

1. 서 론
2. CSMS 기초 및 정밀조사 데이터
3. 분석기법
3.1 차원축소
3.2 K-means 클러스터링 분석
3.3 분석절차
4. 데이터 전처리 및 성능평가 방법
4.1 CSMS 데이터 및 전처리 방법
4.2 클러스터링 성능평가 방법
5. 분석결과
5.1 차원축소에 따른 클러스터링 효과
5.2 주성분 및 선형판별식의 클러스터링 영향
5.3 기존 위험등급 레이블의 품질 평가
5.4 클러스터링 기반 위험등급 분류
5.5 위험등급에 대한 영향인자 분석
6. 결 론
1. 서 론
도로 비탈면의 안정성은 도로 안전 관리에서 매우 중요한 요소로, 비탈면의 붕괴는 도로 이용자에게 심각한 위험을 초래할 수 있다. 이에 따라 비탈면의 유지관리와 위험 평가가 도로 관리 시스템의 핵심 과제이다. 국내에서는 도로 비탈면의 체계적인 관리를 위해 깎기 비탈면 유지관리 시스템(Cut-Slope Management System, CSMS)이 운영되고 있다. CSMS 운영을 통해 전국 도로 비탈면 현황을 파악하고 위험등급을 산정 후 효율적인 비탈면 유지관리 대책을 도출하여 비탈면 붕괴를 사전에 예방한다. CSMS 데이터는 전국 국도변에 위치한 모든 비탈면에 대해 기초조사와 정밀조사를 통해 구축되었으며, 도로 비탈면의 위험 요소를 체계적으로 관리하기 위한 중요한 자료로 활용된다(KICT, 2021). CSMS 데이터는 크게 두 가지로 구분될 수 있다. 첫 번째는 기초조사(Basic survey) 자료이며, 두 번째는 이를 바탕으로 수행되는 정밀조사(Detailed survey)에서 수집되는 자료이다. 기초조사는 국도의 확장, 신설노선 및 우회도로 개통, 위험도로 선형개량, 승격국도 발생에 의해 새로운 비탈면이 준공되었을 때, 국토관리사무소(또는 지자체)로부터 행정구역, 구간, 연장 등 기초사항 정보를 받고, 비탈면 기초조사 매뉴얼에 따라 비탈면 기본정보를 직접 현장에서 취득하는 것을 말한다. Fig. 1은 CSMS의 업무절차를 나타낸다. 기초조사 자료는 위험한 깎기 비탈면을 파악할 수 있는 기본 정보를 내포하고 있으며, 정밀조사 우선순위를 결정하는 주요한 자료이다. 반면, 기초조사 이후에 수행되는 정밀 조사는 대상 위험 비탈면의 불연속면 특성, 풍화도, 암반강도, 누수 현황, 배수시설 상태 등을 정밀하고 상세하게 조사하는 것으로, 수집된 정밀조사 자료는 안정성 해석을 위한 기본 자료 및 대책공법 수립 등에 사용된다. 따라서 기초조사 자료는 향후 우선순위를 결정하는데 중요한 데이터이다. 이러한 조사는 전문가에 의해 수행되지만, 주관적인 판단 또는 인간오차(Human error)가 포함되어 있다(Lee et al., 2021; Woo et al., 2020a). CSMS 데이터에는 이러한 불확실성이 내포된 정보와 측정된 객관적 정보를 바탕으로 위험등급이 구분된다고 볼 수 있다. 현재 비탈면의 위험도 평가는 주로 전문가의 현장 경험과 주관적 판단에 의존하고 있으며, 이로 인해 평가의 일관성과 신뢰성에 대한 문제가 제기되고 있다. 전문가에 따라 동일한 비탈면의 위험등급이 다르게 평가될 수 있으며, 이러한 평가 방식은 객관적인 의사 결정 도구로 활용되는 데는 한계가 있다.
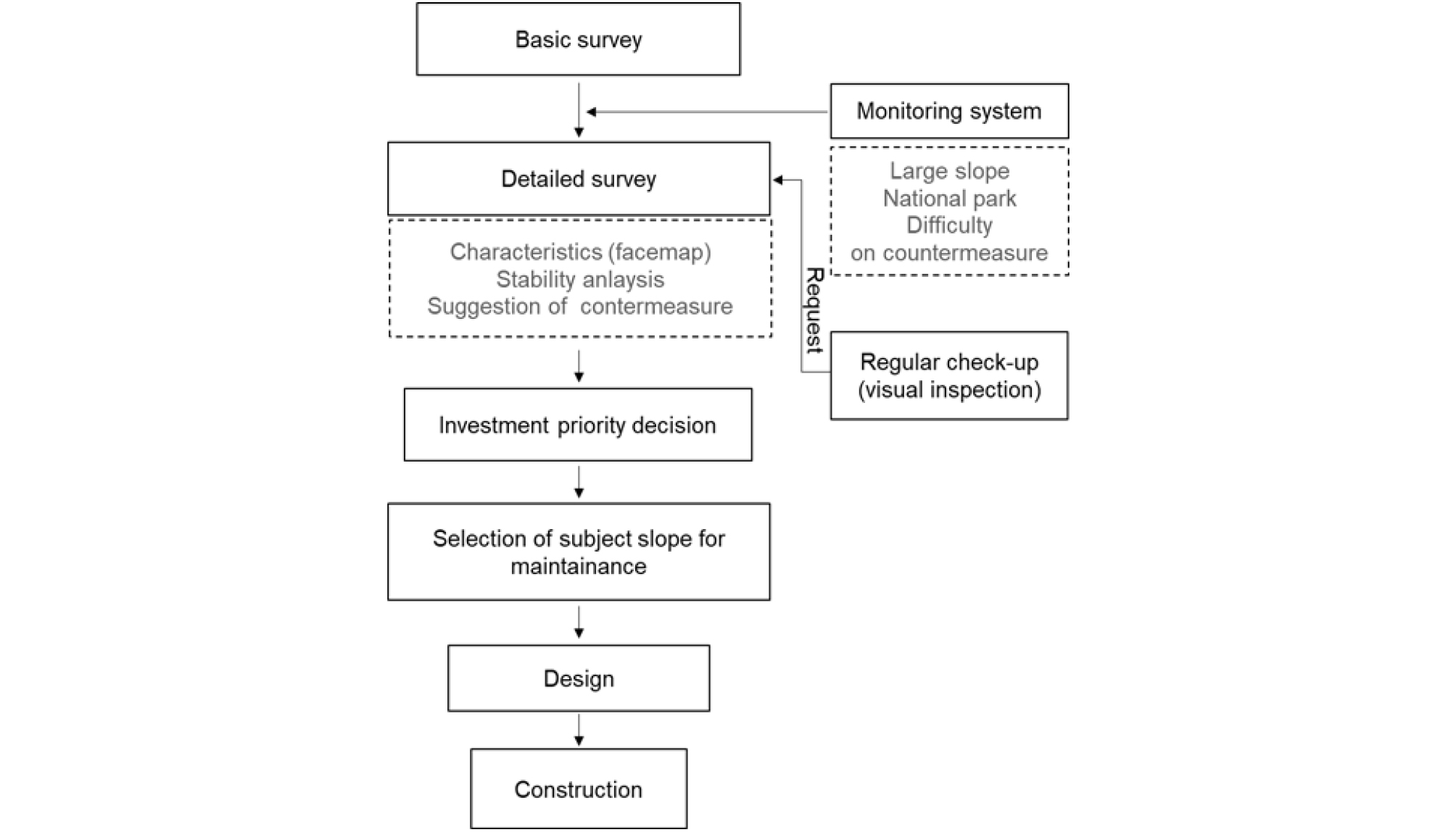
현재의 비탈면 위험등급 관리 방법은 비탈면의 붕괴 발생 요인 중 3가지 주요 인자(지하수 상태, 풍화도, 불연속면 방향성)를 고려하여 위험 기준을 설정하고, 이를 기반으로 5개 위험등급으로 분류하는 방식이다(KICT, 2021). 따라서 CSMS에서 관리하고 있는 모든 요소가 반영되지 않고 정성적 평가에 의존하는 경향이 크다. 이러한 문제는 비탈면 관리의 일관성을 저해할 수 있으며, 효율적인 자원 배분과 예방적 유지관리를 어렵게 만든다. 이와 같은 문제를 해결하기 위해, 도로 비탈면 유지관리에 사용 중인 데이터 기반의 객관적이고 정량적인 위험등급 평가 방법의 필요성이 강조되고 있다.
국내에서 도로 비탈면 유지관리 데이터를 직접적으로 활용한 연구가 수행된 바 있다. CSMS 데이터 중 주관적 판단에 의한 범주형 데이터를 로지스틱 회귀분석과 심층신경망을 통해 예측하였으며, 범주형 데이터의 클래스 개수에 따라 서로 다른 성능을 보여주었다(Lee et al., 2021; Woo et al., 2020a). 연구결과는 CSMS 데이터에서 누락 또는 오기입된 데이터에 대해 회귀모델을 이용하여 보완될 수 있는 가능성을 보여주었다. 도로 비탈면의 붕괴 위험도를 예측하기 위해 CSMS의 정밀조사 데이터를 기반으로 특정 지역 및 기간을 대상으로 기상정보와 머신러닝 방법을 이용하여 붕괴 위험도 값을 산출하고 붕괴 여부를 판단할 수 있음을 확인하였다(Woo et al., 2020b). 최근 국외에서는 도로 비탈면 유지관리 시스템의 개선을 위한 다양한 연구들이 활발히 진행되고 있다. 인도네시아의 Semarang-Salatiga 구간 유료도로에서는 비탈면 위험 관리 시스템을 구축하여 주기적인 모니터링과 유지보수 계획을 지원하고 있으며, 도로 비탈면 자산의 전자 데이터베이스 구축, 지질학적 위험과 경제적 영향을 기반으로 한 우선순위 평가, 정기 유지보수 일정 및 비용 관리 등을 포함하는 통합적 관리 시스템을 운영 중이다(Hermawan et al., 2023). 이 시스템은 BIM(Building Information Modeling)과 유사한 GeoBIM 개념을 도입하여 비탈면을 디지털화하고 효율적으로 관리하고 있다. 인도네시아 국도망에서는 통합 도로 관리 시스템(IRMS)을 활용하여 포장도로 유지관리를 최적화하는 연구가 진행되었다(Nindya et al., 2024). 또한 수명주기 비용 분석(LCCA)과 IRI(International Roughness Index) 지표를 사용하여 도로의 유지보수 우선순위, 처리 유형 및 비용을 최적화하는 방법을 제시하고 있다. 중국 푸젠성 난핑시에서는 수치 시뮬레이션과 이미지 인식을 통합한 도로 비탈면 모니터링 및 조기 경보 시스템을 연구하고 있다(Gu et al., 2023). 이 연구는 다양한 데이터를 활용하여 비탈면의 위험을 평가하고 예측하는 방법을 제시하고 있으며, 특히 이미지 인식 기술을 통해 비탈면의 상태를 실시간으로 모니터링하고 위험을 사전에 경고하는 시스템을 개발하고 있다. 이러한 시스템들은 비탈면 관리의 효율성을 크게 향상시키고 있다. 이와 같은 연구들은 비록 인공지능을 직접적으로 적용하고 있지는 않지만, 데이터 분석, 예측 모델링, 이미지 처리, 의사결정 지원과 같은 인공지능 기술을 적용하기에 적합한 구조를 가지고 있다. 이와 같이 최근 국외 사례들은 도로 비탈면의 유지관리에 있어서 데이터 중심의 접근이 점점 중요해지고 있음을 시사한다. 이러한 시스템들은 대량의 데이터를 효율적으로 분석하여 위험 패턴을 인식하고, 예측 모델링을 통해 미래의 상태를 예측하며, 복잡한 요인을 고려한 최적의 유지보수 전략을 제안하는 데 도움을 줄 수 있다(Gu et al., 2023).
CSMS와 같은 기존 도로 비탈면 유지관리 시스템은 전국의 수많은 도로 비탈면을 관리하기 위한 방대한 데이터를 운영하고 있지만, 모든 비탈면을 일일이 관리하는 데에는 한계가 있다. 따라서, 비탈면의 위험등급을 분류하여 관리하는 것이 더 효율적이며, 이를 위해서는 보다 객관적이고 정량적인 평가 방법이 필요하다. 기존의 평가 방식은 일부 변수에만 의존하여 정성적으로 위험등급을 산정하는 반면, 본 연구에서는 효율적인 도로 비탈면 유지관리를 위해 CSMS 데이터의 다양한 변수들을 모두 활용하여 클러스터링 기법을 적용하여 위험등급을 부여하고 평가할 수 있는 방법을 제안하였다. 이를 위해 주성분 분석(Principal Component Analysis, PCA)과 선형판별분석(Linear Discriminant Analysis, LDA)을 이용하여 비탈면 유지관리 데이터를 차원 축소한 후, K-means 클러스터링을 통해 위험 등급을 분류하고 그 성능을 비교 분석하였다.
2. CSMS 기초 및 정밀조사 데이터
CSMS 데이터는 전국 국도변에 위치한 모든 비탈면에 대한 기초조사와 정밀조사를 통해 구축되어 있다. 기초조사는 전국 국도변에 위치한 비탈면의 기초적인 속성 항목을 전수 조사하는 과정으로, 비탈면의 관리 및 위치 정보, 일반 현황, 비탈면 특성, 조사자 소견, 사진 등의 자료를 수집하여 데이터베이스화하는 것을 목표로 구축된 자료이다(KICT, 2021). 이 과정에서 각 비탈면에는 고유코드가 부여되며, 이는 향후 비탈면 관리 및 조사 우선순위를 결정하는 주요 자료로 활용된다. 현재는 국도 내 모든 노선에 대한 기초조사가 완료된 상태로, 매년 국도 확장 및 개량 공사로 인해 새롭게 조성된 비탈면에 대해 조사가 진행되고 있다. 정밀조사는 기초조사 자료를 기반으로 선정된 위험등급 사면에 대해 비탈면 전문가가 수행하는 상세 조사이다. 정밀조사는 해빙기 정밀조사, 수시 정밀조사, 일반 정밀조사, 기타(위험그룹) 정밀조사로 구분되며, 각 구간의 특성에 따라 현황도가 작성되고 최적의 대책공법이 선정된다. 본 연구에 사용된 CSMS 데이터는 2006년부터 2019년까지 수집된 30,751개의 비탈면에 대한 조사 자료로, 비탈면의 기본 정보 및 특성(객관적 정보)과 위험등급 및 대책공법(전문가 판단 정보)으로 구성되어 있다. Fig. 2는 CSMS을 통해 수집한 데이터 형태의 일부를 보여준다.
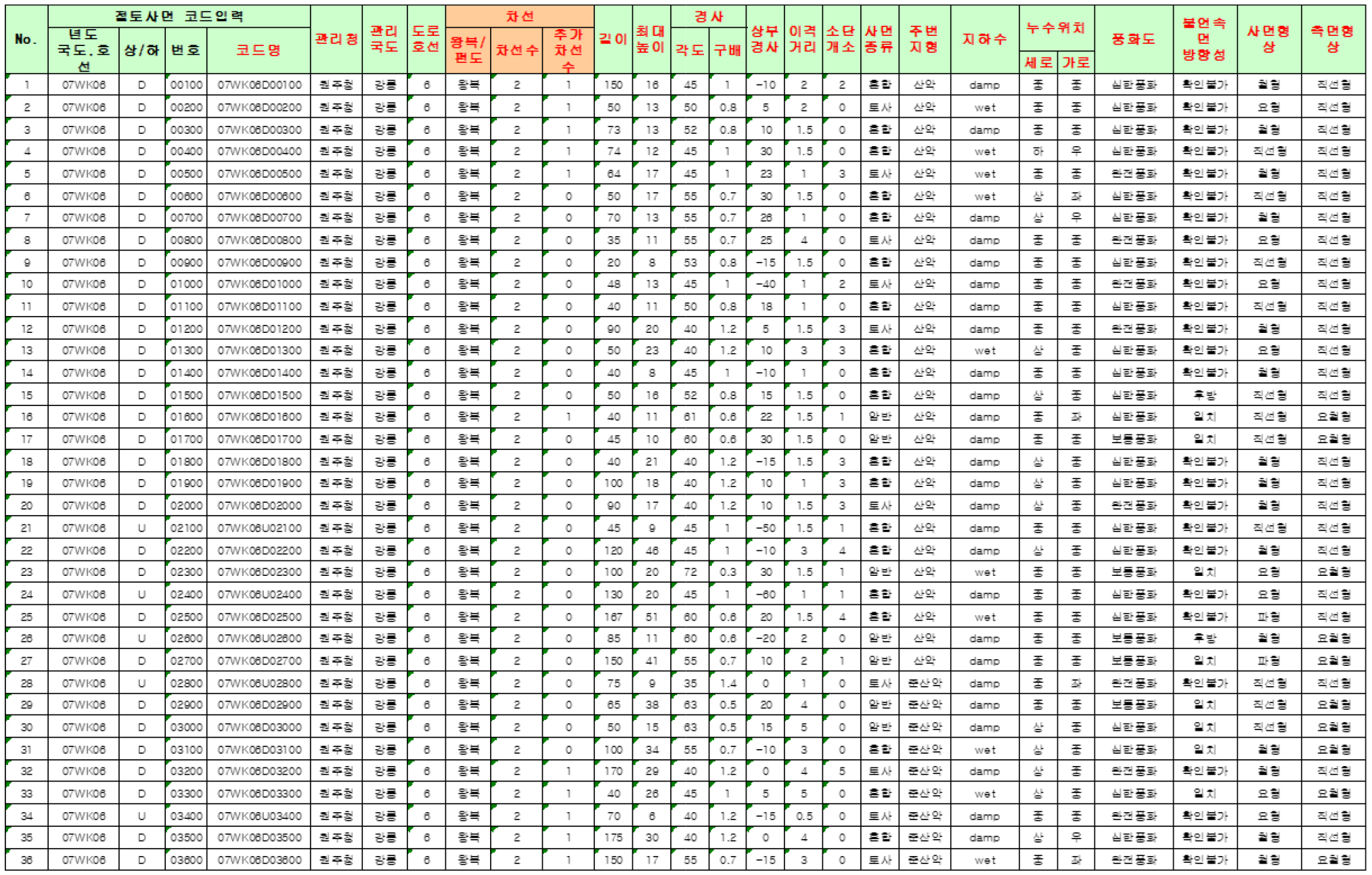
CSMS의 비탈면의 위험등급 관리 방법은 비탈면의 붕괴 발생 요인을 고려한 위험 기준을 설정하고, 이를 기반으로 위험등급을 분류하는 방식으로 이루어진다. 현행 위험등급은 Ⅰ, Ⅱ, Ⅲ, Ⅳ, Ⅴ의 5개 그룹으로 분류되며, Ⅴ그룹 비탈면이 가장 위험한 비탈면으로 분류된다. 위험등급은 과거 비탈면 붕괴요인 분석결과를 바탕으로 불연속면의 방향, 풍화도, 지하수 상태의 3가지 요인으로 판단된다. 불연속면 방향성의 경우 비탈면 방향과의 일치 여부, 지하수 상태는 젖음 이상, 풍화도는 심한풍화 이상을 고려하여 Ⅲ~Ⅴ등급으로 분류한다. 그리고 어느 인자도 해당하지 않는 비탈면은 Ⅱ등급 이하의 안전한 등급으로 분류하고, 비탈면의 높이, 경사, 연장, 교통량 등을 고려하여 Ⅰ과 Ⅱ등급으로 구분하고 있다. 이와 같이 기존의 위험등급 평가는 주로 지하수 상태, 풍화도, 불연속면 방향성과 같은 특정 인자에 의존하고 있으며, 이러한 인자들의 중복 여부에 따라 위험등급이 결정된다. 하지만, 이러한 접근 방식에는 다음과 같은 한계가 존재한다. 첫째, 위험등급 평가는 전문가의 주관적 판단에 크게 의존하며, 동일한 비탈면에 대해 전문가 간 평가 결과가 다를 수 있다. 이는 위험등급 평가의 신뢰성을 저하시킬 수 있는 요소이다. 둘째, 지하수 상태, 풍화도, 불연속면 방향성 등 특정 요인에 집중함으로써, 다른 중요한 요인들(예: 주변 지형, 암종, 낙석 등)에 대한 고려가 부족할 수 있다. 셋째, 기존의 평가 방식은 정량적 데이터보다는 질적 평가에 중점을 두고 있어, 위험등급 간의 명확한 경계를 설정하기 어렵다.
3. 분석기법
비탈면 유지관리 데이터의 고차원성을 해결하기 위해 차원축소 방법을 이용하여 CSMS 데이터의 차원을 축소한 후 K-means 클러스터링을 수행하였다. 본 연구에서는 차원축소 방법으로 주성분 분석(PCA)과 선형판별분석(LDA)을 이용하였다. PCA는 데이터의 분산을 최대화하는 방식으로 축을 설정하여 차원을 축소하고, LDA는 기존 전문가의 주관적 위험 등급 레이블을 사용하여 차원을 축소하였다. 이를 통해 각각의 차원 축소 방법이 클러스터링 성능에 미치는 영향을 비교할 수 있으며, 기존 위험 등급 레이블의 적정성을 간접적으로 평가하였다.
3.1 차원축소
도로 비탈면 관리 시스템에서 다루는 데이터는 비탈면에 대한 물리적, 지형적, 환경적 데이터뿐만 아니라 전문가 판단에 의한 주관적 데이터 등 다양한 요소를 포함하는 높은 차원의 데이터 이다. 이러한 고차원 데이터는 해석이 어렵고, 시각화 및 계산 복잡성을 증가시킨다. 차원 축소는 데이터의 중요한 정보를 최대한 보존하면서 차원을 줄여주는 방법으로, 고차원 데이터를 단순하게 만들고 효율적으로 분석할 수 있게 한다. 고차원 데이터에서 클러스터링 분석은 계산 비용이 높으므로 데이터의 차원을 줄여 처리 시간을 단축하고 계산의 효율성을 향상시킬 수 있다(Erişoğlu et al., 2013). 적절한 차원축소 방법을 사용하면 데이터의 클러스터 구조를 보존하면서 차원을 줄일 수 있다. 또한 차원 축소 과정에서 데이터의 노이즈가 제거되어 클러스터링 분석의 정확도를 향상시킬 수 있다(Ayesha et al., 2020). 고차원 데이터의 클러스터링 분석에서 차원축소를 함께 사용하는 경우는 다양한 분야에서 활발히 적용되고 있다(Ivosev et al., 2008; Jung et al., 2010a; Jung et al., 2010b; Vitalis et al., 2023). 본 연구에서는 두 가지 대표적인 차원 축소 기법인 주성분 분석(PCA)과 선형판별분석(LDA)을 사용하여 CSMS 데이터의 차원을 축소한 후 K-means 클러스터링에 적용하였다. Fig. 3은 PCA와 LDA의 차이를 시각화 한 것이다. PCA는 고차원 데이터를 몇 개의 주요 성분으로 변환하여 데이터의 차원을 축소하는 기법이다. 데이터의 분산을 최대화하는 방향으로 새로운 축(주성분)을 정의하여, 데이터의 중요한 정보를 보존하면서 차원을 축소한다. 각 주성분은 원 데이터의 선형 결합으로 표현되며, 첫 번째 주성분은 데이터의 최대 분산을 설명하고, 두 번째 주성분은 첫 번째 주성분과 직교하며 그 다음으로 큰 분산을 설명하는 방식으로 차례로 결정된다. PCA는 비지도 학습(Unsupervised Learning) 방법으로 데이터에 존재하는 레이블 정보 없이 데이터의 구조를 반영하여 차원을 축소한다. 데이터의 분산을 최대화하는 방향으로 축을 설정하므로, 데이터의 전체적인 변동성을 가장 잘 설명할 수 있다. 데이터의 상관관계를 기반으로 주요 패턴을 추출하며, 노이즈나 중복된 정보를 제거하는 데 효과적이다(Varmuza and Filzmoser, 2016). PCA는 데이터의 고유한 구조를 반영하는 데 유리하지만, 데이터의 클래스 구분 정보는 고려하지 않기 때문에 클래스 간 변별력을 최대화하는 데는 한계가 있다.
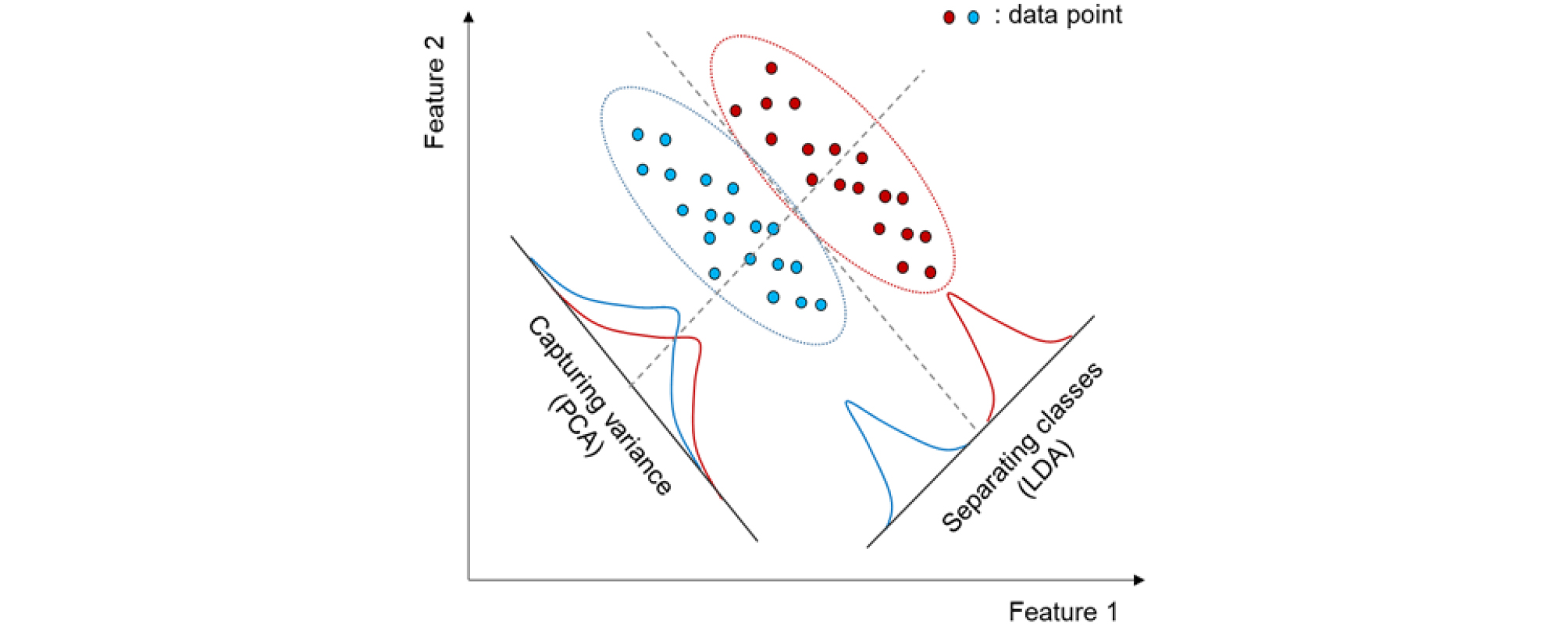
LDA는 데이터의 레이블(위험 등급)를 활용하여 차원을 축소하는 지도 학습(Supervised Learning) 방법이다. LDA의 목표는 클래스 간 분산(Between-class variance)을 최대화하고, 동시에 클래스 내 분산(Within-class variance)을 최소화하는 축을 찾아 데이터를 변환하는 것이다. 이를 통해 서로 다른 클래스에 속하는 데이터 포인트들이 최대한 떨어져 위치하게 하여, 클래스 간의 변별력을 높인다. LDA는 데이터의 레이블 정보를 고려하기 때문에 위험 등급 간 변별력을 유지하면서 차원을 효과적으로 축소할 수 있다(Alam and Kwon, 2017). 따라서 LDA는 레이블 구분을 극대화하는 데 효과적이지만, 데이터의 분포가 비선형적일 경우 한계가 있을 수 있다.
3.2 K-means 클러스터링 분석
차원 축소된 데이터의 패턴을 분석하기 위해 군집분석 방법을 사용하였으며, 본 연구에서는 비지도 학습(Unsupervised learning)의 대표적인 군집분석 방법으로 K-means 클러스터링 방법을 적용하였다. 이 방법은 대량의 데이터에서 군집을 발견하기 용이하고 연산 속도가 빠른 장점이 있다(Ikotun et al., 2023). K-means 클러스터링 방법은 주어진 데이터를 K 개의 군집으로 묶는 알고리즘으로, 반복적으로 객체를 군집에 재할당하기 때문에 초기에 부적절한 군집에 할당되어도 반복 계산을 통해 최종적으로 적절한 군집에 포함될 수 있다. K-means 군집 방법에서 K 값은 클러스터의 개수를 의미하며, 이 알고리즘은 각 클러스터의 중심(centroid)과 클러스터 내의 데이터 객체와의 거리 제곱합(sum of square)을 비용 함수로 정하고, 이 함수값을 최소화하는 방향으로 각 데이터의 소속 군집을 업데이트함으로써 클러스터링을 수행하게 된다. 식 (1)은 K-means 알고리즘의 목적함수를 나타낸다.
이 식은 n개의 데이터 가 주어졌을 때, n개의 데이터를 각 집합 내 데이터 간 응집도를 최대로 하는 개의 집합 로 분할하는 것을 나타낸다. 즉, 가 집합 의 중심점이라 할 때 각 집합별 중심점~집합 내 데이터간 거리의 제곱합을 최소로 하는 집합 S를 찾는 것이다. 이 방법을 통해 각 군집에는 서로 유사한 개체들이 속하게 되며, 군집들을 가장 잘 나타낼 수 있는 중심점을 식별함으로써 유사한 그룹으로 분류할 수 있게 된다(Ganesh et al., 2023). K-means 방법은 반복 계산을 통해 군집의 중심점이 보정되면서 개별 데이터들이 군집을 형성하게 된다. 중심점이 더 이상 변화하지 않을 때 수렴하게 된다. K-means 클러스터링은 초기 중심점의 설정에 따라 최종 클러스터링 결과가 달라질 수 있으므로, 반복 수행을 통해 군집 형성을 비교하여 군집 분석을 수행할 필요가 있다. 또한, 몇 개의 군집으로 데이터를 분류할지 사용자가 K값을 지정해 주어야 하는 특징이 있으며, 적절한 K값을 결정하기 위해서는 통계적 접근 또는 해당 도메인의 전문지식을 통해 결정할 수 있다.
3.3 분석절차
본 연구의 전체 분석 절차는 Fig. 4와 같다. 먼저 CSMS를 통해 도로비탈면의 기초 및 정밀조사 데이터를 수집하고, 데이터 전처리를 통해 결측치 처리, 정규화, 클래스 정의 등 원시 데이터를 가공하였다. 분석에 사용되는 전처리된 CSMS 데이터는 고차원 데이터로 PCA와 LDA를 통해 차원을 축소하였다. 전절의 설명과 같이 PCA는 비지도 학습 방법으로 레이블 구분 없이 데이터의 전반적인 분산을 최대화하는 데 중점을 두며 차원을 축소하고, LDA는 지도 학습 방법으로 레이블 간의 차이를 극대화하면서 데이터가 잘 분리될 수 있는 공간으로 차원을 축소한다. PCA와 LDA를 통해 2~4개의 차원으로 축소하여 K-means 클러스터링을 통해 클러스터 형성 패턴을 비교하고, 클러스터의 유효성 지표를 비교한다. 이 과정에서 각 차원축소 방법의 주성분 개수에 따른 클러스터링 성능을 비교하고, 적절한 주성분 개수를 선정한다. 이때 CSMS의 현행 위험등급 분류체계에 따라 K를 5로 설정하였다. 이 절차를 통해 현재 CSMS 위험등급 레이블의 품질을 간접적으로 평가할 수 있다. LDA는 주어진 레이블 정보를 사용하므로, LDA를 적용한 클러스터링 성능이 레이블 정보 없이 학습한 PCA를 적용한 경우보다 낮게 나타난다면 레이블로 정의된 위험등급 클래스의 신뢰도가 낮다고 판단할 수 있다. 이후 비지도 학습 방법인 PCA를 통해 K-means 클러스터링 분석을 수행하고, 현재 마킹된 CSMS 데이터의 위험등급을 재평가하였다. 또한 K-means 알고리즘을 통해 분류된 클러스터에 속한 도로 비탈면의 주요 인자를 분석하여 위험등급 점수를 산정하고, 각 위험등급에 영향을 주는 주요 인자에 대해 분석하였다.
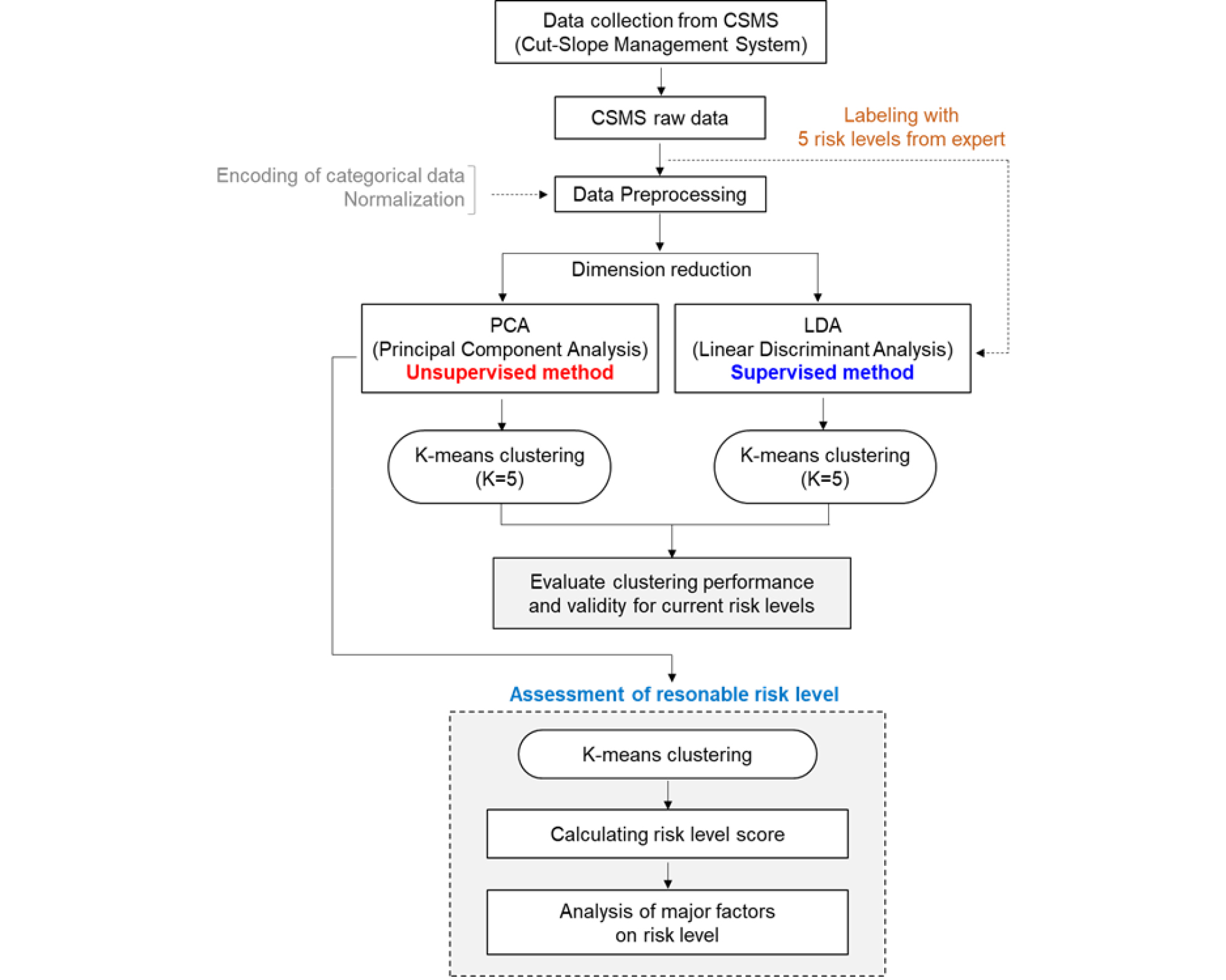
4. 데이터 전처리 및 성능평가 방법
4.1 CSMS 데이터 및 전처리 방법
CSMS 데이터는 전체 30,751개의 비탈면에 대해 다양한 정보를 변수로 하여 구성되어 있고, 크게 비탈면의 지형 정보, 공학적 특성 정보, 전문가 판단 정보로 나눌 수 있다. 이 정보들 중 범주형 데이터는 2개에서 8개의 클래스(class)로 각기 다르게 구성되어 있다. CSMS에서 원시데이터를 추출한 후 비탈면의 지형 정보 또는 공학적 특성 정보가 누락된 비탈면은 분석에서 제외하였다. 분석에 사용된 전체 비탈면은 29,787개이며, 이는 현행 CSMS를 통해 관리중인 비탈면 중 약 97%에 해당한다. CSMS 기초데이터는 28개의 속성 정보를 통해 관리되고 있다. 지형정보는 12가지로 길이, 최대높이, 경사(각도), 상부경사, 이격거리, 소단개소, 사면종류, 주변지형, 사면형상, 측면형상, 계곡부, 교통량이 해당된다. 공학적 특성 정보는 10가지로 지하수, 풍화도, 불연속면방향성, 붕괴이력, 뜬돌, 낙성, 암종, 토층심도, 암반형태, 불연속면이 해당된다. 이외 전문가에 의한 판단 정보는 6가지로 계측추천, 2종시설물, 위험도, 피해도, 붕괴유형, 위험등급이 있다. 전문가 판단 정보는 주관적 정보로 동일한 비탈면에 대해 전문가 간 평가가 다를 수 있고 위험등급 평가의 신뢰성 확보를 위해 본 논문에서는 제외하였다. 따라서 본 논문에서는 지형정보와 공학적 특성 정보 22개 변수를 분석에 사용하였고, 22개 변수에 대해 각기 다른 클래스를 고려하면 분석 데이터는 65차원의 데이터가 된다. 다양한 클래스를 가지는 범주형 데이터는 원핫인코딩(One-Hot encoding)을 통해 수치화하였다. 범주형 데이터는 일반적으로 수치 연산이 불가능하여 직접적인 크기 비교를 위해 수치형 데이터로 변환하는 과정이 필요하다. 원핫인코딩은 범주형 데이터를 이진 벡터(binary vector) 형태로 변환하는 방법으로, 각 범주형 값에 대해 고유한 비트를 부여하고 해당 범주에만 1, 나머지 값에는 0을 할당하는 방식이다. 예로 사면종류의 경우 암반, 혼합, 토사, 자연의 4개 클래스로 구성되어 있으며, 이진 벡터로 표현하면 각 클래스는 [1,0,0,0], [0,1,0,0], [0,0,1,0], [0,0,0,1]로 변환된다. 이와 같이 변환된 이진 벡터는 각 범주가 서로 다른 차원에서 독립적으로 표현되므로, 범주형 데이터가 수치적으로 잘못 해석될 가능성을 방지하고, 각 범주의 관계를 명확하게 구분할 수 있다. 클래스를 단순 숫자로 인코딩하게 되면, 수치형이 혼합되어 있는 CSMS데이터의 경우 데이터간 불필요한 서열관계가 생겨 실제와 다른 의미가 부여될 수 있다. 또한 본 논문에서 사용하는 K-means 클러스터링 방법은 수치형 데이터에 효율적으로 작동하므로 원핫인코딩을 통해 수치형으로 변환하여 모델이 직접 처리할 수 있도록 전처리한다. 수치형 데이터로 변환된 변수들은 각 변수들의 최소값과 최대값을 이용하여 정규화하고, 평균이 0이고 표준편차가 1인 데이터 분포로 표준화하였다. 이와 같이 정규화와 표준화 과정을 거쳐 차원 축소와 클러스터링 분석에 적합한 형태로 데이터를 전처리하였다.
4.2 클러스터링 성능평가 방법
클러스터링의 성능을 평가하기 위해서는 클러스터 내의 응집도와 클러스터 간의 분리도를 고려하는 다양한 평가 지표를 사용하여, 클러스터링 결과의 품질을 정량적으로 판단할 수 있어야 한다. 본 연구에서는 CSMS 데이터를 K-means 클러스터링을 통해 분류한 후, 각 클러스터링의 결과의 유효성을 평가하기 위해 Silhouette Coefficient, Dunn Index, Davies-Bouldin Index, Calinski-Harabasz Score의 4가지 지표를 사용하였다. 각 지표는 클러스터 내 응집도와 클러스터 간 분리도를 다른 방식으로 평가하기 때문에 다양한 관점에서 클러스터링의 품질을 비교할 수 있다. 이러한 다각적인 평가를 통해 클러스터링의 유효성을 확인하고, 데이터 기반의 위험 등급 평가 방법의 타당성을 검증하고자 하였다.
Silhouette Coefficient(SC)는 클러스터링의 품질을 측정하는 지표로, 개별 데이터 포인트가 얼마나 잘 클러스터에 속하는지에 대해 평가할 수 있는 지표이다(Ogbuabor and Ugwoke, 2018). 이 지표는 각 데이터 포인트의 응집도와 분리도를 동시에 고려하여 계산된다. 클러스터링 후 각 데이터 포인트 i에 대한 SC 는 식 (2)로 정의된다.
여기서, 는 데이터 포인트 i와 동일 클러스터 내 다른 모든 데이터 포인트 간의 평균 거리를 나타내고, 은 데이터 포인트 i와 가장 가까운 다른 클러스터의 데이터 포인트 간 평균 거리(최소 거리의 다른 클러스터)를 나타낸다. SC는 데이터 포인트의 응집도와 분리도를 동시에 평가하여 클러스터링의 품질을 직관적으로 이해할 수 있게 해주며, -1부터 1 사이의 값을 가지며, 값이 클수록 클러스터 내의 응집도가 높고, 클러스터 간의 분리도가 높음을 의미한다. 또한, 특정 클러스터가 과적합(overfitting)되거나 데이터가 잘못 할당된 경우를 탐지하는 데 유용하다.
Dunn Index(DI)는 클러스터링의 성능을 평가하기 위해 클러스터 간의 최소 거리와 클러스터 내 최대 거리의 비율을 사용하는 지표이며, 식 (3)으로 계산된다.
여기서, 는 클러스터 와 간의 최단 거리를 나타내고, 는 클러스터 내의 최대 거리, 즉 클러스터 내 두 데이터 포인트 간의 최대 거리를 나타낸다. DI 값이 클수록 클러스터 간의 분리가 잘 되고, 클러스터 내 응집도가 높음을 의미한다. DI는 클러스터 간의 분리도와 클러스터 내 응집도를 모두 고려하기 때문에, 클러스터링이 얼마나 잘 분리되어 있는지를 평가하는 데 유용하다(Dunn, 1974). 특히, 다른 지표들보다 클러스터 간의 분리도에 더 큰 비중을 두기 때문에, 분리도를 강조하고자 할 때 유용하다.
Davies-Bouldin Index(DBI)는 각 클러스터의 분산과 클러스터 간의 평균 거리 비율을 사용하여 클러스터링의 품질을 평가하는 지표이다(Davies and Bouldin, 1979). DBI는 클러스터 내의 데이터 포인트들이 얼마나 밀집되어 있으며, 클러스터 간의 분리가 얼마나 잘 이루어졌는지를 평가한다. DBI는 식 (4)를 통해 계산되며, 는 클러스터 의 분산, 는 클러스터 와 간의 중심점 거리, k는 클러스터 수를 나타낸다.
DBI 값이 작을수록 클러스터링이 잘 되었음을 의미한다. 이는 클러스터 내 분산이 작고, 클러스터 간의 거리가 크다는 것을 의미한다. 클러스터 내 분산을 상대적으로 강조하여, 데이터의 밀집도와 클러스터 간의 관계를 평가하는 데 유리하다.
마지막으로 Calinski-Harabasz Score(CH)는 클러스터 내 분산과 클러스터 간 분산의 비율을 사용하여 클러스터링의 유효성을 평가하는 지표이다(Maulik and Bandyopadhyay, 2002). 이 지표는 클러스터의 수에 대한 클러스터 내와 클러스터 간 분산의 비율을 고려하여, 클러스터링의 품질을 평가한다. CH는 식 (5)로 계산되며, n은 전체 데이터 포인트수, K는 클러스터 수, 는 클러스터의 중심벡터, 는 클러스터에 속하는 데이터 개수, 는 전체 데이터의 중심벡터, 는 k번째 클러스터에 속한 데이터를 의미한다.
CH의 분자는 클러스터 중심 간 분산(Between-cluster variance), 분모는 클러스터 내 데이터 포인트 간 분산(Within-cluster variance)을 의미한다. Calinski-Harabasz Score 값이 클수록 클러스터 간 분리가 잘 되고, 클러스터 내 분산이 작다는 것을 의미하며, 클러스터링이 잘 이루어졌음을 나타낸다.
5. 분석결과
5.1 차원축소에 따른 클러스터링 효과
Fig. 5는 PCA를 통해 차원축소 적용 여부에 따른 K-means 클러스터링 결과를 나타낸다. 차원을 축소하지 않은 원시 데이터를 이용하여 5개의 클러스터로 분류한 결과는 Fig. 5(a)와 같다. 원본 데이터의 클러스터링 결과는 각 데이터 포인트가 고차원에서 무작위로 분포되어 있고, 대부분의 데이터가 서로 겹쳐져 있는 것을 알 수 있다. 이는 고차원 데이터에서 클러스터 간의 분리가 명확하지 않으며, 클러스터링의 품질이 낮음을 시각적으로 보여준다. 또한 클러스터 중심점(Centroid)들이 데이터 포인트의 분포 중심에 몰려 있으며, 특히 0에 가까운 위치에 집중되어 있다. 이는 대부분의 데이터가 동일한 클러스터로 분류되었거나, 클러스터 간의 분리도가 낮음을 의미한다. Fig. 5(b)는 PCA를 통해 차원축소 후 클러스터링을 수행한 결과이다. 차원이 축소된 데이터는 원본 데이터보다 명확하게 구분된 클러스터 구조를 보여준다. 데이터 포인트가 각 클러스터 내에서 밀집되어 있어 클러스터링의 품질이 높아졌음을 알 수 있다. 또한, 클러스터 중심점들이 각 클러스터의 중심에 고르게 분포되어 있으며, 각 중심점 사이의 거리가 충분히 멀어져 있어 클러스터 간 분리가 명확해졌다. 이를 통해 클러스터링이 효과적으로 수행되었음을 알 수 있다.

CSMS 데이터의 클러스터링에서 차원축소 효과를 실루엣 계수(SC)로 평가한 결과는 Fig. 6에 나타나 있다. Fig. 6(a)는 원시 데이터를 그대로 사용하여 K-means 클러스터링을 수행한 후 SC의 분포를 시각화한 결과이다. 대부분의 클러스터가 0 이하의 SC 값을 가지며, 전체적으로 0에 가까운 값을 중심으로 분포하고 있다. 이는 클러스터 내 데이터의 응집도가 낮고, 다른 클러스터와의 분리가 명확하지 않음을 나타낸다. 특히 클러스터 0과 클러스터 2는 SC 값이 음수 영역에 위치하여, 클러스터링 결과가 불안정하고, 데이터 포인트들이 잘못된 클러스터에 할당될 가능성이 높음을 시사한다. 클러스터 1의 크기가 다른 클러스터에 비해 상대적으로 작으며, 이는 클러스터 내 데이터가 충분히 모여 있지 않음을 의미한다. Fig. 6(b)는 차원 축소를 적용한 경우이며, 대부분의 클러스터가 0.4 이상의 SC 값을 가지며, 클러스터 0, 1, 2, 3, 4 모두 긍정적인 SC 값을 나타낸다. 이는 클러스터 내 데이터가 더 밀집되어 있고, 다른 클러스터와 명확히 분리되었음을 의미한다. 모든 클러스터의 SC 값이 양의 영역에 위치하여, 데이터 포인트들이 올바른 클러스터에 속해 있으며, 클러스터 간의 경계가 명확하게 구분되었음을 보여준다. PCA 적용 후 클러스터링 결과는 SC 계수의 평균값이 크게 증가하였으며, 이는 차원 축소를 통해 데이터의 노이즈를 줄이고, 주요한 구조적 정보를 보존하면서 클러스터링의 품질이 크게 향상되었음을 나타낸다.

5.2 주성분 및 선형판별식의 클러스터링 영향
PCA(주성분 분석)와 LDA(선형판별분석)을 통해 도로 비탈면 유지관리 데이터의 차원을 축소한 후, 주성분 개수에 따른 클러스터링 성능을 평가하였다. 각 차원 축소 방법에서 주성분의 개수를 2개에서 4개까지 변화시키며 K-means 클러스터링을 수행하였고, Silhouette Coefficient (SC), Dunn Index, Davies-Bouldin Index, Calinski-Harabasz Score와 같은 다양한 성능 지표를 사용하여 클러스터링 품질을 비교하였다. Fig. 7은 PCA와 LDA를 통해 차원축소 후 클러스터링한 결과를 주성분(Principal Component, PC) 또는 선형판별식(Linear Discriminant, LD)의 개수에 따라 시각화한 것을 나타낸다. 두 방법 모두 데이터를 분류하는 축의 개수가 2개일 때 클러스터링이 가장 명확하고, 개수가 증가할수록 클러스터 간 분리가 모호해지는 것을 알 수 있다. 특히 LDA는 LD가 4인 경우 지도학습임에도 클러스터링 결과가 낮게 나타나 데이터의 노이즈가 많거나 레이블의 신뢰도가 낮은 것으로 유추할 수 있다.
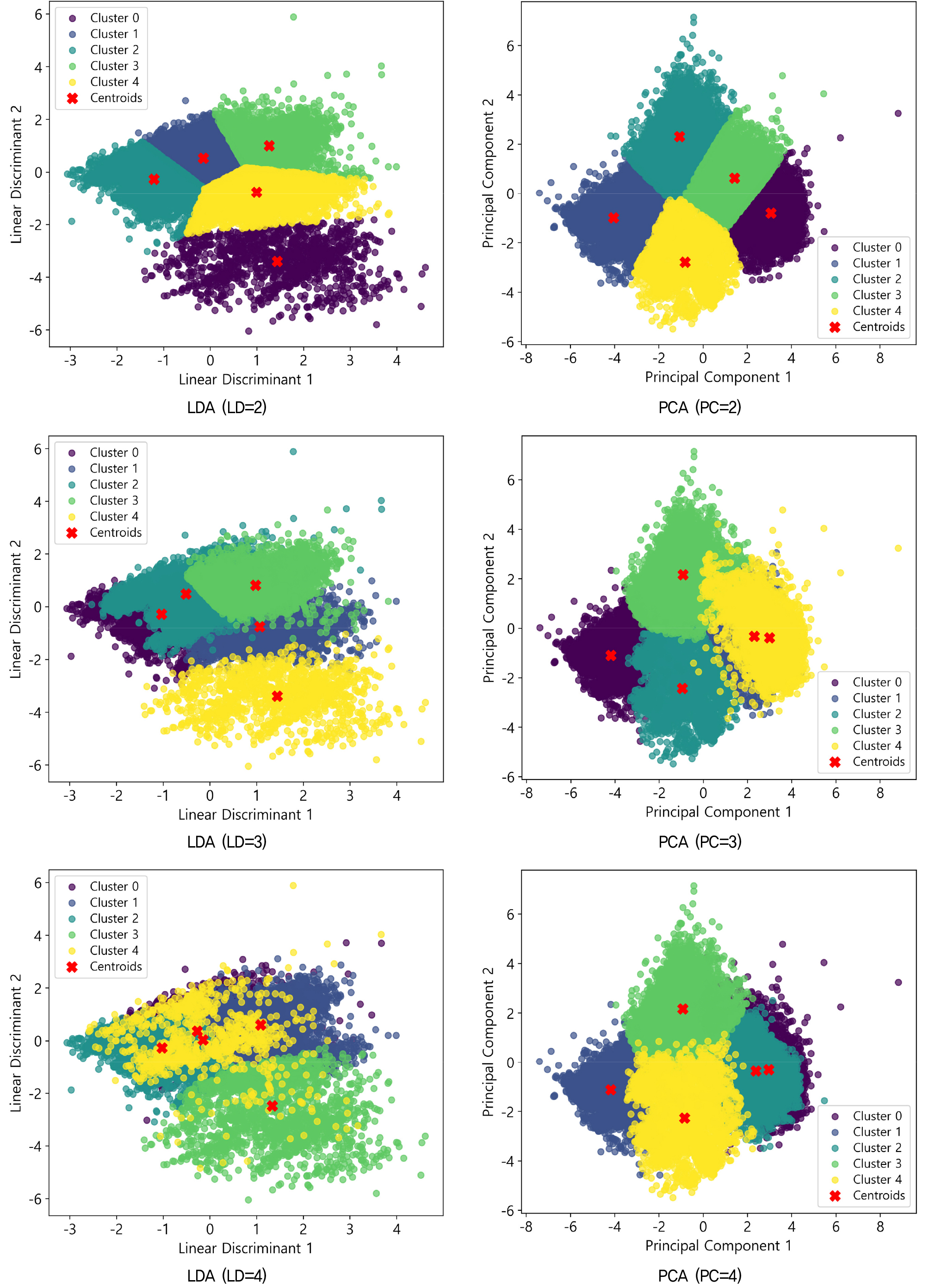
Table 1는 각 차원 축소방법에서 주성분과 선형판별식의 개수에 따른 4개 성능지표에 대한 결과를 보여주며, Fig. 7의 클러스터링 결과를 정량적으로 설명할 수 있다. SC 값의 경우 PCA 적용 시 주성분 2개일 때 가장 높은 SC값을 보였으며(0.470808), LDA는 이보다 낮은 점수(0.382195)를 보였다. 이는 PCA가 LDA보다 클러스터 내 응집도를 더 잘 반영한 결과를 나타낸다. 두 방법 모두 주성분 4개일 때 DI가 가장 높아졌지만, 전체적으로 PCA가 더 낮은 값을 기록하므로 PCA의 클러스터 내 응집도가 더 큰 것을 의미한다. DBI의 경우 두 방법 모두 주성분 수에 따라 증가하였으며, 이는 클러스터 내 분산이 증가했음을 시사한다. 그러나 PCA가 LDA보다 DBI가 더 낮아, 클러스터 내 응집도가 더 우수함을 보여준다. PCA를 적용한 경우 LDA에 비해 모든 경우 높은 점수를 기록하였으며, 이는 PCA가 클러스터 내 분산이 낮고 클러스터 간 분산이 높아, 클러스터링 성능이 더 우수하다는 것을 의미한다. 결론적으로, PCA와 LDA 모두 PC 및 LD 수가 증가함에 따라 클러스터링 성능이 전반적으로 감소하였으며, 주성분 수를 2개로 설정했을 때 가장 높은 성능을 보였다. 특히, PCA는 LDA에 비해 클러스터링의 응집도와 분리도 측면에서 우수한 성능을 보였으며, 이는 CSMS 데이터의 경우 데이터의 분산을 최대화하는 방식이 클러스터링 성능에 더 적합한 것을 나타낸다.
Table 1.
Clustering performance metrics
5.3 기존 위험등급 레이블의 품질 평가
현재 CSMS 데이터에 맵핑된 위험등급을 레이블로 하여 LDA를 통해 차원을 축소하고 K-means 클러스터링을 수행한 결과는 Fig. 8과 같다. 클러스터링한 5개 등급과 실제 위험등급을 혼동 행렬(Confusion matrix)로 나타낸 것이 Fig. 9이며, 혼동 행렬을 통해 각 위험등급이 어느 클러스터에 할당되었는지 확인 할 수 있다. 클러스터링 결과는 기존 레이블과 비교하여 비탈면 수가 많은 클러스터에 해당 위험등급을 부여하였다. 실제 위험등급이 1인 데이터는 총 4326개이며, 이 중 1,004개가 정확히 클러스터 1로 분류되었지만, 나머지 3,322개(약 76.79%)는 다른 클러스터에 잘못 할당되었다. 특히, 클러스터 2와 클러스터 3에 상당수의 데이터가 분포되어 있어, 1등급 레이블의 변별력이 매우 낮음을 보여준다. 2등급 및 3등급의 경우도 클러스터 1 또는 3으로 분류되며, 3등급의 레이블 역시 명확하게 구분되지 않음을 알 수 있다. 4등급은 다른 등급에 비해 정확도가 높으나, 일부 데이터가 다른 클러스터에 분포하여 일관성이 부족하다. 5등급의 경우 대부분 다르게 분류되는데, 실제 5등급 비탈면의 수가 적어 레이블의 품질 평가에는 어려움이 있다.
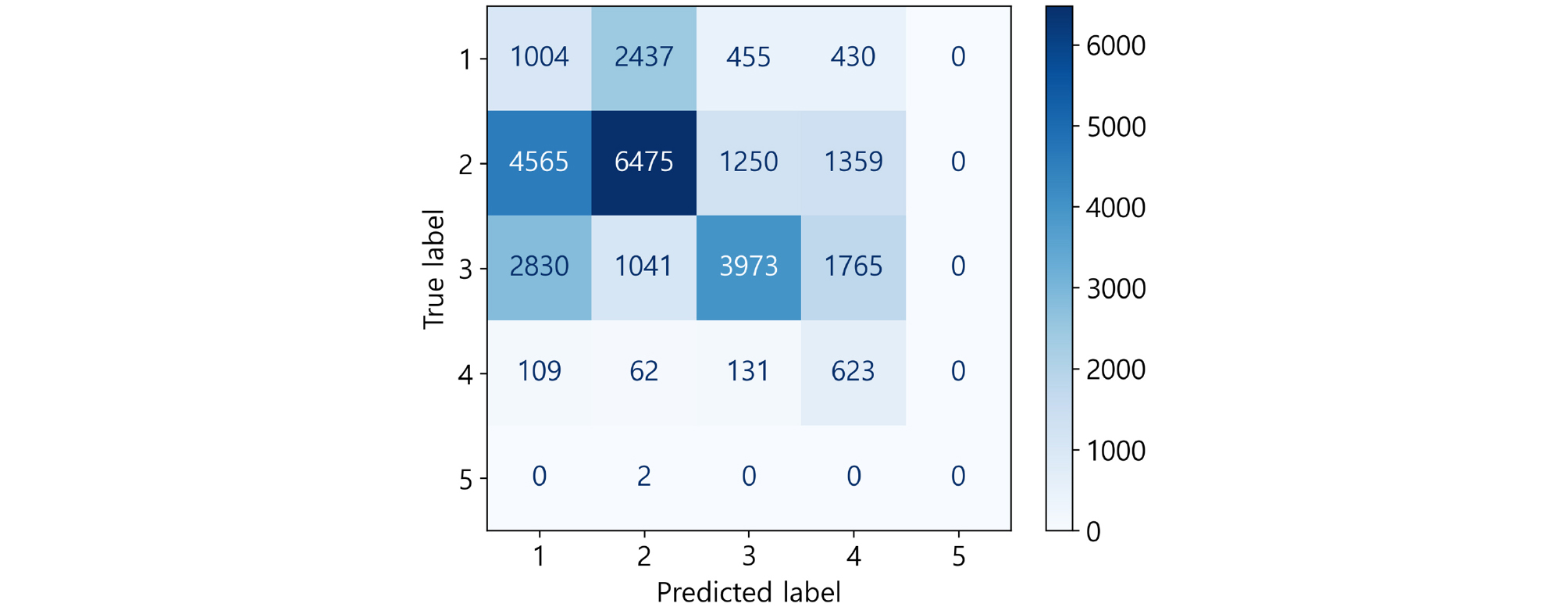
LDA는 지도학습 방법으로 레이블 간 변별력을 최대화하는 방향으로 차원을 축소하기 때문에, 기존 위험등급 레이블을 최대한 분리할 수 있도록 설계되어 있다. LDA를 사용하여 차원 축소를 수행했음에도 클러스터링 결과와 실제 위험등급 간 일치도가 낮다는 것은 몇 가지 문제점을 시사한다. 기존 위험등급 레이블이 주관적 판단에 의해 부여되었기 때문에, 동일한 비탈면에 대해 전문가의 판단이 다를 수 있으며, 이는 데이터의 레이블링에 일관성이 부족함을 의미한다. 특히, 1등급과 2등급, 3등급 간의 데이터가 서로 혼재되어 있는 것을 보면, 해당 등급 간의 기준이 모호하고, 전문가 간 판단의 차이가 클 수 있음을 보여준다. 5등급의 데이터 수가 극히 적어, LDA 및 클러스터링 알고리즘이 이를 제대로 학습하지 못하였다. 이는 데이터 수가 적은 등급에 대해서는 예측 성능이 크게 저하될 수 있음을 의미한다. 따라서 기존 위험등급 레이블의 품질과 일관성이 부족하다는 점을 시사하며, 데이터 기반의 객관적인 평가 방법의 필요성을 보여준다.
5.4 클러스터링 기반 위험등급 분류
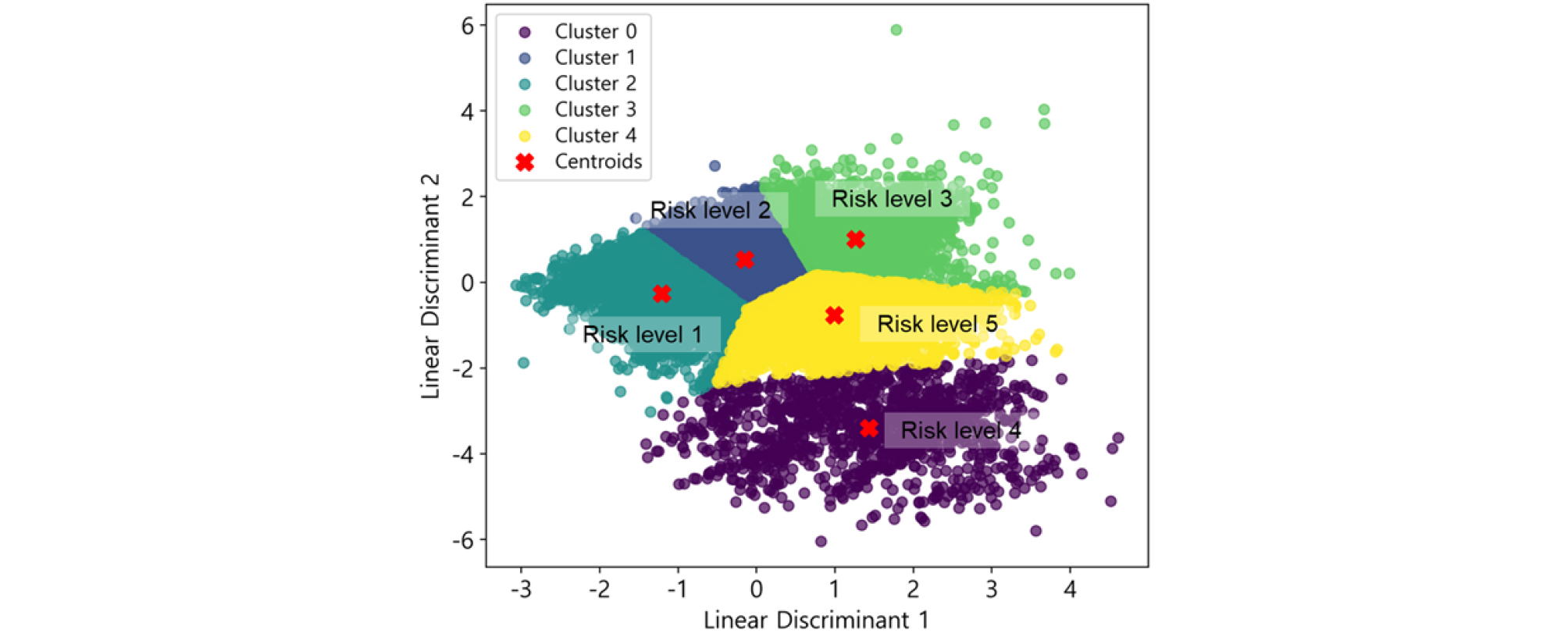
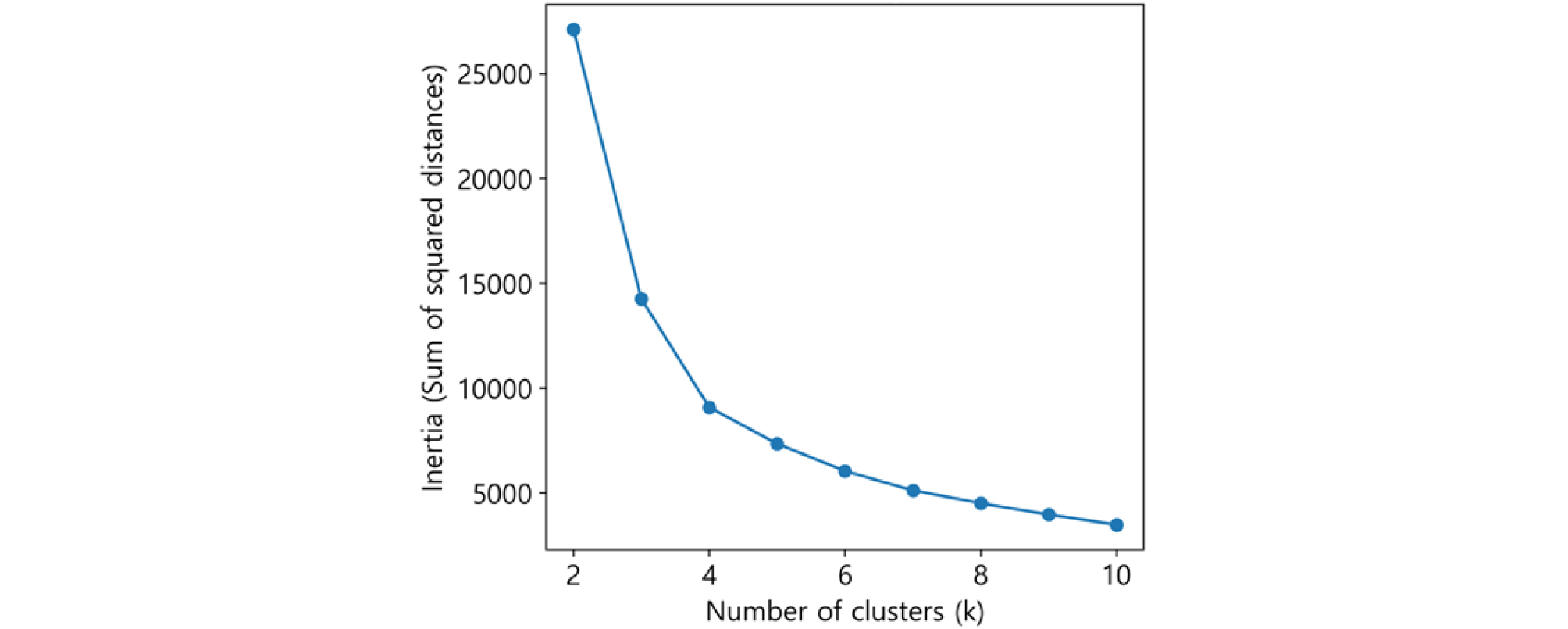
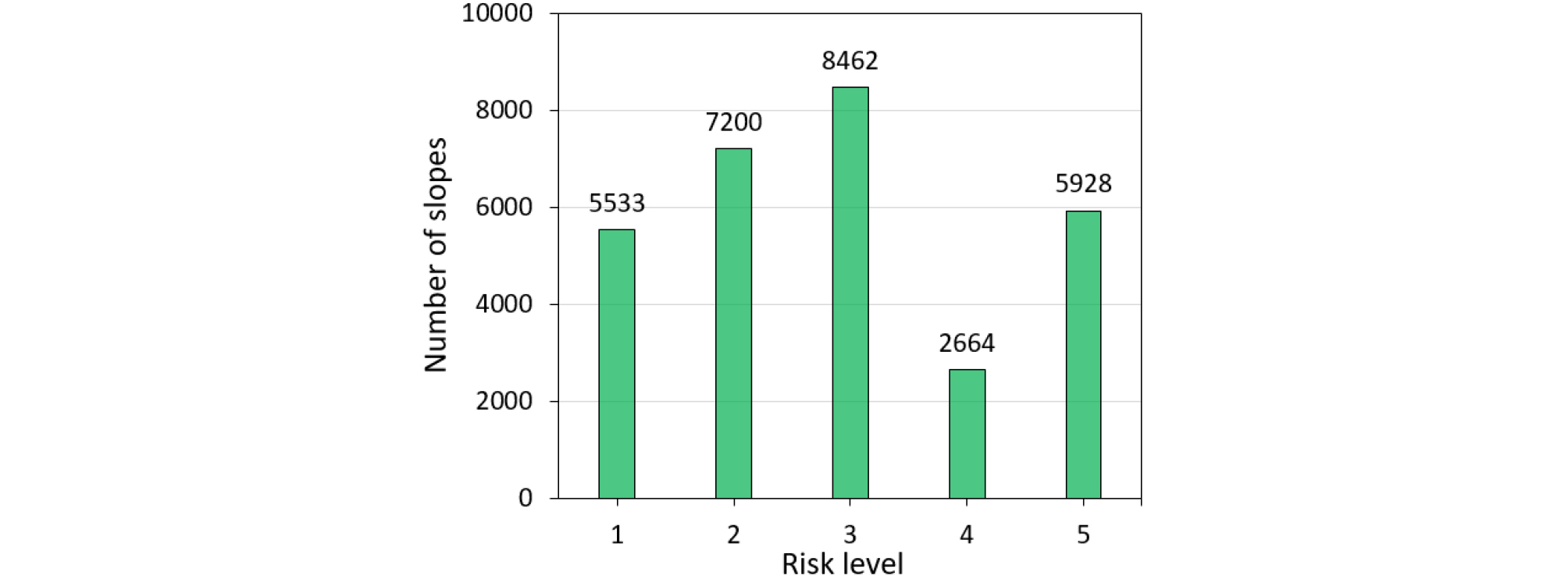
비지도 학습 기법인 주성분 분석(PCA)을 통해 차원을 축소한 후, K-means 클러스터링을 수행하여 위험등급을 재분류하였다. 기존 전문가의 주관적 판단에 의해 부여된 위험등급의 신뢰성 문제를 해결하고자, 클러스터링 결과를 기반으로 새로운 위험등급을 부여하였다. 이를 위해 엘보우 방법(Elbow method)을 사용하여 최적의 클러스터 개수를 결정하고, 각 클러스터에 대해 새로운 위험등급을 부여하는 과정을 거쳤다. 최종적으로 5개의 클러스터를 설정하고, 각 클러스터의 위험 수준을 평가하여 새로운 위험등급을 산출하였다. 클러스터 개수를 설정하기 위해 엘보우 방법을 사용하여 클러스터의 제곱합(Inertia) 변화를 관찰하였다(Fig. 10). 엘보우 방법은 클러스터의 수가 증가함에 따라, 데이터 포인트들이 클러스터 중심점에 더욱 가까워지며 제곱합이 감소하는 것을 이용하여 최적의 클러스터 개수를 선택하는 방법이다. 제곱합이 완만해지는 엘보우 지점으로 K를 5로 결정하였다. K가 5이상인 지점부터는 제곱합의 감소폭이 작지만 필요시 등급을 세분화하기 위해 K를 증가시키는 것도 가능하다. 본 논문에서는 현행 위험등급이 5등급 체계인 점을 고려하여 5개 위험등급으로 구분하였다.
K-means 클러스터링을 통해 5개의 클러스터를 형성한 후, 각 클러스터의 중심점(Centroid) 값을 사용하여 위험 수준(Risk level)을 평가하였다. 위험점수(Risk Score)는 식 (6)과 같이 정의하고, 각 클러스터의 중심점에서 선택된 변수의 절대값 합을 기준으로 결정하였다.
각 클러스터 i에 대해 선택된 변수 j의 중심점 값 의 절대값을 합산하며, n은 선택된 변수의 수를 나타낸다. 각 클러스터의 위험점수 값을 기준으로 위험등급을 부여하였다. 위험점수가 높은 순서대로 1에서 5까지 할당되었으며, 1등급이 가장 낮은 위험 수준을 의미한다. 본 논문에서 위험점수를 계산할 때 선택된 변수는 7가지(지하수, 풍화도, 불연속면방향성, 길이, 최대높이, 경사-각도, 상부경사)이다. 각 변수의 각기 다른 클래스를 가지며, 총 16개의 변수에 대해 위험점수를 계산된 것이다. 이 변수는 도로 비탈면 유지관리에서 공학적으로 중요하다고 판단되는 변수이다(Chung and You, 1996; Kim et al., 2013; Shin et al., 2008).
Fig. 11은 K-means 클러스터링 결과를 PCA 차원 축소된 데이터에 대해 시각화한 것이다. 각 클러스터는 색상으로 구분되며, 클러스터 중심점이 표시되어 있다. 클러스터 2는 5등급으로 가장 높은 위험 등급이 부여되었으며, 선택된 변수들의 절대값 합이 가장 크다. 이는 해당 클러스터의 비탈면들이 가장 높은 위험 수준에 있음을 의미한다. 클러스터 1은 4등급으로 부여되었으며, 클러스터2와 함께 높은 위험 수준에 속한다. 클러스터 3, 4, 5는 각각 위험등급 3, 2, 1로 부여되어, 위험수준이 비교적 낮게 나타난다(Table 2). 이 방법으로 분류된 위험등급별 비탈면 분포는 Fig. 12와 같다. 이와 같이 클러스터링 기반 위험등급 분류는 데이터 기반의 객관적이고 일관된 위험 평가 방법을 제공하며, 비탈면 관리 및 유지보수 우선순위를 설정하는 데 있어 보다 신뢰성 있는 정보를 제공할 수 있을 것으로 판단된다.
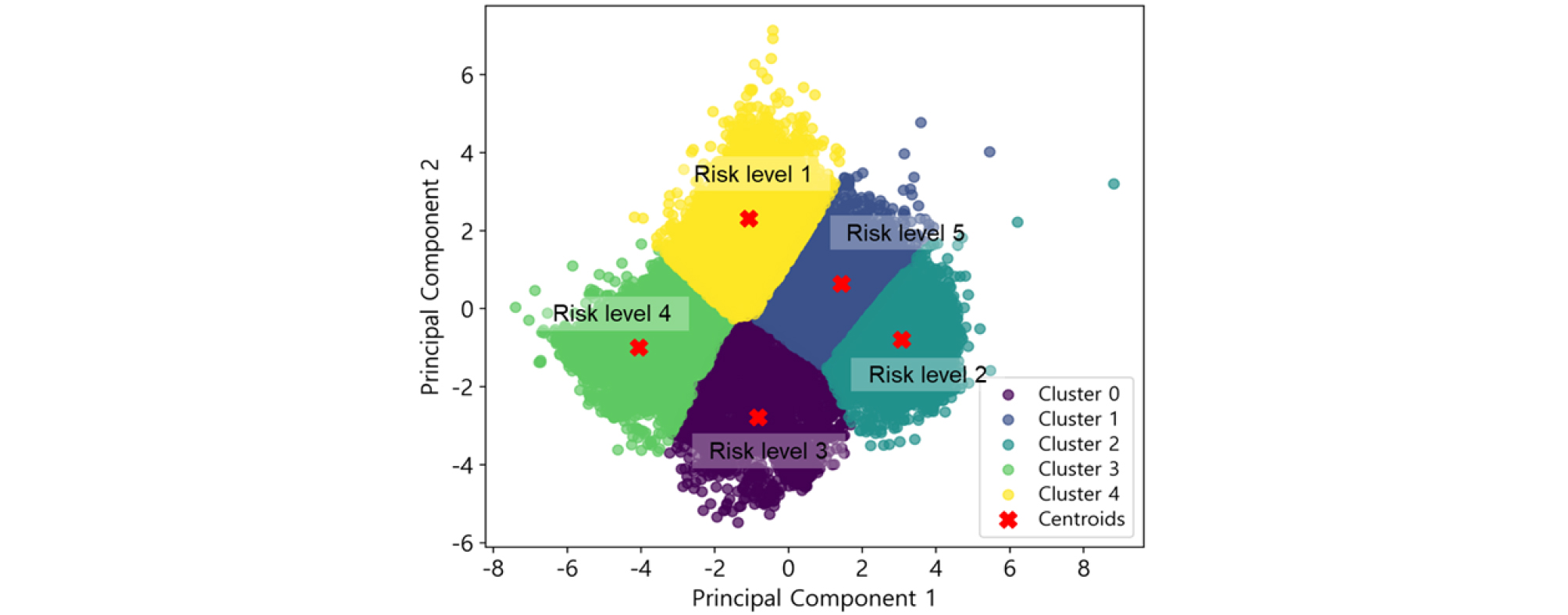
Table 2.
Evaluation results of risk scores for clusters
| Cluster number | Risk score | Risk level |
| 0 | 3.976822 | 3 |
| 1 | 6.903770 | 5 |
| 2 | 2.719360 | 2 |
| 3 | 4.044988 | 4 |
| 4 | 2.670393 | 1 |
5.5 위험등급에 대한 영향인자 분석
각 클러스터에 대해 위험점수를 계산하고, 위험점수에 영향을 미치는 주요 인자들을 정량적으로 평가하였다. 여기서 주요 인자는 위험점수 계산 시 선택된 변수를 의미하며, 본 논문에서는 전절에 소개된 바와 같이 총 16개 변수가 사용된 것이다. Fig. 13은 각 클러스터에 속하는 비탈면의 위험점수를 결정하는 주요 변수들의 절대값을 시각화한 것이다.
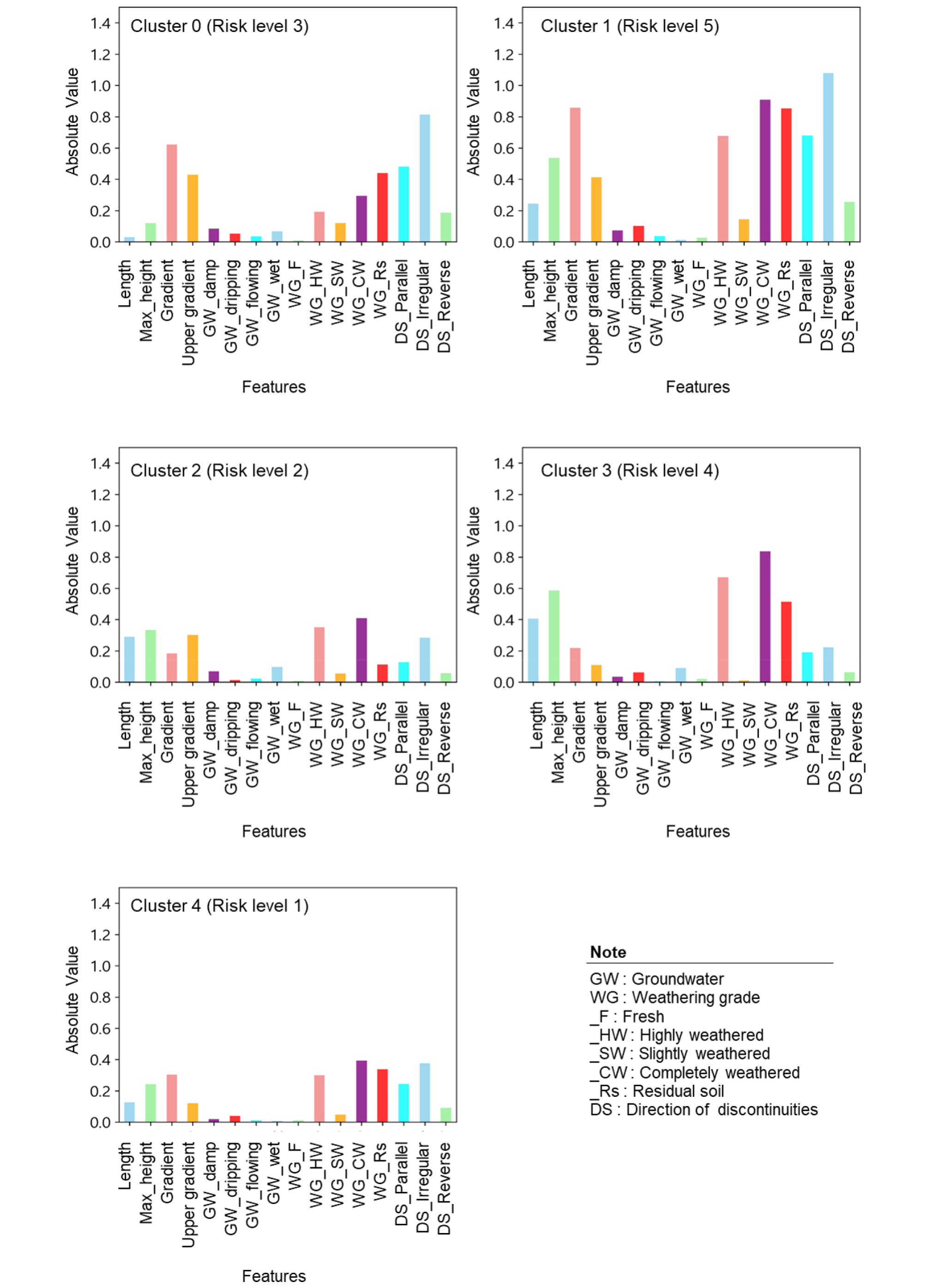
이러한 분석을 통해 각 위험등급에서 비탈면의 위험 수준에 중요한 영향을 미치는 변수들을 파악하고, 위험등급 간 선택된 변수들의 기준을 설정할 수 있을 것이다. 가장 높은 위험도의 5등급 비탈면에서는 경사와 불연속면 방향성, 낙석, 암종, 계곡부 등의 요인이 복합적으로 작용하고 있다. 특히, 절대값이 매우 높은 경사(각도)와 불연속면 방향성, 낙석 등이 위험도를 결정하는 핵심 변수로 작용하고 있음을 알 수 있다. 반면 위험도가 가장 낮은 1등급 비탈면에서는 주로 최대 길이와 경사(각도)와 같은 기본적인 지형적 요인이 주요한 영향을 미치고 있음을 알 수 있다. 특히, 경사와 관련된 변수들이 절대값이 높아, 경사와 길이의 조합이 위험도에 중요한 영향을 미친다는 것을 의미한다.
위험점수는 각 클러스터에서 위험등급을 결정하는 주요 변수들이 절대값을 기준으로 평가되었다. 특정 변수의 절대값이 특정 경계값 이상일 때, 위험등급이 상승하는 경향을 보인다. 이를 통해 각 위험등급을 분류하는 기준 설정이 가능할 것이다. 예를 들어 불연속면의 방향성이 평행이고 0.5 이상인 경우 5등급으로 분류될 가능성이 높고, 풍화도가 심하고 0.5 이상인 경우 4, 5등급으로 분류될 수 있다. 이와 함께 다른 변수들을 함께 고려하여 풍화도는 심하지만 비탈면의 각도 및 상부경사 등이 낮은 경우 보다 낮은 등급으로 분류되기도 한다. 이와 같이 위험등급에 대한 주요 변수들의 영향을 정량적으로 평가함으로써 위험등급 부여의 객관성을 높일 수 있다.
6. 결 론
본 연구에서는 도로 비탈면 유지관리 데이터를 기반으로 차원 축소와 클러스터링 기법을 활용하여 위험등급을 재분류하고, 기존 위험등급 레이블의 품질을 평가하였다. 연구의 주요 결론은 다음과 같다.
(1) PCA를 활용한 차원 축소는 클러스터링 성능 향상에 효과적임을 확인하였다. 차원 축소를 적용하지 않은 원시 데이터에 비해 PCA를 통해 차원을 축소한 데이터는 클러스터 내 데이터 응집도와 클러스터 간 분리가 명확하게 구분되었으며, 클러스터링의 유효성 지표에서도 더 우수한 결과를 나타내었다. 이는 PCA를 통해 데이터의 노이즈를 줄이고 주요한 구조적 정보를 보존함으로써 클러스터링 품질이 향상되었음을 의미한다.
(2) 기존 위험등급 레이블의 품질에 한계가 있음을 확인하였다. LDA와 K-means 클러스터링을 통해 기존 위험등급 레이블의 신뢰성을 평가한 결과, 실제 위험등급과 클러스터링 결과 간의 일치도가 낮았으며, 특히 1, 2, 3등급 데이터가 서로 혼재되어 있었고, 5등급의 경우 대부분 잘못된 클러스터에 할당되었다. 이는 기존 레이블이 전문가의 주관적 판단에 의존하고 있어, 데이터의 실제 구조를 충분히 반영하지 못하고 있음을 시사한다.
(3) 비지도 학습 기반의 클러스터링 기법은 보다 객관적이고 일관된 위험등급 평가 방법을 제공할 수 있음을 보였다. 기존 전문가 판단에 의존한 위험등급 산정 방식의 한계를 극복하고자, PCA와 K-means 클러스터링을 통해 데이터 기반의 새로운 위험등급을 제안하였다. 이 과정에서 클러스터의 중심값을 기준으로 위험 점수를 계산하고, 위험 수준에 따라 등급을 부여함으로써, 주관적 판단의 개입을 최소화하고 일관된 평가 방법을 제시하였다.
(4) 위험등급에 미치는 주요 영향인자를 정량적으로 분석하여 위험등급 부여의 객관성을 높일 수 있음을 확인하였다. 위험 점수에 영향을 미치는 주요 변수들을 분석한 결과, 경사(각도), 불연속면 방향성, 낙석, 암종 등의 변수들이 각 등급별 위험 수준에 중요한 역할을 하고 있음을 알 수 있었다. 특히, 특정 변수의 절대값이 특정 경계값 이상일 때 위험등급이 상승하는 경향을 보였으며, 이러한 기준을 통해 각 등급을 분류할 수 있는 명확한 기준 설정이 가능함을 보여주었다.
본 연구는 도로 비탈면 위험 평가에 있어 기존의 주관적 판단에 의존한 방법론의 한계를 검토하고, 데이터 중심의 과학적이고 정량적인 평가 방법을 제안함으로써 도로 비탈면 관리의 효율성과 신뢰성을 제고하는 데 기여하고자 하였다. 향후 연구에서는 다양한 머신러닝 및 딥러닝 기법을 적용하여 보다 정교한 위험 예측 모델을 개발하고, 이를 통해 도로 비탈면 관리의 자동화 및 실시간 모니터링 체계 구축에 대한 연구를 지속적으로 수행할 필요가 있다.
