고 표준관입시험 N값과의 상관관계를 도시하였다. Fig. 6에서 보는 바와 같이 침하 측정치와 절성토 높이 및 표준관입시험 결과와의 상관성은 매우 떨어지는 것으로 나타났다. 이는 N값은 원지반의 강성을 대표하며, 절성토 높이는 절성토 조건을 대표할 수 있지만, 궤도의 침하는 원지반, 성토체, 콘크리트 슬래브, 노반의 강성 및 시공 품질 그리고 강수량 및 온도와 같은 환경적 요인의 영향을 복합적으로 받기 때문이다. 이러한 낮은 상관도로 인해, 다대일 학습전략에 침하 데이터를 추가하여 시공정보 및 지반정보(표준관입시험 N, 절성토 높이 등)와 함께 입력하여 순환신경망을 학습하여도, 시공정보 및 지반정보의 가중치가 매우 작게 나타나, 순환신경망이 손실율을 최소화하기 위해 모든 지점의 평균 침하량을 예측한다.
이러한 결과를 바탕으로 본 연구에서는 시공 및 지반조사 정보를 배제하고 침하 데이터만을 사용하되 Fig. 7과 같이 각 지점에서 측정된 침하 데이터 하나에 여러 개의 인공지능을 할당하여 학습하고, 다수의 가중치 행렬에 저장하는 일대다 학습전략을 적용하였다. 일대다 학습 전략을 사용할 경우, 한 지점에 대해 여러 개의 인공지능이 침하 예측을 수행하며, 하나의 시간에 따른 침하 곡선에 대해서 할당된 각 인공지능 마다 각기 다른 예측을 수행하게 된다. 이는 각 인공지능을 학습시킬 때마다 적용되는 난수 발생에서 기인한다.
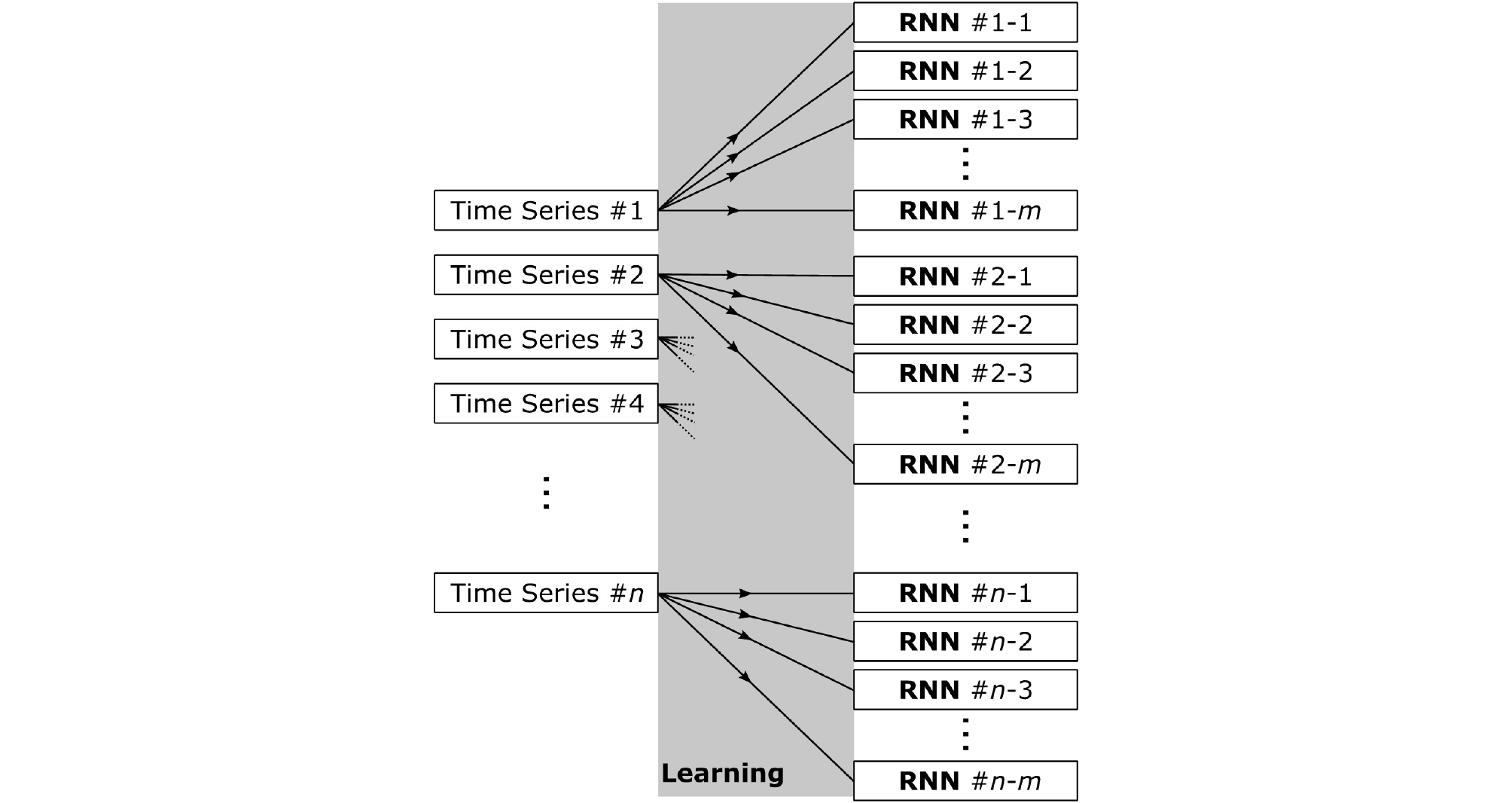
Fig. 8은 주어진 시간 침하 데이터를 이용해서 일대다 학습 전략을 적용한 인공지능을 활용하여 수행한 침하 예측의 예를 보여준다. 통계적 의미를 가지기 위해 총 30개의 인공지능을 한 침하 지점에 할당하여, Fig. 8(a)에 보이는 바와 같이 총 30개의 침하 예측 곡선이 산출되었다. Fig. 8(a)에서 확인할 수 있듯이 몇몇 예측에서는 이상치가 존재하지만, 대부분 예측은 특정 범위 안에 위치함을 알 수 있다. 통계적 관점에서 하나의 예측을 하나의 표본이라 볼 때, 표본의 평균과 표준편차를 산정하여 모집단의 평균을 추정할 수 있다. 이 때, 모집단의 평균은 무한대의 인공지능이 예측을 수행할 경우, 모든 예측의 평균값을 의미한다. Fig. 8(b)는 인공지능을 활용한 침하 예측의 평균, 최소값, 그리고 최대값을 모평균의 99% 신뢰구간과 함께 보여준다. Fig. 8(b)를 활용하면, 특정시간에 대해서 예상되는 침하의 범위를 제안할 수 있으며, 특정 침하가 발생 가능한 시간의 범위를 또한 제시할 수 있다.
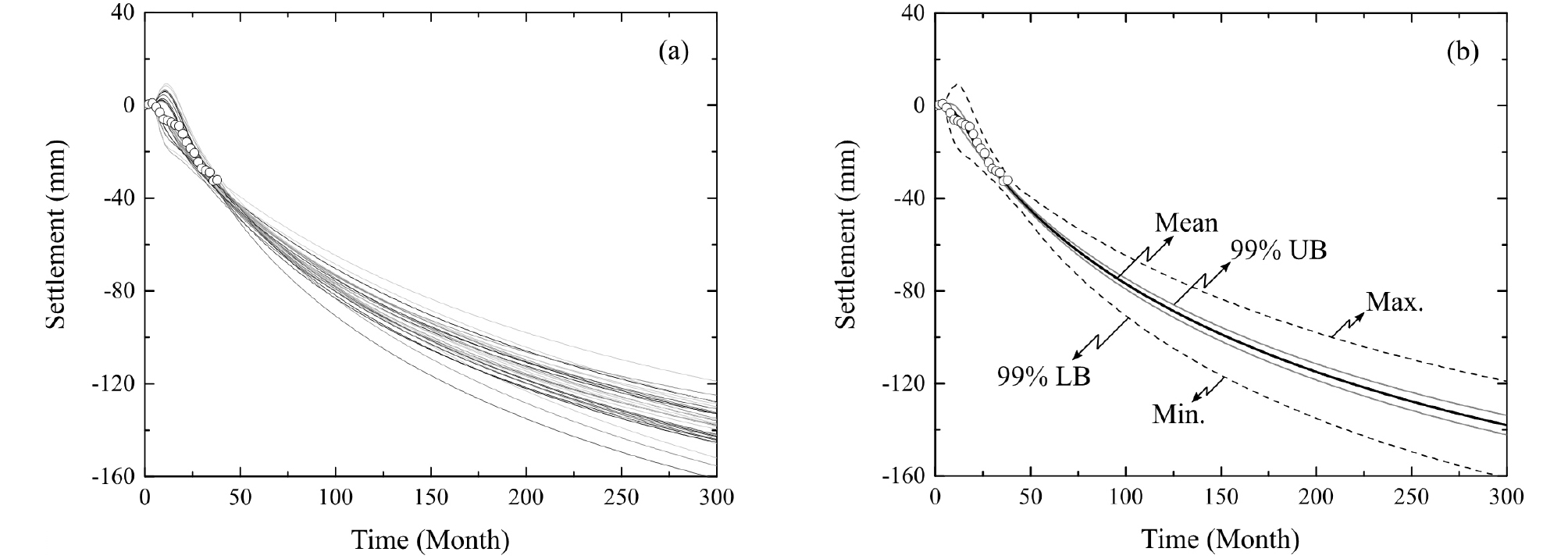
Fig. 8.
A settlement prediction example after the one-to-n learning strategy (hollow symbols represents measured settlements): (a) generated multiple (30) settlement prediction curves and (b) maximum, minimum, and mean settlement prediction curves overlapped with the 99% confidence interval of the mean settlement curve
3. 순환 신경망을 활용한 콘크리트궤도 침하 예측
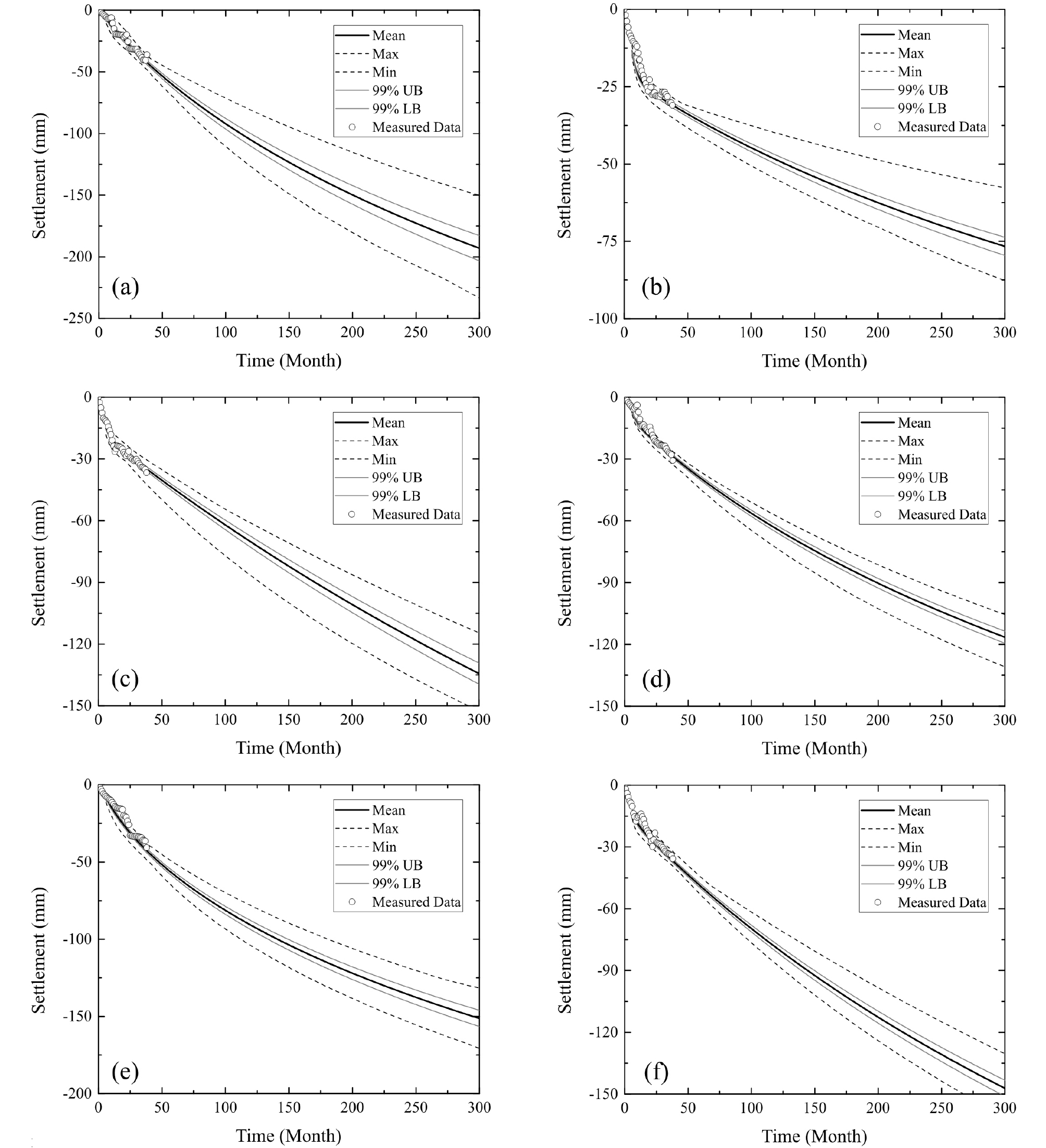
본 연구에서 학습을 위한 데이터셋을 구축하기 위해서, Fig. 3과 같이 순차적인 6개의 침하량을 입력값으로, 다음 순차의 침하량을 레이블로 설정하여 구성하였다. 한 침하 지점에 대해 존재하는 총 39개의 침하데이터를 이용하여, 총 32개의 학습 데이터셋을 구축하였다. 한 침하 지점에 30개의 인공지능을 연결시켰으며, 한 인공지능이 주어진 학습 데이터셋을 반복 학습하는 횟수를 뜻하는 에포크(Epoch)는 50회로 설정하여 각 인공지능을 모두 학습시켰다. 그 후, 처음 6개의 침하 데이터를 입력값으로 하여, Fig. 4에 나타난 과정을 기반으로 향후 약 30년까지의 침하량을 Fig. 8(a)과 같이 모든 인공지능을 이용하여 예측하였다. 최종적으로 각 침하 지점에 대해서 Fig. 8(b)와 같이 침하 예측의 평균, 최댓값, 최솟값, 그리고 99% 신뢰구간을 산정하였다.
Fig. 9는 각 침하 측정 지점에서 측정 침하 데이터(Measured Data)를 입력하여 30개의 순환신경망을 학습시킨 후, 산정한 예측 침하량의 평균(Mean), 최대값(Max), 최소값(Min), 그리고 모평균에 대한 99% 신뢰구간(99% UB와 LB)를 각각 보여주고 있다. Fig. 9의 측정된 침하량(Measured Data)의 패턴을 살펴보면, 점토층이 깊게 존재하는 연약지반의 압밀 침하와는 다르게, 침하량이 단조적으로 증가하지 않고 때때로 침하가 지체되거나, 오히려 융기하는 현상이 나타난다. 이는 앞서 언급한 바와 같이, 콘크리트궤도 노반의 침하는 원지반의 압밀 침하 이외에 원지반의 크리프 변형, 성토체 및 콘크리트 구조체의 변형, 기온 강수와 같은 환경적인 요인의 복합적 작용의 결과로 생각된다. 이러한 경우, 전통적인 방법인 쌍곡선법을 적용할 경우, 회귀분석의 상관 계수가 낮아지며, 예측의 정확도가 떨어지게 되며 때때로 쌍곡선 계수가 음수가 되어 예측이 불가능한 경우가 있다. Fig. 9의 순환신경망을 활용한 침하 예측 패턴을 보면, 전체적인 형태가 쌍곡선 형태를 띄는 침하 데이터(Fig. 9(a), (d), (e)), 선형성이 강한 침하 데이터(Fig. 9(f)), 그리고 쌍선형(Bilinear) 곡선 형태를 띄는 침하 데이터(Fig. 9(b), (c)) 모두에 대해서 모두 예측이 가능함을 알 수 있다.
3.1 침하 예측 성능 평가
본 연구에서는 콘크리트궤도에 대해 계측된 침하 데이터를 순환신경망에 적용하여 침하를 예측하였으며, 이러한 연구는 국내외에서 아직 시도된 바 없기 때문에 침하 예측 성능을 기존 방법과 비교 검증할 필요가 있다. 본 연구에서는 전체 침하 데이터를 학습 데이터과 검증 데이터로 나누어 학습 데이터를 이용하여 순환신경망을 학습시킨 후, 테스트 데이터를 이용하여 학습된 순환신경망의 예측 정확도를 평가하였다. 즉, 계측 시작 지점인 2015년 3월부터 전체 데이터의 80%에 해당하는 2017년 9월까지의 계측 데이터를 학습 데이터로 나머지 데이터를 테스트 데이터(Fig. 10 음영 부분)로 분류하였다. 또한, 현재 계측 기반 침하 예측에 가장 널리 사용되는 쌍곡선법으로 향후 침하를 예측하여 순환신경망을 이용한 침하 예측 결과와 비교하였다. 쌍곡선법의 적용시에는 가장 일반적으로 사용되는 축변환 후 회귀 방법을 사용하였다(Choo et al., 2010). 이 과정에서 얻어지는 선형 회귀식의 y절편 (α)과 기울기 (β)를 쌍곡선 식에 대입하여 침하 곡선을 구하였으며, 각 지점에서 평가된 쌍곡선 파라미터를 Table 2에 정리하였다.
Table 2. Hyperbolic model parameters for the settlement prediction
| Milepost | α | β |
| A | 34.0296 | -0.0092 |
| B | 7.6652 | 0.0269 |
| C | 8.7983 | 0.0228 |
| D | 40.5662 | -0.0056 |
| E | 42.8371 | -0.0209 |
| F | 10.0927 | 0.0227 |
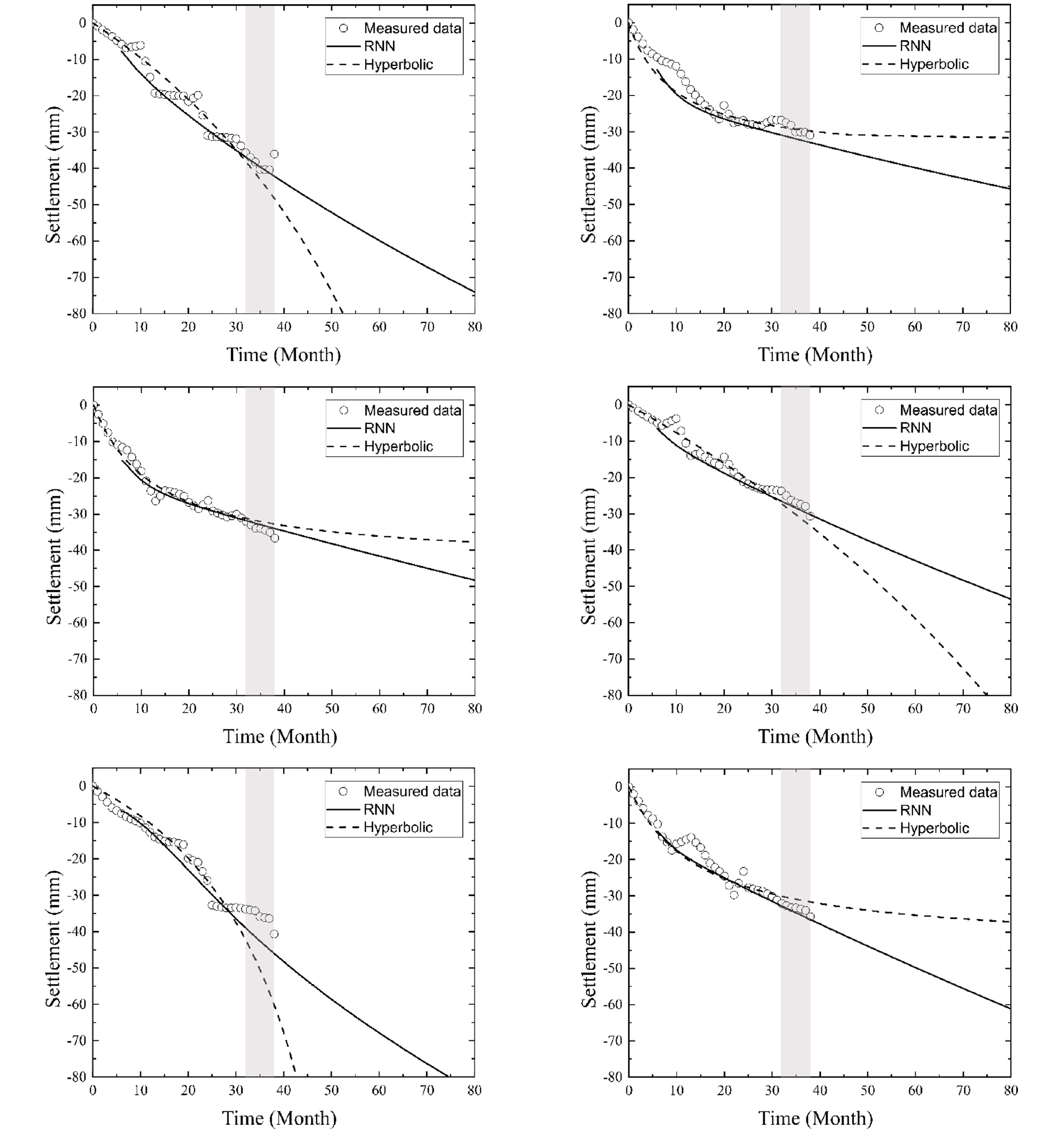
Fig. 10은 선정된 6 지점의 계측 데이터(Measured Data), 순환신경망을 활용한 침하 곡선(RNN), 쌍곡선법을 활용한 침하 곡선(Hyperbolic)을 함께 보여준다. 콘크리트궤도의 침하를 예측하는 데 있어 순환신경망과 쌍곡선법의 성능을 정량적으로 비교하기 위해 계측 데이터와 각 모델이 예측한 값의 평균 제곱근 오차(Root Mean Squared Error, RMSE)를 평가하여 Table 3에 정리하였다. 산정된 RMSE를 기준으로 볼 때, 6개 지점 중 5개 지점(Fig. 10(a), (c), (d), (e), (f))의 경우, 순환신경망이 쌍곡선법에 비해 테스트 데이터 기간에 해당하는 침하를 더 정확하게 예측하였다. 본 연구에서 검증 데이터로 활용한 개통 이후 32∼38개월 기간 동안 발생한 침하에 대해서, 6개 지점 모두에 대해 평균적으로 순환신경망 예측 침하량의 RMSE는 쌍곡선법을 사용한 예측 침하량의 RMSE의 약 절반으로 나타났다. 반면 6개 지점 중 1개 지점(Fig. 10(b))의 경우, 순환신경망을 이용하였을 때의 정확도가 쌍곡선법을 적용하였을 때 보다 떨어지는 것으로 판정되었다. 이는 해당 지점의 침하가 다른 지점과는 달리 압밀 침하와 유사하게 수렴하는 경향을 보이기 때문인 것으로 파악되며, 순환신경망 예측값이 학습 데이터 구간에서도 계측 데이터와 차이를 보이는 것으로 볼 때, 순환신경망의 학습이 최적화되지 않은 것으로 보인다. 순환신경망의 반복 학습 횟수인 에포크를 조절하여 최적화 과정을 거친다면 더 정확하게 침하를 예측할 수 있을 것으로 기대된다.
Table 3. RMSE (Root Mean Squared Error) between the settlements predicted (from the RNN and hyperbolic method) and the validation data at the selected milepost in this study
| Milepost | RMSE (mm) | |
| RNN | Hyperbolic | |
| A | 2.432 | 5.808 |
| B | 2.926 | 1.134 |
| C | 1.438 | 2.312 |
| D | 1.805 | 3.435 |
| E | 6.720 | 15.36 |
| F | 1.216 | 2.697 |
Table 4는 각 지점의 2018년 6월에 가장 마지막으로 계측된 침하량과 함께, 순환신경망과 쌍곡선법을 이용한 개통 4년 후 예측 침하량과 개통 30년 후 예측 침하량을 보여준다. 쌍곡선법을 적용할 때, 3개 지점(Fig. 10(a), (d), (e))에서, 회귀분석을 통해 산정되는 쌍곡선의 계수가 음수로 산정되어, 침하가 수렴하지 않았다. 이에 따라 쌍곡선법은 이 지점에서 개통 4년 후에 매우 큰 침하가 발생할 것으로 예측하였으며, 개통 30년 후 침하량 산정은 불가하였다. 반면, 침하가 발산하지 않은 3개 지점(Fig. 10(b), (c), (f))에서는 개통 후 38개월에 해당하는 최종 계측 침하량과 쌍곡선법이 예측한 4년(= 48개월) 후 침하량이 거의 동일하거나(Fig. 10(b)) 오히려 최종 계측 침하량이 더 큰 사실(Fig. 10(c), (f))에서 확인할 수 있다. 따라서, 이 지점에서는 쌍곡선법이 장래 침하량를 과소평가하는 것으로 판단된다.
Table 4. Predicted settlements (from the RNN and hyperbolic method) after 4 and 30 years
4. 결론 및 요약
콘크리트궤도의 침하는 원지반 강성, 성토체 강성 및 시공품질, 콘크리트 도상 및 궤도의 특성, 그리고 기온, 강수량과 같은 환경적인 요인의 복잡적인 작용의 결과이다. 따라서 콘크리트궤도의 침하 관리를 위해서는 해석적인 방법에 비해 현장 계측값을 활용한 귀납적인 방법이 일반적으로 적용된다. 현재 적절한 예측 방법의 부재로 연약 지반의 압밀 침하량 산정에 주로 사용되는 쌍곡선법이 콘크리트궤도의 침하 예측에 적용되고 있으나, 두꺼운 점토층에 발생하는 압밀 침하와 복잡한 부재로 구성되어 있는 콘크리트궤도의 장기 침하는 그 기전이나 발생 형태에 많은 차이가 있다. 이에 따라 본 연구에서는, 장기 침하량 예측을 위한 대안으로 순환신경망을 적용하여 그 가능성을 모색하였다.
순환신경망과 같은 인공지능을 올바르게 사용하기 위해서는 적절한 학습과정이 반드시 필요하다. 본 연구에서는 하나의 침하지점에 다수의 인공지능을 연결시키는 일대다 학습 전략을 수립하였으며, 각 인공지능은 독립적인 침하 예측을 수행한다. 이를 통계적으로 분석하여, 효율적이고 신뢰성 있는 유지관리를 위해 순환신경망을 이용한 전체 침하예측의 평균과 99% 신뢰구간을 제시하였다. OO고속선의 침하 측정 지점 중 여섯 지점에 대해 순환신경망을 활용하여 침하를 예측한 결과, 순환신경망은 침하 곡선이 쌍곡선 형태를 띄거나 선형성이 강한 경우뿐 아니라, 쌍선형 곡선 형태를 띄는 경우에도 향후 침하량을 예측 가능하였다. 계측 침하 데이터를 학습셋과 검증셋으로 나눈 후, 순환신경망을 통한 예측 침하 곡선과 쌍곡선법을 이용한 예측 침하 곡선을 비교한 결과, 여섯 지점 중 다섯 지점에서 순환신경망이 더 높은 정확도를 보여주었다. 향후 30년 이상의 장기 침하량을 산정한 결과, 순환신경망은 여섯 지점 모두에서 합리적인 범위의 침하량을 산정한 데 반해, 쌍곡선법은 콘크리트궤도의 계측 침하량의 복잡한 형태로 인해 세 지점에서는 쌍곡선 계수가 음수가 되어 침하가 발산하였으며, 나머지 세 지점에서는 침하를 과소평가하는 것으로 나타났다. 즉, 성토노반 및 콘크리트 궤도의 침하를 예측하는 데 있어 기본의 침하 예측 방법(e.g. 쌍곡선법)은 한계가 있는 것으로 나타난 반면, 순환신경망은 상대적으로 더 정확하게 침하를 예측할 수 있는 가능성을 보여주었다.
