

1. 서 론
2. 지하매설물 선형밀도 산정
3. 이력지반함몰 데이터를 활용한 위험도 등급 분석 알고리즘
4. 위험도 등급별 지하매설물 선형 밀도와 이력지반함몰의 상관성 분석 결과
5. 결 론
1. 서 론
지난 2021년 12월 고양시에서 지반침하와 함께 상가건물의 붕괴위험이 발생하여 입주민이 대피하고 시민이 불안감에 빠지는 사고가 발생하였다(YTN, 2021). 이외에도 2014년 8월 송파구 석촌 지하차도 아래쪽에 길이 80m 규모의 대형 공동(빈굴)이 발견되었고, 같은 시기에 공사가 진행 중이었던 제 2롯데월드 전면도로에 지반함몰이 다수 발생하고 석촌 호수의 수위가 낮아지면서 시민들의 불안감이 증폭되었다. 정부는 도심지에서 발생하는 땅꺼짐 사고를 방지하고, 지하공간의 안전한 활용을 위해 ‘지하안전관리에 관한 특별법’을 2018년부터 전면시행하고 있다(Han, 2018).
도심지에서 발생하는 지반함몰의 대다수가 지하에 매설된 관로주변의 지반에서 발생하는 것으로 보고되었다(Kim, 2022). 도심지에서의 사고를 예방하기 위해 지반 침하 및 함몰 위험도를 예측하고 관로의 유지관리에 활용하기 위한 다양한 연구가 진행되었다. 대표적으로 Choi et al.(2016)과 Park et al.(2017)은 상수도 및 하수관로의 구조건전도와 누수 등의 결함을 센싱하여 지반함몰 위험도를 분석할 수 있는 방안을 제시하였다. Kim et al.(2018)과 Kwak et al.(2019)은 하수관로 주변지반의 안전도 분석에 초점을 맞추어, 관로의 설치 상태, 강우, 연식 등과 지반함몰 위험도의 로지스틱 회귀 모델을 통해 위험도를 예측하는 연구를 수행하였다. Choi et al.(2021)과 Kim et al.(2021)은 서울시 지하매설물 정보를 분석하고 지하매설물의 선형밀도와 이력지반함몰 발생의 상관성을 분석하고, 위험도를 예측할 수 있는 최적화 모델을 제시하였다.
Choi et al.(2021)은 도심지 지하공간에 매설되어 있는 6종 시설물(상수도관로, 하수관로, 전력지중관로, 가스관로, 열배관, 통신관로)의 GIS기반 공간정보 데이터를 활용하여, 대상지역의 하부에 설치되어 있는 선형밀도를 분석하고, 2010~2015년 사이에 발생한 이력지반함몰의 위치와 상관관계를 분석하였다. 선형밀도는 공간분석(spatial analysis)에서 활용되는 방법으로, 관심지역 셀 주위의 임의의 반경 내에 설치되어 있는 지하매설물 길이를 단위 면적당의 크기로 정의한다(ArcGIS, 2022). 6종 지하매설물에 따라 설치깊이, 직경, 기능 등이 상이하기 때문에 관심 셀에서 선형밀도는 임의의 반경 내에서 각 매설물 길이별로 가중치를 설정하여 분석해야 한다. Choi et al.(2021)은 이력지반함몰 데이터와 지하매설물 선형밀도의 상관성을 높일 수 있도록 6종 지하매설물의 가중치를 결정하는 최적화 알고리즘을 제안하였다.
공간상의 위험도 분석은 등급을 구분하여 제시하는 것이 일반적이다(Kwon and Kim, 2014). 본 연구에서는 Choi et al.(2021)이 제안한 알고리즘을 보완하여, 제시된 위험도 등급에 따라 이력지반함몰과 매설물 밀도의 상관관계를 향상시킬 수 있는 알고리즘을 제안한다. 수정된 알고리즘은 Choi et al.(2021)이 제시한 1km × 1km 대상 지역의 위험도를 분석하는데 적용되고, 결과의 상호비교를 통해 정확도의 향상정도를 제시한다.
2. 지하매설물 선형밀도 산정
지하공간에 설치된 매설물의 선형밀도는 ArcGIS에서 제공하는 공간분석 기능을 활용하였다(ArcGIS, 2021). 본 절에서는 Choi et al.(2021)에서 제안한 선형밀도(line density)와 정규선형밀도(normalized line density)에 대하여 요약 설명한다. 선형밀도(line density)는 공간상에서 단위 셀 주변에 설치된 구조물의 밀도특성을 나타내며, 해당지역 내에 포함된 선의 공간적인 밀집 정도를 나타낼 수 있는 지표로 단위면적당 길이로 산정한다. Fig. 1은 셀(grid cell)별로 선형밀도(ρ)를 계산하는 개념을 보여준다. 개념적으로 원내에 위치하는 선들의 길이의 합을 산정하고 이를 원의 면적으로 나누어 선형밀도(ρ)를 계산한다. L1과 L2는 원 안에 설치되어 있는 2개 매설물의 공간상의 길이를 나타내며, 각 매설물의 특성에 따라 가중치 w1과 w2를 가정할 수 있다. 이때의 선형밀도(ρ)는 식 (1)을 통해 산정할 수 있다.
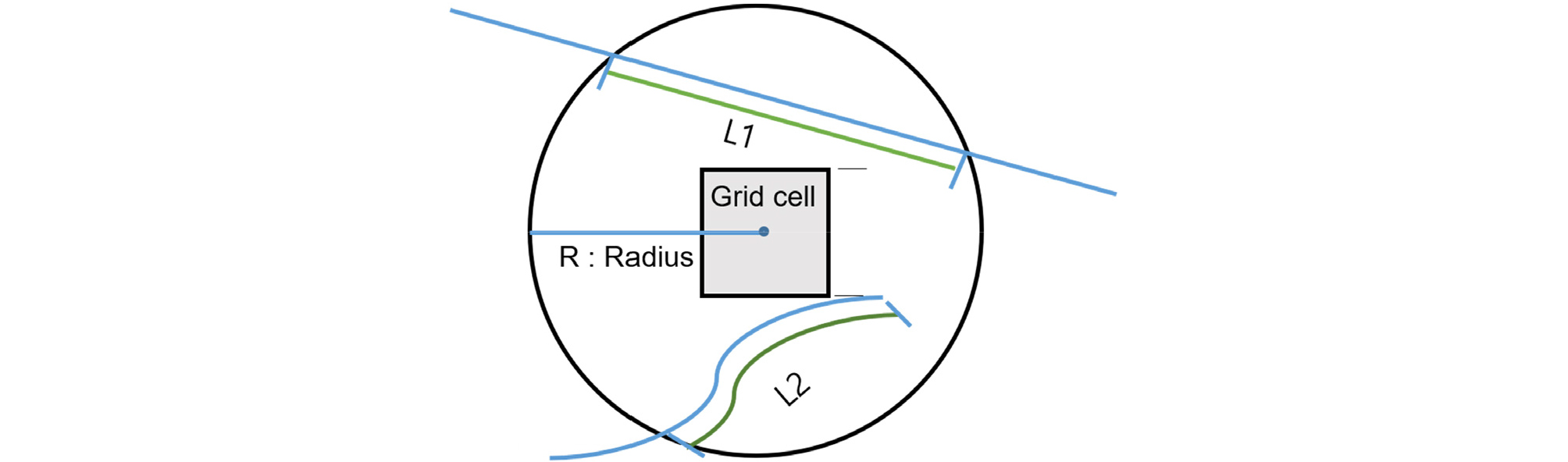
Fig. 1
A raster cell and the circular neighborhood used to determine the length for the line density redrawn from ArcGIS (2022) (Choi et al. (2021))
여기서, AR은 해당 셀에 영향을 미치는 원의 반지름 R로부터 계산된 원의 면적이다. Fig. 1과 식 (1)로부터 셀(grid cell)의 크기, R의 크기, 가중치 w1과 w2를 결정하여 선형밀도를 산정할 수 있다.
Choi et al.(2021)은 대상 지역의 정규 선형밀도를 산정하기 위해 식 (2)를 제안하였다.
where, w1,w2,…wn: weight factors
: length of each buried structures
n: number of buried structure types
: radius of affecting zone
식 (2)에서 ρn(정규선형밀도)는 고려 대상 지하매설물 종류의 개수로 정규화된 선형밀도 값으로 정의할 수 있으며, 식 (3)으로부터 n개 매설물별 weight factor의 합은 1.0으로 제한된다.
본 연구에서는 기본적으로 지반함몰이 발생된 위치에서 정규선형밀도가 높게 분포된다는 가정 하에 최적화 알고리즘을 제안한다. 식 (3)을 충족하고 정규선형밀도가 높게 분석될 수 있도록 6종 지하매설물(상수관, 하수관, 전력 지중관로, 천연가스배관, 통신선로, 열 배관)의 w1,w2…,w6을 랜덤으로 생성하였다. Choi et al.(2021)에서 적용한 100,000세트의 동일한 랜덤 벡터를 본 해석에 활용하였다.
3. 이력지반함몰 데이터를 활용한 위험도 등급 분석 알고리즘
본 절에서는 Choi et al.(2021)에서 제시한 이력지반함몰 데이터 기반의 최적 정규선형밀도 분석 알고리즘을 요약하여 설명하고, 위험도 등급을 기반으로 최적화하기 위하여 보완된 Error 함수를 제시한다.
식 (4)는 지반함몰이 발생한 셀에서 정규선형밀도를 100,000세트의 랜덤 wi=[w1;w2;w3;w4;w5;w6]로 산정하기 위한 일반식이다.
여기서, ρns: 지반함몰이 발생한 셀에서 정규선형밀도, ρsh: 지반함몰이 발생한 셀에서 선형밀도, Dot product(∙): Matrix multiplication을 의미한다. Choi et al.(2021)은 ‘지반함몰이 발생한 지점의 ρn은 해석 대상 구역에서 상대적으로 높은 값을 갖는다’는 전제하에 최적화(optimization)를 위한 Error 함수를 식 (5)와 같이 제안하였다.
앞서 설명한 바와 같이 공간상의 위험도 분석은 등급을 구분하여 제시하는 것이 일반적이다(Kwon and Kim, 2014). 본 논문에서는 ‘지반함몰이 발생한 지점에서 지반함몰 위험도 등급이 가장 높다’는 가정 하에 식 (6)의 Error 함수를 새롭게 제안한다. 새로운 Error 함수의 제시가 Choi et al.(2021)과 차별화되는 부분이다.
식 (6)에서 GN은 구분하고자 하는 위험도 등급의 개수이다(e.g., 5등급으로 분류하고자 하면 GN=5이고, 5등급이 가장 위험한 등급이다). 인덱스 k는 랜덤 wi-set의 순번이며, Gpsk는 지반함몰 발생위치에서 k번째 wi-set을 적용할 때 위험도 등급이다. 따라서 식 (6)은 ‘지반함몰이 발생한 지점에서 지반함몰 위험도 등급이 가장 높다’는 전제하에 Error의 Norm을 나타낸다. Gρsk은 아래의 sub-function을 통해 산정된다.
ρnk은 해석영역에 wik를 적용할 경우의 정규선형밀도로서 최대값은 Max(ρnk)로 정의되며, Nρsk은 지반함몰이 발생한 위치에서 wik를 적용할 때 Max(ρnk으로 정규화된 선형밀도의 비율(0~1.0)로 정의된다(식 (7) 참조).
ρnsk는 지반함몰 발생위치에서 wik를 적용하여 산정한 정규선형밀도이며, ρnk는 식 (8)과 같이 해석영역의 모든 셀에 wik를 적용할 경우의 정규선형밀도이다. 식 (8)에서 ρraw는 ArcGIS로 산정한 매설물별 선형밀도이다.
따라서, sub-function ‘normdensity2grade’는 지반함몰이 발생한 위치에서 정규화된 선형밀도 Nρsk의 위험도 등급을 등급 개수 GN을 적용하여 산정하는 역할을 수행한다.
식 (6)을 통해 100,000개 세트의 Error Norm을 분석하고, 식 (9)와 식 (10)을 통해 Error가 최소인 wgrade-set을 결정한다.
식 (9)의 kgrade는 100,000개의 wi-set 중에서 식 (6)의 Error가 최소화 될 때의 인덱스로 정의된다. Table 1은 식 (4)~식 (10)을 구현하기 위한 Pseudo-code를 보여준다.
Table 1.
Pseudo-code to obtain optimal wi-set for finding higher correlation between risk grade and ground subsidence modified from Choi et al. (2021)
4. 위험도 등급별 지하매설물 선형 밀도와 이력지반함몰의 상관성 분석 결과
본 절에서는 ‘지반함몰이 발생한 지점에서 지반함몰 위험도 등급이 가장 높다’라는 전제하에 제안된 지반함몰 위험도 분석 알고리즘을 실제로 발생한 이력지반함몰 데이터에 적용하여 지하매설물 밀도와 상관관계를 비교한다. 또한, 분석결과를 Choi et al.(2021)에서 제시한 알고리즘을 적용한 결과와 비교하여 위험도 분석 정확도의 향상정도를 파악하였다. 대상지역은 Choi et al.(2021)에서 제시한 서울시 송파구 일대이며, 1km × 1km 대상 지역을 선정하여 6종 지하매설물의 선형밀도 데이터를 분석하고, 해당 지역에서 2010~2015년 사이에 발생한 29건의 지반함몰 위치데이터와 공간상에서 매설물 밀집도의 상관관계를 분석하였다.
Fig. 2는 2010~2015 기간 동안 발생한 29개의 이력지반함몰을 빨간색 점들로 보여준다. Table 2는 해당 지역에 설치된 6종 지하매설물(상수관로, 하수관로, 전력지중관로, 가스관로, 열 배관, 통신관로)의 총 설치길이와 단위 관로의 개수를 제시한다.
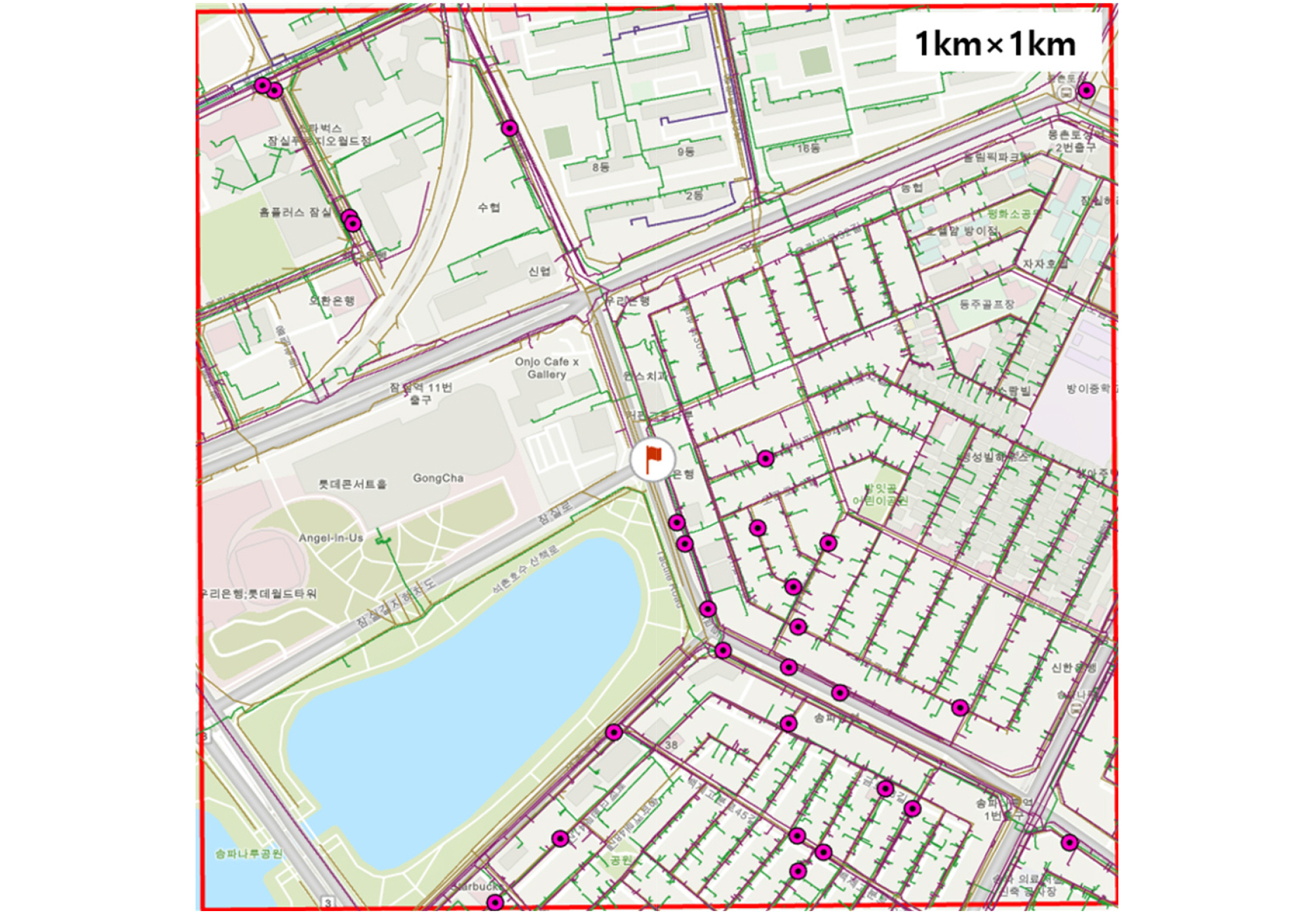
Fig. 2
1km×1km map of analysis region and 29 ground subsidence locations with magenta circle symbol (Choi et al. (2021))
Table 2.
Length and number of unit for 6 buried utility structures (Choi et al. (2021))
Fig. 3은 29개 이력지반함몰 위치에서 정규선형밀도 분석 결과를 5개 등급으로 구분하여 보여준다. 첫 번째 열은 최적화 알고리즘을 적용하지 않은 wi=1/6 경우, 두 번째 열은 Choi et al.(2021)에서 제안한 wopt(정규선형밀도를 기준으로 최적화된 wi)을 적용한 경우, 세 번째 열은 본 연구에서 제안한 wgrade(등급 기준으로 최적화된 wi)을 적용한 해석결과이다. Table 3은 6종 지하매설물(상수관로, 하수관로, 전력지중관로, 가스관로, 통신관로, 열 배관)별로 가중치(w1,w2,w3,w4,w5,w6)를 보여주며, wopt는 식 (5)로 최적화한 경우이고 wgrade는 식 (6)을 적용하여 최적화한 경우이다. Fig. 3의 각 열의 위에서부터 R은 각각 50m, 100m, 150m을 적용한 결과이며, 본 연구에서는 Fig. 1의 셀 크기(Grid cell)의 가로, 세로 길이를 10m로 설정하였고, 자세한 공간분석 내용은 Choi et al.(2021)을 참조한다. 첫 번째 열과 비교하면 두 번째 및 세 번째 열의 최적화 알고리즘을 적용하여 선형밀도분석에 활용할 경우 이력지반함몰이 일어난 위치에서 정규선형밀도의 등급이 상승하는 것을 확인할 수 있다. 이는 최적화 알고리즘을 적용하면 이력지반함몰 발생 위치와 지하매설물 밀도의 상관성에 대한 정확도를 향상시킬 수 있음을 의미한다.
Table 3.
wgrade and wopt out of 100,000 wi-set obtained from minimizing Error functions (Eq. (5) and Eq. (6)) with the variation of R
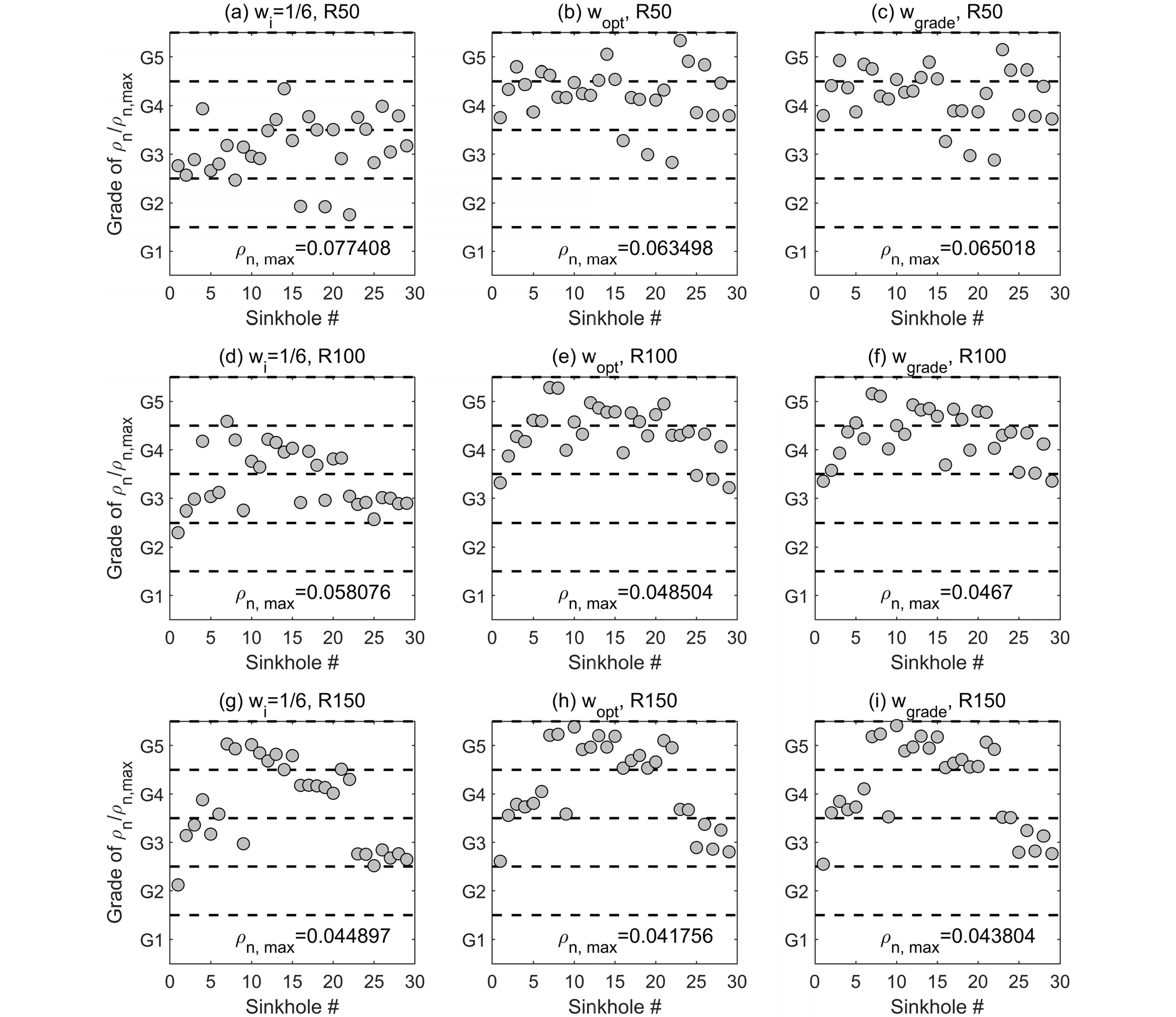
Fig. 3
Comparison of grades of at 29 sinkhole locations, first column , second column wopt (Choi et al. (2021)) and third column wgrade with R: 50m, 100m, 150m for this study
본 연구는 위험도 등급(grade)을 기준으로 Error 함수를 제안한 점이 Choi et al.(2021)과 차별화 된다. Fig. 3의 데이터를 보다 명확히 이해하기 위하여 Table 4에 5개 등급별로 이력지반함몰의 발생개수를 분석하였다. Table 4에서 제시된 바와 같이 2개의 최적화 알고리즘(wopt & wgrade)을 적용할 경우 이력지반함몰은 모두 위험등급 3이상에서 발생한 것으로 분석되었다. Choi et al.(2021)의 최적화 알고리즘과 본 연구의 최적화 알고리즘의 차이는 4등급 이상의 지하매설물 정규선형밀도 지역에서 나타난다. Table 3의 R50과 R150에서 2개의 최적화 알고리즘을 적용할 경우 각각 90%와 79%의 이력지반함몰이 4등급 이상에서 동등하게 발생되었다. 하지만, R100의 경우 Choi et al.(2021)은 86%, 본 연구의 경우 93%의 이력지반함몰이 4등급 이상에서 발생하였다. 이는 본 연구에서 제안한 Error 함수인 등급기준의 최적화 알고리즘을 적용할 경우, 관심 지역에서 지반함몰 위험도 등급 결정에 있어 보다 정확한 결과를 제시한다는 것을 나타낸다.
Table 4.
Number of ground subsidences corresponding to 5 grades at 29 sinkhole locations with , wopt and wgrade
| Radius | R50 | R100 | R150 | ||||||
| Grade | Choi et al. (2021) | This study | Choi et al. (2021) | This study | Choi et al. (2021) | This study | |||
| wopt | wgrade | wopt | wgrade | wopt | wgrade | ||||
| G1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| G2 | 4 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| G3 | 15 | 3 | 3 | 15 | 4 | 2 | 11 | 6 | 6 |
| G4 | 10 | 17 | 16 | 12 | 12 | 15 | 8 | 8 | 8 |
| G5 | 0 | 9 | 10 | 1 | 13 | 12 | 9 | 15 | 15 |
| % (≥G4) | 34 | 90 | 90 | 45 | 86 | 93 | 59 | 79 | 79 |
Fig. 4는 R100 해석결과에 대하여 식 (5)와 식 (6)의 Error 함수를 상호 비교하여 보여준다. Fig. 4(a)와 4(b)는 각각 식 (5)와 식 (6)에 대하여 100,000세트의 랜덤 wi을 적용한 경우 Error 함수의 해석결과이다. Error 함수 식 (5)와 식 (6)을 100,000세트의 랜덤 wi에 적용할 경우 각각 랜덤 세트의 인덱스 k=24,079(심볼 ‘+’)와 k=41,509(심볼 ‘*’)에서 Error가 최소화 되는 것으로 나타났다. 즉, Fig. 4(a)(식 (5))의 ‘+’에서 최소 Error Norm이 분석되었고, 이때의 인덱스 k를 식 (6)에 적용하여 발생하는 Error Norm을 Fig. 4(b)에 ‘+’로 표기하였다. 마찬가지로 Fig. 4(b)(식 (6))의 ‘*’에서 최소 Error Norm이 분석되었고, 이때의 인덱스 k를 식 (5)에 적용하여 발생하는 Error를 Fig. 4(a)에 ‘*’로 표기하였다. Fig. 4(a)에서 Error의 Norm을 보면 식 (5)를 적용한 경우 1.3595, 식 (6)로부터 구한 k를 적용한 경우는 1.4083으로 나타났다. 본 연구의 등급기준으로 최적화 할 경우 ‘지반함몰이 발생한 지점의 정규선형밀도(ρn)는 해석 대상 구역에서 상대적으로 높은 값을 갖는다’라는 가정 하에 최적화한 경우보다 Error Norm이 다소 큰 것으로 분석되었다. 하지만, Fig. 4(b)에서 식 (6)을 적용한 결과를 보면 Error Norm이 각각 5.2915와 4.7958로 나타나 위험도 등급 기준으로 최적화 알고리즘을 적용하면 Error의 Norm이 작아지는 것을 알 수 있다. 즉, 위험도 등급을 구분하기 위한 최적화 알고리즘에는 식 (6)의 등급기준 Error 함수가 보다 적합한 것으로 분석되었다. Table 5는 R50, R100, R150의 경우 식 (5)와 식 (6)을 적용한 경우의 Error값을 상호 비교하여 보여준다. 앞서의 결과와 유사하게 R100의 경우 5개의 위험도 등급 기준으로 해석하면, Choi et al.(2021) 대비 3.5%의 Error 감소 효과를 나타냈고, R50과 R150의 경우 동등 이상의 Error 감소 효과를 나타냈다.
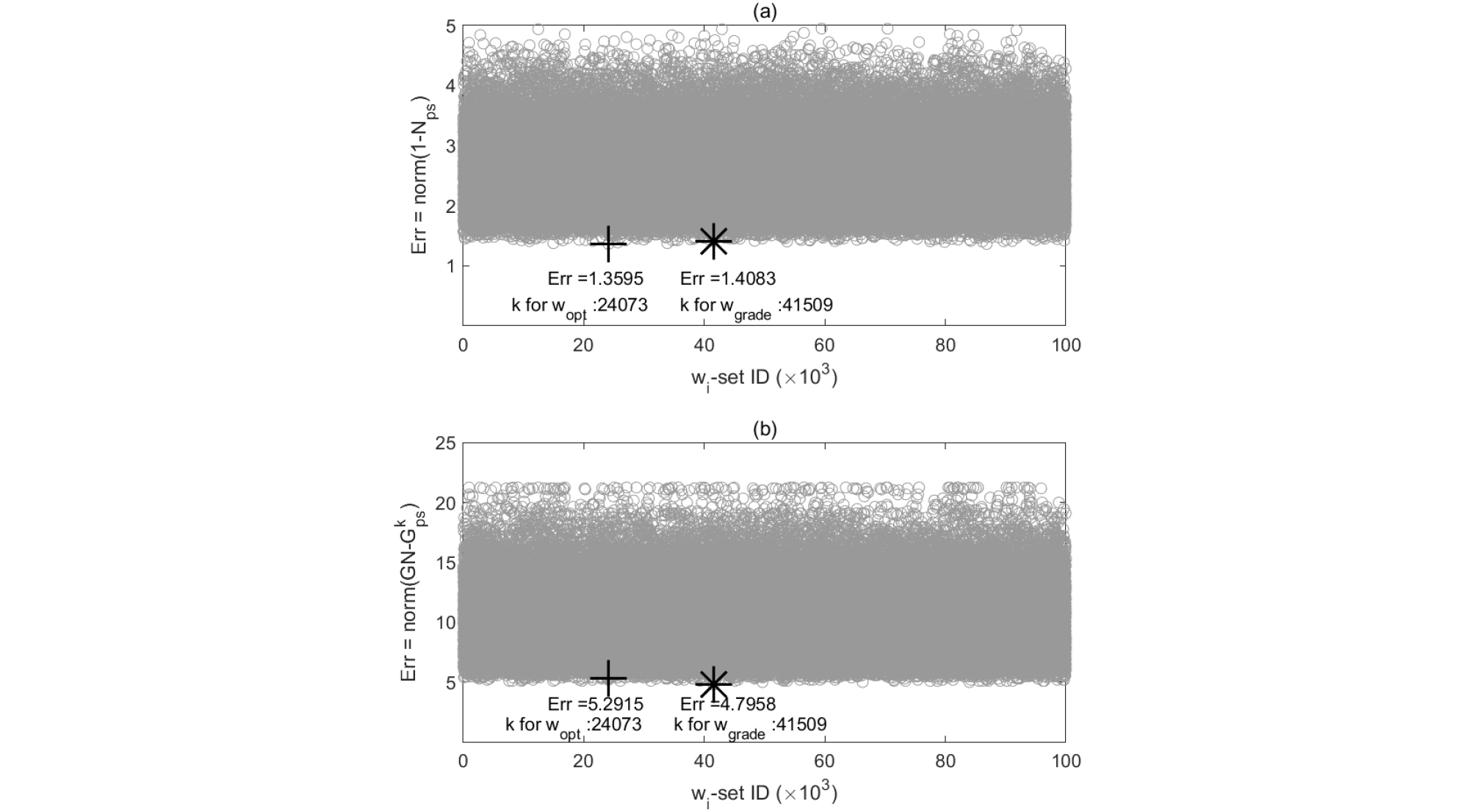
Table 5.
Comparison of Error Norm between Error functions Eq. (5) and Eq. (6)
5. 결 론
본 논문에서는 Choi et al.(2021)이 제안한 지하에 설치되어 있는 매설물의 선형밀도(line density)와 지반함몰 위험도의 상관관계를 최적화하기 위한 보완연구를 수행하였다. Choi et al.(2021)은 지하매설물의 정규선형밀도 개념을 도입하고, ‘지반함몰이 발생한 위치에서 정규선형밀도가 높다’는 가정 하에 Error 함수를 제안하였다. 하지만, 도심지 재해를 관리하는 측면에서는 위험도 등급을 구분하는 것이 일반적이다. 따라서 본 연구에서는 위험도 등급 기준을 바탕으로 ‘지반함몰이 발생한 지역에서 위험도 등급이 높다’는 가정을 통해 Error 함수를 보완하였다. 두 종류의 Error 함수를 적용하고 이력지반함몰과 지하매설물 밀도의 등급을 상호 비교하기 위하여, Choi et al.(2021)에서 활용한 2010~2015년 사이에 발생한 29개 이력지반함몰과 선형밀도의 상관관계를 비교 분석하였다. 1km × 1km 지역에 대한 정규선형밀도를 분석하고, 두 종류의 Error 함수를 통해 5단계 위험도 등급에서 발생한 이력지반함몰 발생 건수를 분석하여 다음과 같은 주요 결론을 도출했다.
(1) R50, R100, R150의 선형밀도 데이터를 활용하여, Error 함수(1)은 ‘지반함몰이 발생한 위치에서 정규선형밀도가 높다’, Error 함수(2)는 ‘지반함몰이 발생한 지역에서 위험도 등급이 높다’는 가정을 바탕으로 제안되었다. 5개 등급으로 구분하여 4등급 이상에서 발생한 지반함몰의 비율을 비교하였다. R100의 경우에서 Error 함수(1)의 경우 86%, Error 함수(2)의 경우 93%의 이력지반함몰이 4등급 이상에서 발생하여 제안된 Error 함수의 정확도가 향상됨을 알 수 있다. R50과 R150의 경우 Error 함수(1)과 Error 함수(2)의 정확도가 유사하게 나타났다. 분석 결과로부터 본 연구를 통해 제안된 ‘지반함몰이 발생한 지역에서 위험도 등급이 높다’는 가정의 Error 함수가 ‘지반함몰이 발생한 위치에서 정규선형밀도가 높다’는 가정의 Error 함수와 비교하여 보다 정확한 등급별 위험도 분석 결과를 제시하는 것으로 나타났다.
(2) 도심지 재해를 예측하기 위한 위험도 분석은 등급을 구분하여 해석하는 것이 일반적이다. 따라서 본 연구를 통해 제안된 등급 기준 최적화 알고리즘은 도심지에서 지반함몰 위험도 지도를 등급별로 분석하는데 적용될 수 있으며, 이를 바탕으로 지하매설물 유지보수 투자를 위한 의사결정 기초자료로 활용될 수 있을 것으로 판단된다.
