

1. 서 론
2. 이론적 배경
2.1 PHC 매입말뚝과 동재하시험 특성
2.2 말뚝지지력 예측을 위한 머신러닝 기술 활용
3. 분석 방법
3.1 동재하시험
3.2 딥러닝 데이터셋
3.3 데이터 전처리 및 특성 구성
3.4 딥러닝 모델 구조
4. 분석 결과
4.1 지지력 예측 결과
4.2 시멘트풀 양생에 따른 지지력 변화
4.3 SHAP(Shapley Additive exPlanations) 분석 결과
4.4 매입말뚝 최대 지지력 확인을 위한 항타조건 결정
4.5 매입말뚝 시공관리 Tool 개발 및 현장 활용
5. 결 론
1. 서 론
고강도 또는 초고강도 PHC(Pretensioned spun High-strength Concrete) 말뚝을 이용한 매입말뚝 공법은 우수한 구조성능과 시공성으로 기초공사에 폭넓게 적용되고 있으며, 특히 저소음·저진동의 이점으로 국내 도심지 현장에서 활용도가 높다. 국내에서 보편화된 SDA(Separated Donut Auger) 공법은 오거와 케이싱을 반대방향으로 회전시켜 지반을 굴착한 후, 굴착공에 PHC 기성말뚝을 삽입하고, 말뚝과 굴착공 사이에 주입된 시멘트풀이 양생되는 동안 주면마찰력이 증대되어 지지력이 발현되는 매커니즘을 갖는다(Fig. 1 - Chai, 2007; Hong and Chai, 2007; Cho, 2023). 따라서 매입말뚝의 지지력에는 주면마찰력과 선단지지력에 더해 시멘트풀의 양생에 따른 시간효과가 복합적으로 작용한다.
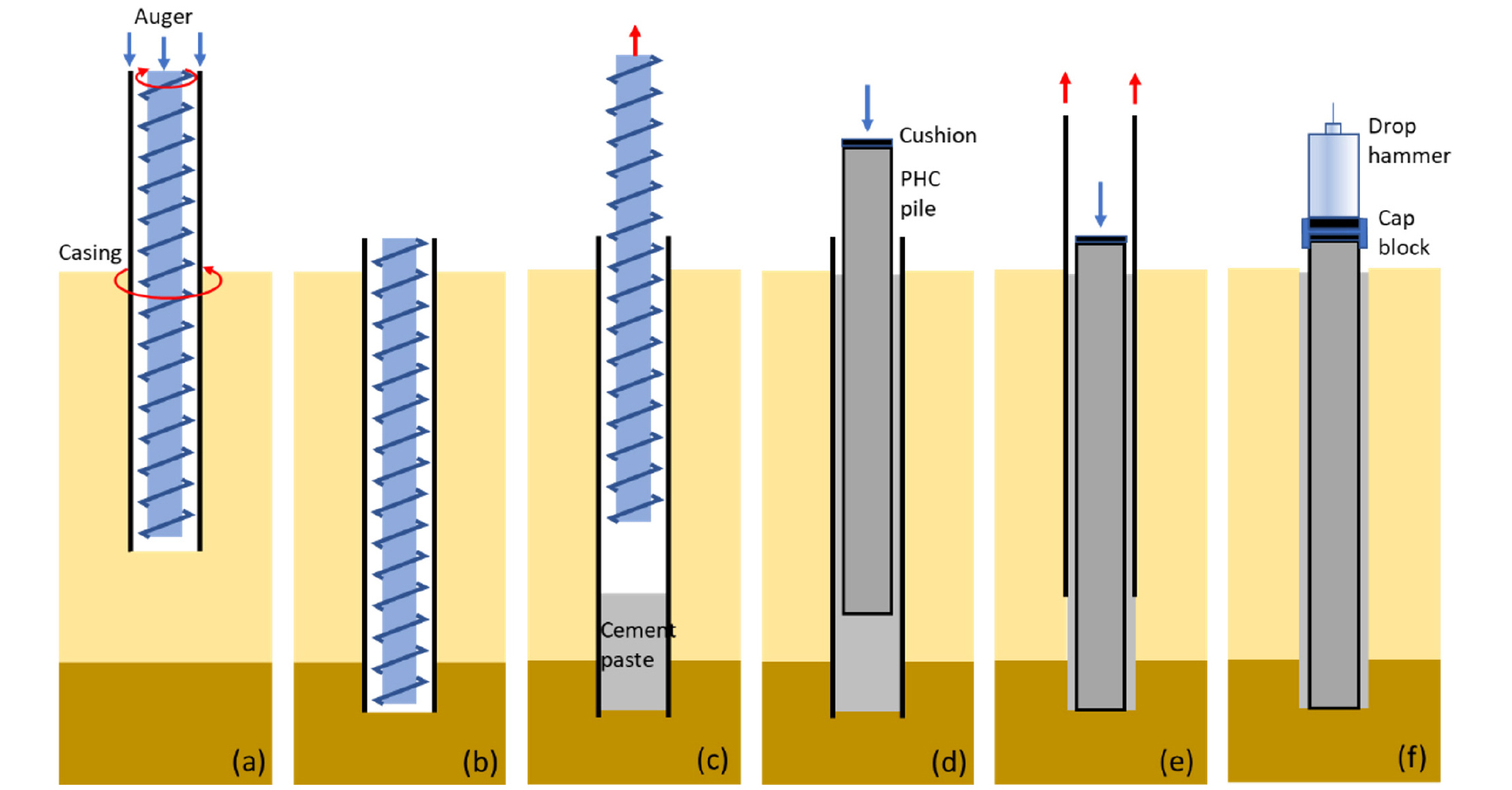
Fig. 1
Pile installation steps of a PHC auger-drilled pile using the SDA method: (a) excavation by rotating the auger and casing, (b) completion of excavation, (c) auger extraction and the 1st cement paste injection, (d) PHC pile installation and the 2nd cement paste injection, (e) casing extraction, (f) ram weight drop
일반적으로 말뚝의 지지력은 지반조건, 말뚝특성, 항타조건, 시간효과 등 다수 인자의 복합적 상호작용에 의해 결정되기 때문에 정량적인 평가가 어렵다(Cho, 2023; Park et al., 2006). 특히 매입말뚝은 시멘트풀 양생으로 인한 시간의존적 거동으로 인해 초기항타(EOID, End Of Initial Driving) 단계와 재항타(Restrike) 단계에서 지지력 양상이 상이하므로, 일반 항타말뚝에 비해 거동이 더욱 복잡하다(Park, 2017; Seo et al., 2020). 현장에서는 PDA(Pile Driving Analyzer)를 이용한 동재하시험으로 시공품질을 확인하며, Case 방법을 통해 말뚝의 총지지력을 즉시 추정할 수 있다. 그러나 주면마찰력과 선단지지력의 분리평가는 CAPWAP(CAse Pile Wave Analysis Program) 해석을 통한 신호매칭 등 후처리 과정이 필요하므로, 현장에서 분리된 지지력을 즉시 판단하기는 어렵다(Lee et al., 1994; Park, 2017).
또한 설계단계에서 일반적으로 사용하는 SPT(Standard Penetration Test) N값 기반의 경험식은 매입말뚝 지지력에 영향을 미치는 다양한 인자를 충분히 반영하기 어렵다. 이로 인해 단순화된 설계 지지력은 동재하시험을 통해 예측한 값과는 상이한 경우가 대부분이다. 따라서 설계단계의 말뚝물량 산정이나 시공단계의 공기예측을 고도화하기 위해서는 시멘트풀 양생에 따른 시간효과를 포함한 다변량의 상호작용을 반영하는 실증적인 예측방법이 요구된다. 이러한 복합거동의 예측은 단순 회귀분석으로는 한계가 있으며, 비선형 상호작용을 학습할 수 있는 머신러닝·딥러닝 기법의 적용이 효과적이다. 최근 지반공학 분야에서도 말뚝의 지지력 예측을 포함한 다양한 공학적 문제에 대해 데이터 기반 모델을 적용하는 사례가 증가하고 있으며, 이는 입력치와 출력치 간의 물리적 관계가 완전히 규명되지 않더라도 높은 예측성능을 확보할 수 있다는 장점이 있다(Lee and Lee, 1996; Park et al., 2006; Shahin, 2010, 2016; Seo et al., 2025).
본 연구의 목적은 국내 현장조건에 적용되는 PHC 매입말뚝의 주면마찰력, 선단지지력 및 총지지력을 시공단계에 따라 분리하여 예측하는 딥러닝 모델을 개발하는데 있다. 기존 SPT N값 기반의 설계 경험식에 비해 예측 정확도와 일반화 성능을 향상시키고, 항타조건 및 지반조건을 반영하며, 매입말뚝의 특성인 시멘트풀 양생에 따른 시간의존적 거동을 분석 가능한 모델을 개발하는 것을 목표로 하였다.
2. 이론적 배경
2.1 PHC 매입말뚝과 동재하시험 특성
매입말뚝의 설계 및 시공관리에서 가장 중요한 부분은 지지력의 정확한 예측과 시공단계에 따른 품질확인이다. 국내 매입말뚝의 지지력 평가는 시공 직후의 지지력을 평가하는 EOID 단계와, 시멘트풀의 양생과정에서 발생하는 주면마찰력 증가효과가 반영된 지지력을 평가하기 위한 Restrike 단계로 구분된다. 매입말뚝의 지지력은 시공조건, 재료특성, 시멘트풀 양생기간 등의 다양한 인자에 의해 영향을 받는데, 머신러닝 기법은 복잡한 비선형 관계를 모델링할 수 있기 때문에(Lee and Chang, 2006; Seo et al., 2025), 특히 시멘트풀 양생에 따라 지지력이 증가하는 시간경과에 따른 지지력의 변화 경향을 데이터 기반으로 학습할 수 있는 장점이 있다.
말뚝기초의 복잡한 거동과 관련한 비선형 문제를 해결하기 위해 머신러닝 기반의 예측기법 적용이 꾸준히 이루어져 왔다. 초기 연구에서는 인공신경망(ANN, Artificial Neural Network) 모델을 중심으로 개발이 이루어졌으며, 이후 다양한 알고리즘으로 확장되어 각 분야에 맞는 문제 해결에 활용되었다. 최근 컴퓨터 성능의 향상과 데이터 처리기술의 발전으로 이러한 모델들이 더욱 고도화되고 있으며, 향후 지반공학 분야에서의 머신러닝·딥러닝 기법의 적용범위가 지속적으로 확대될 것으로 예상된다(Lee and Lee, 1996; Lee and Chang, 2006; Park et al., 2006; Shahin, 2010, 2016; Seo et al., 2025).
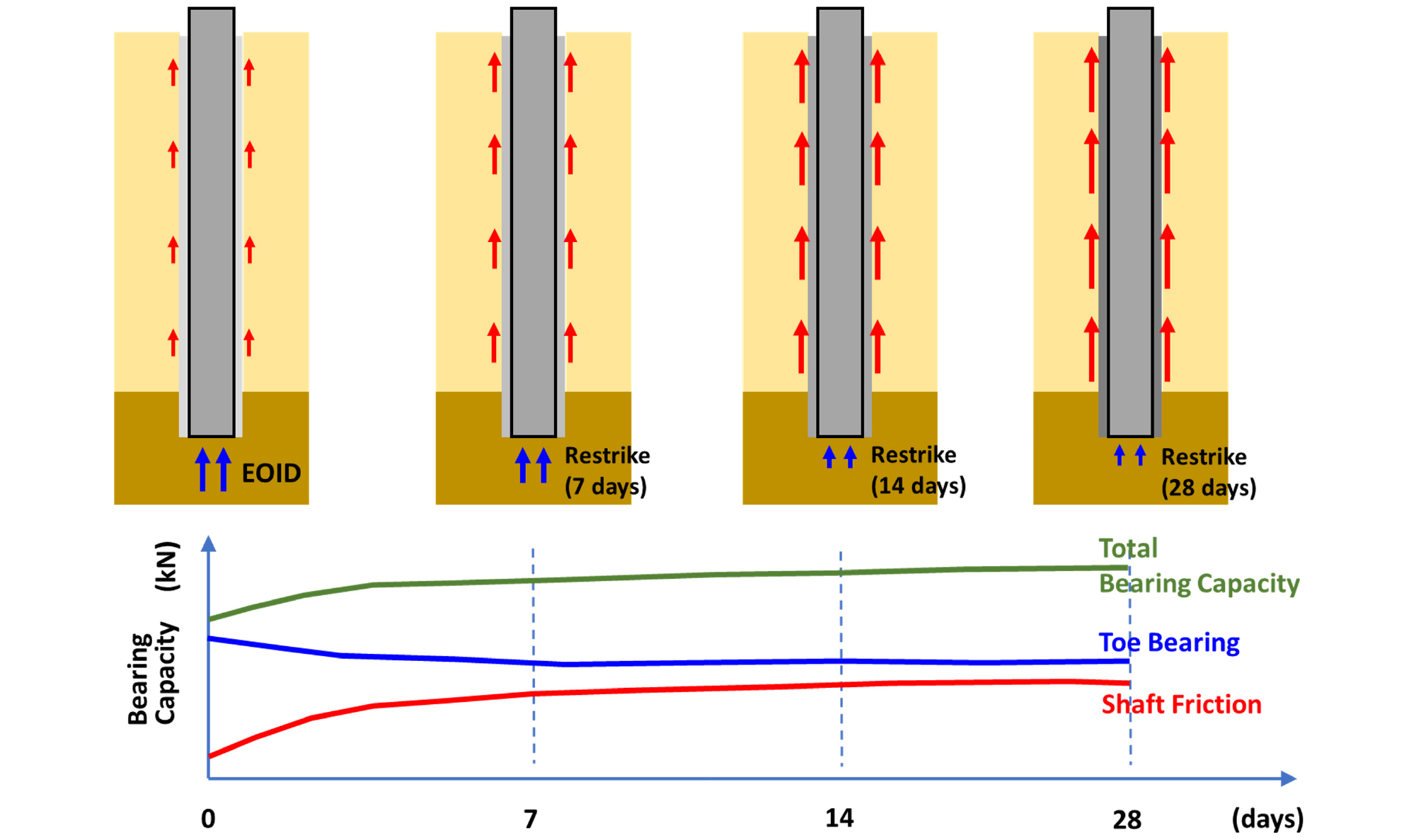
매입말뚝 동재하시험의 신뢰도를 향상시키기 위해서는 시멘트풀 양생 후 실시하는 Restrike 단계에서 선단부까지 충분한 에너지가 전달되도록 타격하는 것이 중요하다. 이는 선단지지력이 충분히 발휘되지 못할 경우 총지지력이 과소평가될 수 있기 때문이다. 시간경과에 따른 주면마찰력 및 선단지지력의 분포에 대한 개념도를 Fig. 2에 나타내었다. 시공 초기에는 선단지지력이 주로 발휘되는 반면, 시멘트풀 경화 이후에는 주면마찰력이 증가하고 선단지지력은 상대적으로 감소하는 경향을 보인다. 이러한 현상을 보완하기 위해 EOID의 선단지지력과 Restrike의 주면마찰력을 조합한 수정 동재하지지력의 사용이 제안된 바 있다(Park, 2017; Seo et al., 2020; Cho, 2023). 그러나 일반적인 현장 실무에서는 PDA 측정치를 기준으로 최종 지지력 품질을 확인하므로, 동재하시험 시 주면마찰력과 선단지지력이 최대한 발휘될 수 있도록 적절한 항타조합을 설정하는 것이 중요하다.
2.2 말뚝지지력 예측을 위한 머신러닝 기술 활용
말뚝지지력 예측을 위해 머신러닝 기술을 활용한 연구를 살펴보면, Lee and Lee(1996)는 50개의 정재하시험 데이터를 이용하여 항타말뚝의 지지력을 예측한 인공신경망(ANN) 기반의 초기 연구를 수행하였다. 동재하시험 결과를 이용한 연구로는 Park et al.(2006)이 국내 항타말뚝에 대한 165개의 PDA 데이터 및 CAPWAP 해석결과를 연계한 인공신경망(ANN) 학습을 통해 주면마찰력, 선단지지력 및 총지지력을 개별적으로 예측하는 연구를 수행하였으며, Maizir and Suryanita(2018)는 항타말뚝에 대한 216개의 PDA 데이터를 이용하여 말뚝직경, 말뚝길이, 항타조건 및 PDA 측정치와 관련된 8개의 입력변수를 기반으로 총지지력을 예측하는 인공신경망(ANN) 학습을 수행하였다. 한편, 2,000개 이상의 대규모 데이터셋을 이용한 연구로는 Pham et al.(2020)의 사례가 있다. 이 연구에서는 2,314개의 정재하시험 데이터셋을 이용하여 항타말뚝의 지지력을 머신러닝 기법으로 비교·분석하였으며, 말뚝제원과 지반조건 등 총 10개의 입력변수를 적용하여 인공신경망(ANN)과 Random Forest 모델의 성능을 평가하였다.
항타말뚝에 대해서는 정재하시험 또는 동재하시험을 이용한 머신러닝 연구가 다양하게 진행되어 왔으나, 국내와 일본에서 주로 사용하고 있는 PHC 매입말뚝 공법에 대한 연구는 현재까지 매우 한정적이다. Lee and Chang(2006)은 SIP(Soil-cement Injected Precast pile) 공법으로 시공된 D400 매입말뚝에 대한 168개의 PDA 데이터와 지층정보를 이용하여 인공신경망(ANN) 모델을 구성하고, R2 > 0.7의 결과를 도출하였다. Seo et al.(2025)은 SDA 공법으로 시공된 매입말뚝에 대한 214개의 PDA 데이터를 이용하여 딥러닝을 포함한 머신러닝 예측모델을 구성하였다. 입력변수로는 말뚝직경, 말뚝길이, 최종관입량, 해머무게, 낙하고, 경과시간의 6개 입력변수에 대해 총지지력을 출력변수로 설정하여 예측한 결과, 딥러닝이 가장 우수한 성능을 보인 것으로 보고하였다.
본 연구에서는 매입말뚝의 지지력 데이터에 내재된 복잡하고 비선형적인 관계를 모델링하기 위해 딥러닝을 적용하였다. 딥러닝은 다변량 데이터에서 변수 간의 고차 상호작용을 학습하여 기존의 분석만으로는 파악하기 어려운 패턴을 발견할 수 있으므로, 본 연구는 매입말뚝 데이터셋을 포괄적으로 탐색하고 각 모델의 강점을 결합하여 말뚝지지력을 효과적으로 평가하고 예측하고자 하였다. 이러한 데이터 기반 접근은 기존 지지력 평가방법의 한계를 보완하고, EOID 및 Restrike 단계에서 나타나는 매입말뚝의 고유한 거동특성을 정량적으로 이해하는데 기여한다. 특히 시멘트풀 양생에 따른 시간의존적 지지력 변화를 분석함으로써, 시공단계별 품질관리와 설계·시공 중 의사결정에 활용 가능한 실용적 예측방법을 제시하였다.
3. 분석 방법
3.1 동재하시험
PDA를 이용한 동재하시험은 말뚝지지력을 예측하기 위한 가장 보편적인 품질확인시험이다. 이 시험은 말뚝 두부에 가한 기계적 충격으로 발생한 응력이 말뚝길이를 따라 파동이 전파된다는 원리에 기반한다. 힘–가속도 기록을 이용한 단순화된 모델을 사용하여 지지력을 예측하는 Case 방법이 있는데, 이 방법의 단점은 감쇠계수의 지반저항에 대한 민감도이다. 현장에서 지지력 파악이 가능한 Case 방법은 단순한 수식에 기반한 해석결과이기 때문에 CAPWAP 결과에 비해 신뢰도가 낮은 것으로 알려져 있다. 한편 CAPWAP은 측정된 힘과 속도를 파동방정식 해석과 결합하여 지반저항 또는 지지력을 산정하는 후처리 프로그램으로, 각 타격 이후 파동분석을 활용하여 힘을 계산하고, 계산된 힘은 변형률 게이지로 측정된 힘과 비교된다. CAPWAP은 계산된 힘과 측정된 힘이 거의 일치할 때까지 감쇠 등의 지반변수를 조정하는 반복적 신호매칭을 수행하는데, 이 과정을 통해 주면마찰력과 선단지지력을 분리하여 예측할 수 있는 장점이 있다(Rausche et al., 1985; Lee et al., 1994).
정확한 지지력 예측을 위해서는 적정한 타격에너지로 동재하시험을 수행하는 것이 중요하다. 매입말뚝에 대한 시험 시 해머의 타격에너지가 말뚝 선단부까지 충분히 전달되지 못할 정도로 작으면, 말뚝에 필요한 변형이 유발되지 못해 예측 지지력이 실제보다 작게 산정될 수 있다. 또한 Restrike 단계에서는 EOID 때보다 큰 타격에너지를 작용시켜야 주면마찰력과 선단지지력의 파악이 가능하다. 따라서 드롭해머를 사용하는 경우, 램의 무게와 낙하고의 적절한 선정은 매입말뚝의 지지력 발현 여부를 판단하고 해석의 신뢰도를 확보하는 데 중요한 요소이다.
3.2 딥러닝 데이터셋
딥러닝은 여러 층의 인공신경망을 사용하여 복잡한 패턴과 비선형 관계를 학습하는 심층학습 기법으로, 입력데이터에서 자동으로 특징을 추출하고 이러한 특징을 기반으로 고차원 비선형 함수를 학습한다. 본 연구에서는 현장에서 측정한 동재하시험 결과의 대규모 데이터셋을 이용하여 범용적인 딥러닝 모델을 구성하고자 하였으므로, 데이터셋의 적정 규모를 결정하는 것이 중요하다. 기존 연구문헌에서는 100~200개 내외의 소규모 데이터셋으로 머신러닝을 수행한 사례가 다수 있으나, 샘플 수가 적어 일반화 성능을 확보하는 데 한계가 있다. 또한 500~600개 규모의 중규모 데이터셋도 입력변수와 조건에 대한 포괄적 경험이 부족하여 일반화가 어렵다고 보고되고 있다(Benbouras et al., 2021; Udengaard et al., 2024; Nguyen et al., 2025). 복잡한 신경망에서 소규모 데이터셋은 과적합의 위험이 증가하므로, 소규모 데이터셋은 단순한 모델에 대해서만 안정적인 것으로 인식되고 있다(Pham et al., 2020; Onyelowe, 2025). 특히 말뚝의 지지력과 같이 다양한 지반-구조물 상호작용이 발생하는 모델에서는 소규모 데이터셋으로는 일반화 성능확보가 어렵기 때문에 대규모 데이터셋 확보가 필요할 것으로 판단하였다.
본 연구에서는 딥러닝 모델의 일반화 성능을 확보하고 과적합을 방지하기 위해, 2,000개 이상의 대규모 데이터셋을 구축하여 학습에 적용하였다. 딥러닝은 대용량 데이터를 통해 일반화 능력을 발휘하므로, 충분한 데이터 확보와 함께 전처리, 정규화, 이상치 처리 등의 과정을 수행하여 모델 성능을 향상시킬 수 있다. 데이터셋에 노이즈가 포함될 경우 모델의 성능이 저하될 수 있으나, 대규모 데이터셋을 활용하면 복잡한 모델을 구현할 수 있는 능력을 기반으로 일반화된 성능을 확보할 수 있다.
사용된 데이터는 현장에서 동재하시험 전문가가 수행한 시항타, 재항타 및 품질확인시험 결과로 구성되어 있어, 기본적인 데이터 품질은 확보된 것으로 판단된다. 다만, 본 연구에서 활용된 실제 현장의 동재하시험 결과는 말뚝 손상을 방지하기 위해, 말뚝 본체가 허용하는 최대 항타에너지 이내에서의 결과이므로, CAPWAP 분석으로 산정된 지지력은 일부 과소평가되었을 가능성이 있다.
학습에 사용된 데이터셋은 국내에서 SDA 공법으로 시공된 직경 400~800mm의 매입말뚝에 대해 CAPWAP 분석결과와 항타조건 및 지반조건이 매치된 총 2,457개의 데이터로 구성된다(Table 1). 지반조건은 매립토, 퇴적토, 풍화토, 풍화암 및 연암층으로 구분하였으며, 말뚝 시공조건에 따라 말뚝 주면부 평균 N값은 26에서 44에 해당된다. 전체 데이터의 90%인 2,211개 데이터는 학습 및 검증에 이용하였고, 10%에 해당하는 246개 데이터는 학습 모델에 대한 테스트에 사용하였다.
Table 1.
Data collection for deep learning studies (2,457 total data, 2,211 for training/validation, 246 for testing)
| Site |
Pile diameter (mm) | Pile type |
Number of data | Location |
Average N-value along the pile shaft |
Pile installation and PDA test period | Reference |
| Published data | 400~500 | High | 432 | Various | 26.8 | 1998-2007 | Chai (2007) |
| Site A | 800 | High | 141 | Gyeonggi | 35.5 | 2015-2016 |
Collected data from 9 sites |
| Site B | 800 | High | 115 | Gyeonggi | 35.6 | 2017-2018 | |
| Site C | 600 | Ultra-high | 694 | Gyeonggi | 38.1 | 2020-2021 | |
| Site D | 500 | Ultra-high | 199 | Daejeon | 34.8 | 2021-2022 | |
| Site E | 600 | Ultra-high | 251 | Gyeonggi | 31.9 | 2022-2023 | |
| Site F | 600 | Ultra-high | 477 | Gyeonggi | 30.2 | 2023-2024 | |
| Site G | 600 | High | 62 | Seoul | 42.1 | 2023-2024 | |
| Site H | 500 | High | 21 | Gyeonggi | 44.4 | 2024 | |
| Site I | 600 | Ultra-high | 65 | Incheon | 30.6 | 2025 |
3.3 데이터 전처리 및 특성 구성
본 연구에서는 말뚝의 지지력을 예측하기 위해 말뚝제원, 항타조건, 지반조건 및 PDA 데이터(CAPWAP)를 활용하였다. 데이터 전처리 과정에서는 누락값을 제거하고, 입력변수 간 상호작용을 반영하기 위해 충격에너지(=해머무게×낙하고) 항목을 추가로 정의하였다. 또한 시멘트풀 양생기간의 비선형성과 왜도(Skewness)를 보정하기 위해 로그변환을 수행하였다. 최종 입력변수는 말뚝직경, 말뚝길이, 해머무게, 낙하고, 물시멘트비, 시멘트풀 양생기간, 주면 N값 및 충격에너지의 8개이고, 출력변수는 주면마찰력, 선단지지력 및 총지지력의 3개이다. 모든 입력변수 및 출력변수는 이상치의 영향을 줄이기 위해 Robust Scaler를 활용하여 정규화하였다.
3.4 딥러닝 모델 구조
본 연구에서는 말뚝의 지지력을 구성하는 주요 요소인 주면마찰력과 선단지지력 및 두 값의 합인 총지지력을 동시에 예측하기 위하여 다중출력 회귀(Multi-output regression) 방식의 딥러닝 모델을 적용하였다. 다중 회귀분석을 통해서 말뚝제원, 항타조건, 지반조건 및 경과시간에 따른 시멘트풀의 양생효과를 반영하여 지지력 예측이 가능한 딥러닝 모델을 구성하였다.
딥러닝 모델은 PyTorch 기반으로 구성되었으며, 8개의 입력층은 128차원으로 변환되고, 중간층은 64차원, 그리고 3개의 출력층이 되도록 하였다. 입력치 간의 상호작용을 학습하여 모델이 중요 특성에 더 집중할 수 있도록 유도하는 SEBlock(Squeeze-and-Excitation Block)을 적용하였고, Pre-activation ResBlock(Residual Block)을 이용하여 안정적인 학습을 위한 잔차구조를 구성하였다. Dropout(0.3) 기법을 적용하여 과적합을 방지하였으며, 초기 정보 손실 최소화 및 학습 안정성을 위해 입력부에는 GELU(Gaussian Error Linear Unit)를 사용하고, 심층블록에는 ReLU(Rectified Linear Unit) 활성화 함수를 혼합 적용하였다(Fig. 3).
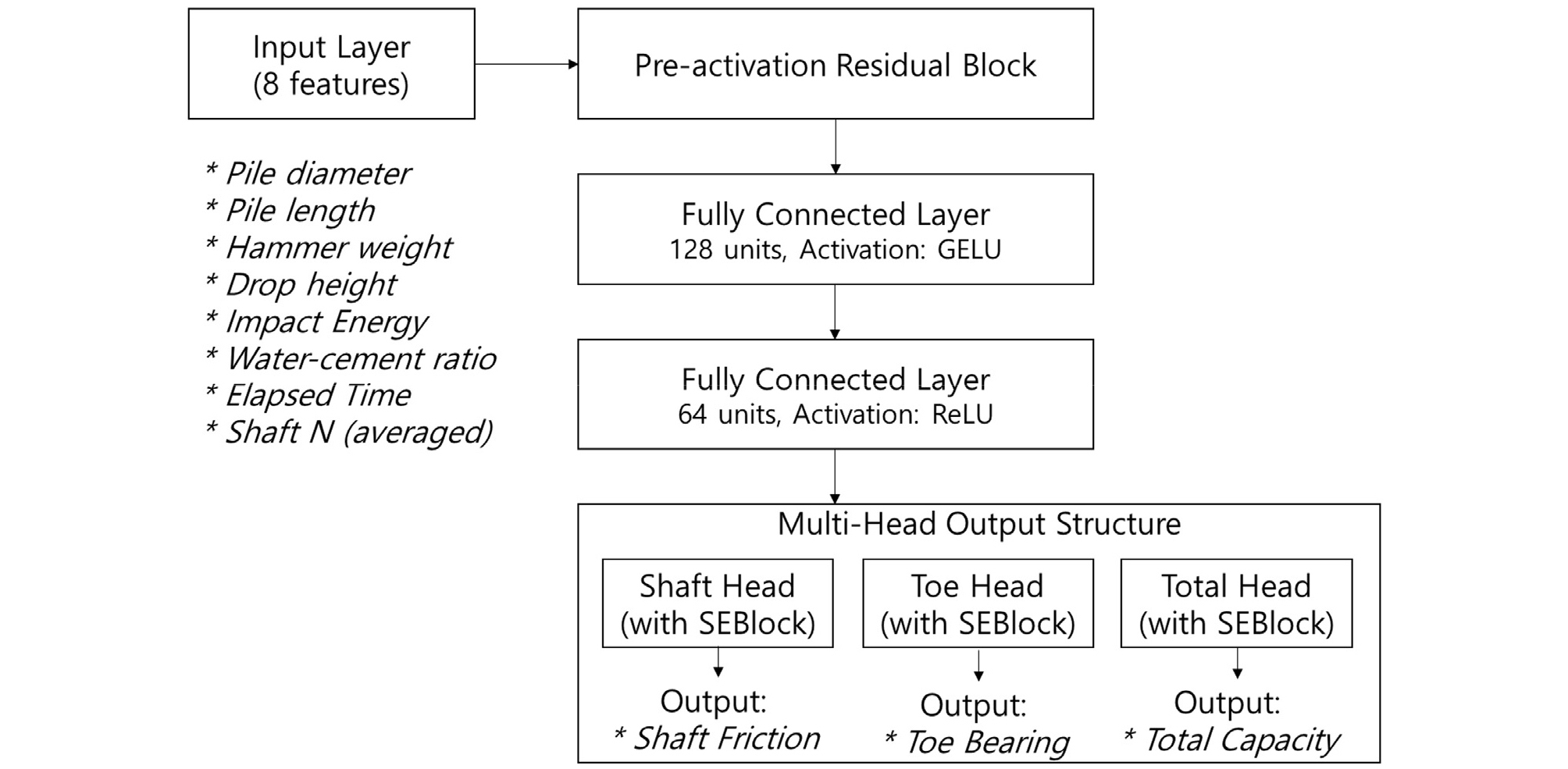
데이터 전처리는 경과시간의 로그변환을 통해 지지력에 대한 단조증가 경향성을 강화하였다. 딥러닝 학습은 모델의 일반화 성능을 평가하고 데이터 분할 편향의 영향을 줄이기 위해 5-Fold 교차검증 방식으로 수행하였으며, 가중 MSE(Mean Squared Error) 손실함수와 Adam optimizer를 적용하였다. 또한 시멘트풀 양생에 따른 지지력의 변화를 파악하기 위해, 경과시간을 0일부터 90일까지 1일 간격으로 변화시키며 주면마찰력, 선단지지력 및 총지지력의 변화를 시각화하였다. 사용 모델에서 출력변수가 3개 이므로, 각 출력에 대한 가중 손실함수는 다음과 같이 정의하였다.
여기서, 는 fold k에 대한 검증 손실값, 는 fold k에 대한 i번째 샘플의 j번째 예측값, 는 i번째 샘플의 j번째 실제값, 는 j번째 출력에 대한 가중치(총지지력에 0.5, 주면마찰력과 선단지지력에 각각 0.25를 부여), n은 배치(batch) 크기를 의미한다.
단일 모델의 예측 편향을 줄이고 일반화 성능을 높이기 위해 교차검증 기반의 앙상블 학습을 수행하였다. 가 작을수록 해당 모델의 가중치는 높게 반영된다. 학습 데이터는 무작위로 5개의 fold로 나누어 각각 훈련과 검증에 활용하였으며, 총 5개의 독립된 모델을 생성하였다. 최종 예측값은 각 모델의 검증 손실값에 역비례하는 가중치를 부여하여 가중 평균 방식으로 앙상블하였다.
여기서, 는 i번째 샘플의 j번째 성분에 대한 앙상블 최종 예측값이다.
4. 분석 결과
4.1 지지력 예측 결과
학습된 모델의 성능은 실제값과 예측값의 산점도를 비교하여 평가하였다(Fig. 4). 모델의 예측 정확도 평가는 결정계수(coefficient of determination, R2)를 이용하였으며, 이는 실제 관측값()과 예측값() 간의 일치 정도를 나타내는 대표적인 회귀성능 지표로 식 (3)과 같이 정의된다.
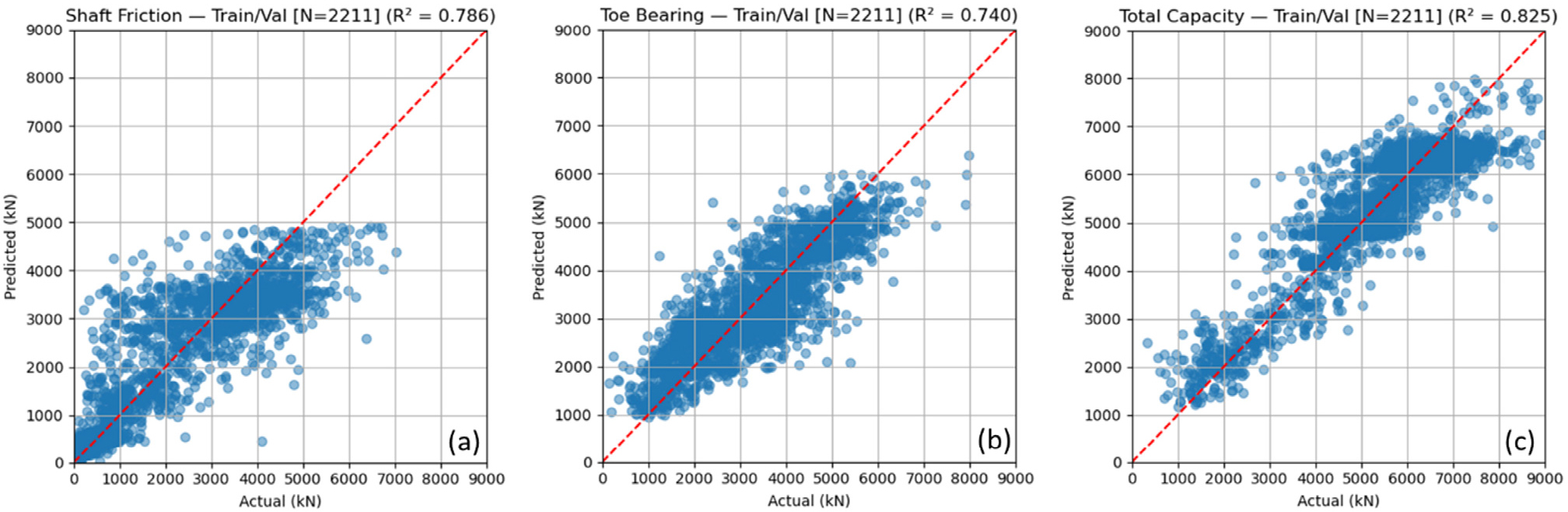
여기서, 는 측정값, 는 예측값, 는 측정값의 평균을 나타내며, R2 값이 1에 가까울수록 모델이 관측 데이터를 잘 설명함을 의미한다. 결정계수(R2)는 예측의 절대적 정확도를 직접적으로 나타내는 지표는 아니지만, 모델이 실측값의 변동성과 경향을 설명하는 정도를 평가하는 유용한 지표로 활용된다. 일반적으로 R2 값이 0.8 이상이면 높은 설명력을 갖는 것으로 간주되며, 지반공학과 같이 현장자료의 불확실성이 큰 분야에서는 0.7 내외의 값도 신뢰 가능한 수준으로 평가된다(Puri et al., 2018).
각각의 출력값에 대해 결정계수(R2)를 산출하였으며, 대각선(1:1) 기준선과 함께 시각화함으로써 예측의 분포와 오차를 직관적으로 파악할 수 있도록 하였다. 개발된 모델의 예측 정확도는 각각 주면마찰력 R2=0.786, 선단지지력 R2=0.740, 총지지력 R2=0.825로 나타났다. 가중치 산정 시에는 예측치의 중요도를 반영하여, 주면마찰력=0.25, 선단지지력=0.25, 총지지력=0.5로 가중치를 적용하였는데, 이는 총지지력의 중요도를 높여 주면마찰력과 선단지지력의 정확도가 상대적으로 낮게 평가된 결과로 해석된다.
4.2 시멘트풀 양생에 따른 지지력 변화
매입말뚝의 지지력은 시멘트풀의 양생기간에 따라 증가 후 수렴하는 경향을 보이므로, 이를 시각적으로 분석하기 위해 경과일을 1일 간격으로 변화시켜 예측 곡선을 생성하였다. 이때 경과일은 28일 이후 일정한 지지력으로 고정된다는 가정을 반영하였다. 특히 말뚝직경이 0.4m에서 0.8m까지 변화하는 조건에 대해 시간-지지력 곡선을 비교함으로써 말뚝직경의 변화가 지지력에 미치는 영향을 정량적으로 분석할 수 있다.
Fig. 5는 임의의 조건(말뚝길이=25m, 주면 평균 N값=30, 해머무게=68.6kN, 낙하고=2m)에서 시멘트풀 양생에 따른 지지력 변화를 말뚝직경별로 나타낸 것이다. 시간경과에 따라 주면마찰력이 점진적으로 증가하며, 특히 7일에서 14일 사이에 최대 지지력에 도달하는 것으로 확인된다. 반면, 선단지지력은 주면마찰력의 증가에 따라 오히려 감소하는 경향을 보인다. D400의 총지지력은 두 지지력 성분이 서로 상쇄되어, 시간경과에 따라 총지지력의 변화가 상대적으로 크지 않은 것으로 나타났다(Fig. 5(a)). 주면마찰력의 시간경과에 따른 증가량은 D600이 다른 직경에 비해 특히 크게 나타나는데, 설계하중이 큰 초고강도 말뚝의 데이터가 D600에 상대적으로 집중되어 발생한 결과로 판단된다(Fig. 5(c)). 향후 다양한 직경의 초고강도 말뚝에 대한 데이터를 추가하여 분석함으로써, 이러한 현상에 대한 보다 명확한 규명이 가능할 것으로 판단된다.

4.3 SHAP(Shapley Additive exPlanations) 분석 결과
공학적 문제에서는 물리적 특성에 기반한 상관관계가 중요한데, 딥러닝 모델을 통한 결과는 인과관계에 대한 해석이 어렵기 때문에 결과의 신뢰도를 평가하기가 어렵다. 이를 보완하여 모델의 예측결과에 대한 해석 가능성을 확보하기 위해 SHAP(Shapley Additive exPlanations) 기법을 도입하였다. SHAP는 협력게임이론(Cooperative game theory)의 Shapley value에 기반한 방법으로, 각 입력변수를 게임 참여자로 간주하고 모든 가능한 변수조합에 대해 각 변수가 예측값에 기여하는 공정한 분배량을 계산한다. 수학적으로 모델의 예측값은 평균 예측값과 각 변수의 기여도(Sharpley value)의 합으로 분해할 수 있으며, 다음 식 (4)와 같이 표현된다.
여기서, 는 모델의 예측값, 는 전체 데이터에 대한 평균 예측값, M은 모델에 사용된 입력변수(input features)의 총 개수, 는 i번째 입력변수가 예측 결과에 기여한 정도를 나타낸다. 는 모든 변수조합에 대해 평균화된 한계 기여도로 정의되며, 이러한 방식은 변수의 순서나 상호작용에 관계없이 각 특성의 공정한 영향도를 계산할 수 있다는 이론적 강점을 가진다(Lundberg and Lee, 2017).
SHAP 값은 각 특성이 예측값에 미치는 영향의 방향과 크기를 시각화하여 변수의 중요도와 영향력을 정량적·시각적으로 해석할 수 있으므로, 모델의 신뢰성을 높이고 실무적 변수해석을 가능하게 한다(Khan et al., 2025; Li et al., 2025; Seo et al., 2025). 본 연구에서는 SHAP 분석을 통해 단순한 모델 정확도 향상뿐 아니라 물리적 해석력을 확보하고, 말뚝설계 및 시공관리 시 중요변수에 대한 우선순위를 판단하고자 하였다.
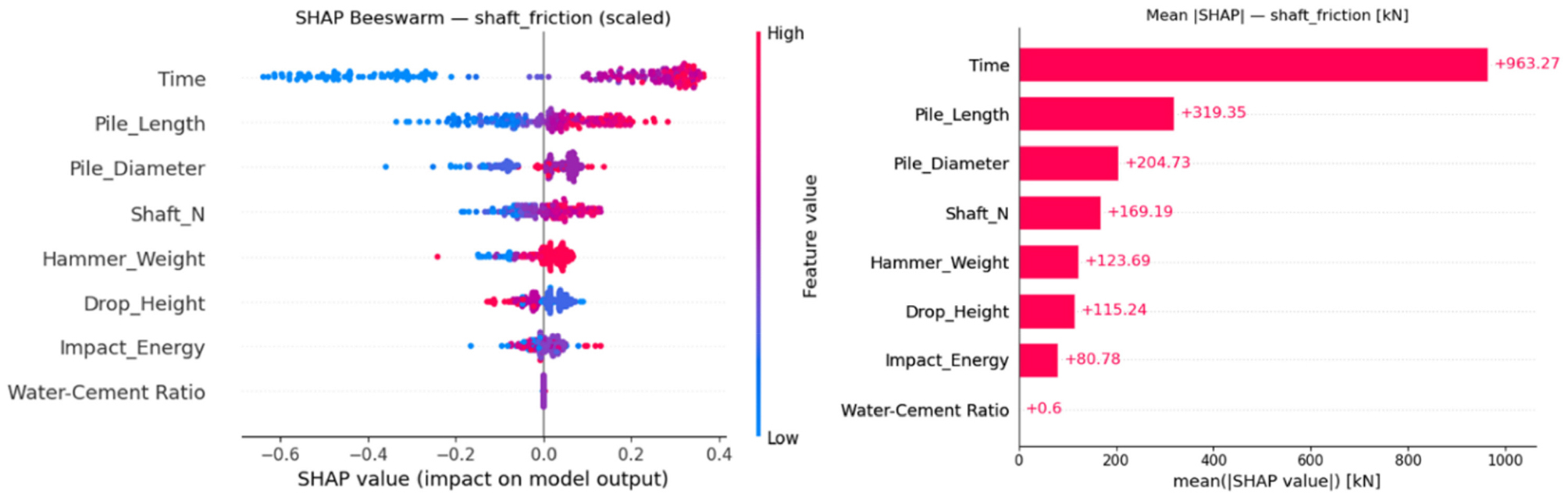
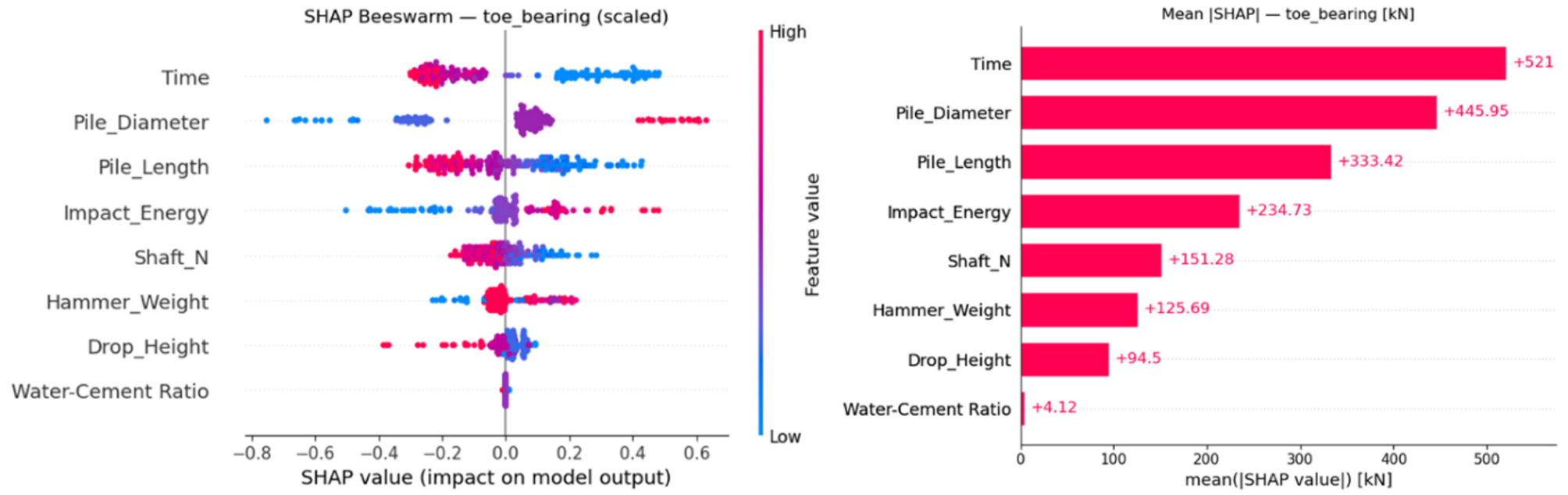
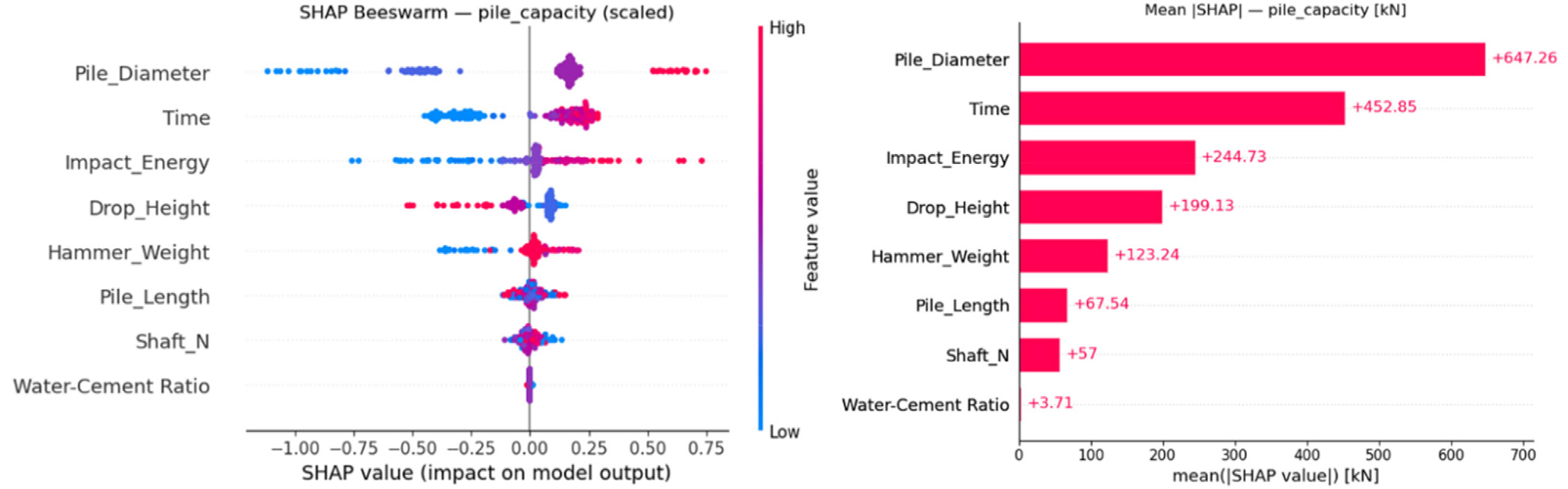
Figs. 6~8은 SHAP 분석결과를 나타낸 것이다. 좌측의 벌떼형 분포도(Beeswarm plot)에서 각 점은 하나의 실제 샘플에 대한 SHAP 값을 의미하며, 빨간색은 해당 특성값이 큰 샘플, 파란색은 값이 작은 샘플에 해당된다. X축은 해당 입력값이 예측결과에 기여한 정도를 나타낸다. SHAP 값이 양수인 경우에는 변수값이 클수록 지지력 예측값을 증가시키는 효과가 있고, SHAP 값이 음수인 경우에는 반대의 효과를 나타낸다. 우측의 막대그래프는 지지력(kN) 단위로 정량화하여 표현한 것으로, 각 변수의 상대적 영향도를 직관적으로 비교할 수 있다. 주면마찰력은 경과시간의 영향이 가장 크게 나타났고, 말뚝길이가 그 다음으로 영향이 큰 것으로 평가되었다(Fig. 6). 선단지지력은 경과시간, 말뚝직경, 말뚝길이 순으로 영향이 큰 것으로 분석되었다(Fig. 7). 총지지력의 경우 말뚝직경과 경과시간이 가장 중요한 인자로 평가되었다(Fig. 8). 이와 같이 SHAP 분석을 통해 지지력 발현에 영향을 미치는 주요 인자를 확인할 수 있으며, 설계요소인 말뚝직경을 제외하면 시공요소 중에서는 경과시간이 가장 중요한 인자인 것으로 평가되었다.
4.4 매입말뚝 최대 지지력 확인을 위한 항타조건 결정
매입말뚝에 대한 품질확인은 시멘트풀의 경화 후 적정 기간에 설계 지지력의 확보여부를 Restrike 동재하시험을 통해서 판단하게 된다. 이때 요구 지지력을 확보하지 못할 경우 재시험 또는 보강말뚝 시공이 필요하므로, 불필요한 시행착오를 방지하기 위해서는 현장 시공관리자의 경험이 매우 중요하다. 딥러닝 모델로 구성한 말뚝지지력 예측모델은 시공관리자의 경험을 보완하여 지지력 판단에 도움을 제공할 수 있다. 개발된 딥러닝 모델을 이용하면 말뚝제원, 항타조건, 지반조건, 물시멘트비 및 경과시간을 고려하여 말뚝의 시공품질을 예측할 수 있으므로, 시공된 말뚝의 품질확인시험을 위한 적정 시험시기와 항타조건에 대한 판단이 가능하다.
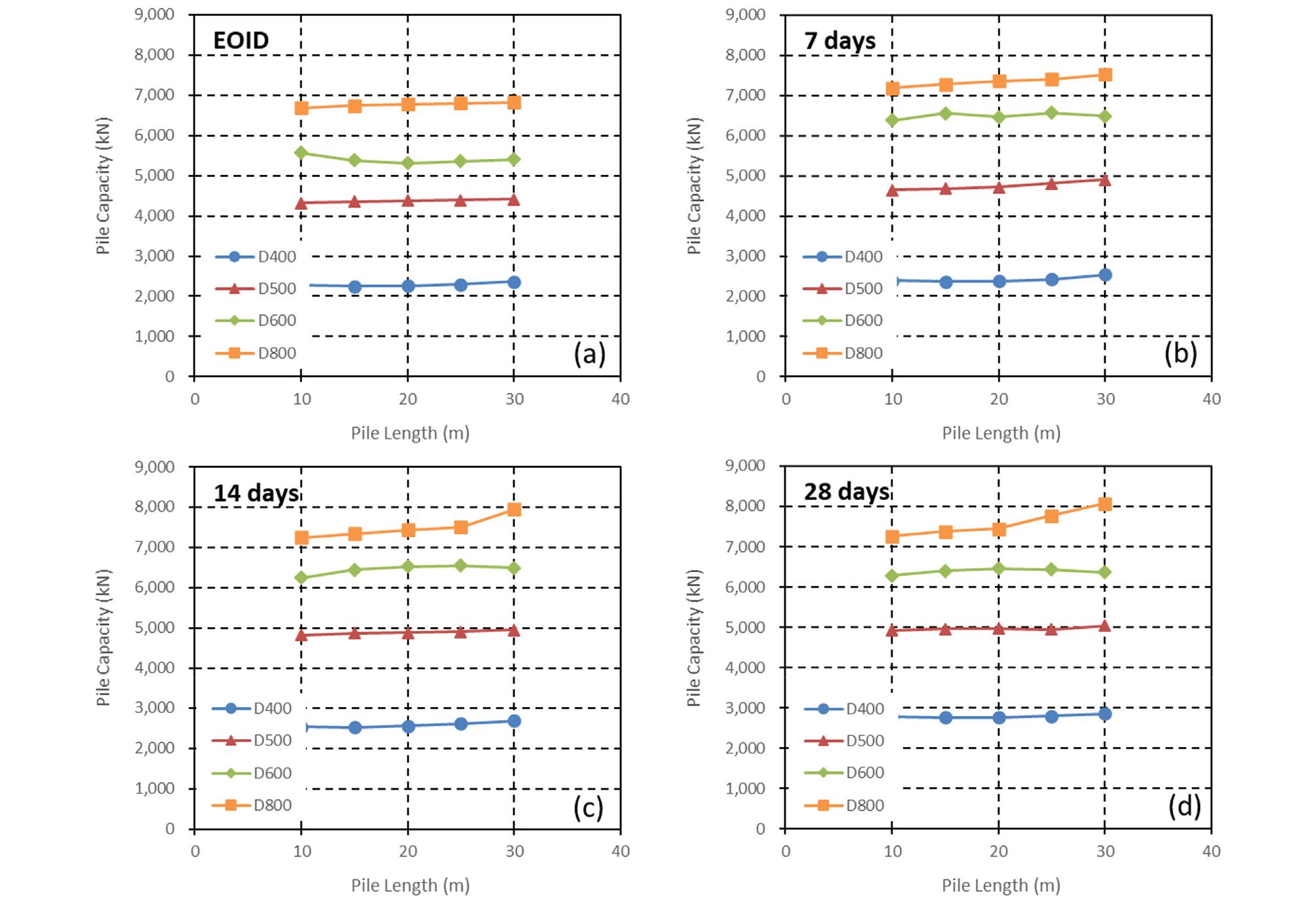
Fig. 9는 동일 지반조건(주면 평균 N값=30)에서 말뚝직경, 말뚝길이, 경과시간에 따라 최대 지지력이 발휘되도록 결정한 최적의 항타조합(해머무게 5~7톤, 낙하고 1~3m)에 따른 지지력을 나타낸 것이다. 직경별 항타조합은 실측 항타에너지의 중앙 90% 범위(평균 ± 1.645×표준편차)에 해당하는 해머무게와 낙하고를 채택하여 결과에 반영하였다. Fig. 5의 말뚝직경별 시간경과에 따른 지지력 변화에서도 나타나듯이, D400은 시간경과와 말뚝길이에 따른 지지력 증가는 미미하나, D500, D600 및 D800의 결과에서는 직경이 클수록 지지력 증가가 뚜렷하게 나타났다. 이는 말뚝직경과 근입심도 증가로 인해 동재하시험 시 작용하는 항타에너지가 커져, 지지력 예측을 위한 측정효율이 향상되기 때문인 것으로 판단된다.
4.5 매입말뚝 시공관리 Tool 개발 및 현장 활용
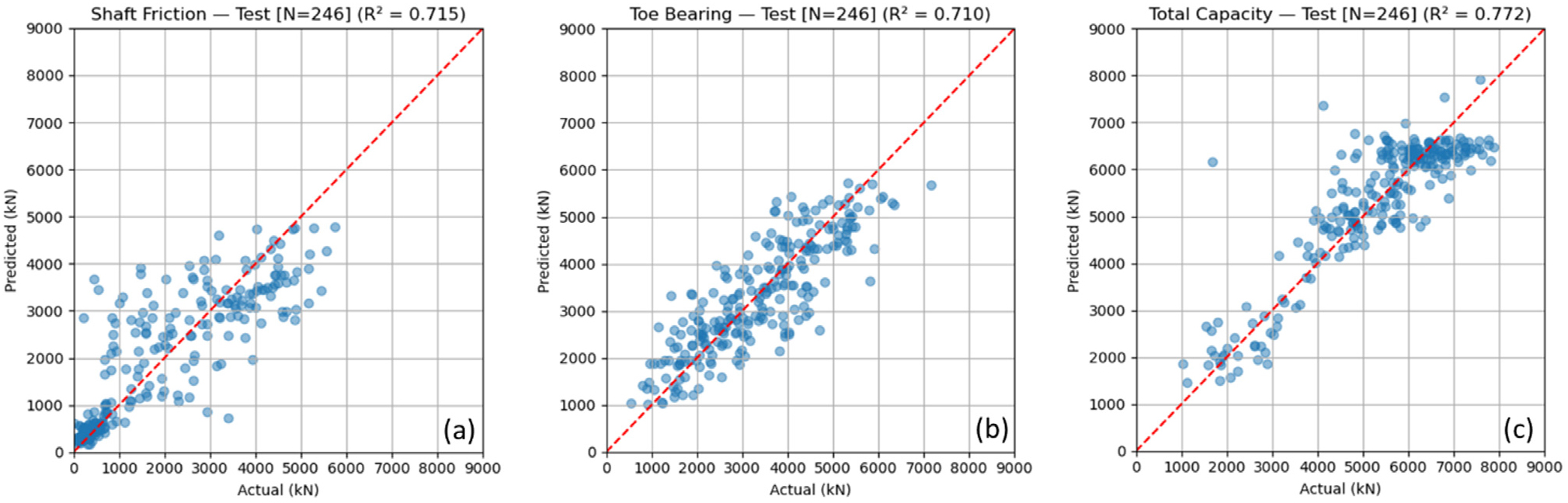
학습된 딥러닝 모델에 대한 성능을 테스트하기 위해, 학습에 사용되지 않은 246개 데이터(전체 데이터의 10%)를 대상으로 분석을 수행하였으며, 그 결과를 Fig. 10에 나타냈다. 교차검증을 통해 평가된 총지지력의 결정계수(R2)는 0.825로 나타났으나, 독립된 테스트 데이터셋에서는 R2=0.772로 약 0.05 낮은 값을 보였다. 이러한 차이는 교차검증 과정에서 모델 구조나 하이퍼파라미터 선택 시 동일 데이터가 일부 중복 사용되어 통계적으로 낙관적 편향(Optimistic bias)이 포함될 수 있기 때문이다. 반면 테스트 데이터셋은 모델 선택 과정과 완전히 분리되어 있어 이러한 편향이 제거된다. 따라서 시험 집합에서의 결정계수가 다소 낮게 나타난 것은 자연스러운 결과로 해석되며, 이는 현장 잡음이 큰 데이터 특성과 회귀문제의 복잡성을 고려할 때 허용 가능한 일반화 오차 범위에 내에 있는 것으로 판단된다.
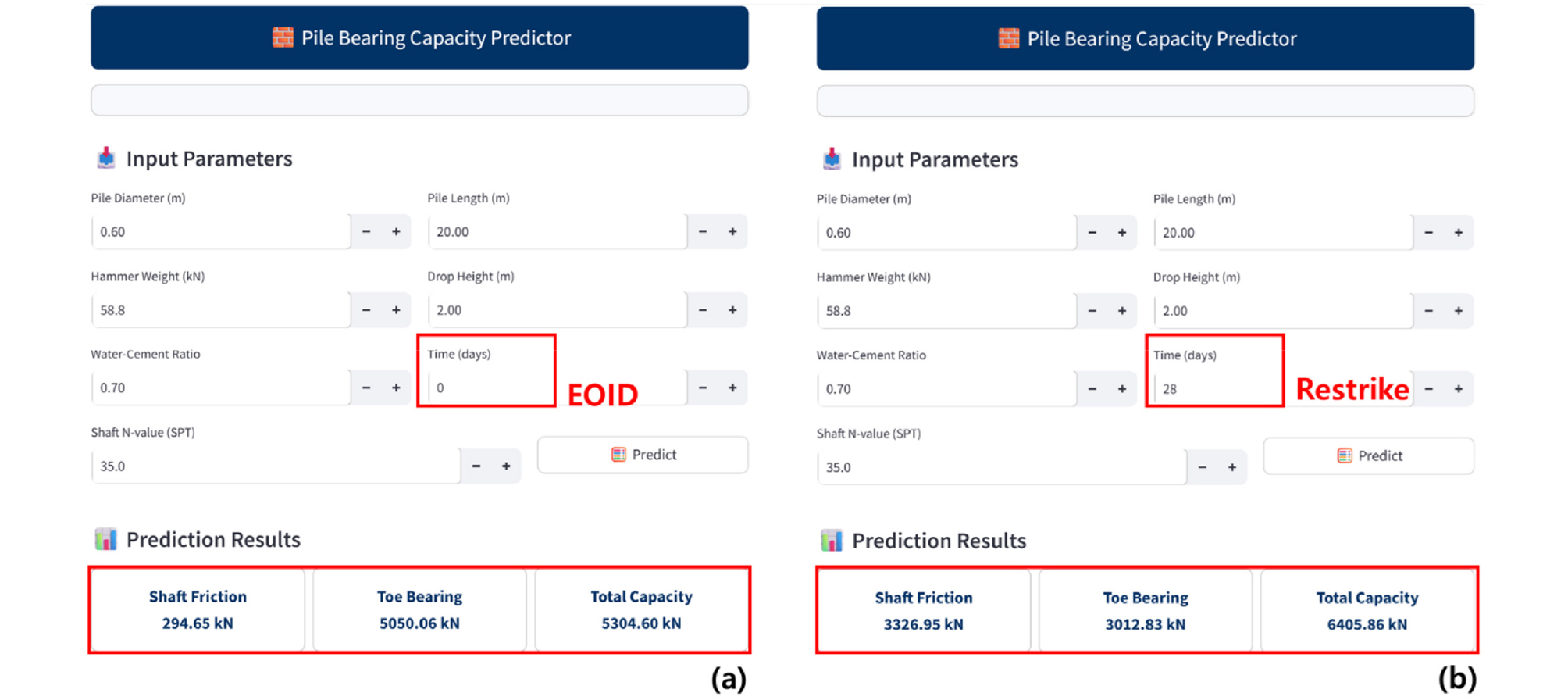
이러한 과정을 통해 개발된 딥러닝 모델은 매입말뚝 지지력 예측을 위한 일반화 성능을 확보하였으며, 이를 현장 시공관리자가 보다 용이하게 활용할 수 있도록 웹기반 GUI(Graphical User Interface) 형태의 매입말뚝 지지력 예측 Tool을 제작하였다(Fig. 11). 시공관리자는 본 GUI에 말뚝의 기본제원, 해머무게, 낙하고, 시멘트풀의 물시멘트비, 경과시간, 그리고 주면 평균 N값을 입력하면, 현재 시공단계에서의 동재하시험 예측치(주면마찰력, 선단지지력, 총지지력)를 추정할 수 있다. 예측된 지지력은 설계 지지력과의 비교를 통해 시공단계별 품질확인시험(PDA) 수행 시점이나 보강말뚝의 시공 필요 여부를 판단하는 데 유용한 정보를 제공한다. Fig. 11은 임의 조건에서 EOID 단계와 Restrike 단계의 지지력 추정 예시를 보여준다.
5. 결 론
본 연구는 SDA 공법으로 시공된 PHC 매입말뚝의 지지력을 주면마찰력, 선단지지력 및 총지지력으로 분리하여 예측하는 딥러닝 기반 모델을 개발하였으며, 시멘트풀 양생에 따른 지지력의 시간의존적 변화를 반영하도록 구성하였다. 제안된 모델은 다양한 시공조건에서 안정적인 예측 결과를 보였으며, 딥러닝 모델 개발 및 비교·분석을 통해 도출한 결론은 다음과 같다.
(1) 총 2,457개의 대규모 데이터셋을 이용하여 학습한 딥러닝 모델을 통해 매입말뚝 지지력의 복잡한 비선형 거동을 주면마찰력, 선단지지력 및 총지지력으로 구분하여 예측하였다. 모델은 결정계수(R2) 0.7~0.8 수준의 예측 성능을 보였으며, 매입말뚝–지반–시멘트풀의 상호작용을 반영하여 지지력을 신속하고 안정적으로 산정할 수 있음을 확인하였다.
(2) 딥러닝 모델을 통해 시멘트풀 경화에 따른 시간경과별 지지력 변화를 정량적으로 예측하였다. 이를 통해 EOID 및 Restrike 단계별 시공품질관리의 실질적인 솔루션을 제공하고, 각 시공단계에서 말뚝성능을 체계적으로 관리할 수 있게 되었다.
(3) SHAP 분석을 적용하여 입력변수의 기여도를 정량적으로 평가하고 시각화함으로써, 지지력 발현에 미치는 주요 인자를 도출하였다. 지지력 성분별로 중요 인자는 상이하나, 총지지력에 대해서는 말뚝직경과 경과시간이 가장 지배적인 요인으로 나타났다.
(4) 제안된 모델은 해머무게, 낙하고, 경과시간과 같은 시공관리 요소를 통합적으로 고려할 수 있어, 현장 실무자가 매입말뚝의 지지력을 사전에 예측하고 초기 항타조건 및 시험시기를 합리적으로 결정하는데 활용할 수 있다. 이를 통해 경험적 방법에 대한 의존도를 낮추고, 시공품질관리 및 의사결정의 정밀성을 향상시킬 수 있다.
종합하면, 본 연구의 딥러닝 기반 예측모델은 비선형·다차원적 특성을 갖는 매입말뚝 지지력 예측 문제를 효율적으로 해결한 사례로서, 경과시간에 따른 지지력 변화를 반영할 수 있다는 점에서 실무 적용성이 높다. 향후 데이터셋의 확충과 모델 구조의 고도화를 통해 매입말뚝 기초의 복합적 공학 문제에 대한 보다 정교한 해석 및 예측이 가능할 것으로 기대된다.
