

1. 서 론
2. 지질 지지지층 깊이 예측을 위한 적용 알고리즘
2.1 IDW
2.2 딥러닝 네트워크
3. 시추공 보간을 위한 데이터 베이스 구축
4. 공간보간기법과 딥러닝의 결측치 추정결과 비교
4.1 IDW 구현
4.2 딥러닝 구현
4.3 결과 및 고찰
5. 결 언
1. 서 론
지반조사의 대표적인 방법인 표준관입시험(Standard Penetration Test, SPT)은 지반의 층상별 특성 및 지지층의 깊이를 파악하기 위한 방법으로 널리 활용되고 있다. 표준관입시험은 지중에 관입된 시험용 샘플러를 약 63.5kg 무게의 햄머로 75cm 높이에서 타격하여 샘플러가 30cm 관입 될 때의 타격횟수를 N치로 나타난다. 지반 깊이에 따라 일정간격으로 SPT-N치를 산정하여 지반 주상도를 작성함으로써 지반구조물 설계 및 지지력 산정시 지층별 토사의 성상 및 공학적 특성과 지지층의 출현 깊이 등을 나타내는 주요한 지표로 사용한다.
지반조사 수행 빈도는 국・내외 다양한 설계기준을 참고하여 시공 환경에 따라 수십 미터에서 수백 미터 간격에 이르기까지 현장 특성을 고려하여 적용된다(Navfac DM7, 1974; Korea Expressway Corporation, 2012). 각종 지반 구조물의 설계를 위한 기본적인 기준을 제시하고 있는 구조물기초설계기준에서는 구조물 시공에 필요한 지반정보를 확보할 수 있는 합리적인 수준에서 수행되도록 명시되어 있다(MOLIT, 2016). 이처럼 지반조사 빈도는 다양한 참고 기준과 설계자의 주관적인 판단에 근거하여 결정되므로 시간과 비용 측면에서의 효율성만이 고려되는 경우 충분한 지반정보의 획득이 어려울 수 있다.
그러나 지층 변동성 및 불확실성을 갖는 지반특성을 간헐적인 현장조사를 통해 모두 파악하는 것은 현실적으로 불가능하므로, 기존의 시추공 정보로부터 미계측 지점을 통계학적으로 보간하여 지반특성을 추정하고 지반 구조물 설계를 위한 정보를 확보하기 위한 여러가지 방법들이 제시되어 왔다.
대표적인 지반정보의 추정방법으로는 공간보간기법이 활용되고 있는데, 그 중 잘 알려진 크리깅(Kriging)은 관측값간의 공간적인 상호관계를 베이지안 추론에 기반하여 선형 조합을 통한 결측값을 예측하는 공간기법이다. 역거리가중법(Inverse Distance Weighting, IDW) 방법 역시 가장 많이 사용되고 있는 공간보간기법 중 하나로 실측값과 결측값 사이의 가중치를 적용하는 기법이다(You and Kim, 2017). 이러한 공간보간기법은 지반분야 뿐 아니라 강우, 식생 분포, 사막화 예측, 및 미세먼지 등 다양한 분야에서 널리 활용되어 왔다(Bargoui and Chebbi, 2009; Gul and Erashin, 2019; Seo et al., 2017). 공간보간기법은 오랫동안 다양한 분야에 걸쳐 활용되어 온 만큼 사용성이 편리하다는 장점이 있지만, 공간내에 존재하는 불확실성과 변동성이 큰 지반 분야에서는 여전히 공간보간기법의 정확성을 높이기 위한 시도들이 진행되어 왔다. 이러한 단점을 극복하고자 최근에는 지반 구조물의 균열 탐지, 지반 내 액상화 발생 가능성 예측 등과 같이 지반분야와 딥러닝 기술을 접목하여 결측된 지반정보의 정확성을 높이기 위한 시도들이 진행되고 있다(Kim et al., 2018; Alobaidi et al., 2019).
본 연구에서는 지반 분야에서도 활용되고 있는 딥러닝 기법 중 완전 연결 네트워크를 기준 모델로 하여 3차원 정보에 특화된 포인트넷 구조를 적용한 네트워크를 구성하여 지반 시추공의 특성 예측을 수행하였다. 특히 지반 구조물의 지지력 산정시 중요한 지지층의 깊이를 추정하는 것을 목표로 연구대상 지역으로부터 확보한 시추조사 결과의 지반두께와 암반 출현 깊이를 예측하고자 하였다. 이를 통해 딥러닝 알고리즘을 통해 도출된 결측치의 오차 평균과 기존의 공간보간기법인 IDW를 통한 오차 평균을 비교하고 결과의 차이를 분석하였다.
2. 지질 지지지층 깊이 예측을 위한 적용 알고리즘
2.1 IDW
IDW는 식 (1)을 바탕으로 계측 데이터의 선형 가중 조합을 이용하여 결측치의 값을 결정하는 방법이다. 공간적으로 인접한 지점 사이의 값은 공통된 위치요인으로 인하여 유사성을 갖게 되며 두 지점 사이의 거리가 증가할수록 유사성은 감소하게 된다(Ahn and Park, 2012).
여기서, Z(x)는 미관측 지점의 추정값, wi는 가중치, Zξ는 인근지점의 관측값, Li는 미관측 지점으로부터 관측점까지의 거리이다.
2.2 딥러닝 네트워크
딥러닝(deep learning) 네트워크는 Fig. 1과 같이 뇌의 구조를 모사한 인공 뉴런(artificial neuron)을 다층 구조로 한 인공 신경망(artificial neuron network, ANN) 이다. 본 절에서는 연구에서 선정한 두 가지 네트워크 구조에 대한 일반적인 설명을 기술하였다.
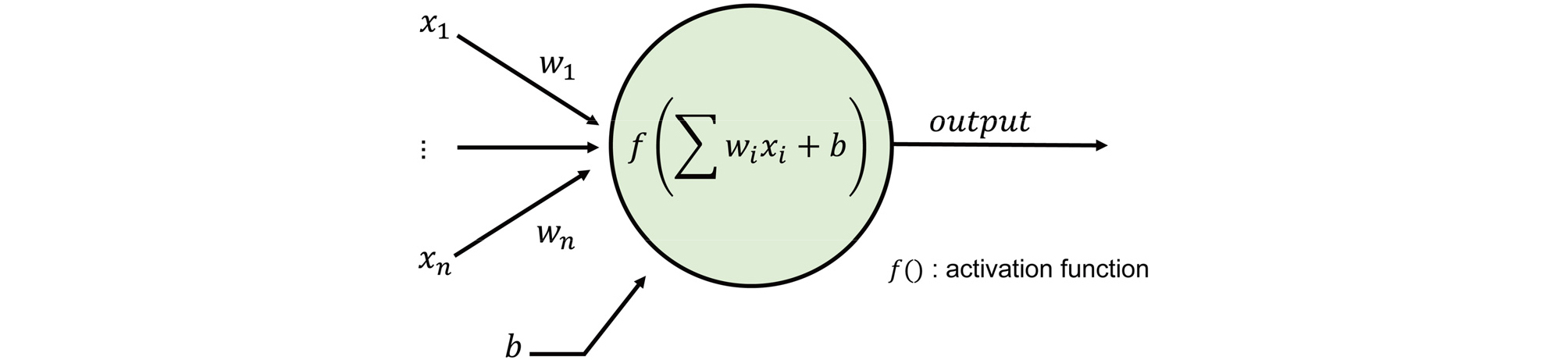
2.2.1 완전 연결 네트워크(Fully connected network)
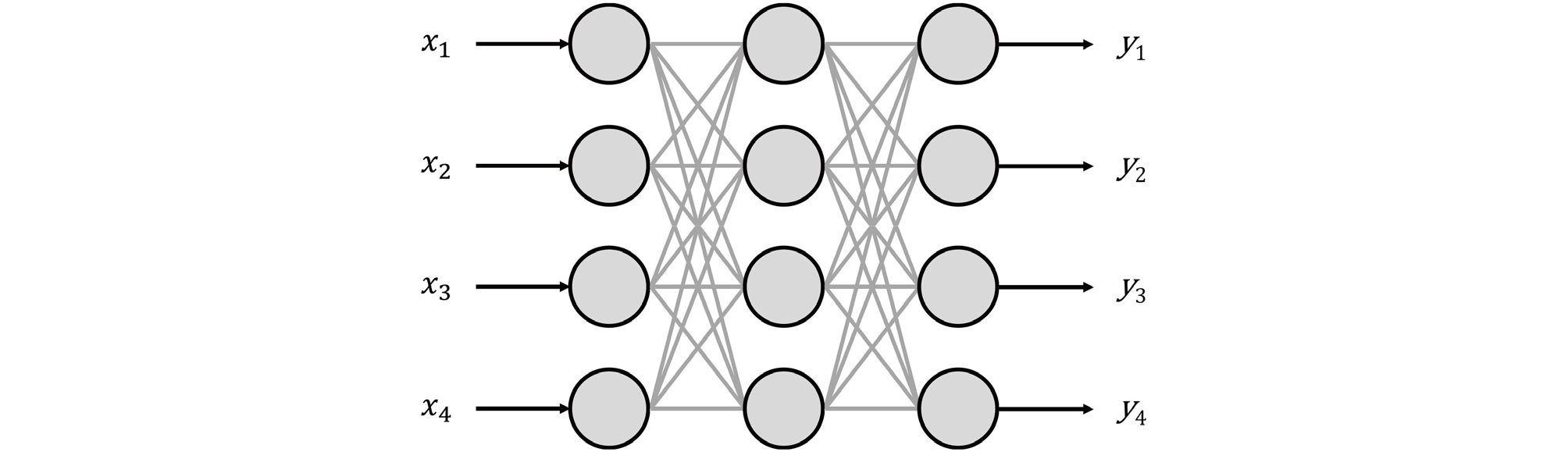
완전 연결 네트워크는 Fig. 2와 같이 각 층의 인공 뉴런이 다음 층의 인공 뉴런으로 모두 연결된 구조를 말한다. 본 네트워크 구조는 입력 자료를 1차원 배열로 만들어 입력을 받아야 하므로 자료의 공간과 시간 정보가 손실된다. 그리고 많은 가중치(weight factor)가 들어가므로 학습 시 연산이 많이 필요한 단점이 있다. 하지만 입력 자료간에 상관관계를 모르는 경우, 완전 연결 네트워크 구조는 각 층간에 연결을 모두 가지므로 입력 자료간에 보이지 않는 상관관계를 구축하여 입력 자료와 출력 값의 상관관계를 만들어주는 장점이 있다. 또한 네트워크 구조도 간단하여 손쉽게 다룰 수 있다. 따라서 이미지 분류나 언어의 번역 같은 정형적인 문제를 제외한 일반적인 문제에 대한 접근으로 가장 쉽게 적용해볼 수 있는 네트워크 구조이다.
2.2.2 포인트넷(PointNet)
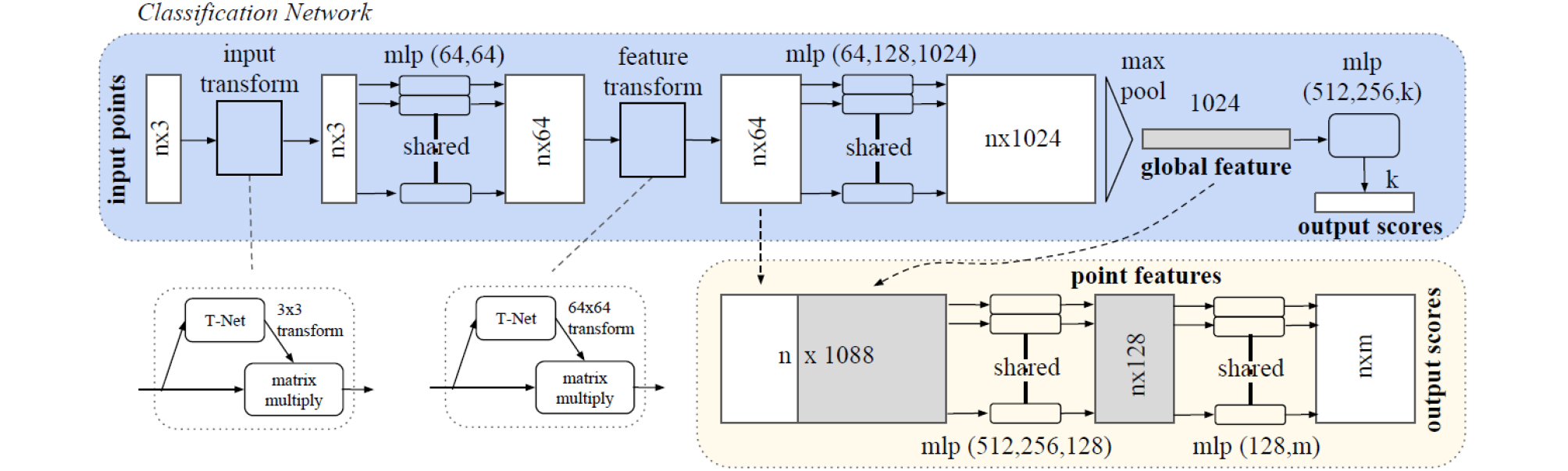
포인트넷은 Qi et al.(2017)에 의해 제안되었으며 3차원의 포인트 정보의 집합을 입력으로 받아 3차원 객체를 분류(classification) 또는 분할(segmentation) 할 수 있는 네트워크 구조이다. 일반적으로 3차원 데이터를 다루기 위해서 복셀(voxel)의 집합이나 이미지 집합을 사용하는데 이는 데이터를 표현하는 용량이 커지는 단점이 있다. 3차원 정보를 포인트의 집합으로 표현하면 적은 데이터로 3차원 형상을 표현할 수 있어 이러한 단점이 극복된다. 그리고 포인트 집합을 네트워크에서 받아 처리한다면 3차원 형상을 보다 손쉽게 인공지능에서 다를 수 있게 된다. 포인트 집합 정보를 받아 네트워크에서 처리하게 만들려면 포인트 집합이 가지는 두 가지의 속성을 네트워크가 이해할 수 있어야 한다. 첫 번째는 순서 불변성(permutation invariant)이고 두 번째는 강체운동 불변성(rigid motion invariant)이다. 3차원 데이터를 포인트 정보로 나타내었을 때 각 포인트의 순서가 바뀌거나 모든 포인트가 동시에 회전이나 이동하여도 같은 데이터로 인지되어야 한다. 포인트넷은 Fig. 3과 같은 구조를 가지는데 입력 포인트 간에 가중치를 공유하고 중간 결과를 max pooling하므로 포인트 순서가 바뀌어도 출력에 차이가 나지 않는다. 따라서 순서 불변성을 만족한다. 그리고 내부적으로 강체 운동을 인지하고 변형행렬을 생성하는 T-net을 포함하여 강체운동 불변성을 구현하였다. 이렇게 포인트넷은 포인트 집합이 가지는 속성을 받아들일 수 있는 구조를 구현한 네트워크이다.
3. 시추공 보간을 위한 데이터 베이스 구축
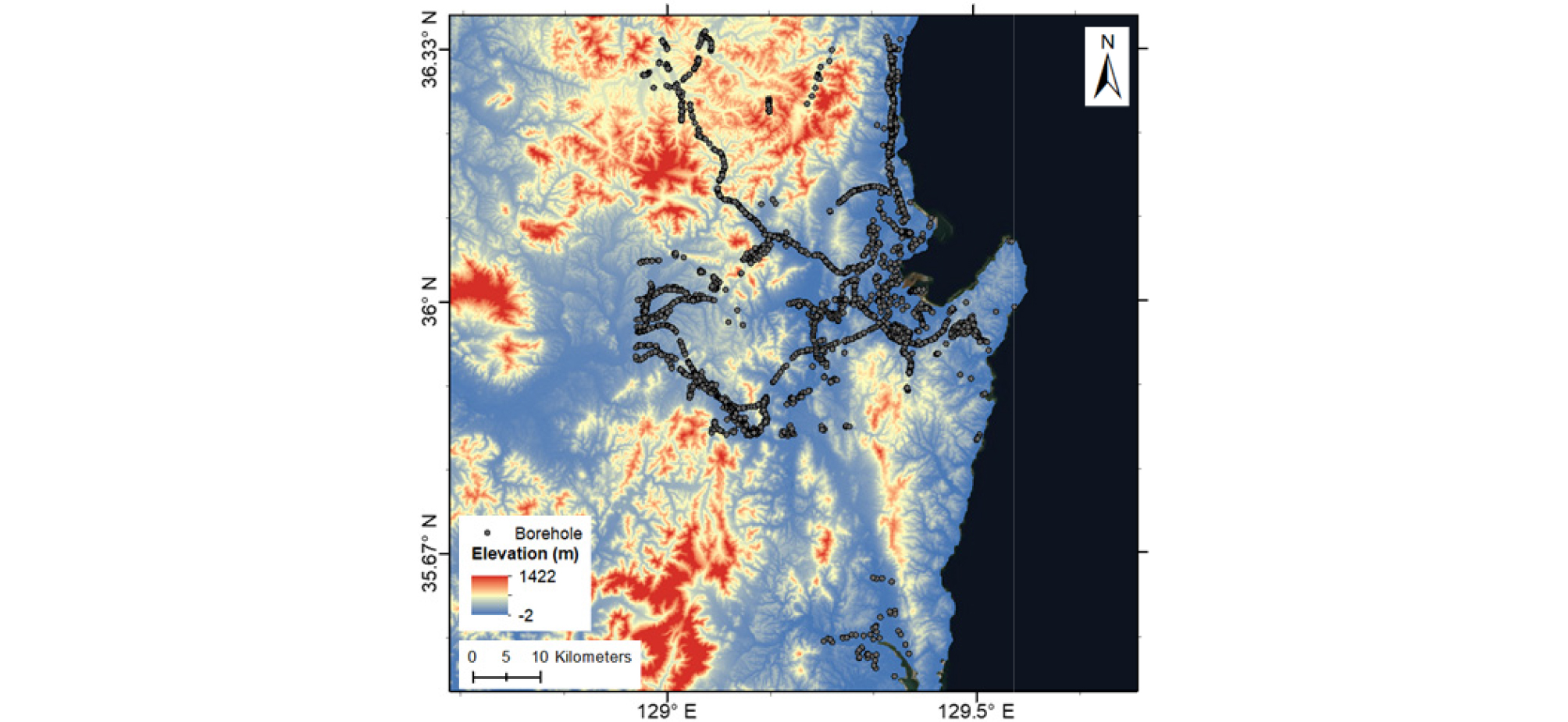
연구대상 지역은 내륙, 산간, 해안 지역을 모두 포함하는 동시에 지반 조사 결과의 획득이 용이한 지역이라고 판단되는 경상북도 지역으로 설정하였다. 약 29만공의 국내 시추조사 데이터베이스를 구축하고 있는 국토지반정보포털시스템 DB 중 경상북도 지역의 시추정보 2만 1천개를 본 연구에 활용하였다. 이를 시추공 ID, 좌표, 지반두께 및 암반의 출현 깊이 순으로 정리하고, 좌표 및 연관 데이터가 중복 또는 누락된 경우를 제외하였다. 또한 데이터 분포현황 중 암반 깊이와 표고 중 일정 값 이상을 벗어나거나 데이터 개수가 현저히 작아 딥러닝이 이상점(outlier)으로 받아들일 것으로 판단되는 값을 제외하였다. 그 결과 지반깊이를 50m 이내로 갖는 총 2만 1천여개의 데이터베이스를 구축하였다.
Fig. 4는 경상북도 지역의 수치표고모델(Digital Elevation Model, DEM)상에 나타난 2만 1천여개의 데이터 분포를 나타내며, 주로 포항, 영덕, 안동 및 경주 근방에서의 지반조사 결과로 구성되어있음을 알 수 있다.
각 지반조사의 시추정보에는 기본적인 정보와 함께 지층 깊이별 N치, 지층종류별 색상, 육안관찰 결과 및 밀도 등의 지층 특성 등 다양한 정보가 포함되어 있다.
이러한 정보들을 종합한 결과 지층의 종류는 매립토, 붕적토, 전답토, 퇴적토, 풍화토로 총 5종, 암반은 풍화암, 연암, 보통암, 경암으로 총 4종으로 구분되었다. 서두에서 기술한바와 같이 본 연구에서는 암반층의 깊이 추정을 목적으로 함에 따라 상기 정보를 종합하여 토층과 암반으로 시추공 정보를 재가공하였다.
딥러닝과 IDW의 입력 데이터는 모든 지반조사 데이터가 한번씩 원점이 될 때 주변점을 20개씩 나열하는 방식으로 구성하였다. 이를 위해 각 데이터의 위도, 경도, 표고가 0이 될 때를 원점으로 하여 직선거리상 가까운 순서로 주변점 20개를 정리하였다. 이 과정에서 지반 데이터는 무작위로 추출하여 80%는 학습을 위한 training set으로 활용하여고, 나머지 20%는 test set(10%)과 validation set(10%)로 분류하였다. 또한 test set과 validation set의 주변점 정보는 training set으로부터 배제되도록 하였다.
4. 공간보간기법과 딥러닝의 결측치 추정결과 비교
본 절에서는 딥러닝 방법과 기존 공간 보간 기법인 IDW 기법의 구현을 구체적으로 기술하고 각 방법의 추정 결과 비교를 수행하였다.
4.1 IDW 구현
IDW 보간은 오픈소스 GIS 소프트웨어인 Qgis 3.10의 내장 플러그인을 통해 수행하였다. 보간을 위해 먼저 학습 데이터로 분류된 17321개의 training set을 입력하고, Fig. 5의 (a)와 같이 토층과 암반의 깊이 정보를 갖는 점 데이터를 포함하는 면적에 대해 보간을 진행하였으며, 이때 가중치(wi)는 2를 입력하였다. 일반적으로 가중치는 0~2사이에서 사용되는데, 가중치가 0에 가까울수록 보간시 주변점의 영향이 낮아지게 된다. 보간 완료 후에는 Fig. 5의 (b)와 같이 결측치에 해당하는 test set 2166개 지점에 대한 지층 깊이 즉 암반 지지층의 출현 깊이를 추정하였다.

4.2 딥러닝 구현
4.2.1 완전연결 네트워크
2.2.1절의 설명과 같이 완전 연결 네트워크는 일반적인 문제에 가장 쉽게 적용해 볼 수 있는 네트워크 구조이므로 지반 지지층 깊이를 예측하기 위한 첫 딥러닝 모델로 Fig. 6과 같은 완전 연결 네트워크 구조를 적용하였다. 네트워크의 구현은 python에서 Tensorflow 프레임워크를 사용하였다. 네트워크의 크기 및 학습률(learning rate)을 결정하기 위해 본 절의 설정을 유지한 상태로 깊이와 넓이를 변경해가며 비교를 수행해 보았고 그 결과 Table 1과 같은 결과를 보였다. 해당 결과를 바탕으로 본 연구에서는 총 8층의 완전 연결층을 사용하였고 각 층별로 640개의 인공 뉴런을 적용하였다. 각 층별로 배치 정규화(Batch normalization)를 적용하여 각 학습 데이터의 입력값 편차에 의한 영향을 최소화 하였다. 활성화 함수(activation function)는 ELU를 사용하였다.
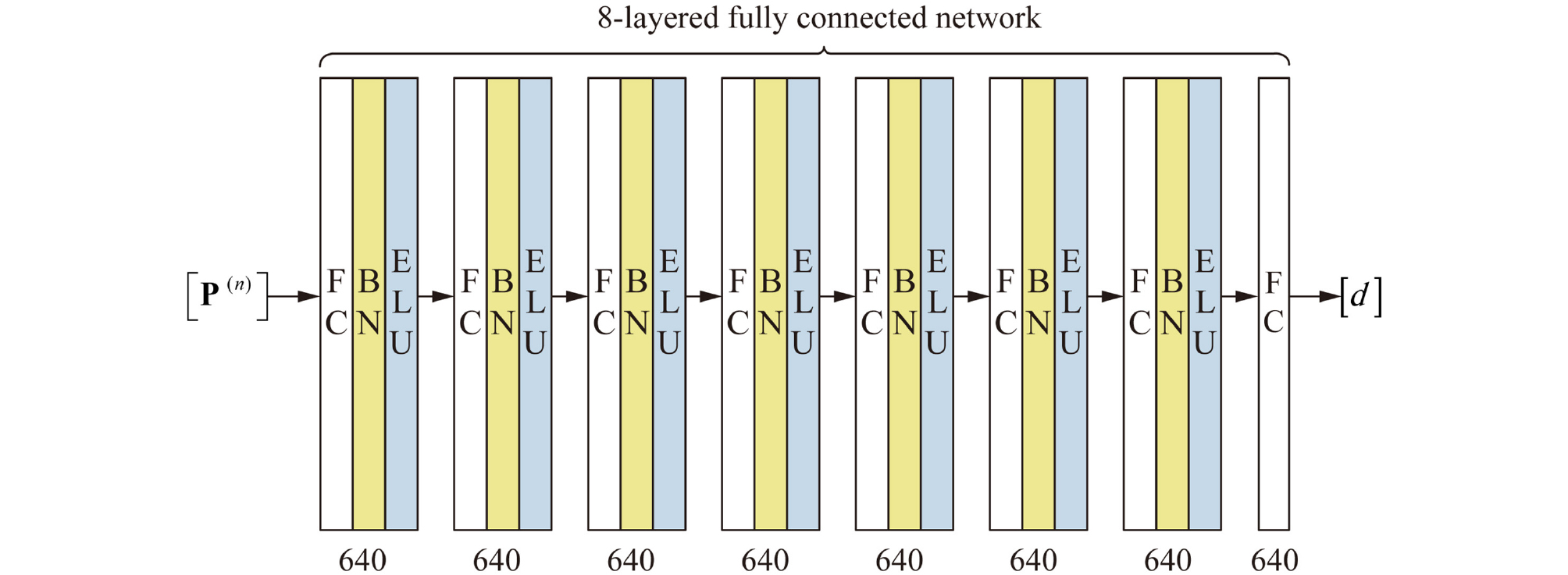
Table 1.
Averaged error of Bed-rock depth estimation from the fully connect layer according to the depth, width, and learning rate (training data error/test data error)
손실함수는 평균절대오차값을 사용하였다. 가중치 최적화는 Adam 최적화를 사용하였고 배치(batch) 크기는 8650, 에폭(epoch)은 10000번, 학습률은 0.01에서 에폭의 진행에 따라 선형적으로 0에 수렴하게 만들었다. 학습시간은 RTX 2080 GPU를 사용하여 약 25분이 소요 되었다.
4.2.2 포인트넷
지반 지지층 깊이를 추정하는 방법은 주변 홀의 정보로부터 보간을 이용한다. 주변 홀 정보는 3차원 포인트 정보라고 할 수 있다. 따라서 2.2.2절의 설명과 같이 3차원 포인트 정보를 다룰 수 있는 포인트 넷의 구조가 본 문제에 적합하다. 하지만 주변 홀 정보는 기하적인 포인트 정보와는 다르다. 순서 불변성은 만족되어야 하지만 절대 위치에 따른 차이가 있을 수 있으므로 강체운동 불변성은 고려되지 않아야 한다. 따라서 포인트넷을 그대로 사용할 수 없으며 주변 홀 정보를 다룸에 있어 적합한 속성인 순서 불변성만을 구현한 별도의 네트워크 모델이 필요하다.
본 연구에서는 순서 불변성만을 구현하기 위해 네트워크를 다음과 같이 구성하였다. 입력단에 포인트간의 가중치를 공유하기 위한 1차원 합성곱 신경망(1D Convolutional Neural Network)을 64개 배치하였고 이후에는 각층별로 128, 256, 512개의 1차원 합성곱 신경망을 배치하였다. 이는 각 포인트의 특성(feature)값이 가중치를 공유한 상태로 합성곱 신경망의 필터 개수와 동일한 인공 뉴런을 가지는 완전 연결 네트워크로 연결된 것과 동일하게 동작하게 만들어준다. 512개의 합성곱 신경망을 거친 결과는 max pooling과 average pooling을 수행한다. 그 후 각 결과 값을 1차원 배열로 연결시켜 다시 512개의 완전 연결층에 입력한다. 이후에는 각 층별로 256, 128, 64개의 완전 연결층을 거쳐 최종적으로 지반 깊이 값이 나오도록 구성하였다. 이를 정리한 네트워크의 구조는 Fig. 7과 같다. 구현은 python의 Tensorflow 프레임워크를 사용하였다. 각 층에는 배치 정규화를 적용하였고 활성화 함수(activation function)는 ELU를 사용하였다. 손실함수는 평균절대오차값을 사용하였다. 가중치 최적화는 Adam 최적화를 사용하였고 배치(batch) 크기는 256, 에폭(epoch)은 2000번, 학습률(learning rate)은 0.0001을 적용하였다. 총 10개의 모델을 구축하도록 10 fold를 적용하였고 예측 결과는 10개 모델의 앙상블 평균을 이용하였다. 10개 모델을 학습하는 총 시간은 RTX 2080 GPU를 사용하여 약 4시간 12분이 소요 되었다.

4.3 결과 및 고찰
본 절에서는 앞서 분류한 학습 데이터를 공간보간기법인 역거리가중법(IDW), 딥러닝 기법 중 완전연결 네트워크(fully connected network)와 포인트넷(point net)을 통해 학습 하고, 결측치로 간주되는 test set 2166개에 대한 지반 지지층 깊이를 추정하였다. 또한 세 가지 방법의 결측치 예측 결과를 test set의 실제 지지층 깊이와 비교하여 각 시추공별 추정 오차를 산정하였으며, Table 2와 같이 각 방법별 최소, 최대 오차 및 전체 예측 오차에 대한 평균을 정리하였다. 그 결과 지반 지지층 깊이 예측결과에 대한 평균 오차는 point net, IDW, Fully connected network 순서로 크게 나타났다. 이를 통해 지지층 깊이 예측에 딥러닝을 적용한다고 하더라도 항상 기존 방법 대비 우수한 결과가 나오는 것이 아니며 딥러닝 네트워크의 선정에 따라 결과의 차이가 발생할 수 있음을 알 수 있다.
Table 2.
Parameter estimation results
| Model type | Bed-rock depthreal-estimation (m) | ||
| Minimum | Maximum | Mean | |
| IDW | 0.0001088 | 40.49 | 3.01 |
| Fully connected network | 0.0013 | 43.54 | 3.22 |
| Point net | 0.0023 | 39.09 | 2.46 |
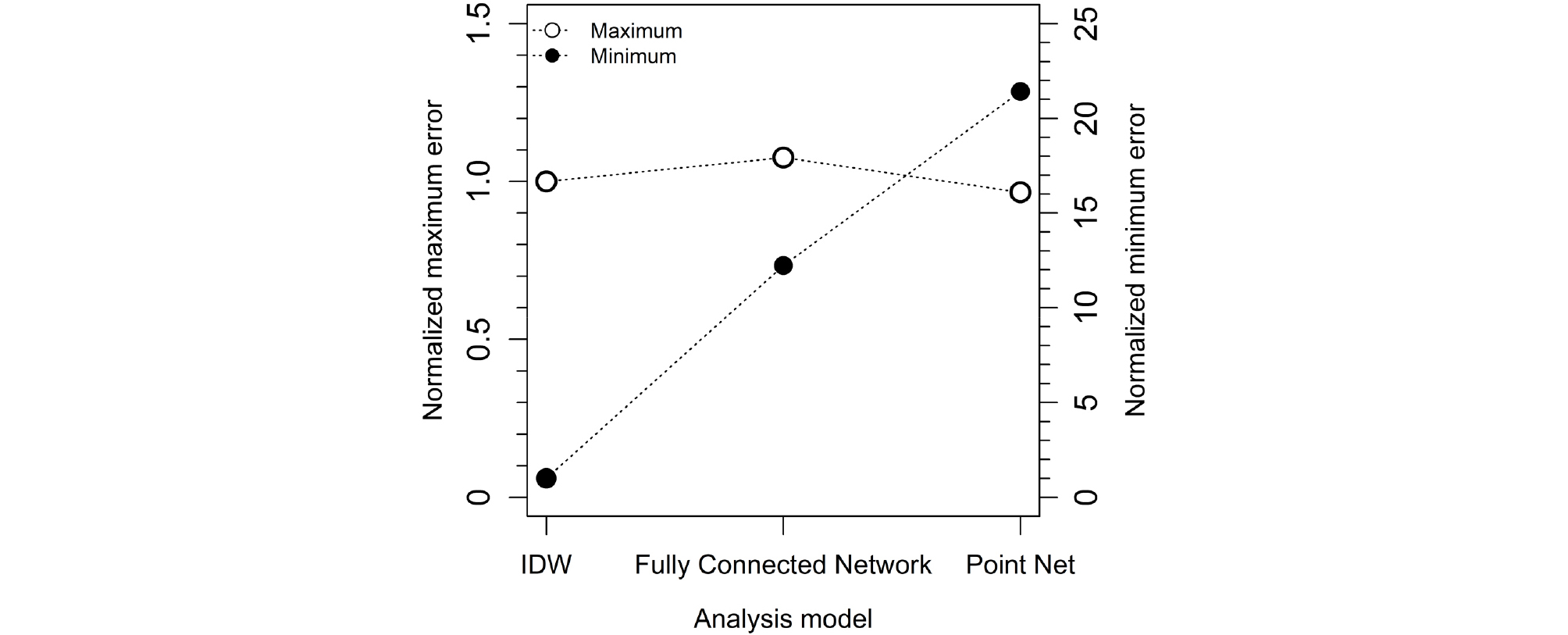
위의 표에서 각 분석 모델로부터 나타난 전체 예측치의 최소, 최대 오차를 IDW에 대해 정규화 하여 Fig. 8에 도시하였다. 최대 오차의 경우 실제 깊이와 세 가지 방법을 통해 예측한 지지층의 깊이가 유사하게 나타났으며, point net 수정 모델이 39.09m로 가장 작게 나타났다. 반면 최소 오차의 경우 IDW와 비교해 20배까지 크게 나타났으나, 각 방법에 따른 절대 오차가 유의미한 차이를 보이지는 않는 것으로 판단되었다.
세 가지 모델로부터 산정한 전체 오차의 평균(μ)은 IDW가 3.01m로 나타난 것에 비해 point net이 2.46m로 나타나 타 모델과 비교해 개선된 결과를 보였다. 이러한 전체 오차 평균(μ)과 표준편차(σ)를 바탕으로 정규분포 특성을 Fig. 9와 같이 살펴본 결과 IDW와 Fully connected network의 표준편차가 각 3.99와 3.95였으며, Point net이 3.54로 오차의 분산 또한 감소한 것을 알 수 있었다.
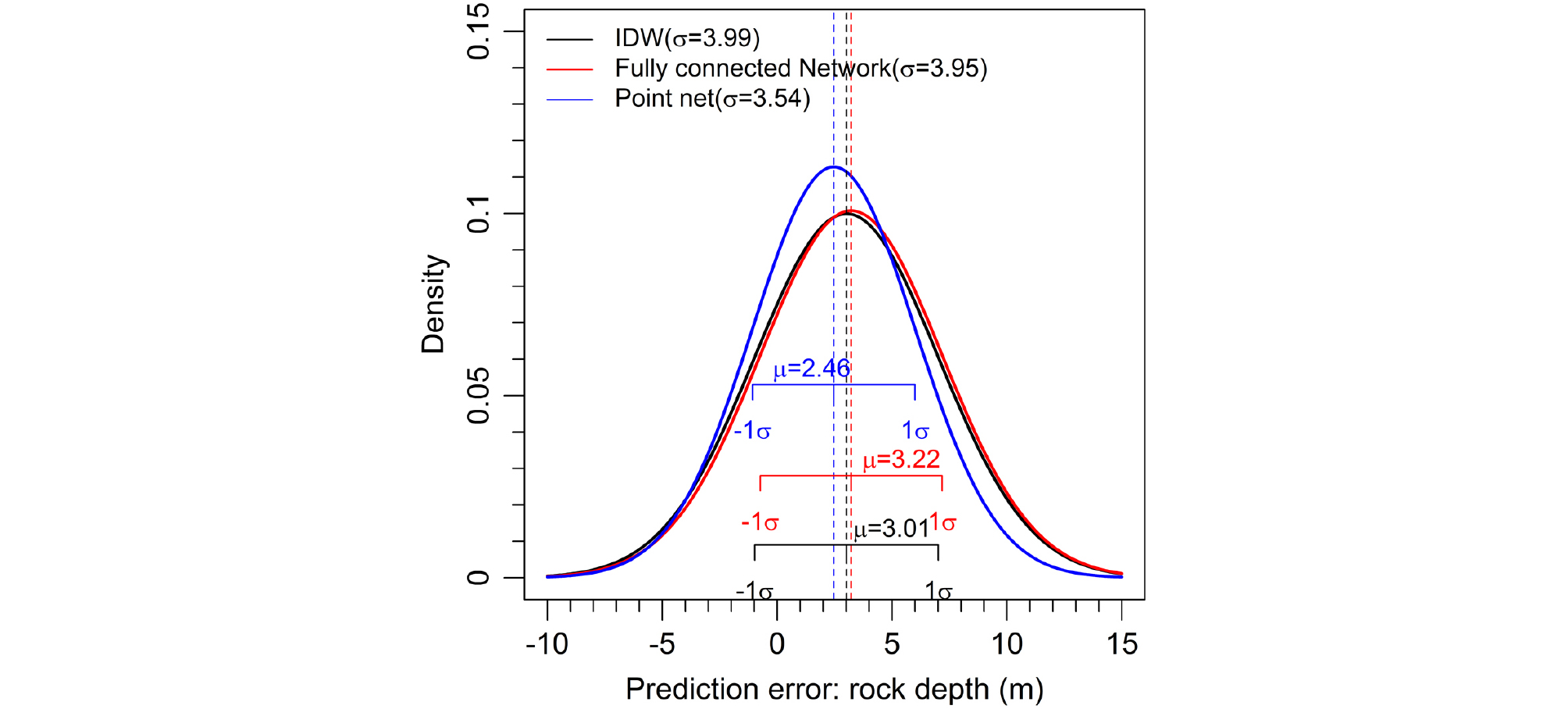
IDW는 주변 점들의 깊이와 거리 정보들을 순서에 관계없이 가중 평균한 방법이므로 순서 불변성은 만족하며 거리를 이용한 유사성만을 활용하게 된다. Fully connected network는 주변점 정보의 순서 불변성은 만족하지 못하지만 주변 점의 절대 좌표 정보와 상대 좌표 정보를 활용한다. 두 방법이 사용하는 특성이 차이가 나지만 각 방법의 추정 오차의 표준편차는 유사한 것을 확인하였다. 본 결과를 통해 기존 방법인 IDW와 좌표 정보를 활용하는 Fully connected network보다 point net이 깊이 추정에 더 적합한 것을 알 수 있었다. 이는 point net 방법이 IDW, Fully connected network와 달리 3차원 정보의 절대 위치별 특성 변화를 활용하고 순서 불변성, 상대 좌표 정보를 동시에 고려하기 때문으로 판단된다. 본 결과를 통해 딥러닝 기술을 활용한다고 하더라도 입력된 정보의 활용 가능성과 적절한 네트워크의 선정이 중요함을 알 수 있으며 딥러닝 기술이 기존 기술에 비해 우수한 결과를 낼 수 있음을 확인하였다. 그러나 여전히 딥러닝 기법을 통해 예측한 지지층의 깊이를 실제로 적용하기 위해서는 오차 한계가 감소되어야 할 것으로 보인다. 이를 위해 향후 지지층 깊이 예측 오차 감소에 영향을 미치는 영향 인자들을 파악하고, 다양한 변수들을 고려한 추가적인 연구를 수행해 나갈 예정이다.
5. 결 언
본 연구에서는 지반 구조물의 지지력 산정시 중요한 자료가 되는 지지층의 깊이를 추정하기 위해 경상북도 지역의 지반조사 데이터를 바탕으로 결측치에 대한 지지층 깊이 예측 연구를 수행하였다. 이를 위해 기존에 활용되고 있는 공간보간기법인 역거리가중법(IDW)을 통해 결측치에 대한 지지층 깊이를 예측하고, 이를 완전 연결 네트워크(fully connected network) 모델 및 3차원 정보에 특화된 포인트넷(point net) 구조를 적용한 딥러닝 결과와 비교하였다. 또한 세 가지 방법들에 지반 형상 및 정보를 학습 시킨 후 테스트 데이터에 대한 추정 결과를 도출하고, 테스트 결과와 추정 결과의 차이를 최대/최소 오차, 평균 오차 및 평균 오차의 분산 특성을 통해 비교하였다. 그 결과 딥러닝 알고리즘 중 포인트넷 모델이 IDW 및 완전연결 네트워크에 비해 개선된 추정 결과를 나타냈다. 이러한 결과를 바탕으로 예측 오차를 개선하기 위한 필요성을 도출하였으며, 이를 위해 향후 지지층 깊이 예측 오차 감소에 영향을 미치는 영향 인자들을 파악하고, 다양한 변수들을 고려한 추가적인 연구를 수행해 나갈 예정이다.
