

1. 서 론
2. 데이터베이스와 모델 학습
2.1 하수관 및 지반함몰 데이터베이스
2.2 모델 학습
2.3 모델 성능 평가 지표
3. 모델 학습 과정 및 결과
3.1 하이퍼파라미터 튜닝
3.2 불균형 데이터 처리 효과
4. 결 론
1. 서 론
도심지 지반함몰은 도로 및 도시 기반시설의 기능 저하를 넘어 시민 안전을 위협할 수 있는 대표적인 지반재해로, 최근 국내외 여러 대도시에서 지속적으로 보고되고 있다. 특히 비석회암 지역의 도심지에서는 자연적 용식 작용보다는 지하 매설물의 손상에 의해 발생하는 인위적 지반함몰이 주된 유형으로 나타나며, 이 중 하수관 결함으로 인한 토사 유실과 공동 형성이 주요 발생 원인으로 지적되고 있다(Kuwano et al., 2010; Indiketiya et al., 2017). 이러한 지반함몰은 사전 징후가 미약한 상태에서 갑작스럽게 발생하는 경우가 많아 교통사고, 인명 피해 및 사회·경제적 손실을 초래할 가능성이 크다. 따라서 도심지 지반함몰 발생 가능성을 사전에 평가하고, 위험 구간을 선별적으로 관리할 수 있는 예측 기술의 중요성이 점차 강조되고 있다.
하수관 손상에 의해 유발되는 지반함몰은 강우 시 하수관 내부와 외부의 수리적 조건 변화로 인해 토사가 반복적으로 유출되면서 공동이 점진적으로 성장하고, 최종적으로 상부 지반이 붕괴되는 과정을 통해 발생한다(Rogers, 1986; Guo et al., 2013). 이를 예방하기 위해 지표투과레이더(GPR), 전기비저항 탐사 등 다양한 지반 물리탐사 기법이 활용되고 있으나, 도심지 전역에 광범위하게 매설된 하수관을 대상으로 전수 조사를 수행하기에는 비용과 시간 측면에서 현실적인 제약이 존재한다(Cardarelli et al., 2013). 이에 따라 하수관의 속성 정보와 지반함몰 발생 이력을 활용하여 위험도를 사전에 평가하고, 탐사 및 정비 우선순위를 합리적으로 설정할 수 있는 데이터 기반 접근 방법의 활용이 이 대안으로 제시되고 있다.
하수관 기반 지반함몰 위험도 평가를 위해 통계적 기법과 기계학습을 활용한 연구가 점진적으로 수행되어 왔다(Kim et al., 2018; Park et al., 2024). 하수관의 사용년수, 길이, 매립심도, 관경, 경사 등은 비교적 쉽게 확보 가능한 정보로, 도시 단위에서 일관된 데이터베이스 구축이 가능하다는 장점이 있다. 그러나 실제 지반함몰 발생 사례는 전체 하수관 대비 극히 일부에 불과하며, 대부분의 하수관은 지반함몰과 직접적인 관련이 없는 것으로 분류된다. 이와 같이 특정 사건의 발생 여부가 한쪽으로 크게 치우친 데이터 분포는 기계학습 분야에서 클래스 불균형 문제(class imbalance problem)로 정의되며, 이러한 클래스 불균형 문제는 예측 모델의 학습 과정과 성능 평가에 큰 영향을 미치는 것으로 알려져 있다.
최근 기계학습 분야에서는 이러한 불균형 데이터 문제를 해결하기 위한 다양한 기법이 제안되고 있다. 대표적인 접근 방식으로는 데이터 수준에서 학습 데이터의 클래스 분포를 조정하는 방법이 있으며, random oversampling, random undersampling, 그리고 SMOTE(Synthetic Minority Over-sampling Technique) 등이 널리 활용되고 있다(He and Garcia, 2009; Chen et al., 2024). Random oversampling은 소수 클래스 샘플을 단순 복제하여 클래스 불균형을 완화하는 방식이며, random undersampling은 다수 클래스 샘플을 일부 제거함으로써 데이터 분포를 조정한다. 한편, SMOTE는 소수 클래스 샘플 간의 특성 공간 보간을 통해 새로운 합성 데이터를 생성함으로써, 단순 복제 방식에 비해 과적합 위험을 완화할 수 있는 장점을 가진다(Chawla et al., 2002). 이러한 데이터 수준 기법들은 산사태, 지반침하 등 희귀 지반재해 예측 문제에서도 예측 성능 향상에 기여한 사례가 보고되고 있다(Yoon, 2023; Min et al., 2023; Song et al., 2023). 다만, 각 기법은 데이터 분포 왜곡, 정보 손실, 또는 합성 표본의 물리적 타당성 부족과 같은 한계를 동시에 내포하고 있어, 문제 특성에 따라 적용 효과가 상이할 수 있음이 지적되고 있다(Krawczyk, 2016).
본 연구에서는 하수관 손상에 의해 유발되는 지반함몰 예측 문제를 극단적인 불균형 데이터 분류 문제로 재정의하고, 이를 해결하기 위한 예측 모델을 제안하고자 한다. 이를 위해 하수관 속성 정보와 지반함몰 발생 이력을 다양한 불균형 데이터 처리 기법(random undersampling, random oversampling, SMOTE)을 적용하고, XGBoost(eXtreme Gradient Boosting) 알고리즘을 활용하여 지반함몰 발생 예측 모델의 성능 변화를 체계적으로 분석하였다. XGBoost는 다수의 결정트리를 순차적으로 학습시키는 부스팅(boosting) 기반 기계학습 알고리즘으로, 이전 단계에서 오분류된 샘플에 가중치를 부여하여 반복적으로 모델을 개선함으로써 복잡한 비선형 관계를 효과적으로 학습할 수 있는 특징을 가진다(Friedman, 2001). 본 연구에서는 극단적인 클래스 불균형 환경에서도 안정적인 예측 성능을 확보하고, 이후 불균형 데이터 처리 기법의 효과를 비교·분석하기 위한 기준 모델로서 XGBoost를 활용하였다. 또한, 단순한 전체 예측 정확도 향상이 아니라, 재현율(Recall)과 PR-AUC(Precision Recall-Area Under the Curve)을 중심으로 모델의 예측 특성을 분석함으로써, 도심지 지반재해 관리 및 하수관 유지관리 의사결정에 대한 실질적인 활용 가능성을 검토하고자 한다.
본 연구의 결과는 하수관 기반 지반함몰 위험도 평가의 신뢰성을 향상시키고, 제한된 자원을 효율적으로 활용하기 위한 지하공동 탐사 및 하수관 정비 우선순위 설정에 기초 자료로 활용될 수 있을 것으로 기대된다.
2. 데이터베이스와 모델 학습
2.1 하수관 및 지반함몰 데이터베이스
본 연구에서는 하수관 손상에 따른 지반함몰 발생 예측을 위하여, 대도시 지역에서 구축된 하수관 속성 정보와 지반함몰 발생 이력 데이터를 통합한 데이터베이스를 활용하였다(Kim et al., 2018). 연구 대상 지역은 대한민국 서울특별시 전역으로, 하수관 밀도가 높고 지반함몰 발생 사례가 다수 보고된 대표적인 도시 지역이다.
하수관 속성 정보는 서울특별시에서 구축·관리 중인 하수도 관리 전산시스템으로부터 취득하였다. 해당 시스템은 서울시 내 총 37만여 개의 하수관의 위치 및 제원 정보를 GIS 기반으로 구축하고 있다. 본 연구에서는 지반함몰 위험도 평가에 영향을 미칠 가능성이 높은 7개의 하수관 속성을 최종 입력 변수(설명 변수)로 선정하였다. 이 중 연속형 변수로는 하수관의 길이, 관경, 매설 심도, 해발고도, 관로 구배, 설치 후 사용 연수 등이 포함되며, 범주형 변수로는 하수관의 재질을 사용하였다. 선정된 변수들은 하수관의 구조적 특성, 지반과의 상호작용 조건, 그리고 장기 사용에 따른 열화 특성을 종합적으로 반영할 수 있도록 구성되었다. 입력변수 값에 결측치가 존재하거나 물리적으로 해석이 어려운 이상값을 포함한 하수관은 분석에서 제외하였으며, 최종적으로 216,188개의 하수관 데이터가 분석에 사용되었다.
지반함몰 발생 이력은 서울특별시 전역에서 보고된 지반함몰 사례 중, 현장 조사 및 행정 기록을 통해 하수관 손상과의 인과관계가 확인된 사례를 제공받아 활용하였다. 각 지반함몰 사례에 대해서는 발생 위치, 발생 시기, 규모 등에 대한 정보가 포함되어 있으며, 본 연구에서는 총 1,173건의 하수관 손상 유발 지반함몰 사례를 활용하였다. 지반함몰 발생 여부를 이진 반응변수(출력변수)로 설정하고 출력값을 할당하기 위해 지반함몰 발생을 유발한 하수관을 식별하는 작업을 수행하였다. 지반함몰 발생 위치와 하수관 위치 정보를 동일한 좌표 체계에서 비교하기 위하여, 도로명 주소로 기록된 지반함몰 발생 위치를 하수관 데이터와 동일한 좌표계(Transverse Mercator)로 변환하였다. 변환된 지반함몰 발생 위치를 하수관 GIS 데이터와 함께 도시한 후, 각 지반함몰 발생 지점으로부터 가장 인접한 하수관을 해당 지반함몰을 유발한 하수관으로 가정하였다. 다만, 지반함몰 발생 위치 주변에 다수의 하수관이 밀집되어 있어 단일 하수관을 특정하기 어려운 경우에는 매칭의 불확실성이 크다고 판단하여 해당 사례를 분석 대상에서 제외하였다.
이와 같은 절차를 통해 지반함몰 발생과 직접적으로 연관된 하수관 442개를 양성(발생) 사례로 정의하였으며, 나머지 215,746개 하수관은 음성(비발생) 사례로 분류하였다. 결과적으로 본 연구에서 사용된 전체 데이터는 극단적인 불균형 특성을 가지며, 지반함몰 발생 사례는 전체 하수관 대비 약 0.2% 수준에 불과하다. 즉, 지반함몰 발생 사례는 전체 데이터에서 극히 낮은 비율을 차지하고 있으며, 본 연구에서 다루는 지반함몰 예측 문제는 전형적인 희귀 사건(rare event) 분류 문제의 특성을 갖는다. 이러한 극단적인 클래스 불균형은 모델 학습 과정에서 다수 클래스에 대한 편향을 유발할 가능성이 높으며, 단순한 정확도 기반의 모델 학습 및 평가는 실제 지반함몰 발생 가능성을 충분히 반영하지 못할 수 있다.
2.2 모델 학습
본 연구에서는 하수관 손상에 따른 지반함몰 발생 예측을 위한 기본 분류 모델로 XGBoost 알고리즘을 사용하였다. XGBoost는 손실 함수 수준에서 클래스 불균형을 고려할 수 있으며, 정규화 항과 효율적인 트리 분할 전략을 통해 과적합을 억제하면서도 대규모 데이터에 대해 안정적인 학습과 우수한 예측 성능을 제공하는 것으로 보고되고 있다(Chen and Guestrin, 2016). 최근에는 위험도 평가 및 재해 예측 분야에서도 XGBoost가 불균형 데이터 환경에서 높은 재현 성능과 전반적인 예측 성능을 보인다는 연구 결과가 다수 제시되고 있어(Velarde et al., 2024), 본 연구의 문제 설정에 적합한 기본 분류 알고리즘으로 판단하였다.
불균형 데이터 처리 기법의 효과를 정량적으로 평가하기 위하여, 본 연구에서는 원본 학습 데이터 분포를 그대로 사용하여 학습한 XGBoost 모델을 기본 모델(baseline model)로 설정하였다. 이후 동일한 모델 구조와 하이퍼파라미터 조건을 유지한 상태에서, 불균형 데이터 처리 기법만을 달리 적용하여 학습한 모델의 성능을 기본 모델과 비교함으로써, 샘플링 기법 자체의 순수한 효과를 평가하고자 하였다.
불균형 데이터 처리 기법으로는 random undersampling, random oversampling, SMOTE의 세 가지 방법을 고려하였다. Random undersampling은 다수 클래스 표본을 무작위로 제거하여 클래스 비율을 조정하는 방법으로, 계산 효율이 높다는 장점이 있으나 다수 클래스의 분포 정보가 손실될 수 있다. Random oversampling은 소수 클래스 표본을 단순 복제하여 클래스 비율을 조정하는 방법으로, 데이터 손실 없이 소수 클래스의 영향력을 확대할 수 있다는 장점이 있다. SMOTE는 소수 클래스 표본 간의 선형 보간을 통해 합성 표본을 생성함으로써, 단순 복제에 따른 과적합 가능성을 완화하고자 제안된 oversampling 기법이다. 본 연구에서는 이 세 가지 방법을 모두 포함하여, 불균형 데이터 처리 방식에 따른 예측 성능 차이를 체계적으로 비교하였다.
또한 불균형 데이터 처리 기법의 효과는 클래스 비율 설정에 따라 달라질 수 있으므로, 본 연구에서는 소수 클래스와 다수 클래스의 표본 비율을 1:1, 1:5, 1:10, 1:20, 1:50의 다섯 가지 수준으로 설정하였다. 이를 통해 random undersampling, random oversampling, SMOTE의 세 가지 처리 방법과 다섯 가지 클래스 비율을 조합한 총 15가지 실험 조건을 구성하였다. Random undersampling의 경우 소수 클래스 표본 수를 유지한 채 다수 클래스 표본 수를 단계적으로 축소하였으며, random oversampling과 SMOTE는 다수 클래스 표본 수를 유지한 상태에서 소수 클래스 표본을 단계적으로 증강하였다. 각 실험 조건에서의 학습 데이터 구성은 Table 1에 요약하여 제시하였다.
Table 1.
Summary of imbalanced dataset handling strategies and training data composition
모든 불균형 데이터 처리 기법은 학습 데이터에만 적용하였으며, 테스트 데이터는 원본 클래스 분포를 유지한 상태에서 모델 성능을 평가하였다. 이를 통해 데이터 누수를 방지하고, 서로 다른 샘플링 기법 및 클래스 비율 설정에 따른 예측 성능을 공정하게 비교할 수 있도록 하였다.
2.3 모델 성능 평가 지표
불균형 이진 분류 데이터 하에서는 전체 분류 정확도(accuracy)가 다수 클래스에 의해 과대평가될 가능성이 높으며, 실제로 지반함몰 발생 사례에 대한 예측 성능을 적절히 반영하지 못할 수 있다. 예를 들어, 전체 관측 지점 중 대부분에서 지반함몰이 발생하지 않는 상황에서 모든 지점을 비발생으로 예측하더라도 높은 정확도를 얻을 수 있으나, 이러한 모델은 실제로 가장 중요한 지반함몰 발생 지점을 전혀 탐지하지 못하는 한계를 갖는다. 반대로, 일부 오탐(False Positive, FP)이 발생하더라도 실제 지반함몰 발생 지점을 최대한 많이 탐지하여 참양성(True Positive, TP) 비율을 높이는 것이 지반 안전 관리 관점에서는 더욱 중요하다. 특히 지반함몰과 같이 발생 빈도가 매우 낮은 재해의 경우, 발생 사례를 놓치는 미탐(False Negative, FN)은 인명 및 시설 안전 측면에서 치명적인 결과를 초래할 수 있다. 따라서 본 연구에서는 불균형 데이터 처리 기법의 효과를 공정하고 합리적으로 비교하기 위하여, 지반함몰 데이터 특성에 적합한 성능 평가 지표를 선정하였다.
먼저 임계값(threshold)에 따른 실제 분류 결과를 해석하기 위하여, 정밀도(precision), 재현율(recall), F1-score와 같은 임계값 기반 성능 지표를 산정하였다. 정밀도는 지반함몰로 예측된 하수관 중 실제로 지반함몰이 발생한 비율을 의미하며, 재현율은 실제 지반함몰 발생 하수관 중 모델이 이를 올바르게 탐지한 비율을 나타낸다. F1-score는 정밀도와 재현율의 조화 평균으로, 지반함몰 탐지 성능과 오탐 간의 균형을 종합적으로 평가하는 지표이다. 본 연구에서는 모든 실험에서 분류 임계값을 0.5로 고정하여 적용하였다. 해당 임계값은 지반함몰 탐지를 위한 최적 운영 기준을 의미하지는 않으나, 불균형 데이터 처리 기법 간의 상대적 성능을 비교하는 본 연구의 목적을 고려하여, 임계값 선택에 따른 영향을 배제하고 샘플링 기법의 효과를 공정하게 비교하기 위한 기준선으로 설정하였다.
한편, 임계값 선택에 의존하지 않고 모델의 예측 확률 전반에 걸친 성능을 평가하기 위하여, 본 연구에서는 PR-AUC를 모델 성능 비교의 주요 지표로 사용하였다. PR-AUC는 재현율을 가로축으로, 정밀도를 세로축으로 하는 재현율–정밀도 곡선 아래 면적을 의미하며, 분류 임계값을 변화시킬 때 모델의 예측 성능 변화를 종합적으로 나타내는 지표이다. PR-AUC는 분류 임계값 전 구간에 걸쳐 정밀도와 재현율의 관계를 평가하므로, 다수 클래스의 영향이 최소화된 상태에서 소수 클래스인 지반함몰 발생 사례에 대한 예측 성능을 직접적으로 반영할 수 있다는 장점이 있다. 특히 PR-AUC는 무작위 분류기의 기대 성능이 양성 클래스의 발생 비율과 동일하다는 특성을 가지므로, 무작위 분류 대비 모델의 상대적 성능 향상을 직관적으로 해석할 수 있다. 이러한 이유로 PR-AUC는 희귀 사건 예측 문제에서 불균형 데이터 처리 기법의 효과를 비교하는 데 가장 적합한 지표로 판단하였다.
추가적으로 모델의 전반적인 분리 능력을 평가하기 위하여 분류 모델의 성능 지표로 널리 사용되는 ROC(Receiver Operating Characteristic)-AUC를 보조 지표로 함께 제시하였다. ROC-AUC는 모든 분류 임계값에 대해 양성과 음성 표본을 올바르게 순위화할 수 있는 능력을 평가하는 지표로서, 모델의 전체적인 분류 특성을 파악하는 데 유용하다. 다만, 희귀 사건 분류 문제에서는 다수 클래스의 비중이 지나치게 커 ROC 곡선이 소수 클래스 예측 성능을 상대적으로 낙관적으로 평가할 수 있다는 한계가 보고된 바 있다(Saito and Rehmsmeier, 2015). 이와 같이 본 연구에서는 PR-AUC를 중심으로 ROC-AUC 및 임계값 기반 성능 지표를 종합적으로 활용함으로써, 불균형 데이터 처리 기법이 지반함몰 예측 모델의 전반적인 분리 능력과 실제 탐지 특성에 미치는 영향을 다각도로 평가하고자 하였다.
3. 모델 학습 과정 및 결과
3.1 하이퍼파라미터 튜닝
본 절에서는 불균형 데이터 처리 기법의 효과를 비교하기 위한 기준선으로서, 샘플링을 적용하지 않고 원본 학습 데이터 분포를 그대로 사용하여 학습한 기본 모델의 학습 과정과 성능을 제시하였다. 기본 모델은 하수관 손상에 따른 지반함몰 발생 여부를 이진 분류 문제로 설정하고 XGBoost 알고리즘을 이용하여 학습하였으며, random undersampling, random oversampling, SMOTE와 같은 불균형 데이터 처리 기법은 적용하지 않았다. 이에 따라 학습 데이터는 소수 클래스와 다수 클래스 간의 극단적인 불균형 상태를 유지한 채 모델이 학습되었으며, 본 절에서 제시하는 기본 모델의 성능은 이후 불균형 데이터 처리 기법을 적용한 모든 실험 결과를 해석하기 위한 기준선으로 활용된다.
기본 모델의 예측 성능을 최대한 확보하기 위하여 XGBoost 모델의 복잡도 조절과 과적합 방지를 위해 중요한 역할을 수행하는 주요 하이퍼파라미터에 대한 튜닝을 수행하였다. 튜닝 대상 하이퍼파라미터에는 트리 개수(n_estimators), 학습률(learning_rate), 최대 트리 깊이(max_depth), 최소 자식 노드 가중치(min_child_weight), 서브샘플링 비율(subsample), 특성 샘플링 비율(colsample_bytree), 분할 최소 손실 감소량(gamma), 그리고 L2 정규화 계수(reg_lambda)를 포함하였다. n_estimators는 부스팅 반복 횟수를 의미하며, 값이 클수록 모델의 표현력은 증가하나 과적합 위험이 커질 수 있다. learning_rate는 각 트리의 기여도를 조절하는 계수로, 작은 값을 사용할수록 보다 안정적인 학습이 가능하다. max_depth와 min_child_weight는 개별 결정트리의 구조를 제어하는 파라미터로, 트리의 복잡도와 분할 민감도를 조절하는 역할을 한다. 또한 subsample과 colsample_bytree는 각각 학습 데이터와 입력 변수의 일부만을 무작위로 사용하여 과적합을 완화하는 데 기여한다. gamma는 분할 시 최소 손실 감소량을 제어하여 불필요한 분할을 억제하며, reg_lambda는 L2 정규화 항으로 모델의 일반화 성능 향상에 기여한다. 하이퍼파라미터의 탐색 범위는 기존 XGBoost 관련 선행 연구와 불균형 데이터 환경에서의 안정적인 학습을 고려하여 설정하였다. 과도한 모델 복잡도를 방지하기 위해 max_depth, subsample, colsample_bytree 등의 범위는 보수적으로 제한하였으며, learning_rate와 n_estimators는 상호 보완적으로 탐색되도록 설정하였다.
탐색 과정의 계산 효율을 확보하기 위하여, 학습 데이터 중 지반함몰 발생 사례는 전부 포함하고, 비발생 사례는 일정 비율로 무작위 추출하여 튜닝용 부분집합을 구성하였다. 하이퍼파라미터 탐색은 제한된 계산 비용 하에서 넓은 탐색 공간을 효율적으로 탐색 가능하다는 장점이 있는 무작위 탐색(Randomized search) 방식으로 수행하였으며, 성능 평가 지표로는 극단적인 클래스 불균형 특성을 고려하여 PR-AUC를 사용하였다. 하이퍼파라미터 무작위 탐색 반복에 따른 검증 데이터의 PR-AUC 수렴 양상을 Fig. 1에 제시하였다. 그림에서 확인할 수 있듯이, 탐색 초기에는 하이퍼파라미터 조합에 따라 PR-AUC 값의 변동 폭이 비교적 크게 나타났으나, 반복 횟수가 증가함에 따라 최고 성능(best-so-far PR-AUC)이 점진적으로 향상되며 일정 수준에서 수렴하는 경향을 보였다. 특히 약 20–30회 이내의 반복에서 PR-AUC가 빠르게 개선된 이후에는 추가 반복에 따른 성능 향상이 제한적으로 나타나, 주요 하이퍼파라미터 공간이 충분히 탐색되었음을 시사한다. 이러한 수렴 양상은 최적 하이퍼파라미터 조합이 비교적 이른 단계에서 도출되었음을 보여주며, 본 연구에서 수행한 무작위 탐색이 계산 효율성과 탐색 안정성 측면에서 적절하게 수행되었음을 뒷받침한다. 각 하이퍼파라미터의 탐색 범위와 탐색 결과 획득한 최적의 하이퍼파라미터 값을 Table 2에 정리하여 제시하였다.
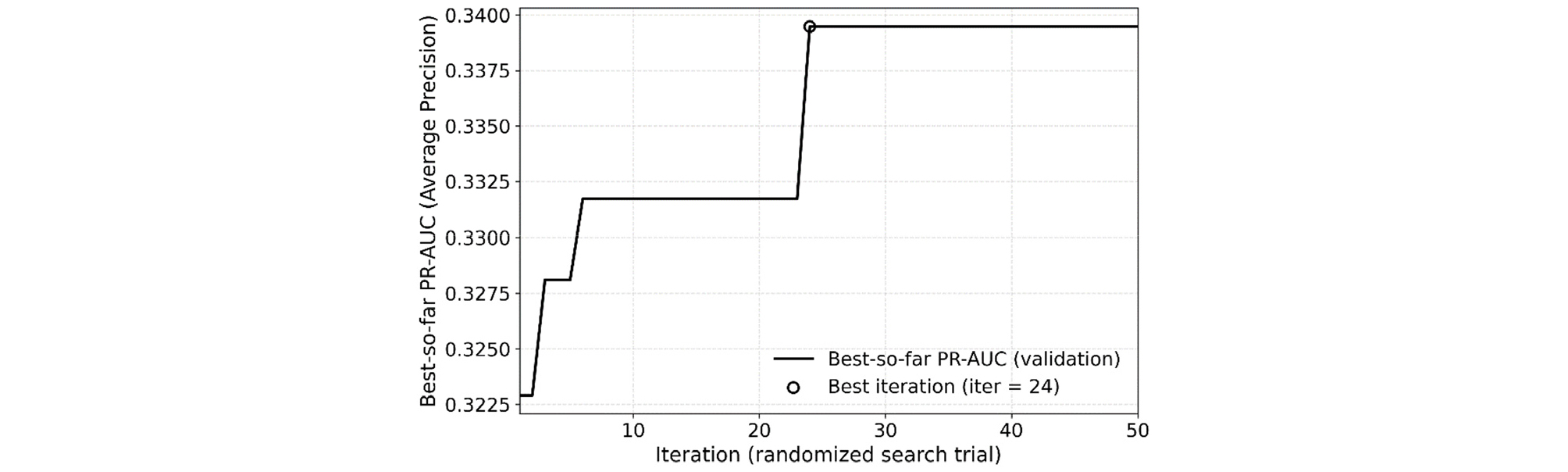
Table 2.
Hyperparameter search ranges and optimal values for the baseline XGBoost model
하이퍼파라미터 튜닝을 통해 도출된 기본 모델의 시험 데이터 성능을 평가한 결과, ROC-AUC는 약 0.85 수준으로 나타나 지반함몰 발생 여부에 대한 전반적인 분리 능력은 비교적 양호한 것으로 확인되었다. 반면, PR-AUC는 약 0.04 수준으로 나타났는데, 이는 절대적인 값으로는 낮아 보일 수 있으나, 전체 데이터에서 지반함몰 발생 사례의 비율이 0.2%로 매우 낮음을 고려하면 무작위 분류기의 PR-AUC(양성 클래스 비율)에 비해 유의미하게 높은 값이다. 그럼에도 불구하고, 임계값 기반 성능 지표에서 소수 클래스에 대한 탐지 성능은 충분하지 않아, 샘플링을 적용하지 않은 기본 모델이 극단적인 클래스 불균형 환경에서 갖는 구조적 한계를 확인할 수 있었다.
3.2 불균형 데이터 처리 효과
Fig. 3는 불균형 데이터 처리 기법과 클래스 비율에 따른 XGBoost 모델의 예측 성능을 PR-AUC와 ROC-AUC 기준으로 비교한 결과를 나타낸 것이다. Fig. 2(a)는 소수 클래스인 지반함몰 발생 사례에 대한 예측 성능을 직접적으로 반영하는 PR-AUC 변화를, Fig. 2(b)는 전체 분류 성능을 나타내는 ROC-AUC 변화를 각각 보여준다.
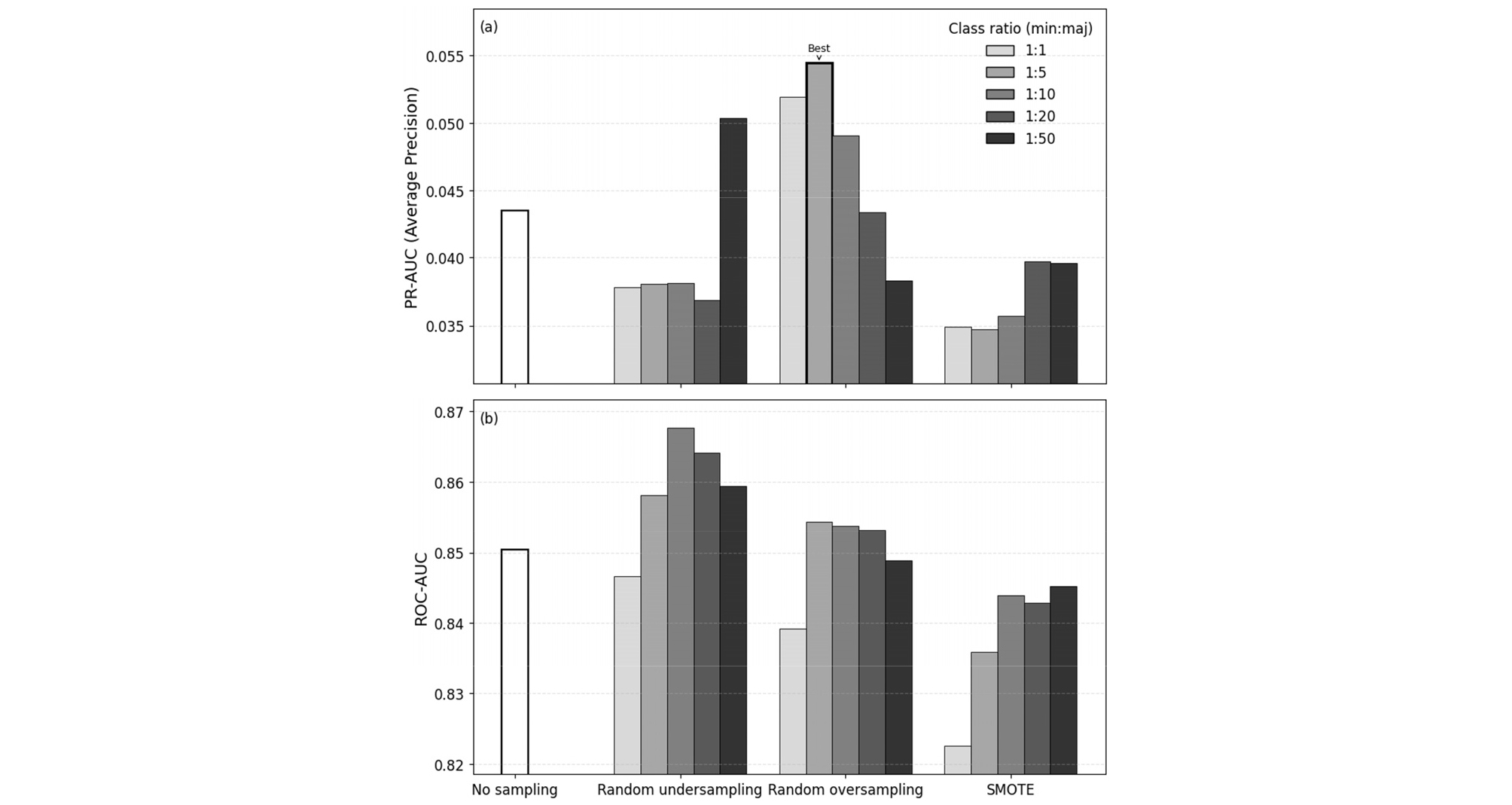
먼저 PR-AUC 결과(Fig. 2(a))를 살펴보면, 샘플링을 적용하지 않은 기본 모델은 PR-AUC가 약 0.04 수준으로 나타났다. 이전에 언급한 바와 같이, 이는 절대적인 값으로는 낮아 보일 수 있으나, 전체 데이터에서 지반함몰 발생 사례의 비율이 매우 낮음을 고려하면 무작위 분류기에 비해 유의미하게 향상된 성능으로 해석할 수 있다. 불균형 데이터 처리 기법을 적용한 경우 전반적으로 PR-AUC가 개선되는 경향을 보였으며, 특히 random oversampling을 적용한 모델에서 상대적으로 큰 성능 향상이 관찰되었다. Random oversampling 중에서도 소수 클래스와 다수 클래스의 비율을 1:5로 설정한 경우 PR-AUC가 가장 높게 나타났는데, 이는 소수 클래스 정보가 충분히 보강되면서도 과도한 중복 표본 생성에 따른 부작용이 상대적으로 억제된 결과로 해석할 수 있다.
한편, oversampling 비율이 1:1로 증가하거나 1:20 및 1:50과 같이 oversampling 비율이 상대적으로 완화되는 경우(즉, 소수 클래스 증강 수준이 낮아지는 경우)에는 PR-AUC 개선 효과가 제한적이거나 오히려 기본 모델에 비해 성능이 감소하는 경향을 보였다. 이는 과도한 oversampling이 학습 데이터의 다양성을 저해하거나, oversampling 강도가 낮아 소수 클래스의 특징이 충분히 강화되지 못하는 경우 예측 성능 향상이 제한될 수 있음을 시사한다. Random undersampling의 경우 일부 비율에서 PR-AUC가 개선되기는 하였으나, 전반적으로 random oversampling에 비해 성능 향상 폭이 크지 않은 것으로 나타났다.
SMOTE를 적용한 경우에는 모든 클래스 비율 조건에서 random oversampling 대비 PR-AUC가 낮게 나타났으며, 일부 조건에서는 기본 모델과 유사하거나 더 낮은 성능을 보였다. 이는 본 연구에서 사용한 지반함몰 데이터가 복잡한 비선형 특성과 국지적인 패턴을 포함하고 있어, 선형 보간 기반의 합성 표본 생성 방식이 데이터 분포를 충분히 반영하지 못했기 때문으로 판단된다.
ROC-AUC 결과(Fig. 2(b))에서는 대부분의 실험 조건에서 비교적 높은 값을 유지하였으며, 샘플링 기법 및 클래스 비율에 따른 변화 폭은 PR-AUC에 비해 상대적으로 제한적인 것으로 나타났다. 이는 ROC-AUC가 다수 클래스의 영향을 크게 받는 지표로서, 극단적인 클래스 불균형 문제에서는 소수 클래스 예측 성능의 차이를 충분히 반영하지 못할 수 있음을 보여준다. 이러한 결과는 불균형 데이터 환경에서 모델 성능 평가 시 PR-AUC와 같은 정밀–재현율 기반 지표를 함께 고려할 필요성을 뒷받침한다.
Fig. 3은 oversampling 비율 변화에 따른 PR-AUC의 민감도를 random oversampling, random undersampling, 그리고 SMOTE 기법별로 비교하여 나타낸 것이다. Fig. 2에서 확인된 기법 간 성능 차이를 보다 명확히 해석하기 위해, 본 그림에서는 클래스 비율에 따른 성능 변화 양상을 연속적인 관점에서 분석하였다. Random oversampling의 경우, 소수 클래스 비율이 증가함에 따라 PR-AUC가 일정 수준까지 상승한 후 다시 감소하는 경향을 보였으며, 특히 1:5 비율에서 가장 높은 PR-AUC를 나타냈다. 이는 소수 클래스 정보가 충분히 보강되면서도 과도한 중복 표본 생성으로 인한 학습 왜곡이 최소화되는 지점이 존재함을 의미한다.
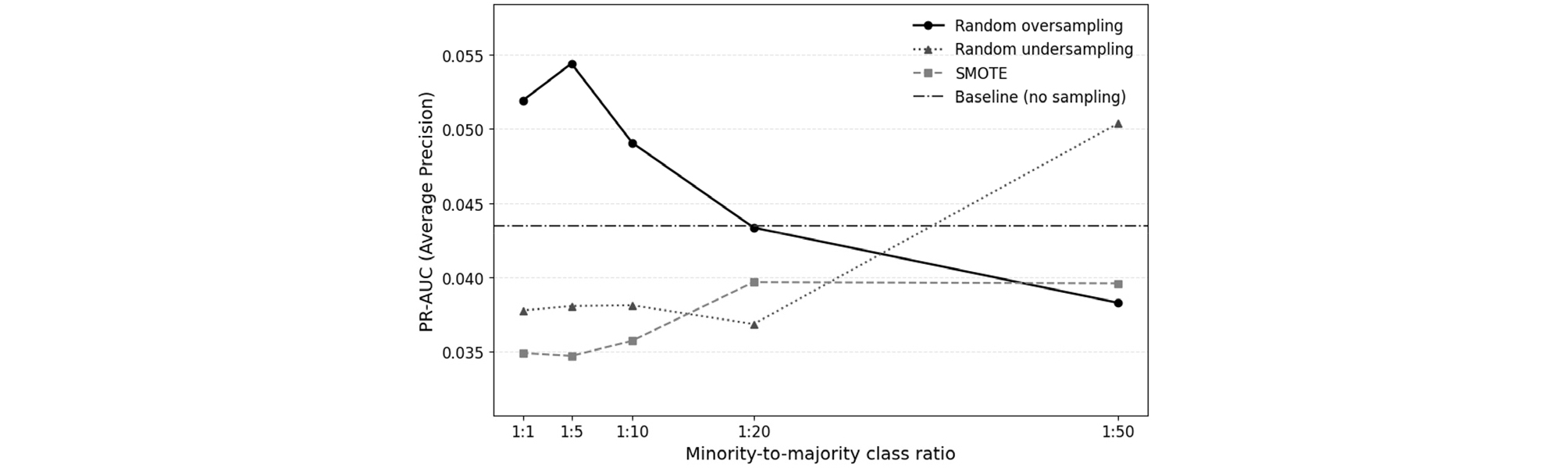
반면, random undersampling의 경우 소수 클래스와 다수 클래스의 비율을 1:50 수준까지 조정했을 때에는 기본 모델 대비 PR-AUC가 유지되거나 소폭 개선되는 경향을 보였다. 그러나 undersampling 비율이 이보다 더 증가하여 다수 클래스 표본이 과도하게 제거되는 경우에는 PR-AUC가 급격히 감소하는 경향이 관찰되었다. 이는 일정 수준까지의 undersampling은 클래스 불균형 완화에 기여할 수 있으나, 임계 비율을 초과할 경우 다수 클래스 정보 손실이 커져 예측 성능에 부정적인 영향을 미칠 수 있음을 시사한다. 한편, SMOTE를 적용한 경우에는 비율 증가에 따른 PR-AUC 개선 효과가 전반적으로 제한적이었으며, 대부분의 비율 조건에서 기본 모델보다도 낮은 성능을 보였다. Fig. 3의 결과는 oversampling과 undersampling 모두에서 샘플링 비율 선택이 모델 성능에 중요한 영향을 미침을 보여주며, 단순한 데이터 증강이나 축소가 아닌 기법별 특성을 고려한 적정 비율 설정이 필요함을 정량적으로 뒷받침한다.
Table 3은 불균형 데이터 처리 기법별로 PR-AUC가 가장 높게 나타난 모델을 기준으로, ROC-AUC, 정밀도, 재현율, F1-score와 같은 다른 성능 지표를 함께 비교한 정량적 결과를 요약한 것이다. 이를 통해 각 샘플링 기법이 소수 클래스 예측 성능을 어떤 방식으로 개선하는지, 그리고 지표 간 성능 균형이 어떻게 달라지는지를 종합적으로 확인할 수 있다.
Table 3.
Performance comparison of representative models using different evaluation metrics
| Sampling strategy |
Class ratio (min:maj*) | PR-AUC | ROC-AUC | Precision@0.5† | Recall@0.5† | F1-score@0.5† |
| No sampling (baseline) | 1:448 | 0.043 | 0.85 | 0 | 0 | 0 |
| Random oversampling | 1:5 | 0.054 | 0.854 | 0.058 | 0.273 | 0.096 |
| Random undersampling | 1:50 | 0.050 | 0.858 | 0.013 | 0.75 | 0.026 |
| SMOTE | 1:5 | 0.035 | 0.836 | 0.058 | 0.273 | 0.091 |
샘플링을 적용하지 않은 기본 모델은 ROC-AUC 기준으로는 비교적 높은 값을 보였으나, PR-AUC와 정밀도, 재현율, F1-score 등 소수 클래스 예측과 직접적으로 관련된 지표에서는 전반적으로 낮은 성능을 나타냈다. 이는 다수 클래스 분리 능력에 비해 지반함몰 발생 사례를 실제로 식별하는 능력이 제한적임을 보여준다.
Random undersampling을 적용한 모델은 Table 3에 나타난 바와 같이, 다른 기법에 비해 재현율이 크게 높게 나타난 반면, 정밀도는 매우 낮은 값을 보였다. 이는 지반함몰 발생 사례 중 상당수를 탐지하는 데에는 성공하였으나, 지반함몰로 예측된 지점 중 다수가 실제로는 비발생 사례에 해당함을 의미한다. 이러한 결과는 지반함몰 발생 확률을 전반적으로 높게 평가하는 예측 성향으로 인해 미탐은 감소한 반면 오탐이 크게 증가한 데 따른 것으로 해석할 수 있다.
반면, random oversampling을 적용한 모델은 PR-AUC와 F1-score 측면에서 전반적으로 가장 균형 잡힌 성능을 보였다. 특히 소수 클래스와 다수 클래스 비율을 1:5로 설정한 경우 PR-AUC와 F1-score가 모두 최대값을 나타냈으며, 이는 지반함몰 발생 사례를 효과적으로 구분하는 능력과 함께 예측의 신뢰도가 동시에 향상되었음을 의미한다. 이러한 결과는 random oversampling이 소수 클래스 표본 수를 적절히 보강함으로써, 지반함몰 발생 여부를 과도하게 예측하지 않으면서도 실제 발생 사례를 안정적으로 탐지할 수 있는 학습 환경을 제공했기 때문으로 해석할 수 있다.
SMOTE를 적용한 모델은 F1-score 측면에서는 random oversampling과 유사한 값을 보였으나, PR-AUC는 상대적으로 낮게 나타났다. 이는 본 연구에서 사용한 임계값 0.5에서는 정밀도와 재현율의 균형이 일정 수준 확보되었으나, 모든 가능한 분류 임계값 전반에서 소수 클래스에 대한 분리 능력을 종합적으로 평가하는 PR-AUC 기준에서는 예측 성능 향상이 충분히 나타나지 않았음을 의미한다.
종합하면, 본 연구의 실험 결과는 불균형 데이터 처리 기법이 지반함몰 발생 예측 성능에 유의미한 영향을 미침을 보여주며, 특히 random oversampling을 적절한 비율로 적용할 경우 소수 클래스 예측 성능이 효과적으로 향상될 수 있음을 확인하였다. 또한, 동일한 데이터셋이라 하더라도 적용 기법과 클래스 비율에 따라 성능 특성이 크게 달라질 수 있음을 고려할 때, 불균형 데이터 처리 전략의 설계가 결과 해석에 중요한 요소로 작용함을 시사한다.
4. 결 론
본 연구에서는 하수관 손상에 따른 지반함몰 발생 예측 문제를 대상으로, 하수관의 기하학적 특성, 매설 조건, 노후도 등을 입력변수로 하고 지반함몰 발생 여부를 출력변수로 하는 기계학습 기반 이진 분류 모델을 구축하였다. 서울시 전역을 대상으로 구축된 하수관 및 지반함몰 데이터베이스를 활용하여, 극단적인 클래스 불균형 환경에서 불균형 데이터 처리 기법이 예측 성능에 미치는 영향을 분석하였다. XGBoost 모델을 기본 모델로 설정하고, 샘플링을 적용하지 않은 기본 모델을 기준으로 random undersampling, random oversampling, SMOTE를 다양한 클래스 비율 조건에서 적용하여 비교 분석한 결과, 다음과 같은 결론을 도출하였다.
(1) 샘플링을 적용하지 않은 기본 모델은 ROC-AUC 기준으로는 비교적 높은 값을 보였으나, PR-AUC 및 임계값 기반 지표에서는 무작위 분류기 수준을 상회하는 제한적인 성능을 나타내어, 극단적인 클래스 불균형 환경에서 소수 클래스 예측에 구조적 한계가 있음을 확인하였다.
(2) 불균형 데이터 처리 기법을 적용한 경우 전반적으로 소수 클래스 예측 성능이 개선되었으며, 특히 random oversampling이 PR-AUC와 F1-score 측면에서 가장 우수한 성능을 보였다. 이 중 소수 클래스와 다수 클래스의 비율을 1:5로 설정한 경우, 성능 향상과 데이터 왜곡 간의 균형이 가장 효과적으로 달성되었다.
(3) Oversampling 비율 변화에 따른 분석 결과, 소수 클래스 비율 증가가 예측 성능의 지속적인 향상으로 직결되지는 않았으며, 특정 비율에서 PR-AUC가 최대화된 이후 감소하는 경향이 확인되었다. 이는 불균형 데이터 처리 과정에서 적정 클래스 비율 설정의 중요성을 시사한다.
(4) Random undersampling은 특정 클래스 비율 조건에서 PR-AUC가 기본 모델을 상회하는 경우도 확인되었으나, 비율 변화에 따라 성능 변동성이 크게 나타나 예측 안정성 측면에서 한계를 보였다. SMOTE는 일부 임계값 기반 지표에서는 oversampling과 유사한 성능을 보였으나, 예측 확률 전반에 대한 평가 지표인 PR-AUC 기준에서는 상대적으로 낮은 값을 나타내어 소수 클래스 예측 성능 개선 효과가 제한적인 것으로 확인되었다.
본 연구의 결과로부터 지반함몰 발생 예측과 같이 불균형 특성이 뚜렷한 지반공학적 문제에서 PR-AUC 기반 평가의 중요성과 함께, 적절한 oversampling 전략이 소수 클래스 예측 성능 향상에 효과적임을 확인하였다. 다만 본 연구는 대규모 관측 자료를 기반으로 한 데이터 기반 접근 방법에 초점을 둔 연구로, 개별 입력변수의 물리적 인과관계를 정량적으로 규명하는 데에는 한계가 존재한다. 향후 연구에서는 물리 기반 모델이나 실험 연구와의 결합, 그리고 다양한 알고리즘 적용과 데이터 확장을 통해 보다 일반화된 지반재해 예측 모델로의 발전이 필요할 것으로 판단된다.
