

1. 서 론
2. SSI가 고려된 단자유도모델
3. 학습 데이터세트 구축
4. ANN 모델
4.1 ANN 모델 개발
4.2 데이터베이스 통계
5. 결과 및 토의
5.1 ANN 모델 개발 결과(double outputs)
5.2 백분위에 따른 최적 ANN 모델 산정
6. 결 론
1. 서 론
2017년 포항 지진 이후, 구조물의 내진성능 관련 데이터베이스 구축에 관한 연구가 진행 중이지만 구조물의 대형화로 인해 컴퓨터 해석을 활용한 데이터베이스 구축은 많은 시간 및 인력, 비용을 발생시킨다. 또한 실제 지진에 대한 구조물의 동적 응답을 산정하기 위해서는 지반과 구조물 사이의 상호작용(Soil-Structure Interaction, SSI)이 고려되어야 하는데(Stewart et al., 1999), 다양한 지반조건 하에서 FLAC3D(Rayhani and El Naggar, 2008)와 같은 FDM이나 FEM 기반 상용소프트웨어를 이용한 해석은 모델링 및 데이터베이스 구축에 많은 시간이 소요된다. 따라서 상대적으로 간편한 데이터베이스 구축 방법 및 지진응답 예측 모델이 필요하다.
선행 연구자들에 의해 개발된 다양한 예측모델 기법 중 인공 신경망 기법(Artificial neural network, ANN)은 머신러닝기법 중 한 가지 기법으로 생물학에서 기원되었다. 생물학적인 뇌는 수십억개의 뉴런과 네트워크로 구성되어 있으며 연결 네트워크에 따라 정보처리가 다르게 된다. ANN은 이러한 복잡한 뇌의 구조에서 기인하여 한 개 또는 여러 개의 층(layer)과 층에 존재하는 여러 개의 뉴런을 서로 연결하는 신경망을 생성하여 복잡한 비선형 공학문제들의 예측 모델 개발에 이용된다(Kartam et al., 1997; Shahin et al., 2001). 특히 지반공학에서는 말뚝의 표면마찰력 예측(Goh, 1994; 1995), 지반진동(ground motion) 파라미터 예측(Alavi and Gandomi, 2011), 터널현장의 지반침하 예측(Yoo and Yang, 2020) 등에 ANN을 이용한 연구가 진행되었다.
본 연구는 간단한 단자유도모델(Single-Degree-Of-Freedom, SDOF)을 이용하여 SSI를 고려한 건물의 지진응답 데이터베이스 구축 및 ANN 예측모델 개발에 대하여 논의하였다. 건축물의 지진응답에 영향을 미칠 수 있는 지반과 지진의 특성을 입력변수로 설정하였으며, 내진성능을 평가할 수 있는 최대변위와 최대 전단력을 출력변수로 선정하였다. ANN 모델의 경우 출력변수의 노드 수를 다르게 적용하여 해당 성능을 분석하였으며, 마지막으로 데이터 백분위에 따른 ANN 모델 성능에 대하여 논의하였다.
2. SSI가 고려된 단자유도모델
본 연구에서는 데이터베이스 구축을 위하여 Lu(2016)에서 제안한 SSI가 고려된 단자유도모델을 이용하였다. 건물에 가해지는 주파수영역(frequency domain) 지진파에 대한 선형 동적응답 산정을 위한 지반진동(ground motion)식은 아래와 같다.
| $$\left(-\omega^2\left[M\right]+i\omega\left[C\right]+\left[K\right]\right)\left\{U\right\}=-\left[M\right]\left\{R\right\}{\ddot U}_g$$ | (1) |
여기서 ω (T-1)는 각진동수(angular frequency), i는 허수, {U}는 변위 벡터, {R}은 {1,1,0}, Üg는 조화지반가속도(harmonic ground acceleration)이다. [M], [C], [K]는 각각 질량(mass), 감쇠(damping), 강성(stiffness)행렬로 SDOF시스템에서는 아래와 같이 표현된다.
여기서 m(M)은 구조물의 질량, J(ML2) 질량 모멘트, c(MT-1) 동적감쇠계수(dynamic damping coefficient), k(MT-2)는 동강성(dynamic stiffness), h(L)는 단자유도모델 높이이다. 여기서 아래첨자 s,f,h,θ는 각각 구조물, 기초, 수평방향, 방사방향을 의미한다. cs, ch, cθ(ML2T-1), kh, kθ는 각각 아래와 같이 표현된다(Gazetas, 1991; Lu, 2016).
| $$k_h=\alpha_h\left(\omega,V_s\right)K_h;\;\;k_\theta=\alpha_\theta\left(\omega,V_s\right)K_\theta$$ | (3) |
| $$c_s=2\xi_s\left(k_sm\right)^{0.5};\;\;c_h=2\xi_h\left(k_hm_f\right)^{0.5};\;\;c_\theta=2\xi_\theta\left(k_\theta J_f\right)^{0.5}$$ | (4) |
여기서 α(-)는 임피던스 계수(impedance term(Stewart et al., 1999)), K(Kh(MT-2), Kθ(ML2T2))는 점탄성 공간(viscoelastic half-space)에서의 정강성(static stiffenss), ξ(-)는 감쇠계수(damping coefficient)이다. Eq. (3)과 (4)의 α는 ω와 지반의 전단파속도(VS (LT-1))의 함수이며 본 논문에서는 Veletsos and Verbič(1973)에서 제안한 식을 이용하여 α를 산정하였다. Kh와 Kθ는 각각 아래와 같이 표현된다.
| $$K_h=\frac{8r}{2-v}G;\;\;K_\theta=\frac{8r^3}{3\left(1-v\right)}G$$ | (5) |
여기서 r(L)은 원형얕은기초(circular shallow foundation)의 반지름이다. Fig. 1과 같이 주어진 시간영역 지반가속도 데이터를 푸리에 변환(Fourier transform)한 Üg를 Eq. (1)에 대입하여 구한 {U}를 역푸리에(inverse Fourier transform)하면:
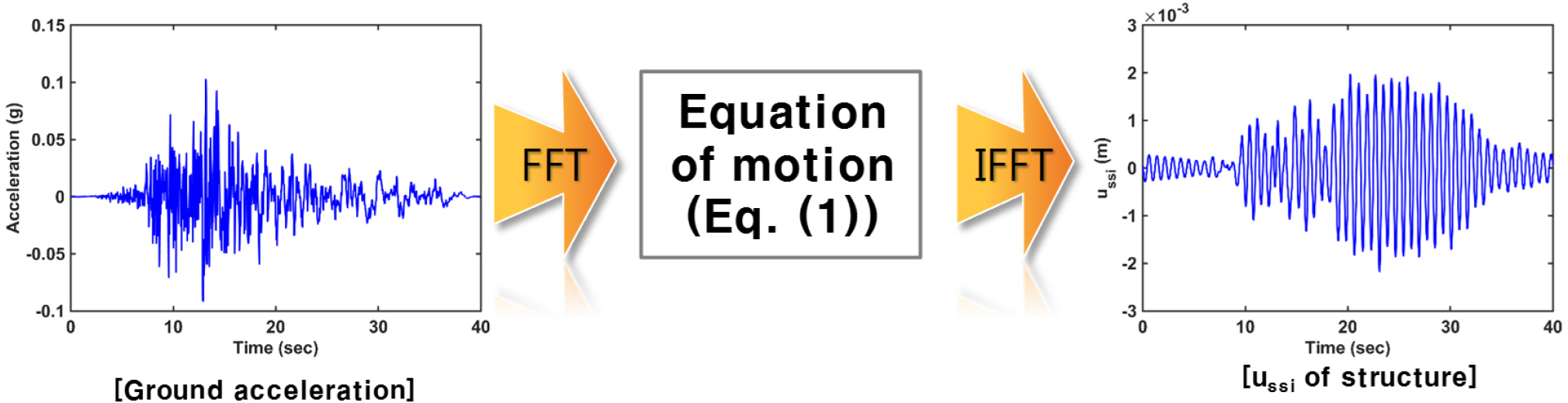
| $$\left\{u\right\}=\begin{bmatrix}u_{ssi}\\u_h\\\theta\end{bmatrix}$$ | (6) |
여기서 ussi(L)은 SSI system에서의 구조물의 변위, uh(L)는 기초의 수평 변형(horizontal translation), θ(-)는 기초의 회전각(rotation)이다. 한편 구조물의 전단력(shear force)은 -ω2{U}를 역푸리에하여 (LT-2)를 구한후 여기에 m을 곱하여 구한다. 본 연구에서는 구조물의 선형 거동만 고려하였다.
3. 학습 데이터세트 구축
본 연구에서는 다양한 지반정보와 지진 시나리오를 고려하기 위하여 총 8가지의 입력변수(input parameters) (Table 1)를 학습 데이터 생성에 이용하였고 출력변수(output parameters)는 내진성능평가에 이용할 수 있는 구조물의 최대변위(maximum displacement)와 최대전단력(maximum shear force)으로 선정하였다(Medhekar and Kennedy, 2000; Xu et al., 2014). 지반관련변수로는 포아송비(ν in Eq. (5)), 전단파속도(Vs in Eq. (3)), 기초-구조물 하중비(foundation to structure mass ratio, mf/m)를 선정하였고 다양한 지반조건을 모사하기 위해 비교적 큰 범위의 변수를 학습 데이터세트 구축에 이용하였다. 지진파는 Pacific Earthquake Engineering Research(PEER)에서 제공하는 지진 데이터베이스에서 단단한 토사지반(SD class, IBC(2012))에서 측정된 중규모 이상(Mw, 5.7~7.4, Table 1)의 지진 기록 중 164개의 지진파를 임의로 선택하여 활용하였다.
Table 1.
Summary of input parameter and total number of data
| Input parameters | Model range | Note | |||
| Minimum | Maximum | Increment | |||
| Earthquake | Mw | 5.74 | 7.35 | - |
164 earthquake records measured at site class (SD) among 3000 PEER Database |
| ED (km) | 2.47 | 142.58 | - | ||
| PGA (g) | 0.10 | 0.70 | - | ||
| PGV (cm/sec) | 4.51 | 102.22 | - | ||
| PGD (cm) | 0.55 | 62.49 | - | ||
|
Geotechnical parameters | η | 0.1 | 0.7 | 0.1 | (Baker, 2007; Chuanromanee et al., 1970) |
| ν | 0.15 | 0.5 | 0.05 | Budhu (2000), Ganjavi et al. (2016), IBC (2012), from loose sand to soft clay | |
| Vs (m/sec) | 90 | 760 | 90 and 100 | IBC (2012), from soft soil to very dense soil | |
| Total number of maximum displacement and shear | 73,472 | ||||
4. ANN 모델
4.1 ANN 모델 개발
ANN 모델은 입력층(input layer), 은닉층(hidden layer), 그리고 출력층(output layer)로 구성되어 있다. 각각의 layer는 여러 개의 노드(node)로 구성되어 있으며 특히 입력층과 출력층의 노드의 개수는 각각 입력변수와 출력변수의 개수이다. 따라서 본 연구에서는 각각 8개의 입력노드와 2개의 출력노드가 설정되었다(Fig. 2). 은닉층의 layer및 노드 개수는 임의로 결정이 가능하며 노드 개수는 일반적으로 출력노드와 입력노드 개수 사이의 값은 선택하고 layer 개수는 활성화 함수(activation function)에 따라서 결정한다(Sontag, 1992). 본 연구에서는 6개의 노드를 가진 2개의 은닉층 이용하였다(Fig. 2). 이전 layer의 i번째 노드값(xi)와 다음 layer의 j번째 노드값(xj) 사이의 연결에 적용되는 가중치 함수(weight function)는:
| $$x_j=f\left(\sum_iw_{ij}x_i-b\right)$$ | (7) |
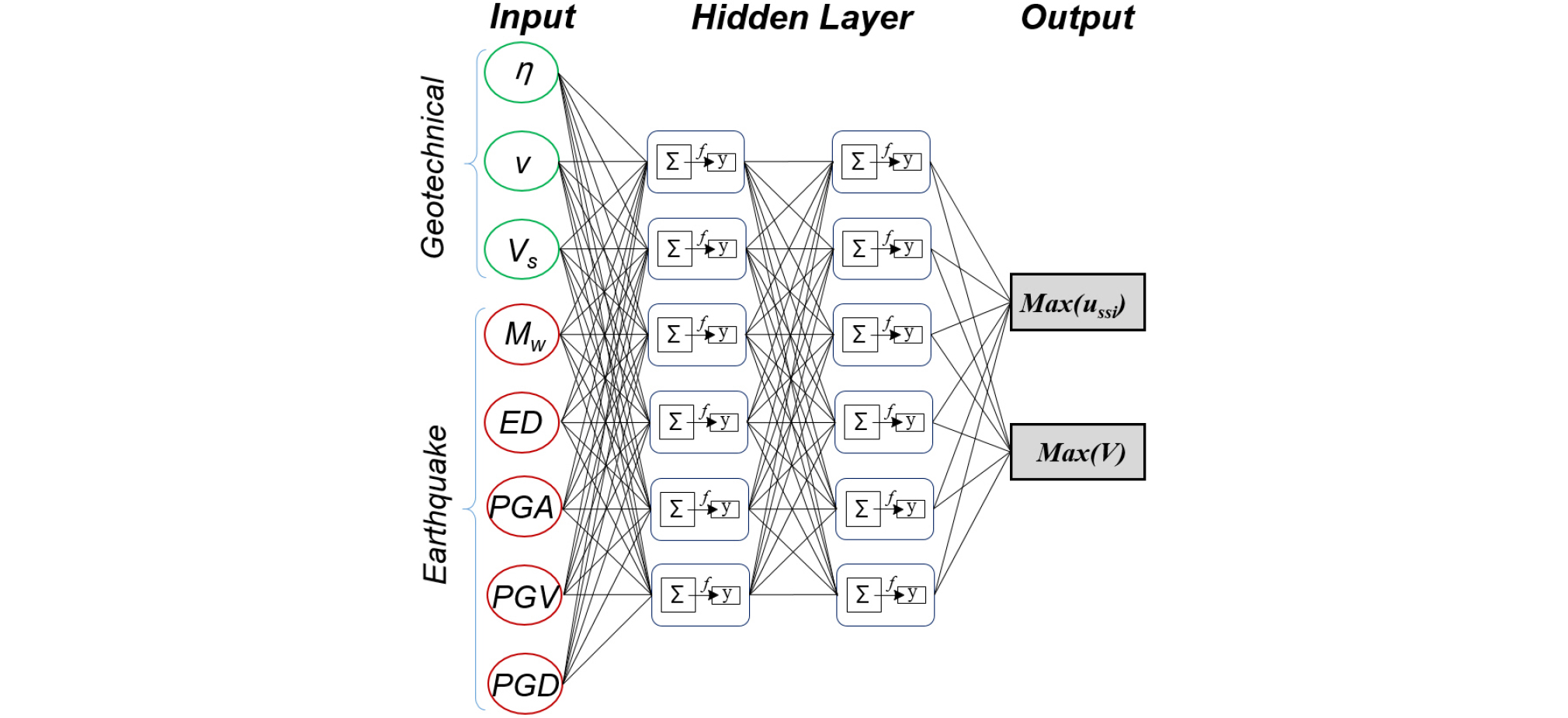
여기서 f는 활성화함수, wij는 xi와 xj사이의 가중치 계수(weight coefficient), b는 bias값이다.
본 연구에서 활성화함수는 ouput 노드값에 비선형성을 반영하고 0에서 1사이의 값을 가지도록 일반적으로 이용하는 sigmoid function을 이용하였고, Training function은 Levenberg-Marquardt backpropagation algorithm을 이용하였다. 총 73,472개의 데이터를 ANN모델을 훈련(training), 모의 시험(validation), 실험(testing)하기 위한 데이터세트는 각 70%, 10% 그리고 20%로 임의로 설정하였다. 또한, Levenberg-Marquardt 알고리즘은 신경망 내의 각 레이어를 통과할 때마다 가중치를 업데이트하여 실제값(actual value)와 예측값(predicted value)사이의 오차를 최소화하기 위한 목적으로 적용되었다. 여기서 모의시험 데이터세트는 각 학습단계 마다 learning rate와 regularization parameter 값을 업데이트하는 방식으로, 과적합(overfitting)을 최소화하기 위하여 활용되었다.
모델의 성능(performance)는 평균 제곱 오차(Mean Square Error, MSE)로 측정하였고 backpropagation algorithm에 의해 구해진 가중치의 편미분 값(gradient)가 1×10-5 이하거나 validation 성능이 6번 연속으로 감소되지 않거나 iteration이 1000번 이상 수행되면 training을 멈추는 stop criteria를 적용하였다. 모델의 학습에는 출력변수인 최대변위와 최대전단력 데이터베이스를 모두 최대값으로 정규화(normalized)시킨 데이터를 이용하였다.
4.2 데이터베이스 통계
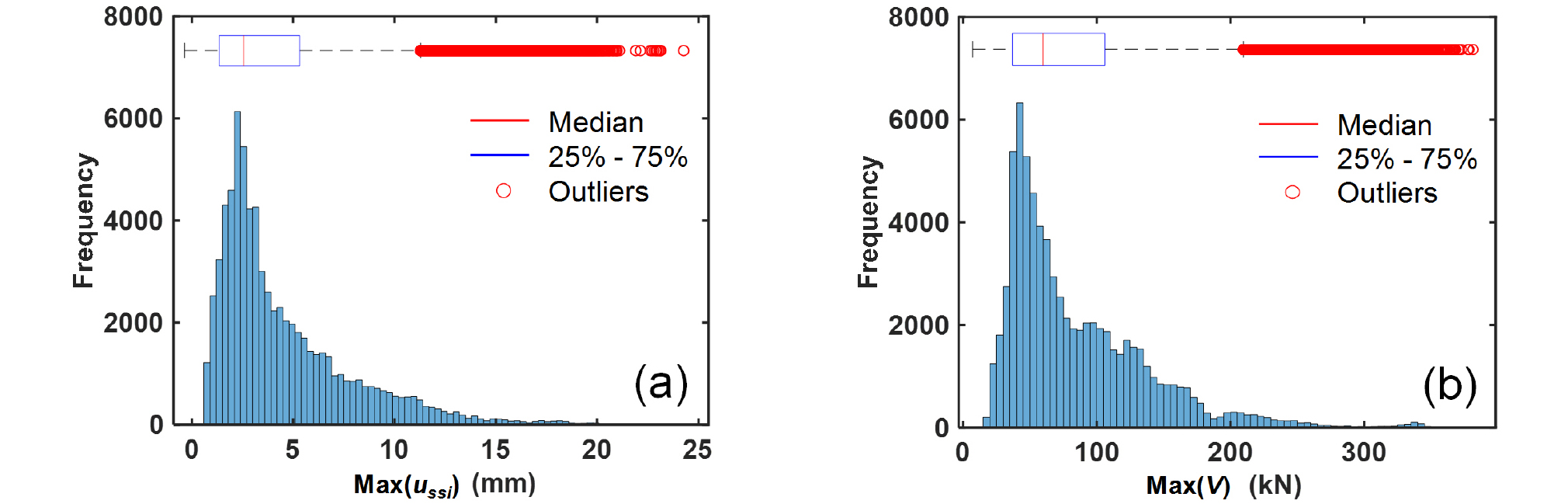
ANN 모델 개발에 이용된 Table 1의 지진파 및 생성된 출력변수의 평균(mean), 중위값(median), 1사분위수(25%, Q1), 3사분위수(75%, Q3)를 Table 2에 나타내었고 출력변수의 데이터 분포를 Fig. 3에 도식화하였다. Table 1의 지반관련 변수는 등간격으로 설정되었으므로 균일분포(uniform distribution)를 나타내기 때문에 Table 2에서 제외되었다.
Table 2.
Summary of input parameter and total number of data
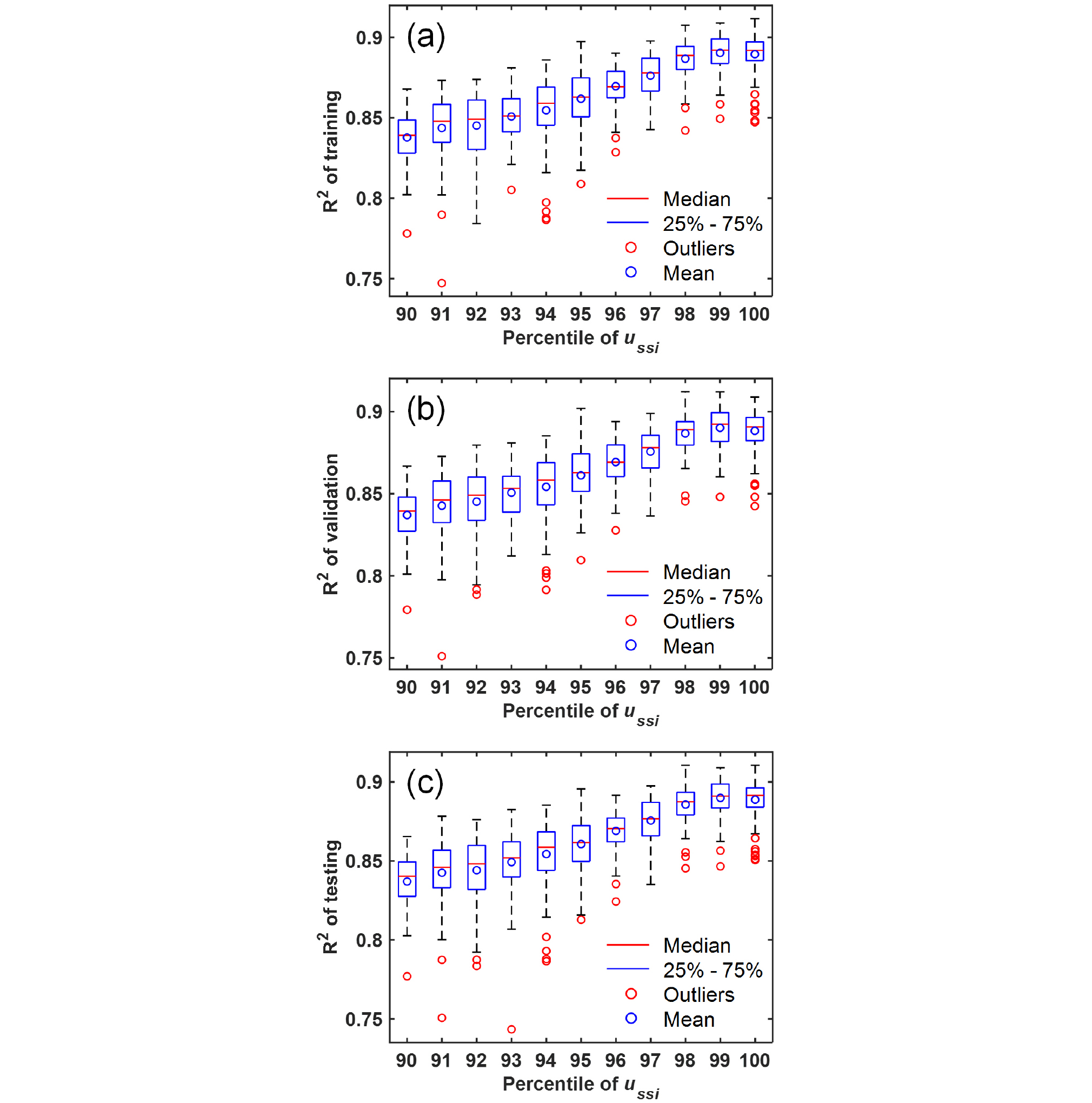
Fig. 3에 도식된 바와 같이 본 연구에서 ANN 모델 개발에 이용된 최대변위와 최대 전단력 분포는 대수 정규 분포(lognormal distribution)의 형태를 보였다. 특히 왼쪽으로 편향된(skewed) 데이터 분포로 인하여 모든 outliers가 큰 값에서 보임을 알 수 있다. Sigmoid 활성화 함수는 입력값과 출력값사이의 비선형성을 충분히 반영할 수 있으나 평균값이나 중간값보다 상대적으로 매우 큰 값들은 ANN 모델의 성능을 저하시킬 우려가 있다. 따라서 본 연구에서는 1% 간격으로 90~100% 백분위(percentile)의 ussi에 대한 ANN 모델의 성능에 대하여 고찰하고 가장 성능이 높은 모델을 최종모델로 선정하였다. ANN 모델의 training, validation, test 데이터 선정은 임의적인 성격을 가지기 때문에 각 백분위당 100번의 모델링을 하여 이를 boxplot으로 분석하였다.
5. 결과 및 토의
5.1 ANN 모델 개발 결과(double outputs)
Fig. 4와 Fig. 5는 각각 SDOF 시스템의 최대변위와 최대전단력에 대하여 ANN 모델을 개발한 결과를 나타낸다. Fig. 4와 Fig. 5는 해석을 통해 산정된 목표값(target output)과 ANN 모델을 통해 예측된 계산값(calculated output)의 Y=T 선형 모델(빨간선)을 활용하여 상관관계를 분석하기 위한 것이다. 이를 바탕으로 개발된 ANN 모델의 학습(training), 모의 실험(validation), 검증 과정(testing)에서의 신뢰도를 분석할 수 있다. Fig. 4와 Fig. 5에 나타난 것과 같이 최대변위와 최대전단력에 대한 ANN 모델의 결정계수(coefficient of determination, R2)는 각각 0.89, 0.87로 상대적으로 높게 나타났다. 이는 개발된 ANN 모델이 상대적으로 높은 정확도를 가짐을 뜻한다. 또한 최대변위와 최대전단력 모두 training과 test에서 유사한 R2값이 나타났는데 이는 개발된 모델에 과적합 문제가 나타나지 않았음을 뜻한다(또는 일반화가 잘 수행되었음을 뜻한다). Fig. 4와 Fig. 5에서 매우 높은 R2(R2 > 0.9)값이 나타나지 않은 이유는 적은 수의 데이터(< 1%)가 mean square error(MSE)를 증폭시켰기 때문으로 판단된다. 특히 최대전단력의 경우 최대전단력이 매우 큰 케이스들(Fig. 5의 Target output이 거의 1에 근접한)에서 모델의 정확도가 떨어지는 것을 볼 수 있다. 따라서 상대적으로 큰 최대전단력을 예측하기 위해서는 다른 활성화 함수 적용, 층이나 노드 개수 변화, 다른 training 함수 이용 등의 방법을 통해 ANN모델의 정확도를 높여야 할 것으로 판단된다. 최초 학습 조건은 1000번의 반복계산을 허용하였으나, Fig. 4(d)에 나타난 바와 같이 각 데이터세트의 MSE가 최소가 되는 지점인 285번의 반복계산에서 학습이 종료되었다. 또한 Fig. 4와 Fig. 5에 개발된 모델은 아래 5.2절에서 설명한 바와 같이 최대변위 기준으로 99% 백분위 데이터가 학습에 이용되었다(총 72,738개).
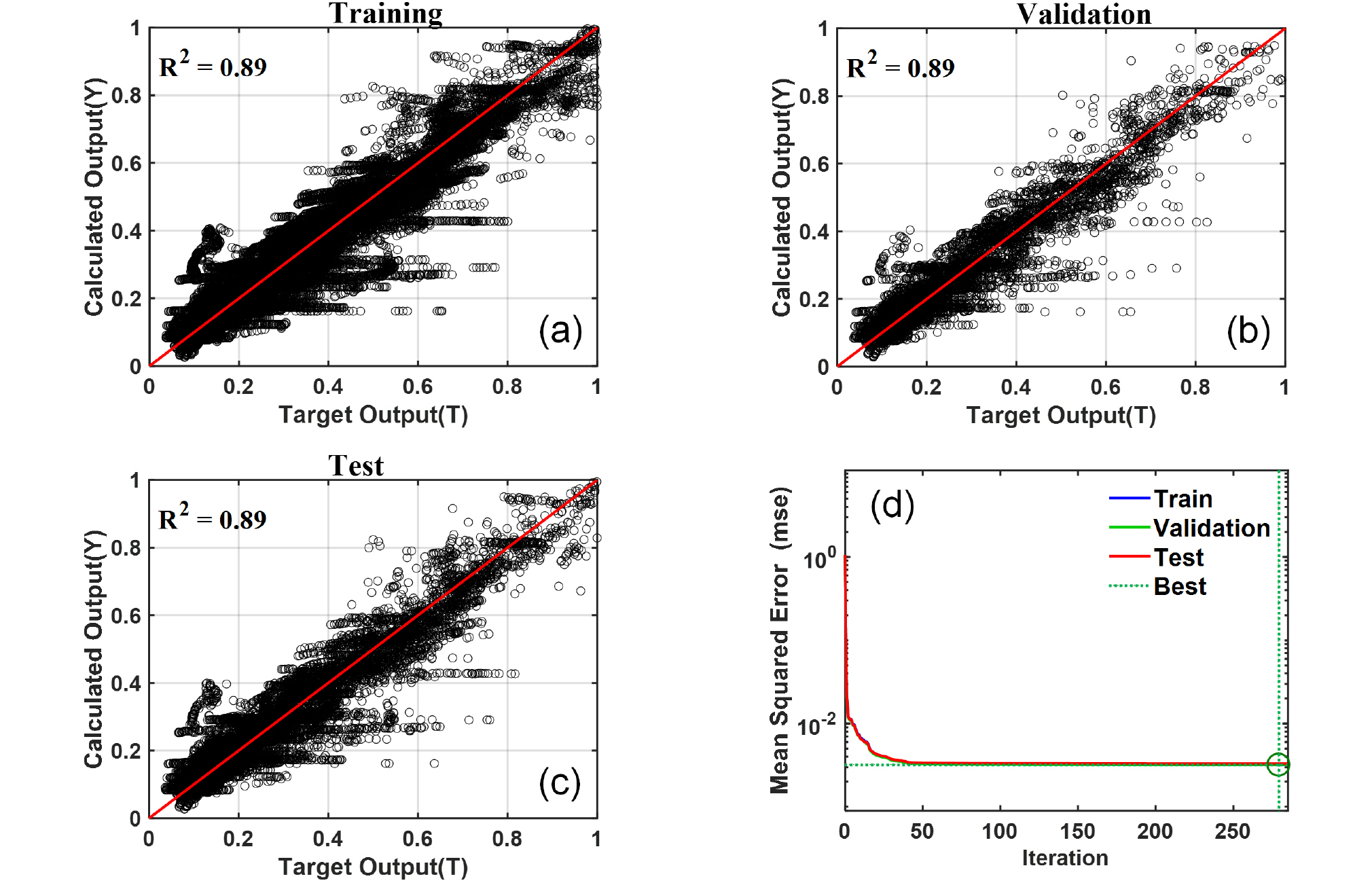
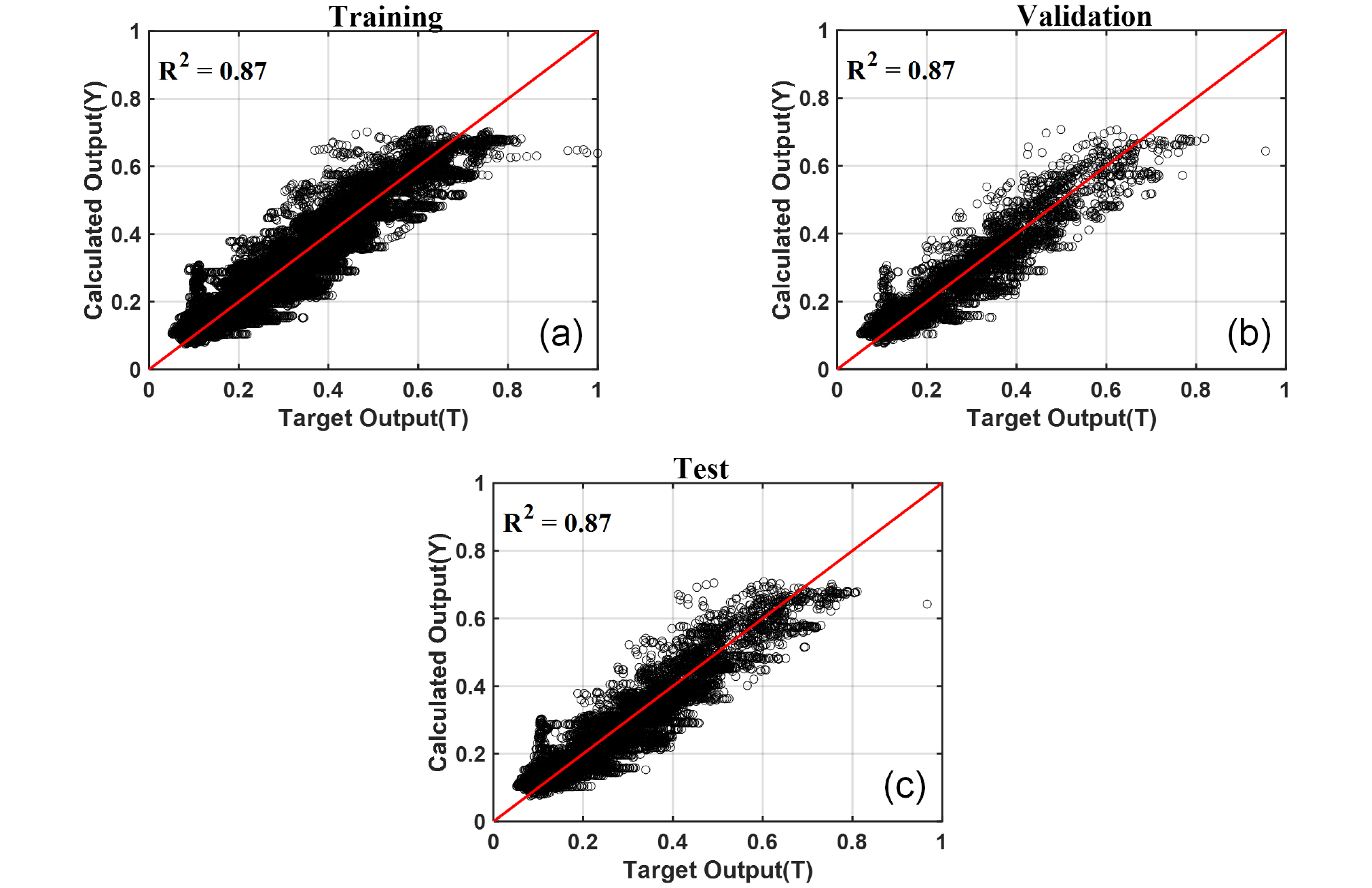
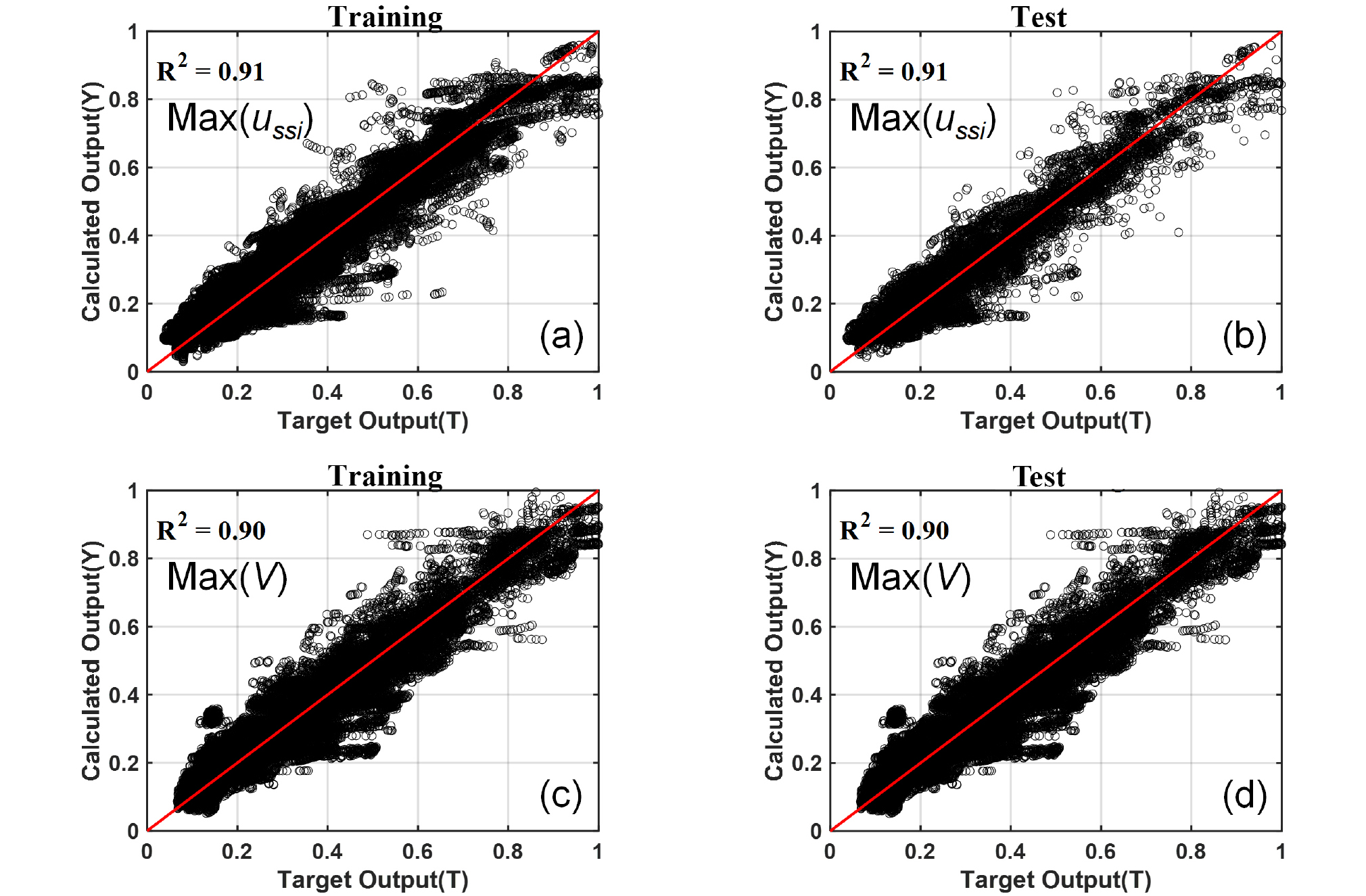
Fig. 6은 모델의 정확도를 높이기 위해 출력변수를 최대변위와 최대전단력 하나씩 설정하여 각각의 ANN 모델을 개발한 결과이다. 이 경우 Fig. 2의 output layer에는 1개의 변수(최대변위 또는 최대전단력)만 존재하게 된다. Fig. 6에 나타난 것과 같이 출력변수를 1개만 설정하였을 때 최대변위와 최대전단력 모두 모델의 정확도가 증가하는 것을 볼 수 있다. 이것은 본 연구와 같이 데이터베이스가 매우 크지 않을 경우 높은 정확도의 ANN 모델 개발은 output layer에 1개의 변수만 설정하여 출력변수에 대하여 각각 ANN 모델을 개발하는 방법이 효과적임을 보여준다. 하지만 single output은 개발된 ANN 적용 시 하나의 출력값(최대변위 또는 최대전단력)만 얻을 수 있기 때문에 최대변위와 최대전단력 모두 필요한 경우 모델을 두번 적용해야되는 단점이 있다. Fig. 6에는 나타나지 않았으나 hyperbolic tangent sigmoid와 선형(linear) 활성화 함수를 이용한 경우 최대변위에 대한 모델의 정확도가 각각 R2=0.9, 0.68로 Fig. 6에서 이용된 log-sigmoid 활성화 함수에 비해 낮게 나타났다.
5.2 백분위에 따른 최적 ANN 모델 산정
4.2절에서 언급한 바와 같이 90~100% 백분위(percentile)의 최대변위에 대한 ANN 모델의 정확도 평가에 대한 결과를 Fig. 7에 나타내었다. Fig. 7에 나타난 바와 같이 최대변위 데이터베이스(Fig. 3(a))를 이용한 ANN 모델의 정확도는 99%의 백분위에서 가장 높은 평균/중간 R2값을 보였다. 다시 말하면 Fig. 3(a)의 가장 큰 최대변위에서부터 1%의 데이터를 삭제하고 학습하였을 때 가장 높은 정확도를 가진 ANN 모델이 개발되었다. 이를 기반으로 5.1절에 나타나있는 Fig. 4, Fig. 5, Fig. 6은 모델 모두 99% 백분위의 데이터를 이용하여 개발되었다. 이와같은 결과는 Fig. 3(a)에서 최대변위가 높은 구간에 데이터의 분포량이 다른 구간에 비해 상대적으로 작기때문에, 해당 구간에서 ANN 모델의 예측 정확도가 떨어진 것으로 사료된다. Fig. 7의 결과는 데이터의 분포에 따라 가장 높은 정확도를 가지는 ANN 모델 개발에 이용할 수 있는 데이터 삭제 범위가 달라질 수 있음을 의미한다. 하지만 데이터삭제에 따른 ANN 모델의 예측범위가 줄어드는 단점에 유의해야 될 것으로 판단된다.
6. 결 론
본 연구에서는 간단한 SDOF 모델을 적용한 데이터베이스 및 최대변위와 최대전단력 ANN예측모델에 대하여 논의하였다. ANN 모델 개발을 위해 다양한 지반조건 및 지진파 하에서 데이터를 생성하였으며 생성된 ANN모델의 정확도를 검증하였다. 본 연구에 대한 결과를 요약하면 아래와 같다.
(1) 본 연구에서 구축된 데이터베이스를 이용하여 개발된 최대변위와 최대전단력 ANN 예측모델은 R2=0.87~0.89의 상대적으로 높은 정확도를 보였다.
(2) 출력층에 두 개의 노드(최대변위와 최대전단력)를 가진 ANN 모델보다 한 개의 노드(최대변위 또는 최대전단력)을 가진 ANN 모델이 더 높은 정확도를 보였다. 그러나, 한 개의 노드를 갖는 ANN 모델은 두번의 학습 과정을 거쳐야하는 단점이 있다.
(3) ANN 모델의 정확도는 모델 개발에 이용된 데이터 백분위에 따라 다른 값을 나타내었고 본 연구에서 구축된 데이터베이스는 99% 백분위에서 가장 높은 ANN 모델 정확도가 나타났다.
(4) 본 연구에서 제시된 ANN 모델링 framework는 향후 더 복잡한 비선형 지진응답모델(3D 수치해석, 다자유도모델, 비선형 기초지반강성 등)에 대한 ANN 모델 개발에 이용될 수 있을 것이라 사료된다. 이와 관련 지진응답에 영향을 미치는 요소가 증가하게 되는데 해당 학습 모델의 정확도를 보다 향상시키기 위하여, 영향인자와 출력값 사이의 주성분 분석 기반의 데이터세트의 설계를 고려할 수 있다.
