

1. 서 론
2. 배경이론
2.1 포인트 클라우드
2.2 포인트넷(PointNet)
3. 캐드 모델링을 활용한 3D 포인트 클라우드 학습 DB 구축
3.1 3D 캐드를 활용한 터널 모델링
3.2 3D 캐드 모델의 포인트 클라우드 데이터 변환
3.3 학습 DB 구축을 위한 카테고리 구분
4. 포인트넷 기반의 터널 객체 분할 인식 파라미터 연구
4.1 동일한 터널 데이터를 사용한 경우
4.2 서로 다른 크기의 복선 터널 데이터를 사용한 경우
4.3 서로 다른 유형의 터널 데이터를 사용한 경우
4.4 다양한 데이터를 사용한 경우
5. 결 론
1. 서 론
과학기술이 발전함에 따라 AICBM(Artificial intelligent, IoT, Cloud, Big data and Moblie) 기술을 사용하는 것이 점점 더 저렴해지고 편리해지면서 과거보다 더 쉽게 현실 세계로부터 데이터를 취득하고, 디지털 공간에서 이를 분석하고 시뮬레이션할 수 있게 되었다. 이러한 기술을 일컬어 디지털 트윈(Digital twin)이라 한다. 디지털 트윈은 2017년부터 2019년까지 3년 동안 가트너가 선정한 10대 전략기술에 포함되어 세계적으로 주목받고 있으며 국내에서도 정부의 ‘한국판 뉴딜’ 정책의 10대 대표과제 중 하나로 선정되었다(Ministry of Economy and Finance, 2020).
건설 분야의 관점에서 BIM(Building Information Modeling)은 디지털 트윈을 적용한 기술의 대표적인 예라고 할 수 있다. BIM은 구조물의 물리적, 기능적 특성을 디지털로 구현한 것으로, 건설 프로젝트 전 생애주기 동안 설계 검토, 시뮬레이션을 통한 공정관리, 유지관리 등 다양한 업무에 활용할 수 있다(Kreider et al., 2010; Hergunsel, 2011). 이러한 장점으로 인해, 전 세계적으로 BIM 도입이 증가하는 추세 속에 국내에서도 턴키 및 공공 도로사업의 BIM 설계 의무화를 통해 BIM 도입을 가속화하고 있다(Ministry of Land, Infrastructure and Transport, 2018). BIM 도입 가속화는 BIM 설계 정착으로 이어지며 나아가 향후 시설물의 유지관리도 BIM 기반 체계로 변환될 것임을 의미한다. 그러나 BIM 도입 이전에 시공된 구조물의 유지관리에 BIM을 활용하기 위해서는 먼저 구조물을 역설계하여 3D BIM 모델을 구축하는 과정이 필요하다. 그러나 역설계를 통한 BIM 모델링은 실측 및 도면 재작성 과정에 많은 비용과 시간이 소모되고 전문 인력과 기술을 필요로 하는 문제가 있어 이를 해결하고자 전문적인 실측 능력을 요구하지 않아도 도면 작성이 가능한 Scan-to-BIM이 활용된다(Park, 2021).
Scan-to-BIM 과정은 라이다(Light Detection And Ranging, LiDAR)로 구조물을 계측하는 것으로 시작된다. 라이다는 정밀한 계측이 가능하여 구조물의 변상상태를 평가하는데 활용되기도 하고 구조물을 여러 방향에서 계측하고 이를 하나로 정합하는 과정을 통해 비교적 넓은 범위의 3차원 정보를 고밀도의 포인트 클라우드 데이터(Point Cloud Data, PCD)의 형태로 획득할 수 있어 정밀한 3D 모델을 구축하는데 많이 활용되고 있다(Hong et al., 2012; Park and Lee, 2015; Lee and Sim, 2021). 그러나 이렇게 취득한 방대한 양의 포인트 클라우드 데이터는 단순히 시각적으로 구조물의 3차원 형상을 볼 수 있게 해줄 뿐 각각의 점이 구조물의 어떤 구성요소에 포함되는지는 알 수 없다. 따라서 BIM 기반 유지관리에 포인트 클라우드 데이터를 효과적으로 활용하기 위해서는 각각의 점이 구조물의 구성요소 중 어디에 해당하는지를 수작업으로 분류해내는 과정이 필요하며, 분류된 점들을 구조물로 3D BIM 모델을 구축하게 된다. 현재는 이러한 모든 과정이 인력에 의한 수작업을 통해 이루어지게 되며, 단순하고 반복적인 업무의 연속으로, 많은 인력과 시간, 비용이 소모된다.
이러한 한계를 극복하기 위해 포인트 클라우드에서 3D 모델 생성을 자동화하려는 연구들이 진행되고 있다. 그 중에 하나로 딥러닝을 통해 여러 가지 객체들이 혼재하는 포인트 클라우드 데이터에서 각각의 서로 다른 객체들을 구분해내는 객체 분할(Semantic segmentation)에 대한 연구들이 수행되고 있으며(Qi et al., 2017; Landrieu and Simonovsky 2018; Wang et al., 2019; Rao et al., 2021), 건설 분야에도 이러한 연구들을 바탕으로 하여 딥러닝을 통해 구조물을 객체 분할하는 연구들이 수행되고 있다(Soilán et al., 2020; Kim et al., 2020; Meng, 2020; Park, 2021; Lee et al., 2021). 건설 분야에서의 이러한 연구들은 모두 테스트 결과를 향상시키기 위한 다양한 방법들을 다루고 있다. 그러나 건설 분야에서의 연구들은 딥러닝 알고리즘을 구조물에 적용하는 것에 초점이 맞추어져 있으며, 딥러닝의 학습 데이터에 따라서 구조물의 객체 분할의 정확도가 어떻게 변하는지에 대한 연구는 이루어지지 않았다.
본 연구에서는 철도 터널의 3차원 포인트 클라우드 데이터를 대상으로 딥러닝 알고리즘 적용을 통해 자동화된 객체 분할에 대한 연구를 진행하고자 하며, 이때 학습 데이터로 사용한 철도 터널의 단면의 크기, 선로 유형, 종류 등에 따라 객체 분할 정확도의 변화를 살펴보고자 매개변수 연구를 수행하였다. 이를 통해 각각의 요인들이 테스트 정확도에 어떠한 영향을 미치는지 검토하고 철도 터널의 객체 분할을 수행하는데 효율성을 높이기 위해 필요한 학습 데이터 구성 조건에 대해 기술하였다.
2. 배경이론
2.1 포인트 클라우드
포인트 클라우드는 3차원 공간의 데이터 포인트 군집을 의미하는데 일반적으로 라이다와 같은 3D 스캐너를 통해 생성된다. 3D 스캐너는 구조물의 외부 표면에서 다수의 포인트를 측정하는데 이렇게 측정된 데이터는 점의 형태로 기록되며 각각의 포인트는 3차원 위상정보(x, y, z 좌표)와 색상 정보(R, G, B)를 포함한다. 본 연구에서는 매개변수 연구를 위해 여러 종류의 철도 터널에 대한 포인트 클라우드 데이터가 필요하였다. 그러나 현실적으로 운영 중인 철도 터널을 대상으로 다수의 계측을 진행하기는 매우 어렵기 때문에 3D 캐드(CAD) 모델을 포인트 클라우드 데이터로 변환하는 방법을 사용하였다. 이에 대한 자세한 설명은 3장에 서술하였다.
2.2 포인트넷(PointNet)
본 연구에서는 2.1에서 설명한 포인트 클라우드를 활용하여 객체 분할을 하기 위한 알고리즘으로 포인트넷을 사용하였다. 포인트넷은 포인트 클라우드를 학습하여 3차원 객체의 분류(classification) 또는 분할(segmentation)하는 딥러닝의 기법이다(Qi et al., 2017). 포인트넷은 기존에 포인트 클라우드를 활용하기 위해 이미지 그리드(image grid) 또는 3D 복셀(voxel) 형식의 규칙적인 형식의 데이터로 변환하던 과정을 거치지 않고 포인트 클라우드 자체를 학습 데이터로 활용할 수 있다. 이로 인해 변환 과정에서 발생할 수 있는 데이터 용량 증가, 데이터 왜곡 등의 문제를 극복할 수 있다는 장점이 있다. 이러한 장점은 크기가 큰 토목 구조물을 대상으로 객체 분할을 수행하는데 효과적일 것으로 판단되어 본 연구를 수행하는데 활용하였다. 포인트넷의 아키텍쳐는 Fig. 1과 같다.
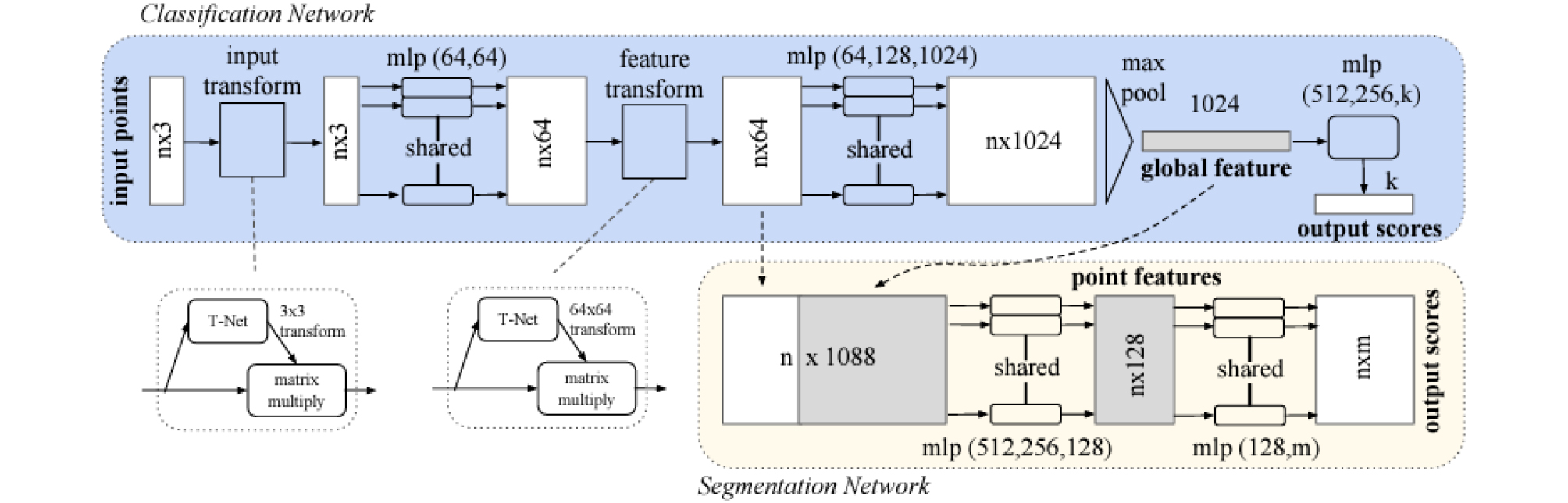
포인트넷의 아키텍쳐를 살펴보면 우선, 입력 데이터인 포인트 클라우드를 T-Net을 이용해 3×3 변환 행렬(transform matrix)을 출력하고 여기에 다시 포인트 클라우드를 곱해준다. 이 과정을 통해 포인트 클라우드는 이동과 회전에 영향을 받지 않게 된다(Jaderberg et al., 2015). 이후에 다층 퍼셉트론(multi layer perceptron, mlp)을 통해 포인트 클라우드를 64차원으로 늘리고 특성 변환(feature transform) 과정을 통해 64×64 변환 행렬을 계산하여 지역 특징(local feature)을 추출한다. 추출된 지역 특징은 1024차원의 특징점으로 다층 퍼셉트론을 활용해 생성하고 최대 풀링(max pooling)을 수행하여 전역 특징(global feature)을 도출한다. 이렇게 도출된 64차원의 지역 특징과 1024차원의 전역 특징을 합해주고 다층 퍼셉트론을 거쳐 산출 점수(output score)를 결정하여 각 3차원 좌표가 의미하는 바를 결정한다(Qi et al., 2017).
3. 캐드 모델링을 활용한 3D 포인트 클라우드 학습 DB 구축
학습 데이터의 종류와 그 구성의 변화에 따른 철도 터널 객체 분할 인식 정확도의 변화를 확인하기 위해서는 우선 학습 데이터 구축에 사용할 다양한 형상의 철도 터널 포인트 클라우드 데이터가 필요하다. 일반적으로 구조물의 포인트 클라우드 데이터는 라이다 계측을 통해 취득하게 된다. 그러나 라이다 계측을 통해 실제 운영 중인 철도 터널의 포인트 클라우드 데이터를 확보하려면 철도의 운영을 중단시켜야 한다는 문제가 있으며 계측에도 많은 시간과 비용을 필요로 한다. 더욱이 본 연구의 목적을 위해서는 다양한 형상의 터널을 대상으로 계측을 수행하여야 하는데 이는 현실적으로 불가능하다. 이런 문제를 극복하고자 3D 캐드를 활용하여 터널을 모델링하여 학습 DB 구축에 활용하는 방안을 제안하였다.
3.1 3D 캐드를 활용한 터널 모델링
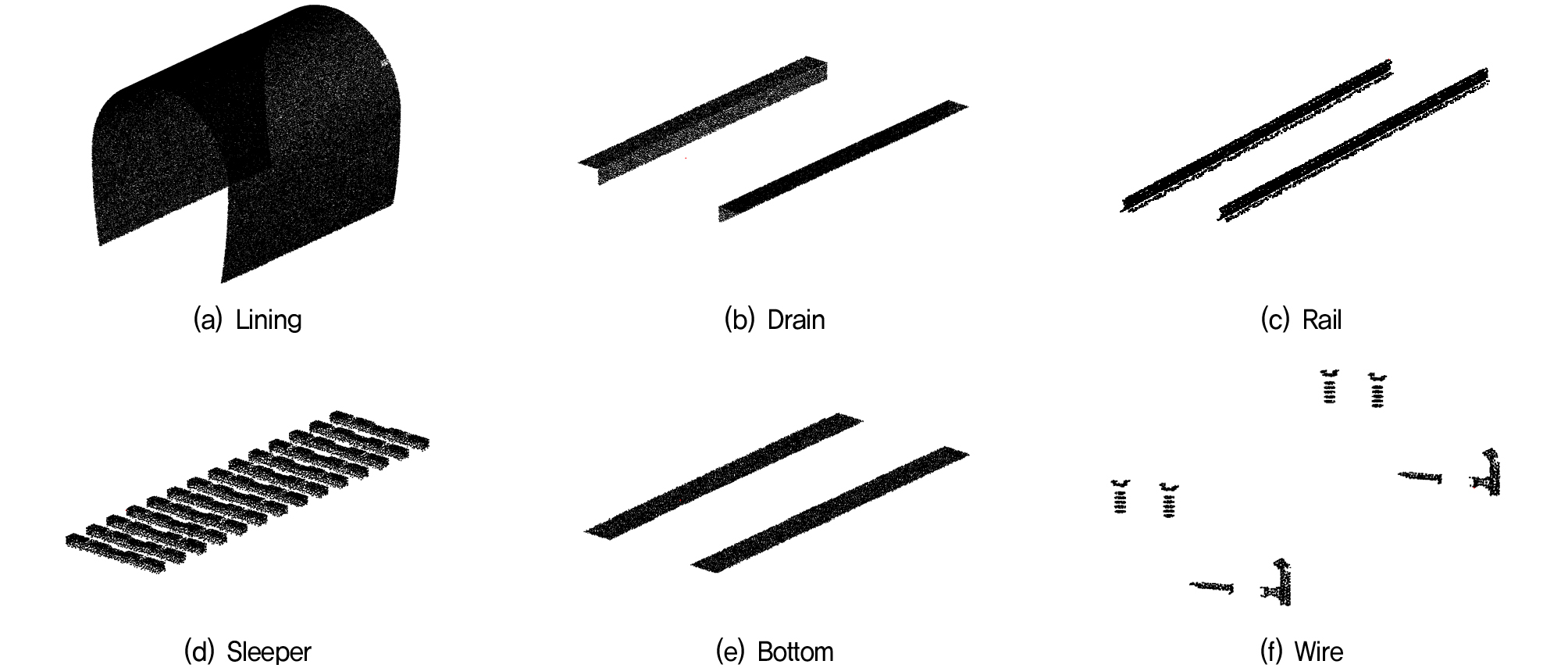
3D 캐드를 활용한 터널 모델링은 라이다 계측에 소요되는 인력과 시간을 절약하고 터널 운영에 지장을 주지 않으며 원하는 단면의 형태를 고려하여 모델링이 가능하기 때문에 본 연구를 수행하는데 적합한 방식이며, 모델링은 NATM 공법으로 건설된 철도 터널을 대상으로 하였다. 터널의 단면 크기와 형상이 철도 터널의 객체 분할 정확도에 어떤 영향을 미치는지 알아보고자 단면 크기가 서로 다른 세 가지 복선 터널과 선로가 하나인 단선 터널을 모델링하였다. 각각의 터널은 총 여섯 가지 카테고리로 구성되는데 각각 라이닝(Lining), 배수로(Drain), 선로(Rail), 침목(Sleeper), 바닥부(Bottom), 전선(Wire)으로 이루어졌다. 복선 터널과 단선 터널의 형상은 Fig. 2와 같으며 단면의 치수는 Table 1과 같다. 복선 터널은 단면의 크기가 작은 것부터 순서대로 소형(Double-S), 중형(Double-M), 대형(Double-L)으로 구분하여 명명하였다.
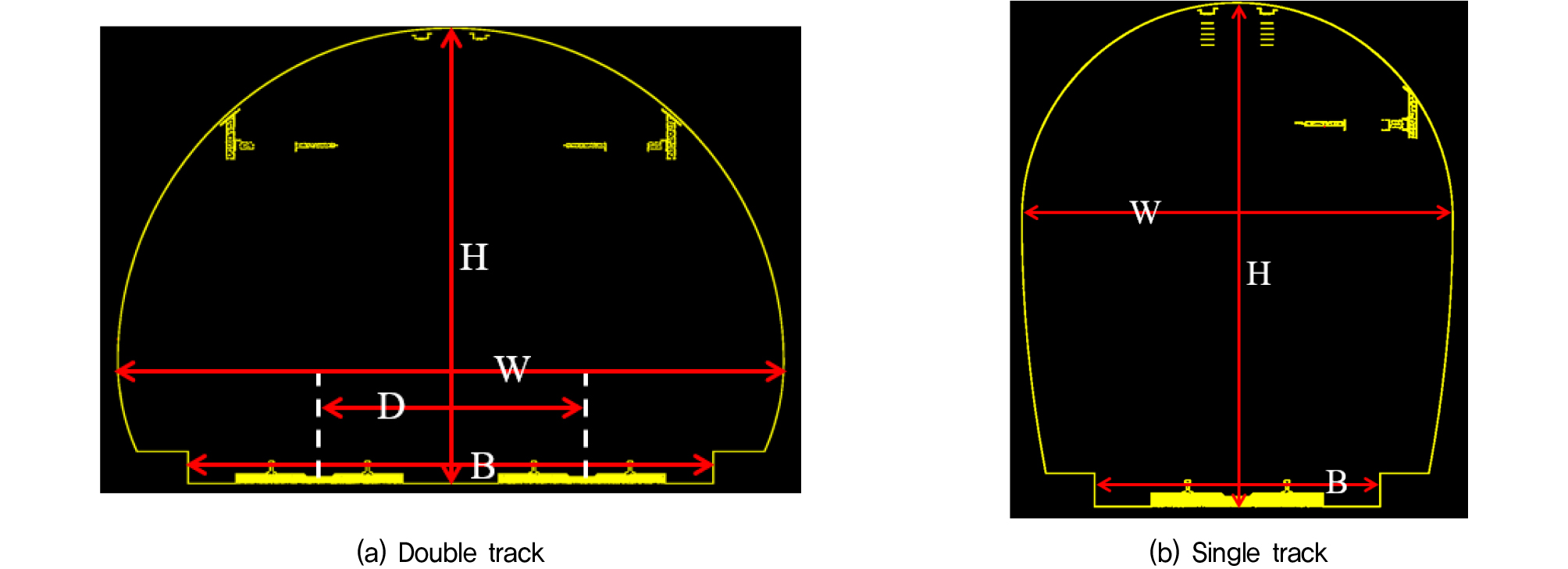
Table 1.
The cross-sectional dimensions of the tunnel
3.2 3D 캐드 모델의 포인트 클라우드 데이터 변환
앞서 제작한 3D 캐드 모델을 딥러닝에 활용하기 위한 학습 DB를 구축하기 위해서는 먼저 포인트 클라우드 데이터로 변환하는 과정이 필요하다. 이를 위해 Meshlab 프로그램을 사용하였으며 3D 캐드 모델의 단면에서 점들을 추출하는 방식을 통해 포인트 클라우드 데이터 변환을 하였다. 점들을 추출하는 방법으로는 Poisson-disk sampling 방식을 사용하였다. 무작위로 샘플을 추출할 경우 단면 내에서 추출된 점들 사이의 거리를 고려하지 않고 임의로 추출되기 때문에 밀도가 높은 곳과 낮은 곳이 생길 수 있어 균질한 데이터를 얻기 어려우나 Poisson-disk sampling 방식은 점들을 랜덤하게 배치하면서도 점들이 특정 거리보다 가까이 있지 않도록 제한하는 방식으로 추출하기 때문에 균질한 데이터를 얻을 수 있다(Robert, 1986).
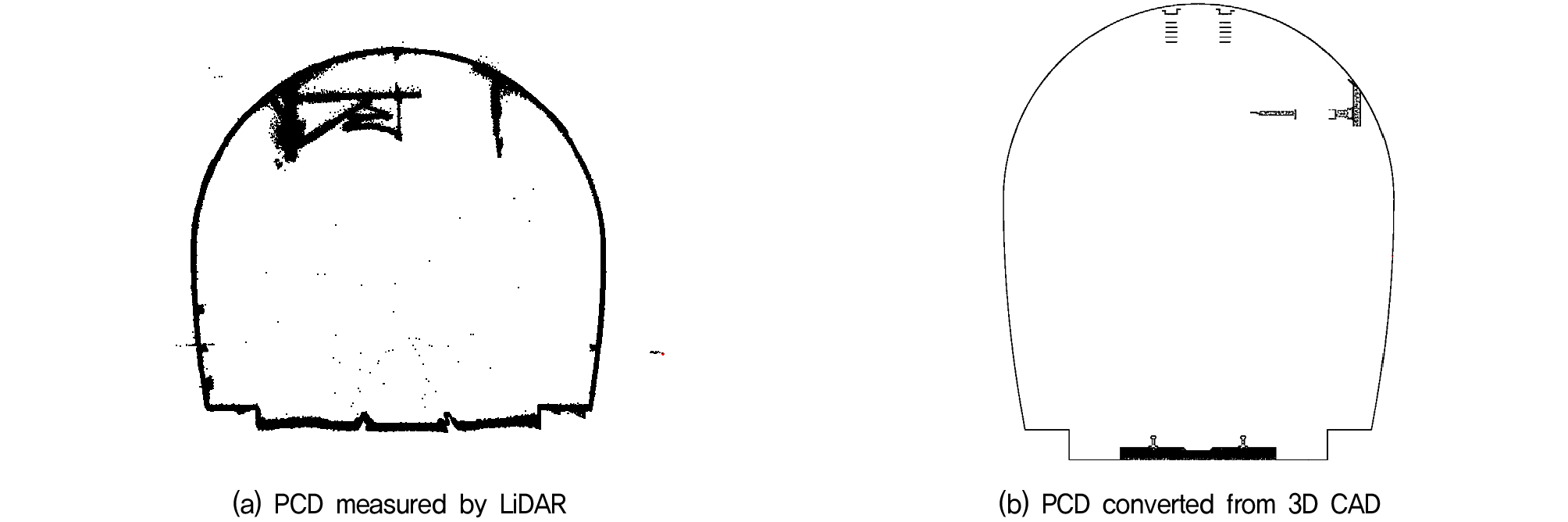
실제 라이다 계측 시에는 구조물의 표면이 계측되는데 이 과정에서 Fig. 3의 (a)와 같이 노이즈가 발생하거나 오차로 인해 단면이 수 mm의 두께를 가지는 점군의 형태로 표현되게 된다. 그러나 3D 캐드 모델에서 포인트 클라우드 데이터를 변환하는 과정에서는 이러한 문제가 없이 Fig. 3의 (b)와 같이 매끄러운 형태의 데이터로 변환할 수 있다는 장점이 있다. 본 연구의 목적은 학습 데이터를 구성하는 터널 단면의 크기와 선로 유형에 따라 철도 터널의 객체 분할 정확도에 어떠한 영향을 미치는지를 확인하는 것으로 실제 계측 데이터가 아닌 3D 캐드 모델에서 변환한 데이터를 사용하여도 연구 결과의 도출에 문제가 없기에 해당 방식으로 학습 DB를 구축하였다.
3.3 학습 DB 구축을 위한 카테고리 구분
3.2와 같은 과정을 거쳐 변환된 포인트 클라우드 데이터를 딥러닝에 활용하기 위해서는 터널 전체 포인트 클라우드 데이터를 각각의 카테고리별 포인트 클라우드 데이터로 분리해내는 라벨링(labeling) 과정이 필요하다. 이를 위해 RIEGL사의 포인트 클라우드 데이터 데이터 처리 프로그램인 Riscan Pro를 사용하였다.
학습 DB 구축을 위해 먼저 10m 단위로 터널을 구분하여 하나의 데이터로 하였다. 이는 학습 데이터의 수에 따른 영향을 보기 위함으로 연장이 400m인 네 터널은 각각 40개의 데이터로 분할되었다. 10m 단위로 분할된 포인트 클라우드 데이터에서 각각의 카테고리에 해당하는 점군을 수작업으로 선택하고 분리하여 Fig. 4와 같이 카테고리별로 분류하였다.
라벨링까지 완료된 데이터는 마지막으로 딥러닝에 적용하기 위해 텍스트 파일의 형태로 추출하였다. 이때 각각의 점들은 위치 정보인 x, y, z 좌표값과 색상 정보인 RGB값을 포함한다. 본 연구에서는 터널 단면의 크기와 형상에 대한 영향을 검토하므로 이와 관계없는 변수인 색상에 의해 영향을 받지 않도록 3D 캐드로 구축한 모델에 모두 동일하게 회색을 부여하여 추출하였다. 라벨링을 통해 카테고리별로 분류되어 추출된 포인트들은 입력 데이터로서 학습에 활용되기도 하고, 테스트 데이터로 활용될 때에는 객체 분할의 결과가 참인지 거짓인지를 평가하는 기준이 되기도 한다.
4. 포인트넷 기반의 터널 객체 분할 인식 파라미터 연구
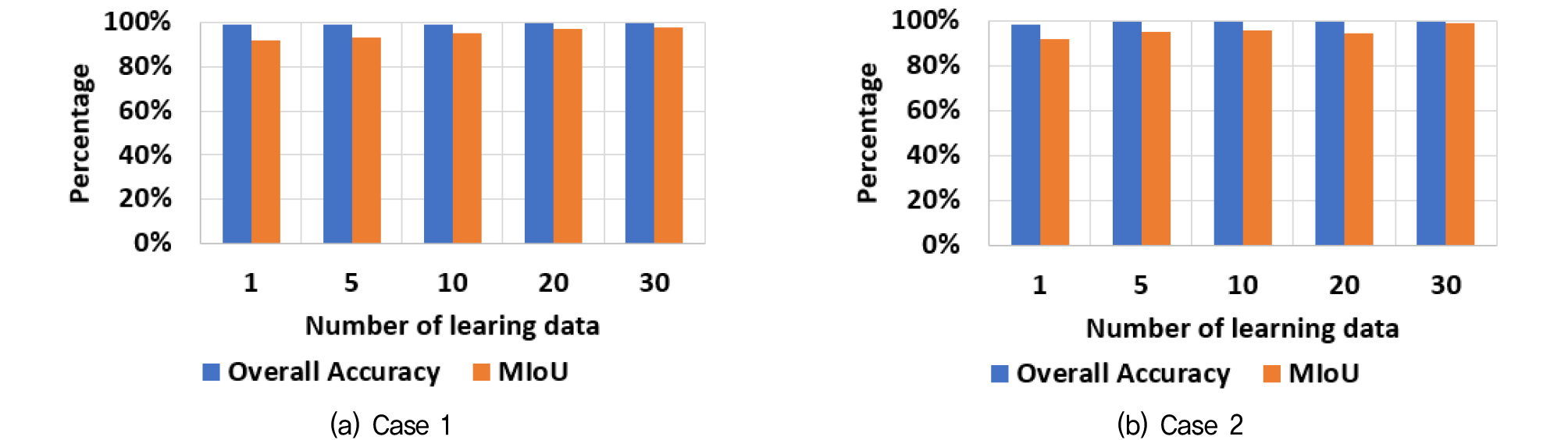
4.1 동일한 터널 데이터를 사용한 경우
학습과 테스트에 동일한 터널을 사용하는 것과 학습 데이터의 수가 터널 객체 분할 정확도에 미치는 영향을 확인하고자 Table 2의 Case 1, 2를 수행하였다. Case 1과 2는 학습과 테스트에 각각 복선 소형과 단선 터널을 사용하였고 학습 데이터의 수를 하나부터 증가시켜가며 해석을 수행하여 구성요소를 얼마나 잘 구분하여 인식하였는지를 OA(Overall Accuracy)와 MIoU(Mean Intersection over Union)의 변화를 통해 확인하였다. OA는 테스트 데이터에 포함된 전체 점들 가운데 정확하게 인식하여 분류해낸 점이 얼마나 되는지를 의미하는 것으로 식 (1)과 같이 표현된다. MIoU는 각각의 카테고리별 IoU(Intersection over Union)의 평균값이며 식 (2)와 같이 표현된다. IoU는 객체 분할 성능을 평가하는데 일반적으로 사용되는 도구로서 테스트에 의해 카테고리로 예측된 점들 중에 옳게 예측된 점의 비율을 의미하는 것이다. 정확도(accuracy)는 계산 과정에서 해당 카테고리로 라벨링된 점의 개수를 분모로 가지지만 IoU는 참, 거짓에 관계없이 테스트 결과 해당 카테고리로 분류된 점의 개수를 분모로 가진다.
Table 2.
Learning and test data for each case
여기서, n은 분류한 카테고리의 수로 앞서 정의한 바와 같이 6이다. GT, TP, FP는 각각 Ground truth, True-positive, False-positive에 속하는 포인트의 개수이다. GT는 해당 카테고리로 정의된 모든 점의 수를 의미한다. TP는 해당 카테고리로 분류된 점들 중 실제로 참인 점의 수를 의미한다. FP는 다른 카테고리에 해당하는 점이지만 해당 카테고리로 잘못 분류된 점의 수를 의미한다. 예를 들어 설명하면, 라벨링에 의해 라이닝으로 정의된 점의 수가 100개라면 GT는 100이고, 테스트 결과 라이닝으로 분류된 점이 120개이고 이 중에 실제로 라이닝인 점이 80개 그렇지 않은 점이 40개라면 TP는 80, FP는 40이 되며 이 경우 정확도는 80%, IoU는 57.1%가 된다.
Case 1, 2를 학습 데이터의 수를 늘려가며 진행한 결과는 Fig. 5와 같다. 테스트 결과, 학습 데이터를 하나만 사용해도 두 가지 case 모두 OA와 MIoU가 90%를 초과하는 것으로 나타나 학습과 테스트에 동일한 터널을 사용할 경우, 학습 데이터 수가 적어도 높은 분류 성능을 보이는 것을 알 수 있었다. 또한, 학습 데이터의 수가 30개에 이르면 OA는 100%에 근접하며 MIoU도 97~98% 정도로 수렴하는 것을 확인하였다. 이를 근거로 하여 이후에 수행할 Case의 학습 데이터 수는 모두 30개로 동일하게 적용하여 다른 변수를 고려할 때 영향을 미치지 않도록 제한하였다.
4.2 서로 다른 크기의 복선 터널 데이터를 사용한 경우
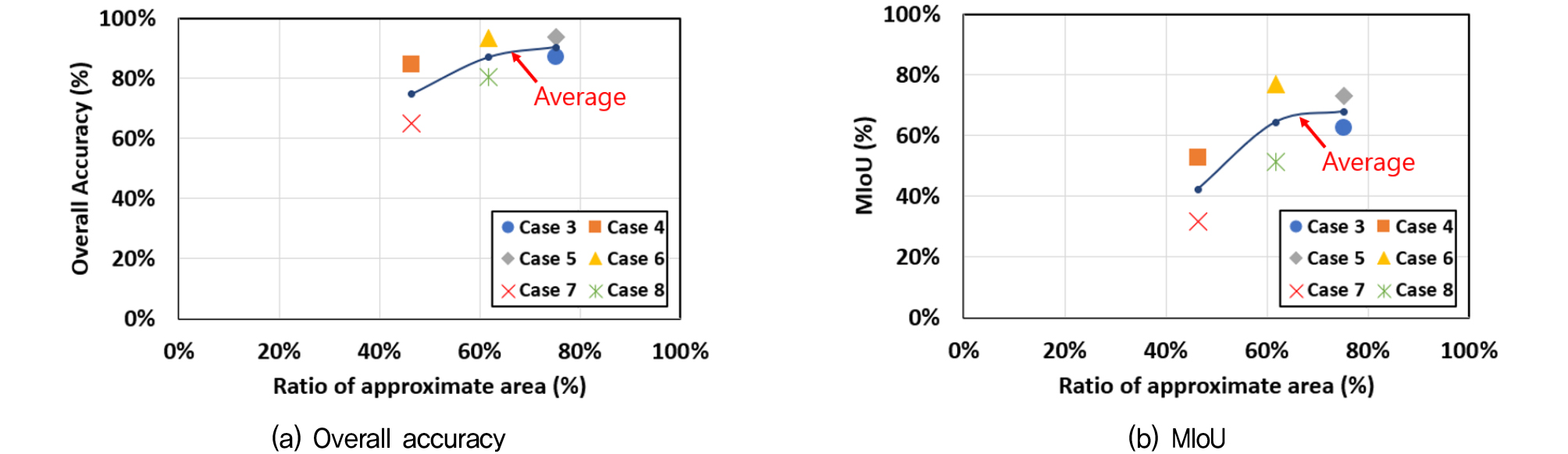
학습 데이터와 테스트 데이터에 모두 복선 터널을 사용하나 두 터널의 단면 크기가 다른 경우에 객체 분할에 어떤 영향이 있는지 살펴보기 위해 Case 3부터 Case 8까지 수행하였다. 테스트 결과는 Table 3과 같이 정리하였는데 학습과 테스트에 같은 데이터를 사용한 경우와 비교하기 위해 4.1절의 Case 1에서 학습 데이터의 수가 30개인 경우의 결과를 함께 나타내었다. 표의 내용 중 근사 면적(approximate area)의 비율은 학습 데이터와 테스트 데이터에 사용된 터널의 근사 면적 사이의 비율을 의미하며 이는 둘 사이에서 상대적으로 작은 값을 큰 값으로 나눈 값이다. 이때, 터널의 근사 면적은 Table 1에 나타낸 것과 같이 터널의 가로폭과 높이를 곱한 값을 의미한다.
Table 3.
Test results from Case 1 to Case 8 according to the ratio of approximate area (except for Case 2)
Table 3의 결과값을 통해 알 수 있듯이, 학습과 테스트에 동일하게 복선 소형 터널을 사용한 Case 1의 경우는 OA와 MIoU가 모두 100%에 가까운 결과를 보였으나, 학습에 각각 복선 중형과 복선 대형을 사용한 Case 3과 4는 OA는 각각 87.0%와 84.7%, MIoU는 62.5%와 52.9%로 객체 분할 성능이 감소한 것을 확인할 수 있었다. 이를 통해 기존에 Soilán et al.(2020)에서와 같이 학습과 테스트에 동일한 터널을 사용하여 객체 분할 성능을 도출하는 것은 정확도 결과가 과대평가될 수 있음을 알 수 있다. 또한 새로운 터널에 대해 객체 분할을 수행할 때마다 해당 터널 데이터로 새로 학습을 진행해야 하므로 시간이 소요되어 객체 분할을 적용하기에 수고로움이 있음을 알 수 있다.
Fig. 6은 근사 면적 사이의 비율을 가로축으로 하였을 때의 Case 3부터 8까지의 테스트 결과를 도시한 것이다. 테스트 결과, 터널 사이의 근사 면적 차이가 가장 적은 복선 소형과 복선 중형을 학습과 테스트에 각각 활용한 Case 3과 Case 5의 평균 성능이 가장 좋았다. 반면에 근사 면적간의 차이가 가장 큰 복선 소형과 복선 대형을 사용한 경우인 Case 4와 Case 7의 평균 정확도는 가장 낮았다. 이로부터 서로 다른 크기의 복선 터널 데이터를 사용할 경우, 둘 사이의 크기가 비슷할수록 객체 분할 인식의 정확도가 높아지는 것을 알 수 있었다.
4.3 서로 다른 유형의 터널 데이터를 사용한 경우
학습 데이터와 테스트 데이터에 복선 터널과 단선 터널과 같이 그 유형이 다른 터널을 사용하는 경우 객체 분할 인식에 어떤 영향이 있는지 살펴보기 위해 Case 9부터 Case 14까지 수행하였다. 테스트 결과는 Fig. 7과 같다.
Fig. 7의 (a)를 통해 알 수 있듯이 단선 터널 데이터로 학습하여 복선 터널을 테스트한 경우는 모두 MIoU가 50%에 미치지 못하는 수준의 낮은 정확도를 보였다. 반면에 복선 터널 데이터를 학습하여 단선 터널을 테스트한 경우에는 Fig. 7의 (b)와 같이 상대적으로 높은 정확도를 보였다. 이러한 차이가 발생한 이유는 단선과 복선의 선로와 침목 데이터의 포인트 수에 있다. 각각의 터널별 선로와 침목 데이터 포인트 수의 합을 단선 터널인 경우를 1로 하여 정규화하면 Table 4와 같다.
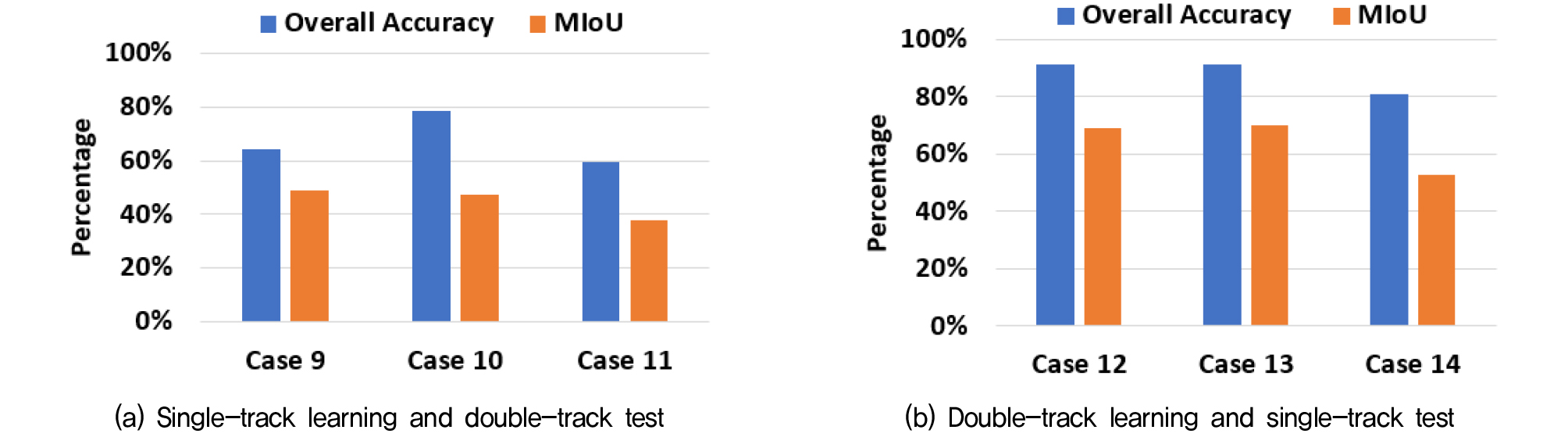
Table 4.
Total number of point data on rail and sleeper for each tunnel normalized based on a single-track tunnel
| Single | Double-S | Double-M | Double-L |
| 1 | 1.75 | 1.84 | 1.81 |
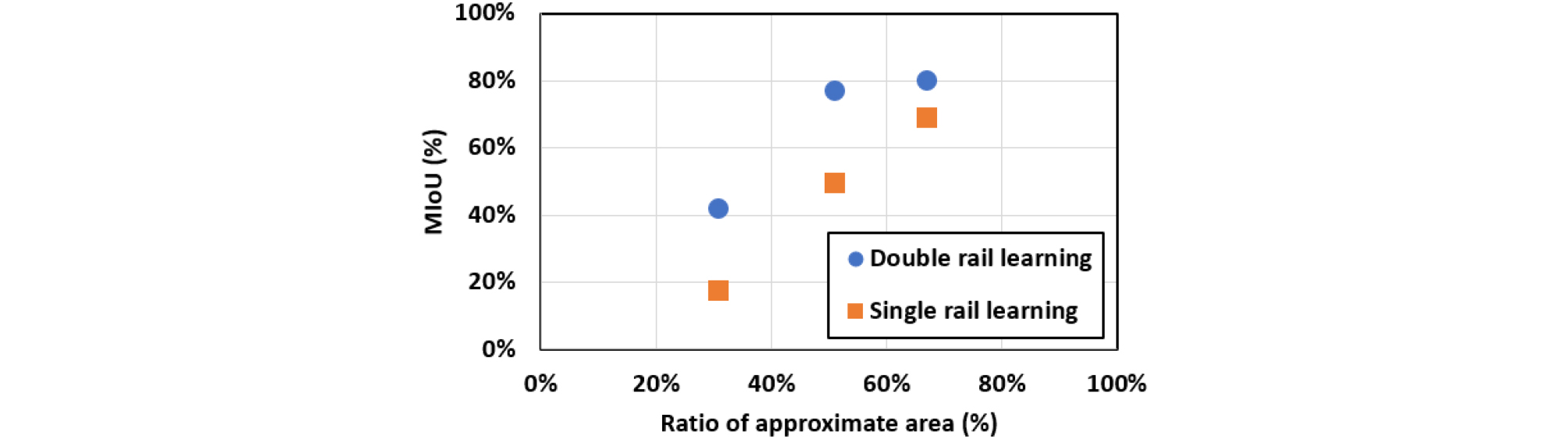
Table 4를 통해 알 수 있듯이 선로와 침목의 데이터 포인트 수는 복선이 단선에 비해 약 1.8배 가량 더 많은 것을 알 수 있다. 같은 복선 터널 사이의 선로와 침목 포인트 개수의 합계가 조금씩 다른 것은 3D 캐드 모델에서 포인트 클라우드로 변환하는 과정에서 샘플링된 포인트의 개수에 차이가 발생하기 때문이다. Fig. 8은 앞서 4.2절에서와 같이 학습과 테스트 터널 사이의 근사 면적 비율을 고려하였을 때 선로와 레일에 대한 IoU의 평균을 나타낸 것이다. 이를 통해서 알 수 있듯이 근사 면적 비율이 동일한 경우 모두 복선 터널로 학습하여 단선 터널을 테스트한 것의 결과가 더 높은 것을 알 수 있다. 또한, 이 경우에도 학습 데이터와 테스트 데이터의 단면의 크기가 유사할수록 정확도가 높게 나타났는데 이를 통해 정확도에 단면의 크기가 영향을 미친다는 것을 다시 한번 확인할 수 있었다.
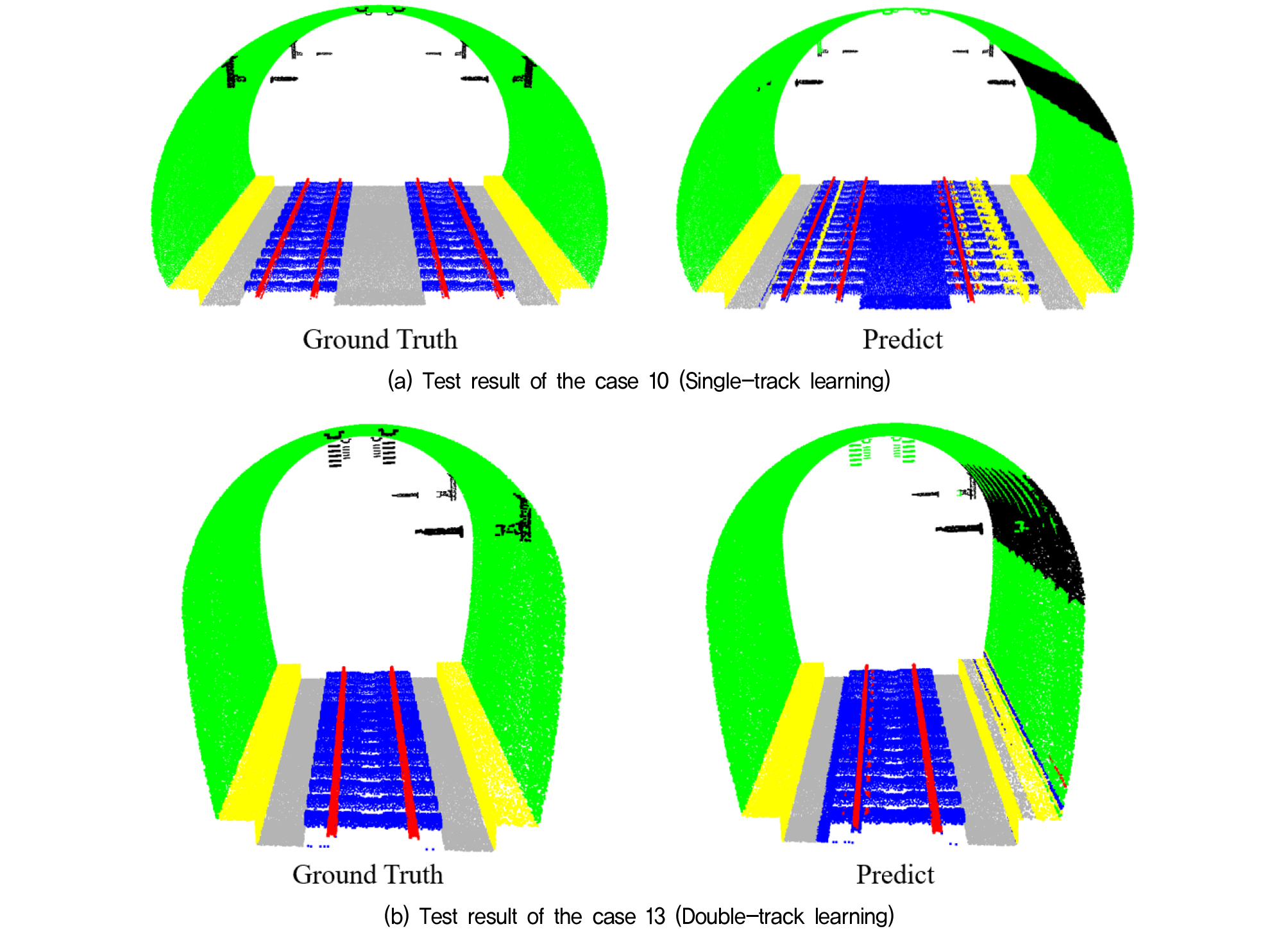
선로와 침목에 대한 객체 분할 인식 정확도의 상승은 Fig. 9에서 볼 수 있듯이 단선 터널 데이터로 학습하여 복선을 테스트한 Case 10에 비해 복선 터널 데이터로 학습하여 단선을 테스트한 Case 13이 선로와 침목을 인식하는데 오답률이 더 적어 Ground truth에 가까움을 알 수 있으며 이로 인해 선로와 침목 주위에 위치한 배수로와 바닥부에 대한 오답률 역시 함께 감소하여 전체적으로 정확도가 상승하는 결과를 보였다.
4.4 다양한 데이터를 사용한 경우
학습에 두 가지 이상의 데이터를 사용할 경우의 정확도 변화 양상을 확인하고자 복선 터널 세 가지를 대상으로 테스트를 수행하였다. 테스트는 Case 15부터 Case 20까지 총 여섯 가지 경우에 대해 수행하였다. Case 15, 16, 17은 테스트에 사용한 터널을 제외한 나머지 복선 터널을 학습하여 테스트하였고 Case 18, 19, 20은 단선 터널 데이터까지 추가하여 학습하였다. 학습 데이터에 사용되는 터널의 가지 수가 늘어나더라도 학습 데이터의 수는 30개를 유지하여 학습 데이터 양 증가에 따른 정확도 증가를 배제하였다. 각각의 복선 터널의 학습 데이터에 따른 테스트 결과는 아래 Table 5에 정리하였고 학습 데이터에 사용한 터널의 수와 정확도의 변화를 Fig. 10과 같이 도시하였다. Fig. 10에서 학습에 사용한 터널의 수가 1로 표기된 경우는 학습에 테스트 데이터를 제외한 나머지 터널로 학습한 경우에 대한 평균값이다. 예를 들어 설명하면, Fig. 10의 (a)의 가로축 1에 해당하는 값은 각각 Table 5의 학습 데이터가 M, L, Single일 때의 Test S의 OA와 MIoU의 평균값을 의미한다.
Table 5.
Test results of the double-track tunnel by each learning data
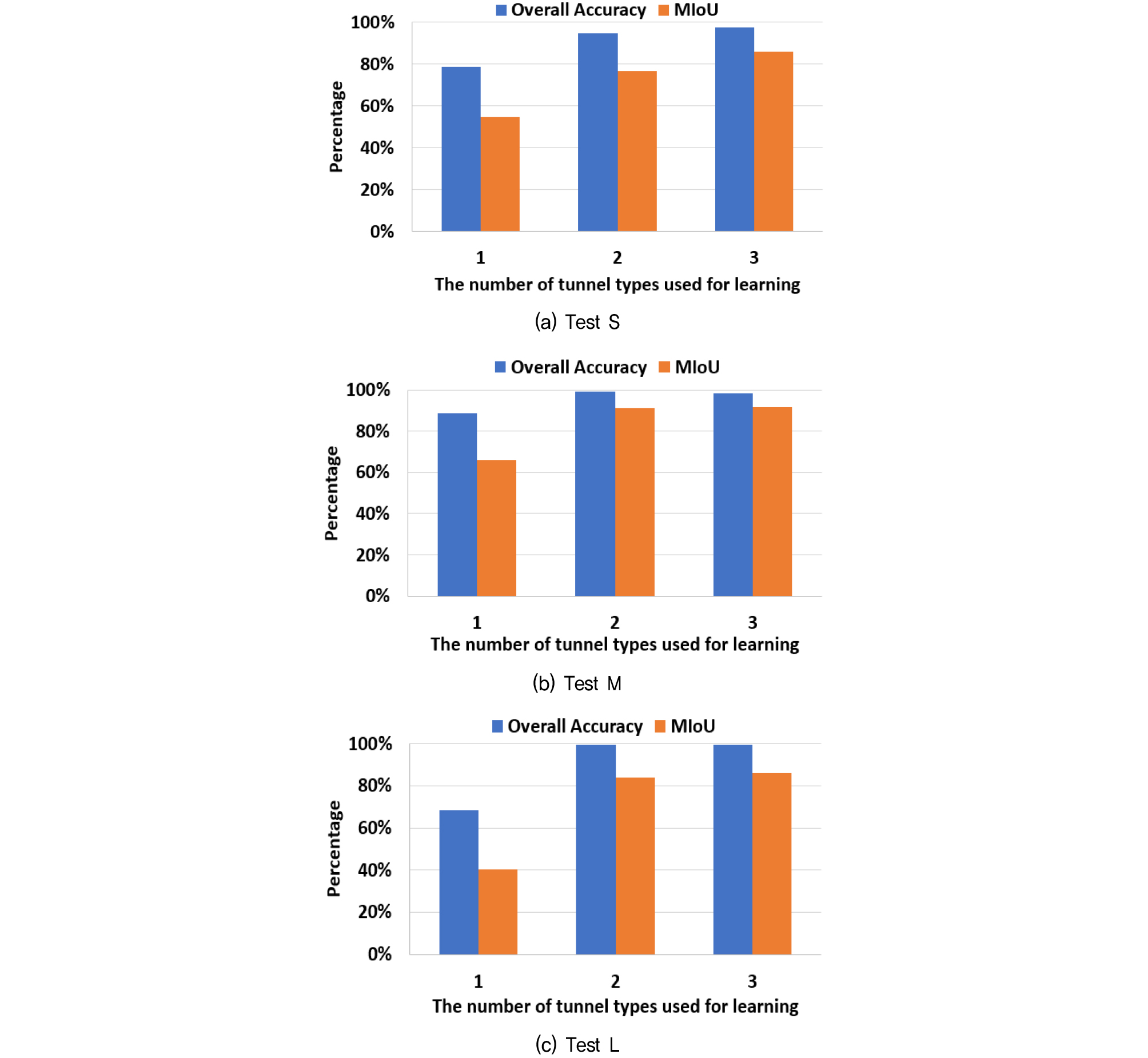
테스트 결과, 한 가지 종류의 터널만 학습에 사용한 경우보다 두 종류의 터널을 학습에 사용한 경우에 객체 분할 인식 정확도가 급격히 증가하는 것을 확인할 수 있었다. 세 가지 복선 터널 모두에서 Overall accuracy는 약 10~30%가량 증가하였고 MIoU는 20~45%가량 증가하였다. 또한, 복선 터널과는 다른 유형인 단선 터널을 학습 데이터에 추가하였을 경우 두 가지 복선 터널만을 학습했을 때와 비교해 적게는 1~2%, 많게는 8~9%가량 객체 분할 정확도가 증가하였다. 이러한 결과로부터 학습 데이터의 수가 충분할 경우에 학습 데이터로 여러 종류의 터널을 활용할수록 객체 분할 인식 적용성 증대될 것이라는 결론을 얻을 수 있었다.
5. 결 론
본 논문에서는 서로 다른 학습 데이터 조건에서 터널의 객체 분할 인식을 수행하여 각각의 정확도를 비교하는 매개변수 연구를 수행하였다. 매개변수 연구 결과로부터 학습과 테스트에 동일한 터널을 사용하는 것은 해당 알고리즘의 객체 인식 성능을 평가하는데 한계가 있음을 증명하였으며 테스트 결과에 신뢰성을 확보할 수 있을만큼 학습 데이터 수를 충족하였다면 학습 데이터의 종류를 다양하게 할수록 효율적인 터널 객체 분할 인식이 가능함을 알 수 있었다. 연구 수행 결과를 종합해보면 다음과 같다.
(1) 학습과 테스트에 동일한 터널 데이터를 사용하는 경우 하나의 학습 데이터만으로도 OA와 MIoU가 모두 90%를 초과하는 결과를 보였다. 그러나 학습과 테스트에 사용한 터널의 단면의 크기가 서로 다른 경우에는 OA와 MIoU가 각각 13~15%, 35~45% 가량 감소하는 모습을 보였다. 이를 통해 학습과 테스트에 동일한 데이터를 사용하여 객체를 분할 인식하는 방법은 새로운 형상의 터널을 대상으로 객체 분할을 수행할 때마다 새롭게 학습 DB를 구축해야 하는 번거로움이 있어 범용성이 떨어지는 것을 확인할 수 있었다. 또한, 학습과 테스트에 사용한 터널의 단면 크기가 서로 다른 경우에는 각 터널의 근사 면적이 유사할수록 객체 분할 인식의 정확도가 증가하는 경향을 보였다.
(2) 학습과 테스트에 복선 터널과 단선 터널을 각각 활용한 경우 서로 다른 크기의 복선 터널을 활용한 경우에 비해 정확도가 감소하는 것을 확인하였다. 단선 터널을 학습하여 복선 터널을 테스트하는 경우, OA와 MIoU가 모두 5~25%가량 감소하는 것을 확인할 수 있었다. 다만, 복선 터널을 학습하여 단선 터널을 테스트하는 경우는 상대적으로 높은 정확도를 보였는데 이는 복선 터널의 선로와 침목에 대한 학습 데이터 양이 단선 터널의 약 1.8배 수준이기에 선로와 침목에 대한 객체 분할 인식 정확도가 증가되었고 이와 함께 선로와 침목 주변의 배수로와 바닥부에 대한 정확도도 증가하며 전체적으로 정확도가 증가한 것으로 판단하였다.
(3) 학습 데이터로 두 종류 이상의 터널 데이터를 활용할 경우 객체 분할 인식 정확도가 크게 증가하는 것을 확인하였다. 하나의 터널을 학습한 경우보다 두 종류의 터널을 학습한 경우에 OA와 MIoU가 적게는 10%에서 많게는 50%가량 증가하였다. 또한, 학습 데이터에 테스트 데이터와 선로의 수가 다른 단선 터널을 추가하였을 경우에도 정확도 개선이 소폭 이루어지는 것을 확인하였다. 이를 통해 철도 터널 객체 분할 인식에서 학습 데이터의 수가 충분하다면 다양한 종류의 터널로 학습 데이터를 구성하여 효율성을 증대할 수 있음을 확인하였다.
